Command Palette
Search for a command to run...
더 안전한 추론 흔적(Reasoning Traces): LLM에서 Chain-of-Thought 누출의 측정 및 완화
더 안전한 추론 흔적(Reasoning Traces): LLM에서 Chain-of-Thought 누출의 측정 및 완화
Patrick Ahrend Tobias Eder Xiyang Yang Zhiyi Pan Georg Groh
초록
Chain-of-Thought (CoT) prompting은 LLM의 추론 능력을 향상시키지만, 모델이 PII를 재진술하지 않도록 지시하는 정책 하에서도 prompt에 포함된 개인 식별 정보(PII)가 추론 과정(reasoning traces) 및 출력값에 다시 나타남으로써 프라이버시 위험을 증가시킬 수 있습니다. 본 연구에서는 다음과 같은 모델 불가지론적(model-agnostic) 프레임워크를 사용하여 이러한 직접적인 추론 시점(inference-time)의 PII 유출을 연구합니다. (i) 유출을 11가지 PII 유형에 걸친 위험 가중치 기반의 token 단위 이벤트로 정의하고, (ii) 허용된 CoT budget의 함수로서 유출 곡선을 추적하며, (iii) 계층적 위험 분류 체계(hierarchical risk taxonomy)를 갖춘 구조화된 PII 데이터셋을 통해 오픈 소스 및 폐쇄형 모델 제품군을 비교합니다. 연구 결과, CoT는 특히 고위험 카테고리에서 유출을 일관되게 심화시키며, 유출 정도는 모델 제품군 및 budget에 따라 강력한 의존성을 보임을 확인했습니다. 즉, reasoning budget을 늘리는 것이 베이스 모델에 따라 유출을 증폭시키거나 혹은 완화할 수 있습니다. 이어 우리는 rule-based detector, TF-IDF + logistic regression classifier, GLiNER 기반 NER 모델, 그리고 LLM-as-judge를 포함한 경량 추론 시점 gatekeeper들을 위험 가중치 적용 F1(risk-weighted F1), Macro-F1, recall 지표를 사용하여 benchmark합니다. 단일 방법론이 모든 모델이나 budget에서 우위를 점하지 못한다는 점은, 공통적이고 재현 가능한 프로토콜 하에서 유용성과 위험 사이의 균형을 맞추는 하이브리드 방식 및 스타일 적응형(style-adaptive) gatekeeping 정책의 필요성을 시사합니다.
One-sentence Summary
This study proposes a model-agnostic framework to measure and mitigate privacy risks from Chain-of-Thought leakage by analyzing risk-weighted token-level events across 11 PII types and varying reasoning budgets, ultimately benchmarking inference-time gatekeepers including a rule-based detector, a TF-IDF and logistic regression classifier, a GLiNER-based NER model, and an LLM-as-judge to advocate for hybrid, style-adaptive policies.
Key Contributions
- The paper introduces a model-agnostic framework that defines PII leakage as risk-weighted, token-level events across eleven distinct PII types to analyze how reasoning traces resurface sensitive information.
- This work establishes a reproducible protocol to trace leakage curves as a function of the allowed Chain-of-Thought budget, revealing that reasoning processes systematically increase leakage in a manner that is highly dependent on the specific model family and budget size.
- The study benchmarks several lightweight inference-time gatekeepers, including rule-based detectors, lexical classifiers, GLiNER-based NER models, and LLM-as-judge variants, demonstrating that no single method provides universal protection across all models and reasoning budgets.
Introduction
While Chain-of-Thought (CoT) prompting significantly enhances the reasoning capabilities of large language models, it introduces a critical privacy vulnerability by potentially resurfacing personally identifiable information (PII) from the prompt into intermediate reasoning traces and final outputs. Prior research has largely focused on PII extraction from training data or general contextual privacy, often overlooking the specific risk of direct, inference-time leakage where models violate "do not restate PII" policies during step-by-step reasoning. The authors leverage a model-agnostic framework to quantify this risk, defining leakage as risk-weighted, token-level events across eleven PII categories. They demonstrate that CoT consistently increases leakage and that these patterns vary significantly based on the model family and the reasoning budget allowed. To address this, the authors benchmark several lightweight inference-time gatekeepers, including rule-based detectors, lexical classifiers, NER models, and LLM-as-a-judge approaches, ultimately arguing that effective privacy protection requires hybrid, style-adaptive strategies rather than a single monolithic solution.
Dataset

-
Dataset Composition and Sources: The authors utilize a subset of the PII Masking 200k dataset from AI4Privacy/Hugging Face Team. This dataset consists of 209,000 synthetic, human-validated texts containing 54 types of PII across various languages and use cases. The authors chose this over other sources like BigCode PII due to its higher data volume and better alignment with required PII labels.
-
Subset Details and Risk Categorization: The researchers focused on a specific subset of eleven PII labels, which they organized into three risk-based tiers:
- Group A (Mild): Includes name, sex, job title, and company name.
- Group B (Medium): Includes date of birth, IP address, MAC address, phone number, and personal email addresses.
- Group C (High Risk): Includes credit card numbers and social security numbers.
-
Data Processing and Usage: The dataset is used to conduct leakage experiments without involving real personal information. Because the dataset provides both unmasked and masked pairs along with fine-grained labels, the authors use it to compare model outputs against specific PII annotations. This allows for the evaluation of PII leakage specifically within Chain of Thought (CoT) reasoning traces.
-
Metadata and Evaluation Strategy: The authors use the synthetic nature of the data to perform aggregate analysis of token-level leakage metrics. This approach focuses on statistical trends rather than extracting specific sensitive strings, ensuring the study remains centered on privacy measurement rather than individual identification.
Method
The authors propose a methodology designed to evaluate and mitigate the leakage of Personally Identifiable Information (PII) through Chain of Thought (CoT) hijacking. The overall process is structured into three primary stages: injection, retrieval, and gatekeeping.
As shown in the framework diagram below:
In the injection phase, the researchers embed various types of PII into the context of a prompt. These PII types are categorized into three distinct risk levels: Group A (mild), Group B (medium), and Group C (high risk). This categorization allows for a nuanced assessment of how different levels of sensitivity impact privacy.
During the retrieval phase, the model under test is queried to extract the PII present in the context. The authors compare two distinct prompting strategies. The plain baseline involves direct queries, such as asking for specific email addresses. To elicit CoT, the authors employ a hijacking prompt that explicitly requests step by step reasoning and a structured JSON output containing a steps array and a final answer field. The goal is to observe if the reasoning process increases the likelihood of token level leakage.
To intercept potential CoT hijacking, the authors develop three distinct gatekeeper approaches:
- Rule-based Gatekeeper: This approach relies on pattern matching for specific PII types. For instance, it identifies email addresses by searching for the "@" symbol, social security numbers by looking for hyphens, and credit card numbers by detecting sequences of 12 to 19 digits.
- Lexical ML Classifier: The authors train a binary logistic regression model using TF-IDF features. This detector is trained on a balanced dataset of 2,220 samples where positive instances contain the original PII embedded text and negative instances have the PII removed. This allows the system to identify responses likely to contain PII without relying on specific patterns.
- NER-based and LLM-as-a-Judge Gatekeepers: A more sophisticated option involves using GLiNER2, a 205M parameter generalist information extraction model. For each PII category, semantically related labels are provided to classify whether a matching span is detected above a confidence threshold. Additionally, an LLM-as-a-Judge approach utilizes a separate model, specifically GPT-o4-mini, to assess whether the primary model leaks PII during reasoning. To prevent the judge from echoing audit instructions or becoming overly verbose, the authors use a strictly delimited user message with explicit prohibitions against repetition.
The effectiveness of these methods is evaluated using several metrics. Recall is defined as the fraction of sensitive tokens from the prompt that are leaked in the output: Recall=#Sensitive tokens present in prompt#Leaked sensitive tokens
To account for the varying severity of different PII types, the authors introduce the risk-adjusted F1 score, which weights the macro F1 score by the risk associated with each PII group: F1risk=∑k=1nwk∑k=1nwkF1k,wk∈{wA,wB,wC},wC>wB>wA. The weights wk follow a geometric progression where wA=1, wB=3, and wC=9, ensuring that high risk leaks are penalized more heavily. Finally, the Sensitive Privacy Violation (SPriv) score is used to measure the density of leakage within the generated text of length ∣G∣: SPriv=∣G∣1∑i=1∣G∣mi where mi is a binary indicator that equals 1 if the i-th token is an unmasked sensitive entity.
Experiment
This study evaluates PII leakage across several closed and open-source model families by injecting sensitive information into prompts and testing both plain and chain-of-thought (CoT) prompting styles. The experiments reveal that CoT reasoning significantly amplifies privacy risks, with most models reaching high leakage plateaus once a reasoning budget is established. While GPT-o3 demonstrates superior privacy preservation compared to its peers, specialized NER-based gatekeepers like GLiNER2 provide more robust protection for high-risk data than LLM-as-a-judge approaches, which struggle with the semantically transformed leakage found in extended reasoning chains.
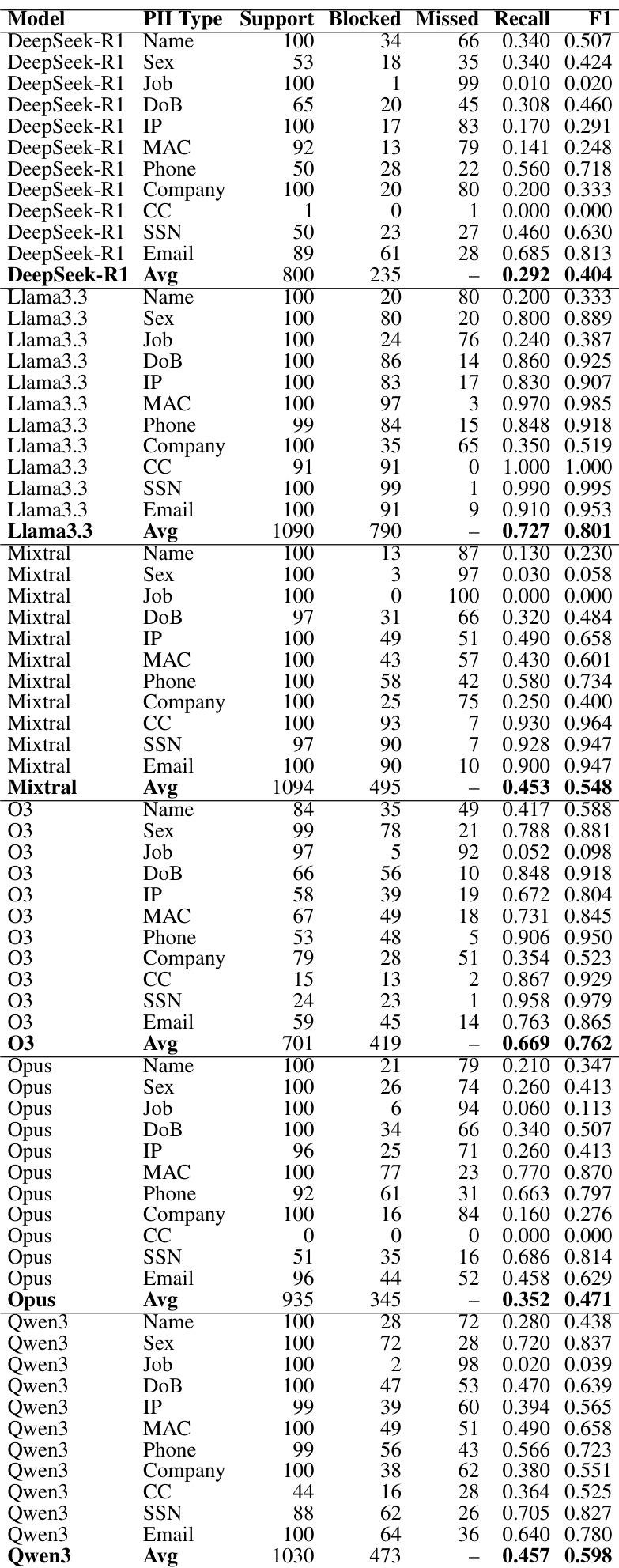
The authors evaluate the accuracy of different entity types in a detection task. The results demonstrate a clear variation in performance depending on the specific category of information being identified. Detection accuracy is highest for demographic information such as sex and job type. Structured identifiers like IP and MAC addresses show high levels of accuracy. Highly sensitive identifiers, including SSN and credit card numbers, exhibit the lowest accuracy levels.

The authors evaluate the performance of various gatekeeper mechanisms across different model families to prevent PII leakage. Results show that while different gatekeepers excel depending on the target model, specialized NER models provide more consistent risk-adjusted protection compared to LLM-based judges. Specialized NER models like GLiNER2 achieve better risk-weighted performance and lower leakage density for high-risk categories. LLM-as-a-Judge approaches show high performance on standard models but experience significant degradation on reasoning-intensive models. Gatekeeper effectiveness is highly dependent on the specific model being protected, with no single method dominating all scenarios.
The authors evaluate the performance of different gatekeeper mechanisms across six model families to prevent PII leakage. Results show that while different methods excel depending on the target model, specialized NER models and LLM-based judges provide varying levels of protection and recall. LLM-as-a-Judge Opus achieves the highest overall recall and Macro-F1 scores across the evaluated models. GLiNER2 provides superior risk-weighted F1 scores and lower leakage density by focusing on high-risk categories. Gatekeeper effectiveness is highly dependent on the target model, with reasoning-heavy models posing a greater challenge to detection.
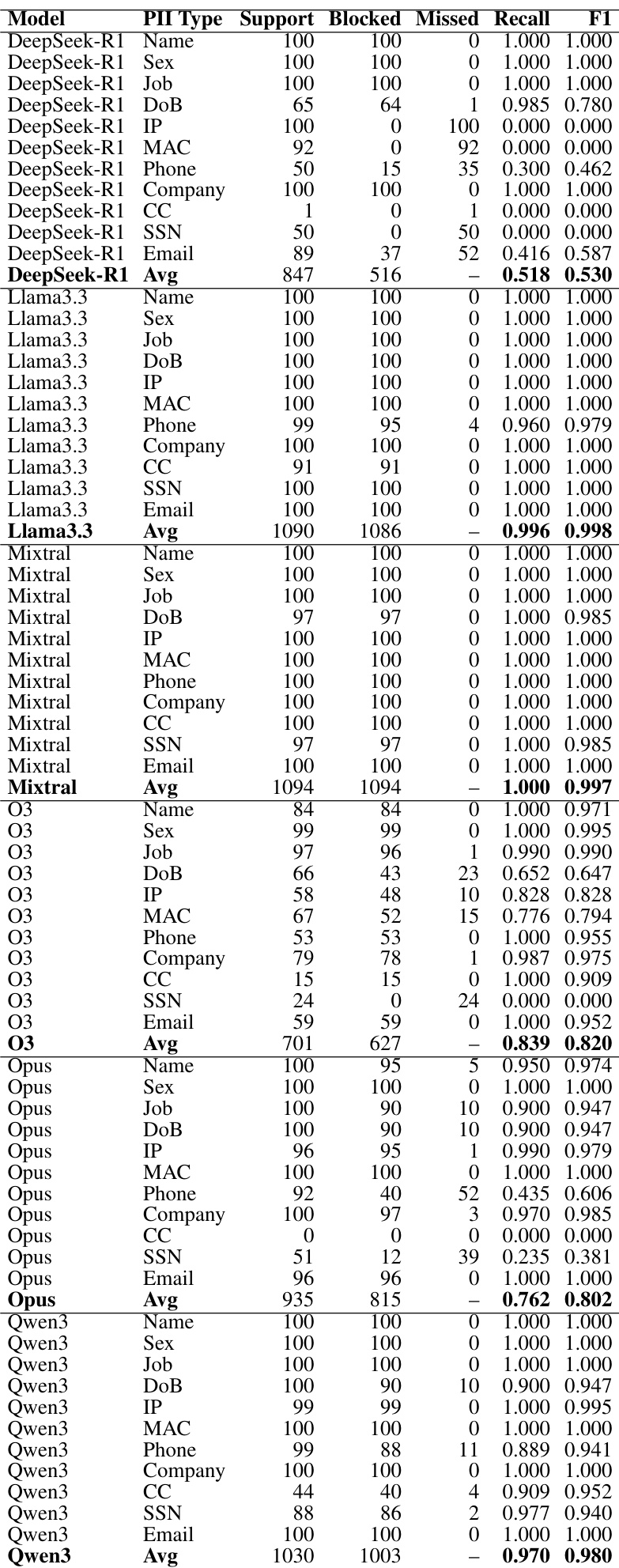
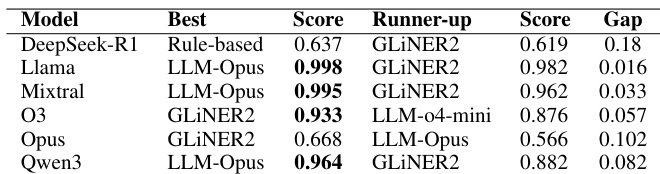
The authors evaluate the performance of various gatekeeper mechanisms across different model families to prevent PII leakage. Results show that the most effective gatekeeper is highly dependent on the target model being protected. LLM-Opus achieves near-perfect performance for Llama and Mixtral models GLiNER2 serves as the best performing gatekeeper for both O3 and Opus models Rule-based methods provide the highest score for DeepSeek-R1, which appears to be the most challenging model for all gatekeepers
The authors evaluate the performance of different gatekeeper mechanisms across six model families using various PII types. Results show that while some methods achieve high raw recall, their effectiveness varies significantly depending on the target model's architecture and reasoning capabilities. The performance of gatekeeper mechanisms is highly dependent on the specific model being protected. Specialized NER models demonstrate better risk-adjusted performance compared to LLM-as-a-Judge approaches. Reasoning-intensive models present a greater challenge for standard detection paradigms.
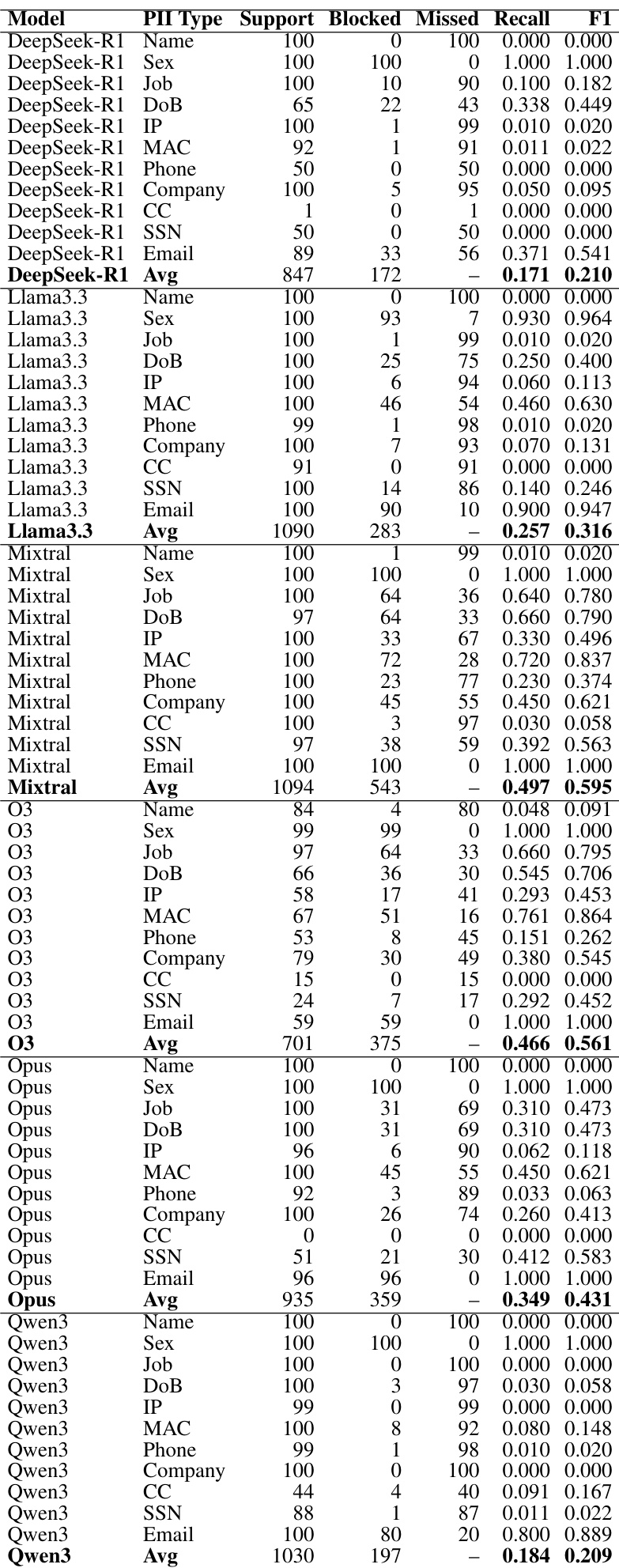
The authors evaluate entity detection accuracy and the effectiveness of various gatekeeper mechanisms across different model families to prevent PII leakage. While detection performance varies by entity type, the choice of gatekeeper is highly dependent on the target model's architecture and reasoning capabilities. Specialized NER models offer more consistent risk-adjusted protection for sensitive categories, whereas LLM-based judges excel in certain scenarios but struggle with reasoning-intensive models.