Command Palette
Search for a command to run...
SURvHTE-Bench: 생존 분석에서의 이질적 처치 효과 추정(Heterogeneous Treatment Effect Estimation)을 위한 벤치마크
SURvHTE-Bench: 생존 분석에서의 이질적 처치 효과 추정(Heterogeneous Treatment Effect Estimation)을 위한 벤치마크
Shahrriar Noroozizadeh Xiaobin Shen Jeremy C. Weiss George H. Chen
초록
우측 검측(right-censored)된 생존 데이터로부터 이질적 처치 효과(Heterogeneous Treatment Effects, HTEs)를 추정하는 것은 정밀 의료 및 개별화된 정책 수립과 같이 리스크가 큰 분야에서 매우 중요합니다. 그러나 생존 분석 환경은 검측(censoring), 관찰되지 않은 반사실(unobserved counterfactuals), 그리고 복잡한 식별 가정(identification assumptions)으로 인해 HTE 추정에 있어 독특한 난제들을 제기합니다. 최근 Causal Survival Forests부터 survival meta-learners 및 outcome imputation 방식에 이르기까지 기술적 진보가 이루어졌음에도 불구하고, 평가 관행은 여전히 파편화되어 있으며 일관되지 않은 상태입니다.본 논문에서는 검측된 결과(censored outcomes)를 가진 HTE 추정을 위한 최초의 종합적 벤치마크인 SURVHTE-BENCH를 소개합니다. 이 벤치마크는 다음을 포함합니다: (i) 인과적 가정과 생존 역학(survival dynamics)을 체계적으로 변화시키며 정답(ground truth)을 알고 있는 모듈형 합성 데이터셋 세트, (ii) 실제 공변량(covariates)과 시뮬레이션된 처치 및 결과(treatments and outcomes)를 결합한 준합성(semi-synthetic) 데이터셋, (iii) 정답을 알고 있는 쌍둥이 연구(twin study) 및 HIV 임상 시험에서 추출한 실제 데이터셋.합성, 준합성 및 실제 환경 전반에 걸쳐, 본 연구는 다양한 조건과 현실적인 가정 위반(assumption violations) 상황 하에서 생존 HTE 방법론들에 대한 최초의 엄격한 비교를 제공합니다. SURVHTE-BENCH는 인과적 생존(causal survival) 방법론에 대한 공정하고 재현 가능하며 확장 가능한 평가를 위한 토대를 마련합니다.
One-sentence Summary
To facilitate fair and reproducible evaluation, the authors introduce SURvHTE-Bench, the first comprehensive benchmark for heterogeneous treatment effect estimation in survival analysis, which utilizes synthetic, semi-synthetic, and real-world datasets to rigorously compare causal survival methods under diverse censoring conditions and complex identification assumptions.
Key Contributions
- The paper introduces SURVHTE-BENCH, the first comprehensive benchmark designed specifically for evaluating heterogeneous treatment effect estimation within censored survival data settings.
- This benchmark provides a modular suite of synthetic datasets with known ground truth, semi-synthetic datasets combining real-world covariates with simulated outcomes, and real-world datasets from a twin study and an HIV clinical trial.
- The work delivers the first rigorous comparison of survival HTE methods across diverse conditions and realistic assumption violations, establishing a foundation for reproducible and extensible evaluation of causal survival methods.
Introduction
Estimating heterogeneous treatment effects (HTEs) from right-censored survival data is essential for high-stakes fields like precision medicine and individualized policy-making. However, the presence of censoring and unobserved counterfactuals complicates identification and estimation. While various causal survival methods have emerged, evaluation practices remain fragmented because researchers often rely on bespoke simulations or limited datasets with unknown ground truth. This lack of standardization makes it difficult to compare the robustness of different estimators or measure methodological progress. The authors introduce SURVHTE-BENCH, the first comprehensive benchmark designed to provide a fair and reproducible evaluation of survival HTE estimation. The benchmark features a modular implementation of 53 methods across three algorithmic families and includes a diverse suite of synthetic, semi-synthetic, and real-world datasets to test estimator performance under realistic assumption violations.
Dataset
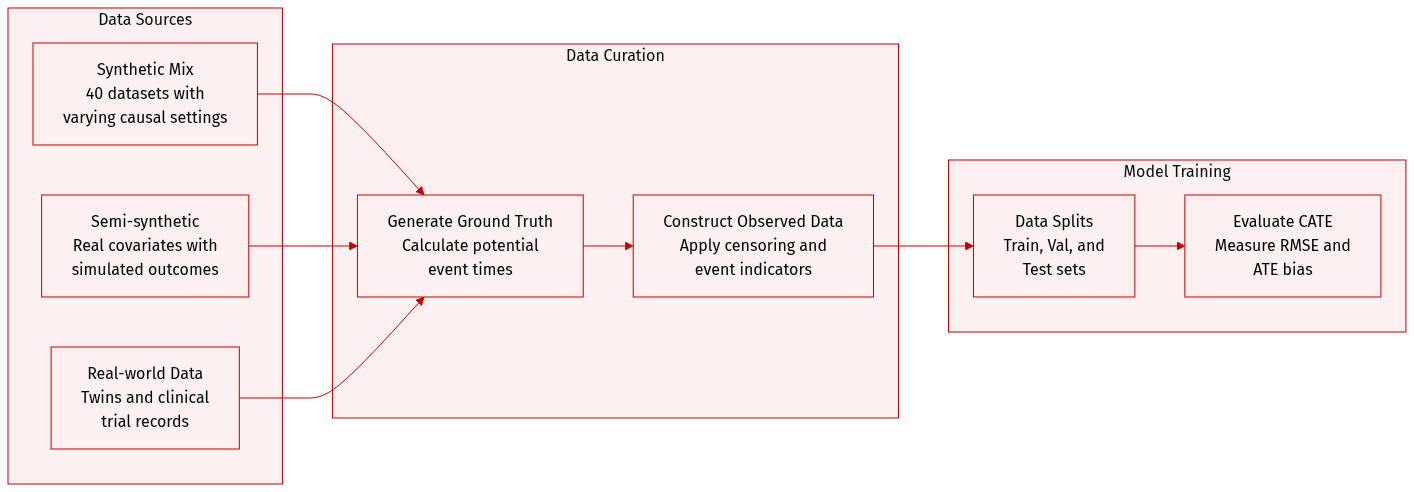
The authors introduce SURVHTE-BENCH, a modular benchmark designed to evaluate survival Conditional Average Treatment Effect (CATE) estimators across various causal and survival settings. The dataset is composed of three main categories:
- Synthetic Datasets: A suite of 40 datasets created by crossing 8 causal configurations with 5 survival scenarios.
- Causal Configurations: These include Randomized Controlled Trials (RCT) and Observational Studies (OBS) that test violations of ignorability (unobserved confounding), positivity (lack of positivity), and ignorable censoring (informative censoring).
- Survival Scenarios: These include Cox proportional hazards, Accelerated Failure Time (AFT) models, and Poisson hazard models, with censoring rates ranging from low (under 30%) to high (over 70%).
- Details: Each dataset contains up to 50,000 units with five independent Uniform(0, 1) covariates and binary, time-fixed treatments.
- Semi-synthetic Datasets: 10 datasets that pair real-world covariates with simulated treatments and outcomes to maintain realistic feature distributions while providing ground-truth CATEs.
- ACTG HIV Trial: Uses 23 baseline covariates from the ACTG 175 trial, simulating covariate-dependent treatment and Gompertz-Cox event times.
- MIMIC-IV ICU Records: A suite of nine datasets using 36 covariates. This includes a subset (MIMIC-i-v) with independent treatment assignment to test censoring severity (53% to 88% censoring) and a subset (MIMIC-vi-ix) with confounded assignment to test non-linear functional forms.
- Real-world Datasets:
- Twins Dataset: Focuses on twin births in the USA. The authors use the sibling as a counterfactual to create an observational dataset with known ground truth. It includes over 11,000 twin pairs with 43 feature dimensions.
- ACTG 175: A real-world clinical trial dataset used for evaluation without ground truth.
Data Processing and Usage
- Processing: For synthetic and semi-synthetic data, the authors generate potential event times T(0) and T(1) to ensure ground-truth CATEs are known. Observed data is constructed by taking the minimum of event and censoring times.
- Evaluation Strategy: The authors evaluate models using CATE RMSE, ATE bias, and auxiliary metrics like imputation accuracy and survival model fit. For the Twins dataset, they utilize a 50/25/25 training, validation, and testing split.
- Target Estimand: The benchmark focuses on the Restricted Mean Survival Time (RMST) up to a user-specified time horizon h. For Poisson-distributed event times, they compute ground-truth survival probabilities at the 25th, 50th, and 75th percentiles of the realized event-time distribution.
Method
The authors evaluate a diverse range of causal inference methods for survival analysis, which can be broadly categorized into three distinct paradigms: outcome imputation methods, direct-survival CATE models, and survival meta-learners.
Outcome Imputation Methods
The first approach transforms right-censored survival data into a standard regression problem by imputing surrogate event times for censored subjects. The authors implement three specific imputation strategies to estimate the true event time T when only the observed time Y=min(T,C) and censoring indicator δ are available.
-
Margin Imputation: This method uses the nonparametric Kaplan-Meier estimator to assign a "best guess" value, interpreted as the conditional expectation of the event time given that the event occurs after the censoring time ti: T~imargin=E[Ti∣Ti>ti]=ti+SKM(D)(ti)∫ti∞SKM(D)(t)dt
-
IPCW-T Imputation: This strategy imputes the event time by averaging the observed event times of all uncensored subjects who experienced their event after the subject i was censored: T~iIPCW=∑i=1N1{ti<tj}⋅1{δj=1}∑j=1N1{ti<tj}⋅1{δj=1}⋅tj
-
Pseudo-observation Imputation: This method estimates the individual contribution of subject i to an overall unbiased estimator θ^ of the mean event time. The pseudo-observation is defined as: T~ipseudo=ϵPseudo−Obs(ti,D)=N⋅θ^−(N−1)⋅θ^−i where θ^ and θ^−i are computed using the mean of the Kaplan-Meier survival curve.
Once the survival outcomes are converted into continuous imputed values, standard meta-learners such as the T-Learner, S-Learner, X-Learner, DR-Learner, Double-ML, and Causal Forest can be applied.
Direct-Survival CATE Methods
Alternatively, the authors examine methods that handle censored observations natively without the need for imputation.
Causal Survival Forests (CSF) extend the Causal Forest framework by incorporating doubly robust estimating equations. The process involves estimating nuisance components (propensity scores, outcome regression, and censoring survival functions) and constructing a forest where trees are grown using a causal splitting criterion that targets variation in doubly robust scores. For a target point x, the CATE is estimated by solving: ∑α(x)ψτ^(x)(X,y(U),U∧h,W,Δh;e^,m^,S^wC,Q^w)=0
SurvITE utilizes representation learning to address selection bias. It maps covariates X to a latent representation Φ(X) while minimizing an Integral Probability Metric (IPM) to balance treated and control distributions. Simultaneously, it minimizes a factual loss function Lsurv using treatment-specific heads h1 and h0: Φ,h0,h1min∑i=1NwiLsurv(hWi(Φ(xi)),Ti,Δi)+α⋅IPM
Survival Meta-Learners
The final category consists of survival-specific adaptations of meta-learning frameworks. These methods operate directly on survival distributions, often using the Restricted Mean Survival Time (RMST) as the target metric.
The T-Learner-Survival and S-Learner-Survival fit separate or unified survival models to estimate the survival functions S0(u∣x) and S1(u∣x). The CATE is then derived from the difference in their respective RMSTs: μ(x,w)=∫0hS(u∣x,w)du
Finally, Matching-Survival estimates the CATE by identifying K nearest neighbors from the opposite treatment group to impute the counterfactual RMST, thereby making minimal modeling assumptions beyond local similarity.
Experiment
The evaluation utilizes synthetic, semi-synthetic, and real-world datasets to benchmark 53 estimator variants across diverse causal configurations and survival scenarios. The experiments validate how different method families, specifically outcome imputation, direct-survival models, and survival meta-learners, respond to varying censoring rates and violations of causal assumptions like ignorability and positivity. Findings indicate that while outcome imputation methods excel in low-censoring randomized settings, survival-aware models demonstrate superior robustness and stability as censoring intensifies or when multiple causal assumptions are violated.
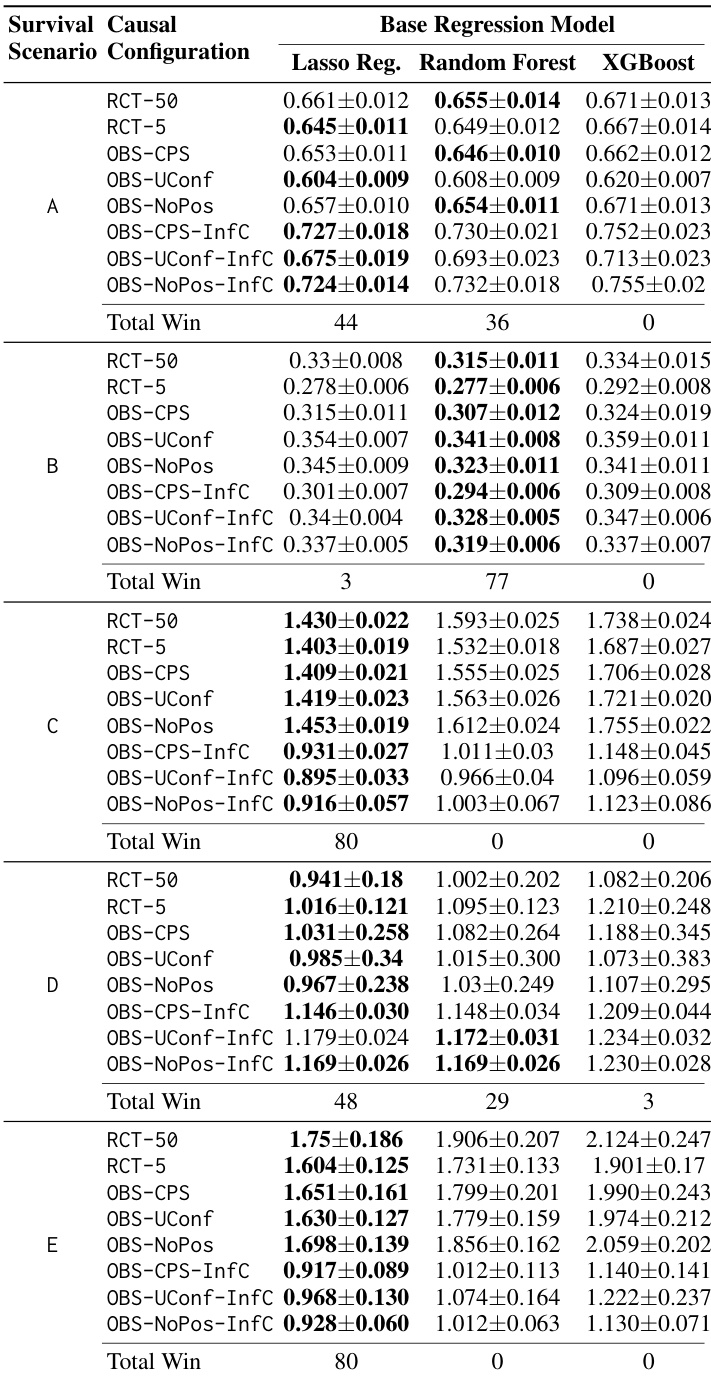
The the the table presents the performance of three base regression models across five survival scenarios and various causal configurations. Results are reported as mean error with standard deviation, showing how model accuracy fluctuates depending on censoring levels and assumption violations. Lasso Regression frequently achieves lower error rates compared to Random Forest and XGBoost across several scenarios, particularly in Scenario C and Scenario E. Performance varies significantly by survival scenario, with error levels being notably lower in Scenario B compared to the higher error observed in Scenario D. The impact of causal configurations on error is evident, as models often show different stability and accuracy levels when moving from randomized trials to observational settings with informative censoring.
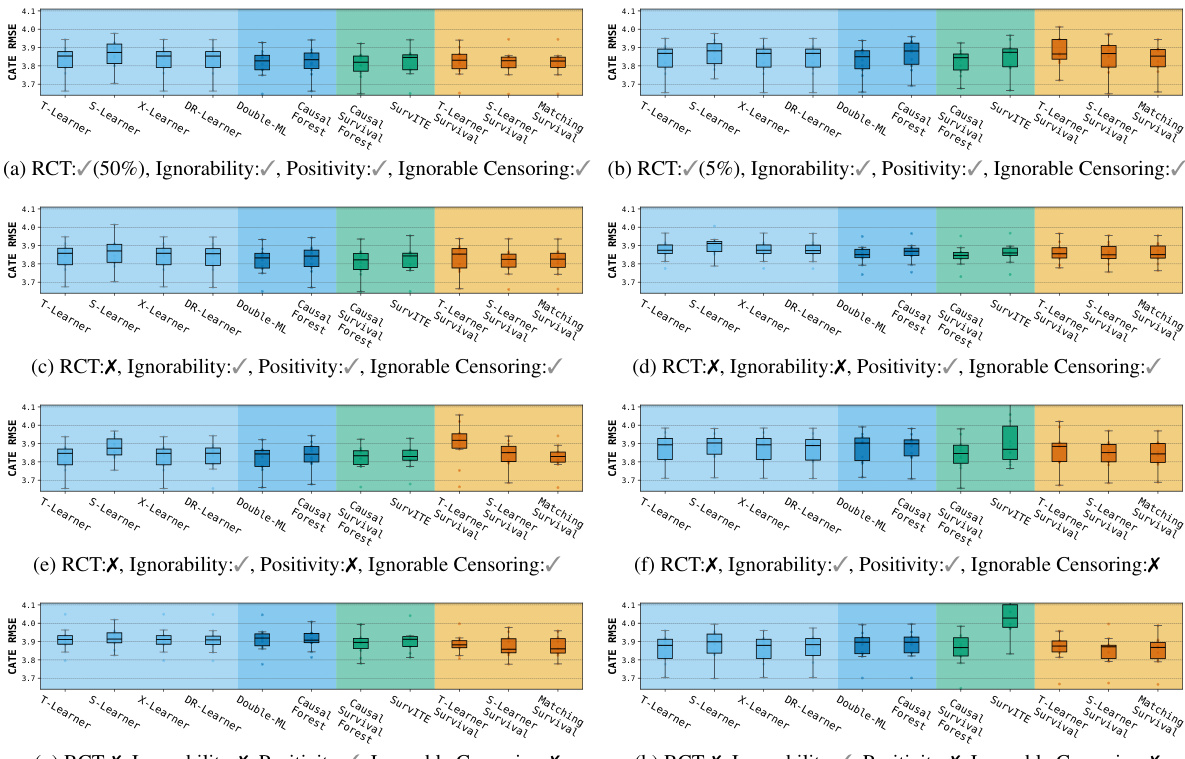
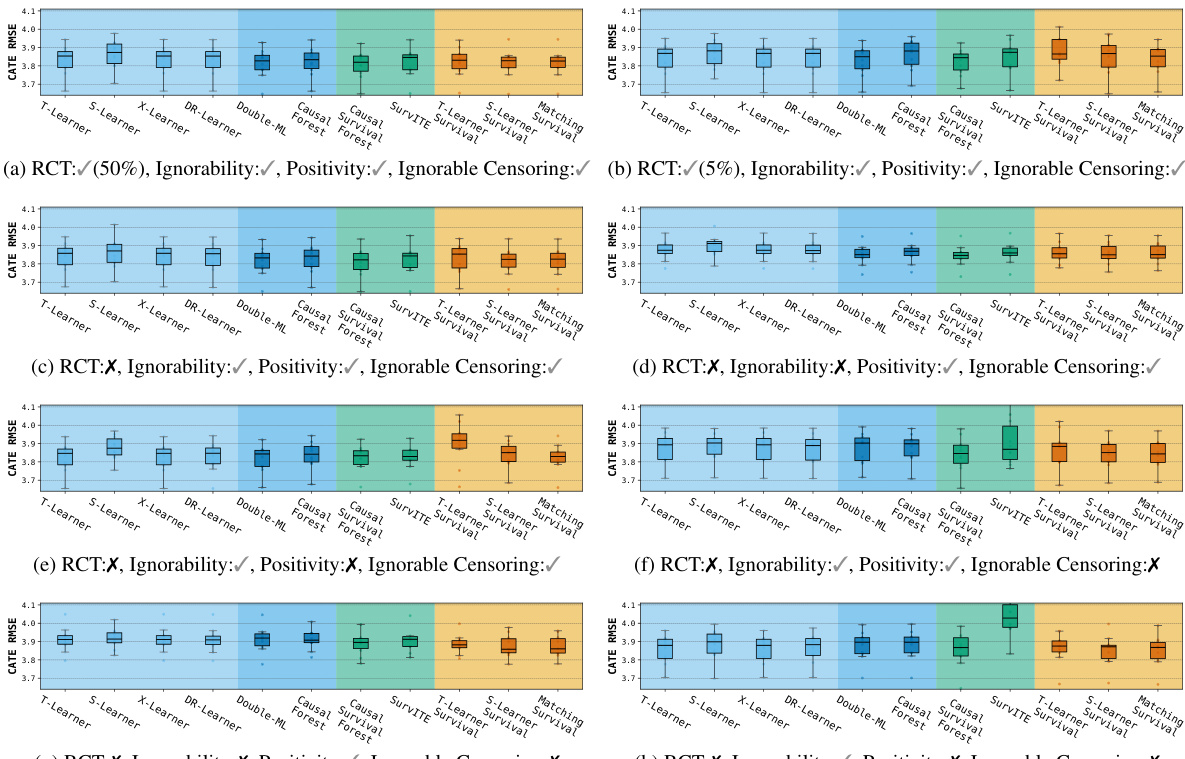
The results evaluate CATE RMSE across various causal configurations, including randomized controlled trials and observational settings with different assumption violations. The performance of estimator families shifts significantly depending on whether the data follows randomized or observational patterns and how causal assumptions like ignorability and positivity are met. Outcome imputation methods like Double-ML and X-Learner perform well in randomized settings with balanced treatment assignment. Survival meta-learners and direct-survival models show increased robustness when faced with multiple simultaneous violations of causal assumptions. Estimator performance is highly sensitive to the specific causal configuration, particularly under conditions of unmeasured confounding or informative censoring.
The the the table presents the win-rate percentages for method families across various survival scenarios and causal configurations. It illustrates how different data-generating processes and assumption violations influence the frequency with which specific method families achieve top-tier performance. Performance metrics vary significantly depending on whether the setting is a randomized controlled trial or an observational study. Certain causal configurations, such as those involving unmeasured confounding, show distinct patterns of success for different method families. The introduction of informative censoring affects the win-rate distribution across the different survival scenarios.
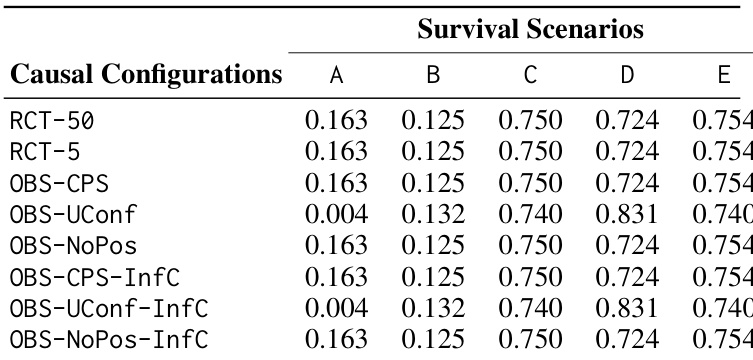
The the the table presents the total win counts for different causal estimation methods across various survival scenarios and causal configurations. It compares the performance of base regression models, specifically Random Survival Forest (RSF), DeepSurv, and DeepHit, between treated and control groups. In scenario B, the total win counts for the treated group are distributed among the three base models, with RSF and DeepHit showing higher counts than DeepSurv. Scenario C shows a significant concentration of wins for the DeepSurv model in the treated group, while the control group wins are more evenly distributed among the three models. Across scenarios A, D, and E, the distribution of wins for the control group varies, with some scenarios showing a strong preference for the RSF model and others showing more balanced results among the three base learners.
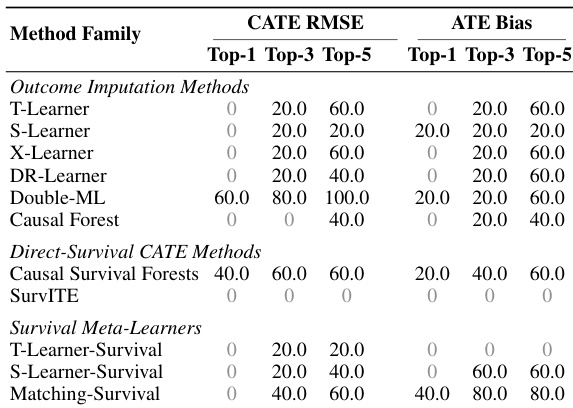
The the the table summarizes the win-rate percentages for different method families across various experimental configurations, categorized by CATE RMSE and ATE Bias. It shows how frequently each family appears in the top-1, top-3, and top-5 rankings. Double-ML is a dominant performer in CATE RMSE, achieving the highest top-1 frequency among all listed families. Survival meta-learners, particularly Matching-Survival, show strong consistency in ATE Bias rankings, frequently appearing in the top-3 and top-5. Direct-survival methods like Causal Survival Forests maintain competitive presence across both CATE RMSE and ATE Bias metrics.
These experiments evaluate the performance of various regression models, meta-learners, and direct-survival methods across diverse survival scenarios and causal configurations, including randomized trials and observational settings with assumption violations. The results demonstrate that estimator accuracy and stability are highly sensitive to data-generating processes such as informative censoring and unmeasured confounding. While Double-ML shows dominance in minimizing CATE error, survival meta-learners and direct-survival models offer increased robustness and consistency when facing complex violations of causal assumptions.