Command Palette
Search for a command to run...
모델을 신뢰하라: 분산 기반 신뢰도 보정
모델을 신뢰하라: 분산 기반 신뢰도 보정
Xizhong Yang Haotian Zhang Huiming Wang Mofei Song
초록
대규모 추론 모델들은 테스트 시간 확장(test-time scaling) 기법의 발전과 함께 뛰어난 성능을 보여주고 있습니다. 해당 기법은 여러 후보 응답을 생성한 후 가장 신뢰할 수 있는 답변을 선택함으로써 예측 정확도를 향상시킵니다. 기존 연구들은 신뢰도 점수(confidence scores)와 같은 내부 모델 신호가 응답의 정확성을 부분적으로 나타낼 수 있으며, 정확도와 분포적 상관관계(distributional correlation)를 보인다고 분석하였습니다. 그러나 이러한 분포 정보를 정답 선택을 안내하는 데 완전히 활용하지는 못했습니다. 이에 착안하여, 본 논문은 투표(voting) 과정에서 신뢰도 신호와 함께 분포적 사전 정보(distributional priors)를 추가 신호로 통합하는 'DistriVoting'을 제안합니다. 구체적으로, 본 방법은 (1) 가우시안 혼합 모델(Gaussian Mixture Models)을 활용하여 혼합된 신뢰도 분포를 긍정 및 부정 구성 요소로 먼저 분해한 후, (2) 해당 구성 요소에서 추출된 긍정/부정 샘플에 기반한 거절 필터(reject filter)를 적용하여 두 분포 간의 중첩을 완화합니다. 또한, 분포 자체의 관점에서 중첩을 더욱 경감하기 위해 'SelfStepConf'를 제안합니다. 이는 단계별 신뢰도(step-level confidence)를 활용하여 추론 과정을 동적으로 조정함으로써 두 분포 간의 분리도를 높이고, 투표 시 신뢰도의 신뢰성을 향상시킵니다. 16 개의 모델과 5 개의 벤치마크에 걸친 실험 결과, 제안된 방법이 최신 기법들(state-of-the-art approaches)보다 현저히 우수한 성능을 입증하였습니다.
One-sentence Summary
Researchers from Southeast University and Kuaishou Technology propose DistriVoting, a novel framework that enhances Large Reasoning Models by integrating distributional priors with confidence scores. By decomposing confidence distributions and introducing SelfStepConf for dynamic inference adjustment, this method significantly improves answer selection reliability across diverse benchmarks compared to existing state-of-the-art approaches.
Key Contributions
- Large Reasoning Models struggle to evaluate answer quality during test-time scaling due to a lack of external reward signals, leaving distributional correlations between confidence scores and correctness underutilized for answer selection.
- The proposed DistriVoting method decomposes mixed confidence distributions into positive and negative components using Gaussian Mixture Models and applies a reject filter to mitigate overlap, while SelfStepConf dynamically adjusts the inference process using step-level confidence to further separate these distributions.
- Experiments across 16 models and 5 benchmarks, including HMMT2025 and AIME, demonstrate that this approach significantly outperforms state-of-the-art methods by improving the reliability of confidence-based voting.
Introduction
Large Reasoning Models rely on test-time scaling to generate multiple candidate answers, yet selecting the most accurate response remains difficult due to the absence of external labels during inference. While prior methods utilize internal confidence scores to guide this selection, they often fail to fully exploit the distinct statistical distributions that separate correct answers from incorrect ones, leading to significant overlap between high-confidence errors and low-confidence correct responses. To address this, the authors propose DistriVoting, a method that decomposes confidence distributions into positive and negative components using Gaussian Mixture Models to filter out unreliable samples before voting. They further introduce SelfStepConf, which dynamically adjusts the inference process using step-level confidence to increase the separation between correct and incorrect distributions, thereby significantly improving answer selection accuracy across various models and benchmarks.
Method
The proposed framework consists of two primary components: SelfStepConf (SSC) for dynamic confidence adjustment during inference, and DistriVoting for post-inference trajectory filtering and aggregation.
SelfStepConf (SSC) The authors leverage token negative log-probabilities to assess trajectory quality in real-time. For a trajectory containing N tokens, the trajectory confidence Ctraj is defined as the average negative log-probability of the top-k tokens in the final answer segment:
Ctraj=−NG×k1i∈G∑j=1∑klogPi(j)where G represents the subset of tokens used for confidence computation. During inference, the system monitors step-wise confidence CGm. If the relative change Δconf falls below a threshold δ and the confidence is declining, the system triggers self-reflection. This involves injecting reflection tokens by swapping the highest-probability token's probability with that of a reflection token, effectively forcing the model to reconsider its reasoning path without disrupting the confidence calculation mechanism.
DistriVoting Following inference, the method employs a distribution-based voting strategy to select the final answer from the generated trajectories. This process involves modeling the confidence distribution, filtering out low-quality samples, and performing hierarchical voting.
The core of this pipeline involves modeling the confidence scores of the sampled trajectories as a mixture of two Gaussian distributions, representing positive (correct) and negative (incorrect) reasoning paths. The authors apply a Gaussian Mixture Model (GMM) to approximate this bimodal distribution:
p(x)=π1N(x∣μ1,σ12)+π2N(x∣μ2,σ22)where π1 and π2 are mixing weights. The component with the higher mean is mapped to the positive distribution, while the lower mean corresponds to the negative distribution.
As shown in the figure below:
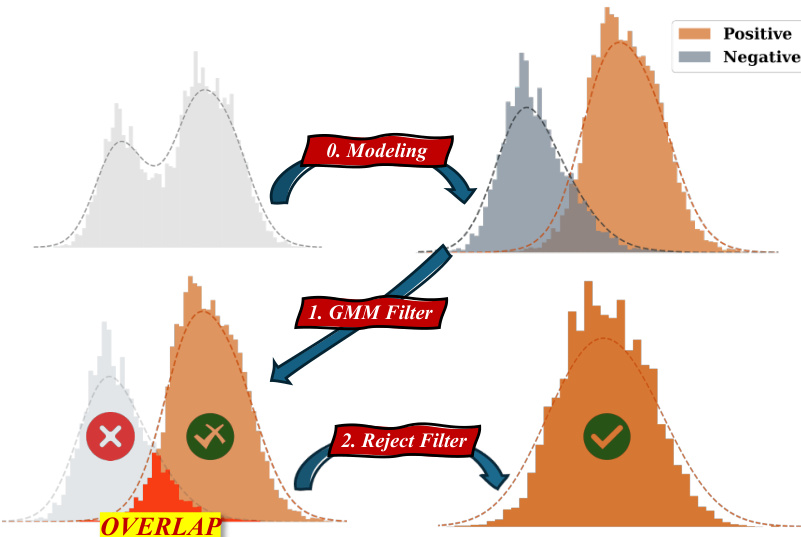
The framework proceeds through three distinct stages illustrated in the diagram. First, in the Modeling stage, the raw confidence histograms are fitted to the GMM components. Second, the GMM Filter separates the trajectories into potentially correct (Vpos) and potentially incorrect (Vneg) sets based on the fitted distributions. However, significant overlap often exists between these distributions. To address this, the Reject Filter stage utilizes the negative set to identify and eliminate false positive samples from the candidate pool. Specifically, the method identifies the most likely incorrect answer from the negative set and removes trajectories from the positive set that align with this incorrect answer, thereby refining the candidate pool V^pos.
Finally, the method employs Hierarchical Voting (HierVoting) on the refined positive pool. The confidence scores are divided into NC sub-intervals. Within each interval, a weighted majority voting is performed to select a sub-answer. These sub-answers are then aggregated using a final weighted majority vote to determine the final answer Afinal. This hierarchical approach compensates for potential performance deficiencies in the filtering stages by leveraging confidence intervals to ensure robust voting.
Experiment
- DistriVoting and SelfStepConf (SSC) are validated as superior to existing test-time scaling methods like Self-Consistency and Best-of-N, demonstrating that distribution-aware voting and enhanced confidence differentiation significantly improve reasoning accuracy.
- The adaptive GMM Filter consistently outperforms fixed Top-50 filtering by effectively modeling the bimodal distribution of correct and incorrect trajectories, leading to higher quality candidate pools for voting.
- SSC enhances voting performance by increasing the separation between confidence distributions of correct and incorrect samples, which improves the reliability of the filtering process without expanding the model's fundamental reasoning limits.
- Ablation studies confirm that the GMM Filter is the most critical component of DistriVoting, while the Reject Filter provides additional gains only when built upon a robust distribution split.
- The proposed methods show robustness across various model sizes and budgets, with performance gains becoming more pronounced as sample sizes increase to provide reliable distributional information.
- Step splitting using paragraph-level delimiters and reflection triggers based on confidence drops are identified as effective strategies for maintaining logical integrity and improving trajectory quality during inference.