Command Palette
Search for a command to run...
Proact-VL: 실시간 AI 동반자를 위한 능동적 VideoLLM
Proact-VL: 실시간 AI 동반자를 위한 능동적 VideoLLM
Weicai Yan Yuhong Dai Qi Ran Haodong Li Wang Lin Hao Liao Xing Xie Tao Jin Jianxun Lian
초록
인간과 유사한 AI 동반자를 구현하기 위해서는 능동적이고 실시간 상호작용 경험이 필수적이지만, 다음과 같은 세 가지 주요 과제가 존재합니다: (1) 지속적인 스트리밍 입력 하에서 저지연 추론 달성, (2) 응답 시점을 자율적으로 결정하는 능력, (3) 실시간 제약 조건을 충족시키기 위해 생성된 콘텐츠의 품질과 양을 동시에 제어하는 것. 본 연구에서는 자동 평가에 적합하도록 선정된 두 가지 게임 시나리오, 즉 해설자(guide)와 가이드(commentator)를 통해 AI 동반자를 구체화하였습니다. 또한 세 가지 대표 시나리오(단독 해설, 공동 해설, 사용자 가이드)를 포함하는 대규모 데이터셋인 'Live Gaming Benchmark'를 소개하고, 다중 모달 언어 모델을 인간과 유사한 환경 인식 및 상호작용이 가능한 능동적 실시간 상호작용 에이전트로 전환하는 범용 프레임워크인 'Proact-VL'을 제안합니다. 광범위한 실험 결과, Proact-VL 은 뛰어난 응답 지연 시간과 품질을 달성하면서도 강력한 비디오 이해 능력을 유지함으로써 실시간 상호작용 응용 분야에서의 실용성을 입증하였습니다.
One-sentence Summary
Yan, Dai, and colleagues from multiple institutions introduce Proact-VL, a framework transforming multimodal models into proactive agents for real-time gaming commentary and guidance. By addressing latency and autonomous response challenges, this approach outperforms prior methods in the new Live Gaming Benchmark, enabling human-like interactive AI companions.
Key Contributions
- Addressing the challenges of low-latency inference and autonomous response timing in continuous streaming inputs, the authors introduce the Live Gaming Benchmark, a large-scale dataset covering solo commentary, co-commentary, and user guidance scenarios.
- The paper presents Proact-VL, a general framework that shapes multimodal language models into proactive agents by combining a chunk-wise input-output schema with a lightweight mechanism to autonomously decide when to respond.
- Extensive experiments demonstrate that Proact-VL achieves superior response latency and quality while maintaining strong video understanding capabilities, outperforming existing methods on metrics like TimeDiff and F1.
Introduction
Creating human-like AI companions for real-time video streams requires balancing low-latency inference with the ability to autonomously decide when to speak and how much to say. Prior approaches struggle to achieve this balance, as proactive models often generate lengthy responses with high latency while real-time systems lack control over speaking behavior, leading to either excessive talking or disruptive silence. To address these issues, the authors introduce Proact-VL, a framework that combines chunk-wise video processing with a lightweight mechanism for autonomous response timing and a multi-tier loss function for stable training. This system enables AI agents to deliver short, continuous, and context-aware commentary in gaming scenarios while maintaining strong video understanding capabilities.
Dataset
Live Gaming Dataset Overview
The authors curate a specialized multimodal dataset designed to train proactive AI companions for live video game commentary and guidance.
-
Dataset Composition and Sources The core collection consists of 561 hours of high-quality English commentary footage spanning 12 blockbuster game titles across various genres. The authors source this data from YouTube, prioritizing professional tournament broadcasts and expert influencer channels to ensure high narrative density and linguistic coherence. All videos are archived at 420p resolution to balance visual fidelity with streaming efficiency.
-
Key Details for Each Subset
- Training Set: Covers 10 specific games (including Cyberpunk 2077, League of Legends, and Minecraft) and incorporates two general streaming datasets (LiveCC and Ego4D), totaling 128,000 samples.
- Live Gaming Benchmark: A clip-level test suite containing 3,014 samples. It includes an in-domain subset of 2,640 clips from 10 games and a common-and-general subset with 134 samples from Ego4D and 240 clips from an out-of-domain game.
- Live Gaming Benchmark-Streaming: A long-horizon evaluation set comprising 10 full-length videos (ranging from 30 minutes to 2 hours) selected from both solo and co-commentary settings.
-
Data Usage and Splitting Strategy The authors employ a video-wise split for the 10 training games, allocating 80% of videos for training, 10% for testing, and reserving 10% for future use. For training, videos are segmented into 36-second clips with an 18-second overlap, while Minecraft data also includes 60-second variants. The benchmark subsets are stratified by response rate (0–30%, 30–70%, and 70–100%) to ensure diverse evaluation scenarios.
-
Processing and Metadata Construction
- Speech Processing: The pipeline uses WhisperX-large-v3 for automatic speech recognition and speaker identification, followed by a frequency-based filter to remove non-human sounds like background music.
- Refinement and Labeling: Qwen3-Omni-Flash labels paralinguistic nuances such as pauses and laughter, while DeepSeek-V3.2-Exp polishes transcripts to correct domain-specific terminology and filter offensive content.
- Temporal Alignment: To enable per-second supervision, the authors convert segment-level captions into second-level sequences by distributing words evenly across time bins and appending ellipsis suffixes to indicate ongoing utterances.
- Prompt Engineering: System prompts are randomized during training to include game-specific roles, mined personas, and task templates for solo commentary, co-commentary, or guidance scenarios.
Method
The Proact-VL framework is designed to facilitate real-time video understanding and interaction across two primary gaming domains: live commentary and proactive user guidance. As illustrated in the overview diagram, the system supports diverse scenarios ranging from competitive esports analysis to instructional assistance in sandbox environments.
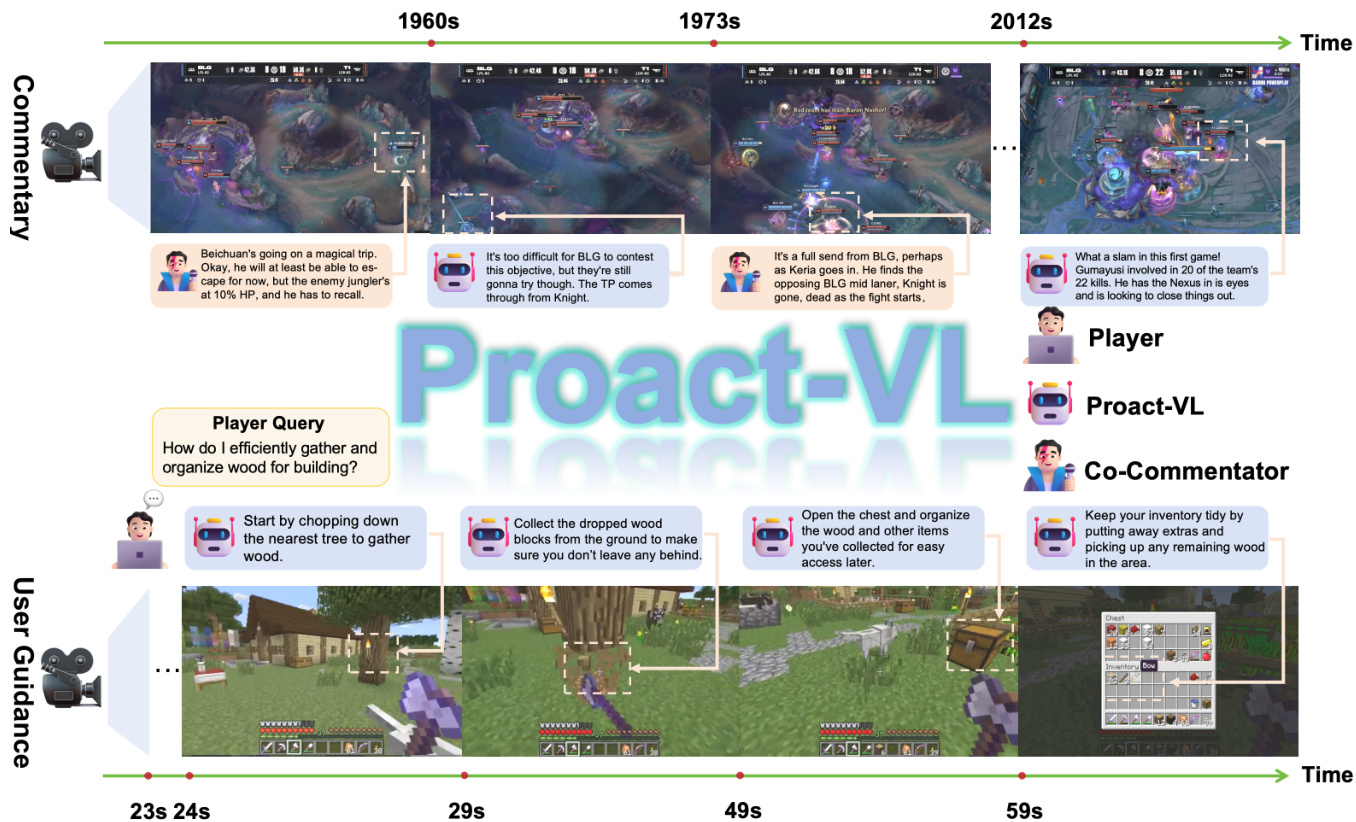
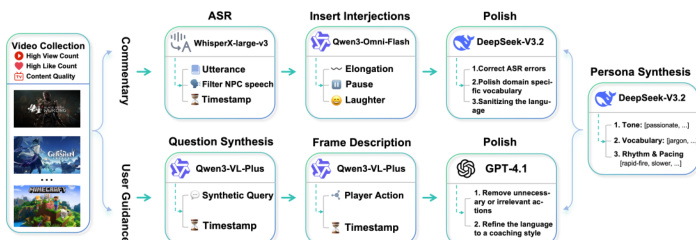
To enable this versatility, the authors employ a comprehensive data synthesis pipeline. The process begins with video collection, followed by domain-specific processing. For the commentary domain, Automatic Speech Recognition (ASR) extracts transcripts which are then enriched with interjections and polished to match specific commentator personas. Conversely, for the user guidance domain, the system synthesizes potential player queries and generates fine-grained frame descriptions. These descriptions are refined by large language models to produce concise, action-oriented coaching instructions.
The core architecture operates on a chunk-wise processing approach to handle streaming video inputs efficiently. At each time step t, the model receives a triplet of inputs: visual content Vt, optional user query Qt, and environmental context Bt. This structure allows the system to maintain temporal awareness while processing continuous streams. The inputs are serialized into a ChatML-style format that explicitly separates history, video chunks, and queries using special tokens.
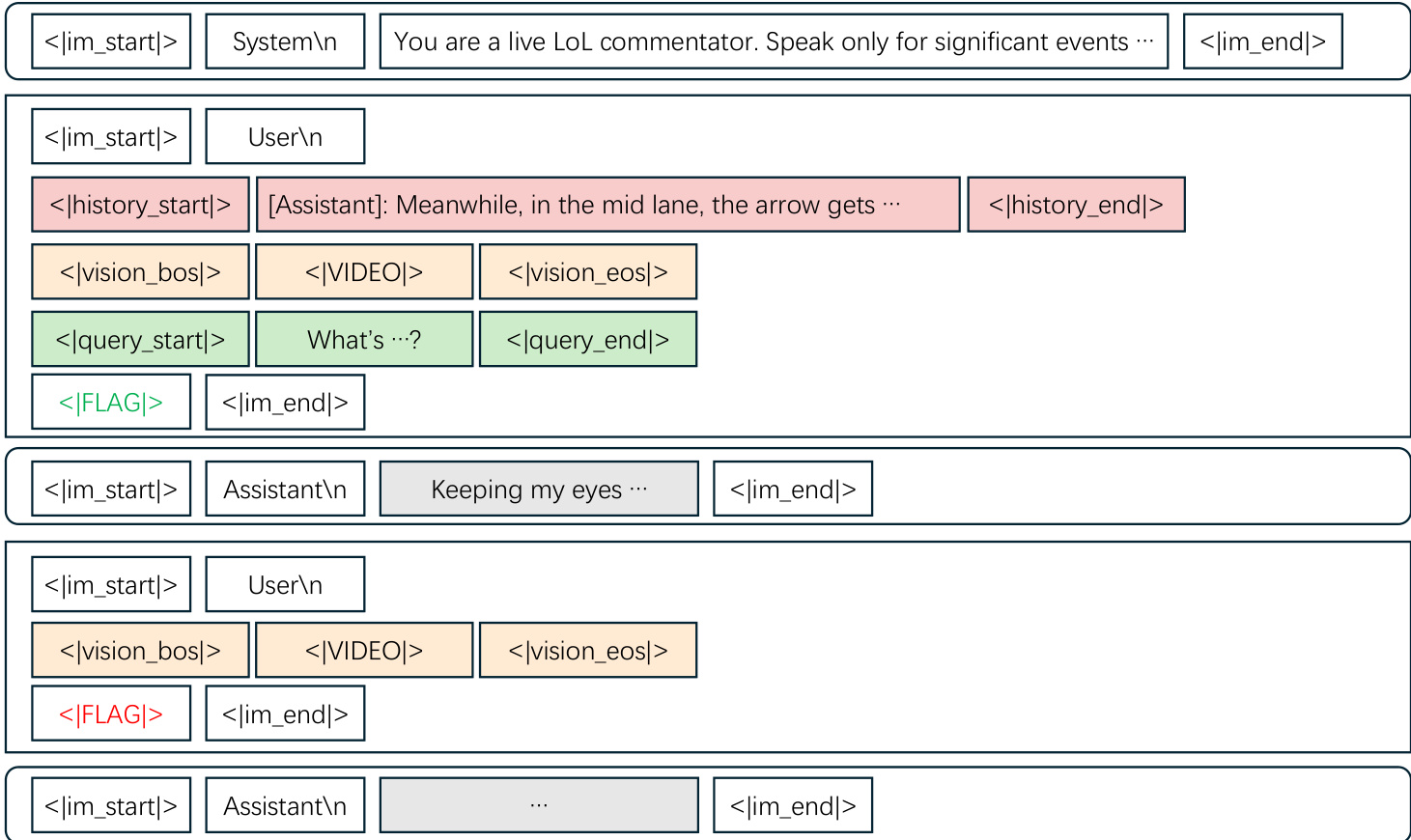
A key innovation is the proactive response mechanism, which enables the model to autonomously decide when to speak. Instead of waiting for explicit prompts, the system inserts a special decision token <|FLAG|> at the end of each user message. The hidden state corresponding to this token is fed into a lightweight response head to compute a speaking probability.
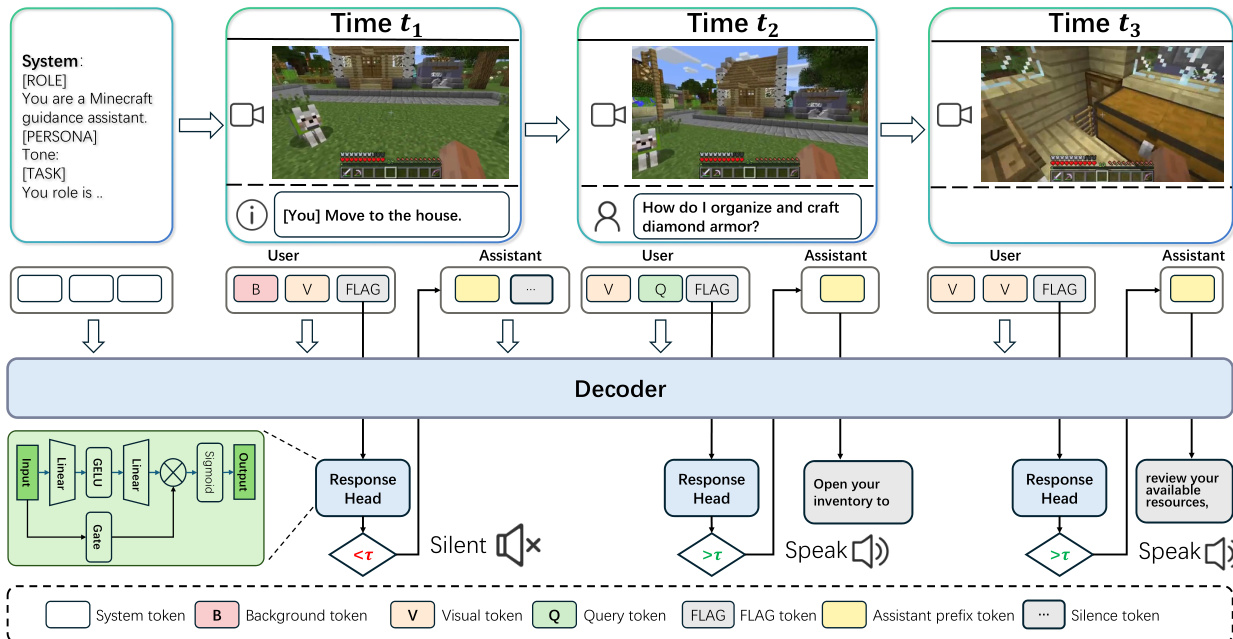
The decision is formalized as pt=σ(MLP(ht)), where ht is the hidden state. A binary decision is made by comparing pt against a threshold τ. If triggered, the model generates a commentary clip; otherwise, it outputs a silence token. This design enables a two-stage inference pipeline where the model first decides whether to respond and only then produces a commentary clip if needed.
The model is optimized using a combined objective that balances utterance quality and speaking behavior. The primary loss supervises the text generation, while a secondary response loss governs the timing of the commentary. This response loss includes a transition-smoothed classification component to handle state changes and a regularization term to ensure stable speaking rates. For long-duration streaming, the system employs a dual-cache sliding-window mechanism to maintain a persistent context while evicting older tokens to stay within memory limits.
Experiment
- Live gaming commentary experiments demonstrate that the model achieves superior text quality and proactive timing compared to commercial and prior real-time baselines, effectively balancing engagement with accuracy in solo, co-commentary, and guidance scenarios.
- Evaluations on common and general commentary sets confirm strong out-of-domain generalization, with the model maintaining high coherence and reliable event-triggering on unseen games and egocentric video streams.
- Long-form streaming tests reveal that the model sustains consistent text quality and stable response behavior over extended inference horizons, proving robustness for continuous live broadcasting.
- Ablation studies validate that the proposed training losses are complementary and essential for precise response timing, while data mixture analysis shows that combining gaming, general, and live-streaming sources maximizes domain adaptability.
- In-depth analyses of inference efficiency and trigger thresholds indicate a stable low-latency profile and a clear trade-off between response coverage and consistency, with case studies highlighting the model's ability to adopt specific personas and handle complex multi-speaker dynamics.