Command Palette
Search for a command to run...
LoGeR: 하이브리드 메모리를 활용한 장문맥 기하학적 재구성
LoGeR: 하이브리드 메모리를 활용한 장문맥 기하학적 재구성
Junyi Zhang Charles Herrmann Junhwa Hur Chen Sun Ming-Hsuan Yang Forrester Cole Trevor Darrell Deqing Sun
초록
순방향 기하학적 기초 모델은 짧은 시간 창 내에서의 재구성에 탁월한 성능을 보이지만, 이를 수 분 길이의 비디오로 확장할 경우 이차적 주의 복잡도 또는 순환 구조 설계의 제한된 유효 메모리 때문에 병목 현상이 발생합니다. 본 논문은 사후 최적화 없이 밀집형 3 차원 재구성을 극도로 긴 시퀀스로 확장할 수 있는 새로운 아키텍처인 LoGeR(Long-context Geometric Reconstruction) 를 제안합니다. LoGeR 는 비디오 스트림을 청크 단위로 처리하여 청크 내부의 고충실도 추론을 위해 강력한 양방향 사전 지식을 활용합니다. 청크 간 경계를 가로지르는 일관성이라는 핵심 과제를 해결하기 위해, 학습 기반의 하이브리드 메모리 모듈을 도입했습니다. 이 이중 구성 요소 시스템은 파라메트릭 테스트타임 트레이닝(Test-Time Training, TTT) 메모리를 결합하여 글로벌 좌표계를 고정하고 스케일 드리프트를 방지함과 동시에, 비파라메트릭 슬라이딩 윈도우 어텐션(Sliding Window Attention, SWA) 메커니즘을 통해 압축되지 않은 컨텍스트를 보존하여 고정밀 인접 정렬을 가능하게 합니다. 주목할 만한 점은, 이 메모리 아키텍처 덕분에 LoGeR 는 128 프레임 시퀀스로 훈련되면서도 추론 단계에서는 수천 프레임까지 일반화할 수 있다는 것입니다. 표준 벤치마크와 최대 19,000 프레임 길이의 시퀀스를 포함하도록 새롭게 재구성된 VBR 데이터셋에 대한 평가 결과, LoGeR 는 기존 최첨단 순방향 방법들을 크게 능가하여 KITTI 데이터셋에서 절대 트래젝토리 오차(Absolute Trajectory Error, ATE) 를 74% 이상 감소시켰으며, 전례 없는 시야 범위에서 강건하고 전역적으로 일관된 재구성을 달성했습니다.
One-sentence Summary
Researchers from Google DeepMind and UC Berkeley present LoGeR, a feedforward model that scales 3D reconstruction to long videos by combining Test-Time Training for global consistency with Sliding Window Attention for local precision, eliminating the need for post-optimization while achieving superior accuracy on datasets with thousands of frames.
Key Contributions
- Feedforward geometric models currently struggle to scale to minute-long videos due to quadratic attention complexity and limited memory, creating a critical gap between short-window reconstruction and the need for global consistency over long sequences.
- LoGeR introduces a novel chunk-wise architecture with a hybrid memory module that combines parametric Test-Time Training to anchor the global coordinate frame and non-parametric Sliding Window Attention to preserve high-precision local alignment.
- Trained on sequences of only 128 frames, the model generalizes to thousands of frames and achieves state-of-the-art performance by reducing Absolute Trajectory Error on KITTI by over 74% and improving results by 30.8% on a new 19k-frame VBR benchmark.
Introduction
Large-scale dense 3D reconstruction is essential for applications ranging from autonomous driving to generative world-building, yet current methods struggle to balance computational efficiency with long-range consistency. While classical optimization pipelines can handle city-scale scenes, they rely on slow offline processes and fail on sparse inputs, whereas modern feedforward geometric models offer speed but are limited to short, bounded scenes due to quadratic attention complexity and a lack of training data for long sequences. To bridge this gap, the authors propose LoGeR, a feedforward framework that utilizes a hybrid memory module combining non-parametric sliding window attention for high-fidelity local details and parametric associative memory for global structural integrity. This approach allows the model to process massive sequences of up to 19,000 frames with linear computational cost, effectively overcoming the context and data walls that previously prevented feedforward models from scaling to real-world, long-horizon trajectories.
Dataset
-
Dataset Composition and Sources: The authors utilize a diverse mixture of 14 large-scale datasets containing both real-world and synthetic scenes across indoor, outdoor, and autonomous driving environments to support long-context geometric reconstruction.
-
Key Details for Each Subset:
- Navigation and large-scale scene datasets like TartanAirV2 and VKITTI2 are heavily weighted to encourage long-range geometric reasoning.
- DL3DV receives a high sampling weight due to its exceptional real-world scene diversity, which aids model generalization.
- Smaller or object-centric datasets are down-weighted in the mixture.
- The OmniWorld-Game contribution is limited to a subset of 5,000 sequences based on the publicly released data at the time of training.
-
Data Usage and Mixture Ratios: The training configuration employs relative sampling percentages as summarized in Table 4, where the mixture is specifically tuned to provide sufficient long-horizon signals and diverse scene priors.
-
Processing and Filtering Strategies:
- All datasets are standardized into multi-view sequences with 48 views (or 128 views for H200 GPU training) at a uniform resolution of 504 × 280.
- The sampling strategy follows the CUT3R approach.
- Rigorous depth filtering is applied to ensure geometric supervision quality.
- Metric-scale datasets like ARKitScenes and ScanNet use a maximum depth threshold (e.g., 80.0 meters), while others like DL3DV and TartanAir use percentile-based clipping (e.g., 90th or 98th percentile) to mask noisy or invalid depth values.
Method
The authors propose LoGeR, a novel architecture designed to scale dense 3D reconstruction to extremely long video sequences without post-optimization. To overcome the quadratic complexity of global attention and the scarcity of long-horizon training data, the method processes video streams sequentially by chunk. This approach tightly bounds computational cost while ensuring that local inferences remain within the distribution of existing short-context training data.
Refer to the framework diagram for an overview of the proposed chunk-wise processing pipeline and its performance on long sequences.
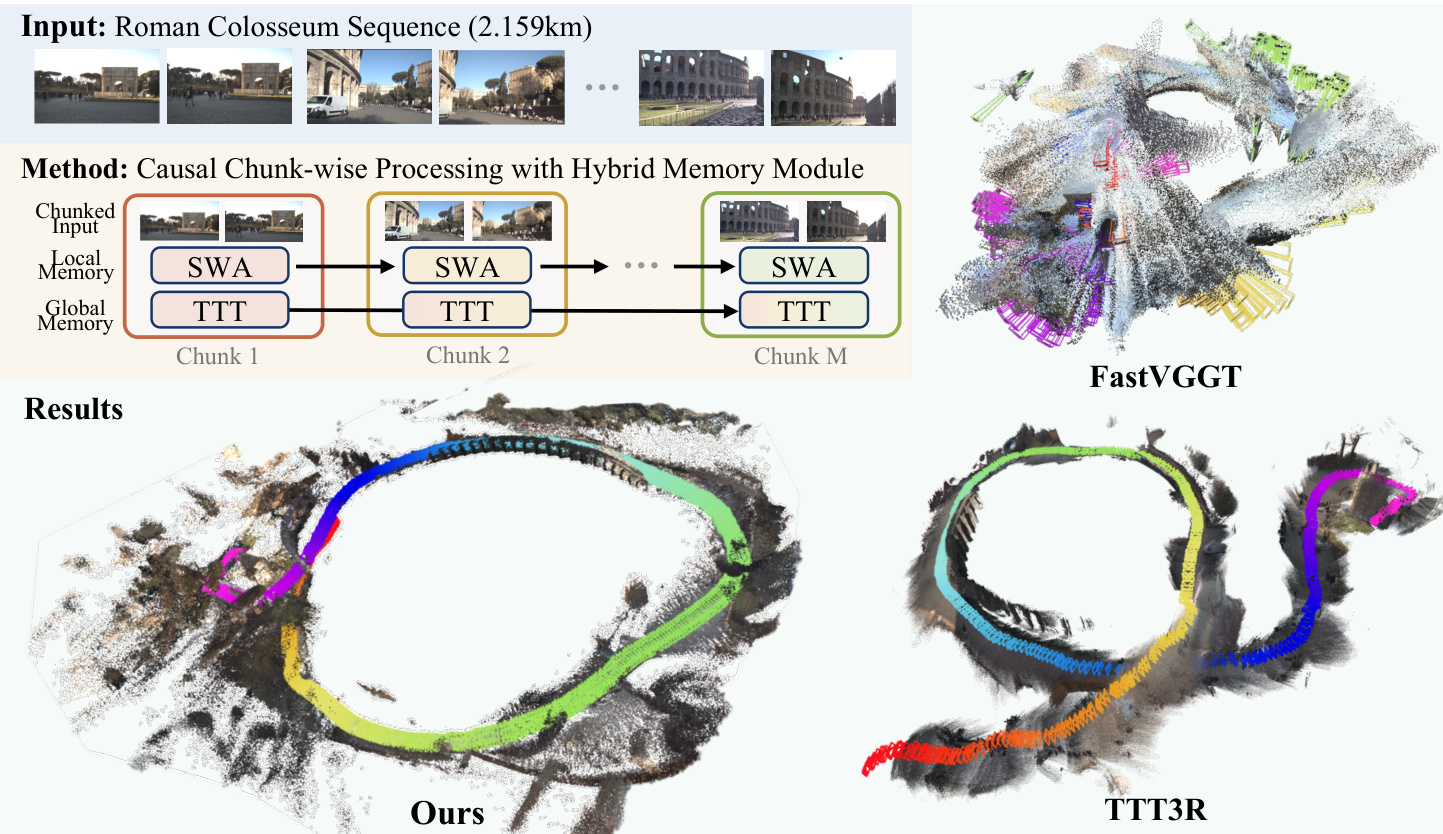
The core innovation lies in a learning-based hybrid memory module that manages coherence across chunk boundaries. This dual-component system combines a parametric Test-Time Training (TTT) memory to anchor the global coordinate frame and prevent scale drift, alongside a non-parametric Sliding Window Attention (SWA) mechanism to preserve uncompressed context for high-precision adjacent alignment.
As shown in the figure below, the architecture processes input sequences in consecutive chunks, utilizing specific mechanisms for the first chunk versus following chunks to propagate information effectively.
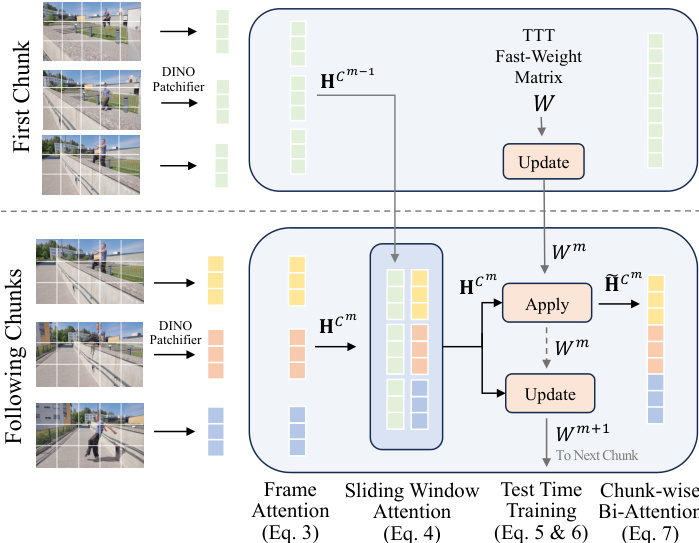
Within each residual block of the geometry backbone, the authors introduce the hybrid memory system. The process begins with per-frame attention to extract spatial features independently for each frame. To align adjacent chunks, sparse sliding-window attention layers are inserted at a subset of network depths. These layers attend to tokens from both the previous chunk Cm−1 and the current chunk Cm, establishing a lossless information highway for high-fidelity feature propagation.
To integrate global context, the model maintains a set of fast weights Wm that summarize information up to chunk m. The TTT layer performs an apply-then-update procedure at the chunk level. In the apply operation, the TTT layers use historical information stored in the weights to modulate the network's processing of the current chunk. In the update operation, the weights are edited to store information from the current chunk, conceptually compressing important but redundant geometric information. The mathematical formulation for the TTT update and apply operations is defined as:
W←W−η∇WL(fW(k),v) Apply operation:o=fW(q)where η is the learning rate and L is a loss function encouraging the function fW to link keys with corresponding values. Finally, within each chunk, a bidirectional attention module is employed for powerful geometric reasoning under a bounded context window.
For training, the authors employ a progressive curriculum strategy to stabilize the optimization of recurrent TTT layers. The schedule begins with shorter sequences and gradually increases complexity, forcing the model to shift reliance from local Sliding Window Attention to the global TTT hidden state. Additionally, to mitigate prediction errors in very long streams, a variant called LoGeR* incorporates a purely feedforward alignment step. This step aligns raw predictions into a consistent global coordinate system by computing a rigid SE(3) transformation using overlapping frames between chunks.
Experiment
- Long-sequence evaluation on KITTI and VBR benchmarks demonstrates that LoGeR effectively mitigates accumulated drift over thousands of frames, maintaining global scale and trajectory consistency where prior methods fail.
- Short-sequence tests on 7-Scenes, ScanNet, and TUM-Dynamics confirm that the proposed model and baseline significantly outperform existing feedforward and optimization-based approaches in 3D reconstruction and camera pose estimation.
- Ablation studies validate that the hybrid architecture is essential, with the Test-Time Training layer ensuring global consistency and the Sliding Window Attention layer preserving local geometric smoothness.
- Experiments on data mixture and curriculum training prove that incorporating large-scale navigation datasets and a progressive training schedule are critical for generalization and stabilizing recurrent layer optimization.