Command Palette
Search for a command to run...
다중 뷰 일관성 3D 장면 편집을 위한 기하학 기반 강화 학습
다중 뷰 일관성 3D 장면 편집을 위한 기하학 기반 강화 학습
초록
2 차원 확산 모델의 사전 지식 (priors) 을 활용하여 3 차원 편집을 수행하는 접근법은 유망한 패러다임으로 부상하고 있습니다. 그러나 편집된 결과에서 다중 뷰 일관성 (multi-view consistency) 을 유지하는 것은 여전히 과제로 남아 있으며, 3 차원 일관성을 갖춘 편집 쌍 데이터의 극심한 부족으로 인해 편집 작업에 가장 효과적인 학습 전략인 지도 미세 조정 (Supervised Fine-Tuning, SFT) 을 적용하는 것이 불가능합니다. 본 논문에서는 3 차원 일관성을 갖춘 콘텐츠 생성이 매우 어렵지만, 3 차원 일관성 검증은 실현 가능하다는 점을 관찰함으로써, 강화 학습 (Reinforcement Learning, RL) 을 실현 가능한 해결책으로 자연스럽게 도출합니다. 이에 영감을 받아, 우리는 3 차원 기초 모델인 VGGT 에서 파생된 새로운 보상 신호를 기반으로 한 RL 최적화驱动的 단일 패스 프레임워크인 RL3DEdit을 제안합니다. 구체적으로, 본 연구는 방대한 실제 데이터로부터 학습된 VGGT 의 강력한 사전 지식을 활용하여 편집된 이미지를 입력하고, 출력 신뢰도 맵 및 포즈 추정 오차를 보상 신호로 사용하여, RL 을 통해 2 차원 편집 사전 지식을 3 차원 일관성 매니폴드에 효과적으로 고정합니다. 광범위한 실험 결과, RL3DEdit 은 안정적인 다중 뷰 일관성을 달성할 뿐만 아니라, 편집 품질과 효율성 측면에서 기존 최첨단 방법들을 능가함을 입증했습니다. 3 차원 편집 분야의 발전을 촉진하기 위해, 우리는 해당 코드와 모델을 공개할 예정입니다.
One-sentence Summary
Researchers from BJTU, AMap Alibaba Group, NTU, and CQUPT propose RL3DEdit, a single-pass 3D editing framework that leverages reinforcement learning with VGGT-derived rewards to ensure multi-view consistency, overcoming data scarcity and outperforming iterative methods in both quality and efficiency for AR and gaming applications.
Key Contributions
- Current 3D editing methods struggle with multi-view consistency and cannot utilize supervised fine-tuning due to the extreme scarcity of 3D-consistent paired data.
- The proposed RL3DEdit framework leverages the 3D foundation model VGGT to generate novel reward signals from confidence maps and pose errors, enabling RL optimization that anchors 2D editing priors onto a 3D-consistent manifold without requiring paired datasets.
- Extensive experiments demonstrate that this single-pass approach achieves state-of-the-art editing quality and stable multi-view consistency while operating more than twice as fast as previous iterative optimization methods.
Introduction
3D scene editing is critical for AR/VR and gaming applications, yet current methods struggle to maintain geometric coherence while leveraging powerful 2D diffusion models. Prior approaches suffer from inefficiency due to iterative optimization, produce blurry artifacts from inconsistent signals, or fail to handle edits that alter scene geometry because they rely on depth maps or attention propagation. The authors address these challenges by introducing RL3DEdit, a single-pass framework that uses reinforcement learning to optimize 2D editors for 3D consistency without requiring scarce paired training data. They leverage the 3D foundation model VGGT as a robust verifier to generate geometry-aware reward signals, effectively anchoring 2D editing priors onto a 3D-consistent manifold while achieving state-of-the-art quality and over twice the speed of existing methods.
Method
The authors propose RL3DEdit, a framework that leverages Reinforcement Learning to equip a 2D foundation model with 3D-consistency priors. The overall architecture is illustrated in the framework diagram. Given a 3D asset, the system first renders it from M viewpoints to obtain a set of images {Im}m=1M. These images are fed simultaneously into a 2D editor, denoted as π, for joint multi-view editing. During inference, the fine-tuned editor produces multi-view consistent images in a single forward pass, which are subsequently processed by 3D Gaussian Splatting (3DGS) reconstruction to yield the final edited 3D scene.
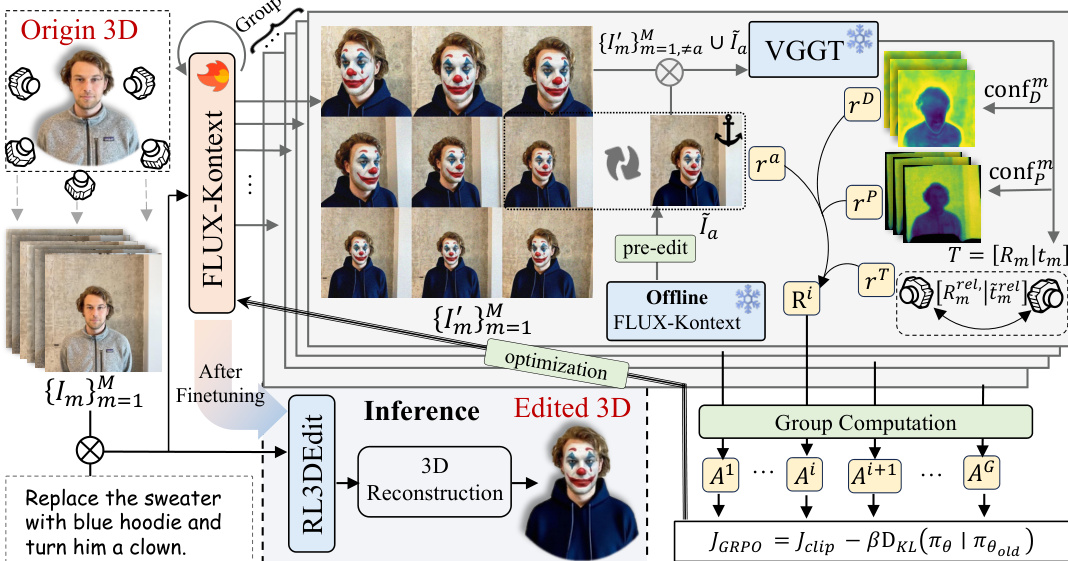
To address the core challenge of ensuring 3D consistency without paired supervision, the authors employ the Group Relative Policy Optimization (GRPO) algorithm. During training, the system explores a group of G edited results through independent inference passes. A dedicated 3D-aware reward model, implemented via VGGT, is utilized to explicitly enforce both editing faithfulness and multi-view coherence. This model jointly assesses three critical aspects of multi-view consistency, represented as depth confidence rD, point confidence rP, and relative pose reward rT, alongside an editing quality term ra. These complementary rewards are combined to form the final composite reward Ri, which guides the optimization toward consistent and high-quality 3D-aware editing.
The choice of the 2D backbone is critical for enabling cross-view interaction. The authors adopt FLUX-Kontext, a DiT-based model that naturally supports multi-image joint editing through global attention mechanisms. This capability allows the model to process all input views as a concatenated sequence, facilitating the necessary cross-view interactions for 3D consistency. The versatility of this approach is demonstrated by the diverse editing capabilities shown in the qualitative results, which include motion, replacement, style transfer, background modification, and object addition.

A key component of the training process is the anchor reward, designed to preserve the original 2D editing fidelity of the foundation model. By comparing the edited anchor view against a pre-computed high-quality 2D edit, the model ensures that semantic correctness and visual details are maintained while learning 3D priors. As illustrated in the comparison of editing capabilities, the RL fine-tuned model successfully preserves the original 2D editing fidelity of the base model, as evidenced by the comparable VIE Score metrics.

Finally, the relative advantage Ai is computed from the group rewards, and the model is optimized by maximizing the following objective:
J(θ)=Jclip(θ)−βDKL(πθ∣∣πref)where πθ and πref denote the fine-tuned and original 2D editors, respectively. This formulation allows the model to learn 3D-consistency priors effectively without requiring curated paired data.
Experiment
- Comparative experiments against state-of-the-art 3D editing methods demonstrate that the proposed approach achieves superior instruction following, visual fidelity, and multi-view consistency while significantly reducing editing time.
- Qualitative analysis reveals that the method successfully handles complex geometric transformations, motion edits, and style changes where baseline models fail due to artifacts, ghosting, or semantic misinterpretation.
- Ablation studies confirm that depth and point confidence rewards are essential for preventing ghosting artifacts and maintaining 3D consistency, while text-based rewards ensure accurate viewpoint alignment.
- Experiments comparing consistency verifiers show that traditional metrics like Structure-from-Motion and photometric reprojection loss lead to textureless or blurred outputs, validating the necessity of using data-driven priors for reward signals.
- Additional tests verify that the framework generalizes effectively to unseen instructions and scenes in a zero-shot setting and can be enhanced by integrating more powerful 2D editing backbones.