Command Palette
Search for a command to run...
이질적 Agent 협업 강화 학습
이질적 Agent 협업 강화 학습
Zhixia Zhang Zixuan Huang Xin Xia Deqing Wang Fuzhen Zhuang Shuai Ma Ning Ding Yaodong Yang Jianxin Li Yikun Ban
초록
이 논문은 고립된 온-폴리시 (on-policy) 최적화의 비효율성을 해결하는 새로운 학습 패러다임인 이질적 에이전트 협력 강화학습 (Heterogeneous Agent Collaborative Reinforcement Learning, HACRL) 을 제시합니다. HACRL 은 훈련 과정에서 검증된 롤아웃 (rollout) 을 이질적 에이전트 간에 공유하여 상호 개선하도록 허용하면서도, 추론 (inference) 시에는 각 에이전트가 독립적으로 실행될 수 있도록 하는 협력적 최적화를 가능하게 합니다. 대규모 언어 모델 (LLM) 기반의 다중 에이전트 강화학습 (MARL) 과 달리 HACRL 은 조정된 배포를 요구하지 않으며, 온/오프-폴리시 증류 (distillation) 와는 달리 단방향적인 교사 - 학생 전수가 아닌 이질적 에이전트 간 양방향 상호 학습을 구현합니다.본 패러다임을 기반으로, 본 연구는 표본 활용도와 에이전트 간 지식 전이를 극대화하기 위해 원칙에 기반한 롤아웃 공유를 가능하게 하는 협력적 강화학습 알고리즘인 HACPO 를 제안합니다. 능력 격차와 정책 분포 이동을 완화하기 위해 HACPO 는 편향되지 않은 이점 (advantage) 추정 및 최적화의 정확성에 대한 이론적 보장을 제공하는 네 가지 맞춤형 메커니즘을 도입합니다. 다양한 이질적 모델 조합 및 추론 벤치마크를 통한 광범위한 실험 결과, HACPO 는 참여하는 모든 에이전트의 성능을 지속적으로 향상시켰으며, GSPO 대비 평균 3.3% 높은 성능을 달성하면서도 롤아웃 비용은 절반 수준으로 절감하는 것을 확인했습니다.
One-sentence Summary
Researchers from Beihang University and collaborating institutes propose HACRL, a paradigm enabling heterogeneous agents to share verified rollouts for mutual improvement without coordinated deployment. Their algorithm, HACPO, introduces bidirectional learning mechanisms that outperform GSPO in reasoning benchmarks while halving rollout costs.
Key Contributions
- Heterogeneous Agent Collaborative Reinforcement Learning (HACRL) addresses the inefficiencies of isolated on-policy optimization by enabling heterogeneous agents to share verified rollouts during training while maintaining independent execution at inference time.
- The proposed HACPO algorithm implements this paradigm through four tailored mechanisms that mitigate capability discrepancies and policy distribution shifts to ensure unbiased advantage estimation and maximize sample utilization.
- Extensive experiments across diverse heterogeneous model combinations and reasoning benchmarks demonstrate that HACPO consistently improves all participating agents, outperforming GSPO by an average of 3.3% while using only half the rollout cost.
Introduction
Reinforcement Learning with Verifiable Rewards (RLVR) has become a standard for training strong reasoning models, yet it suffers from high computational costs due to isolated on-policy sampling where each agent generates and discards its own trajectories. Prior approaches like Multi-Agent Reinforcement Learning require coordinated execution that is impractical for independent deployment, while knowledge distillation typically enforces a one-way transfer from a teacher to a student that limits bidirectional learning among heterogeneous models. The authors introduce Heterogeneous Agent Collaborative Reinforcement Learning (HACRL) and its algorithm HACPO to enable independent agents to share verified rollouts during training for mutual improvement. This framework maximizes sample efficiency by reusing trajectories across multiple agents and ensures unbiased optimization through four tailored mechanisms that address capability discrepancies and policy distribution shifts.
Method
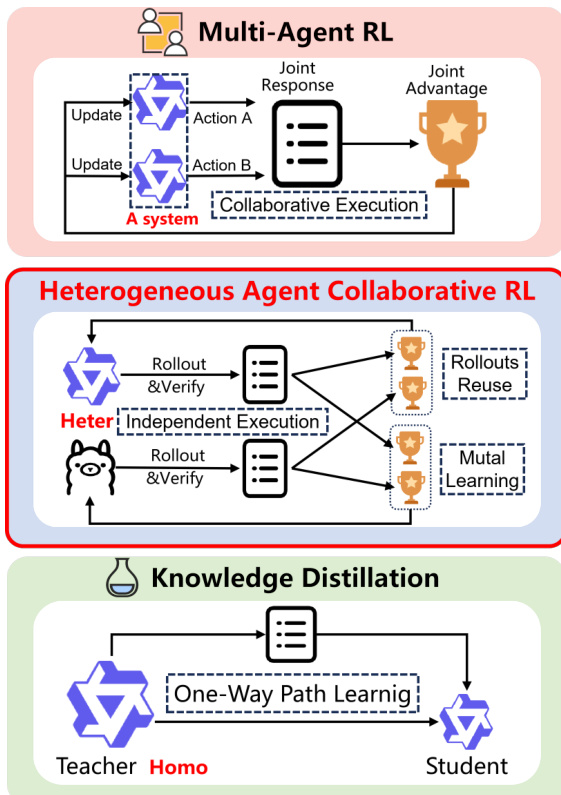
The authors propose Heterogeneous Agent Collaborative Policy Optimization (HACPO), a novel framework designed to facilitate rollout sharing and knowledge transfer among heterogeneous Large Language Model (LLM) agents. Unlike traditional Multi-Agent Reinforcement Learning (MARL) which often relies on joint responses or Knowledge Distillation which follows a one-way path, HACRL enables independent execution with mutual learning through cross-agent rollout reuse.
The core objective of HACRL is to optimize each agent k by maximizing a joint objective that combines self-generated experiences (Jhomo) and cross-agent information (Jhete). This formulation allows agents to benefit from the diverse capabilities of their peers while managing the challenges introduced by heterogeneity.
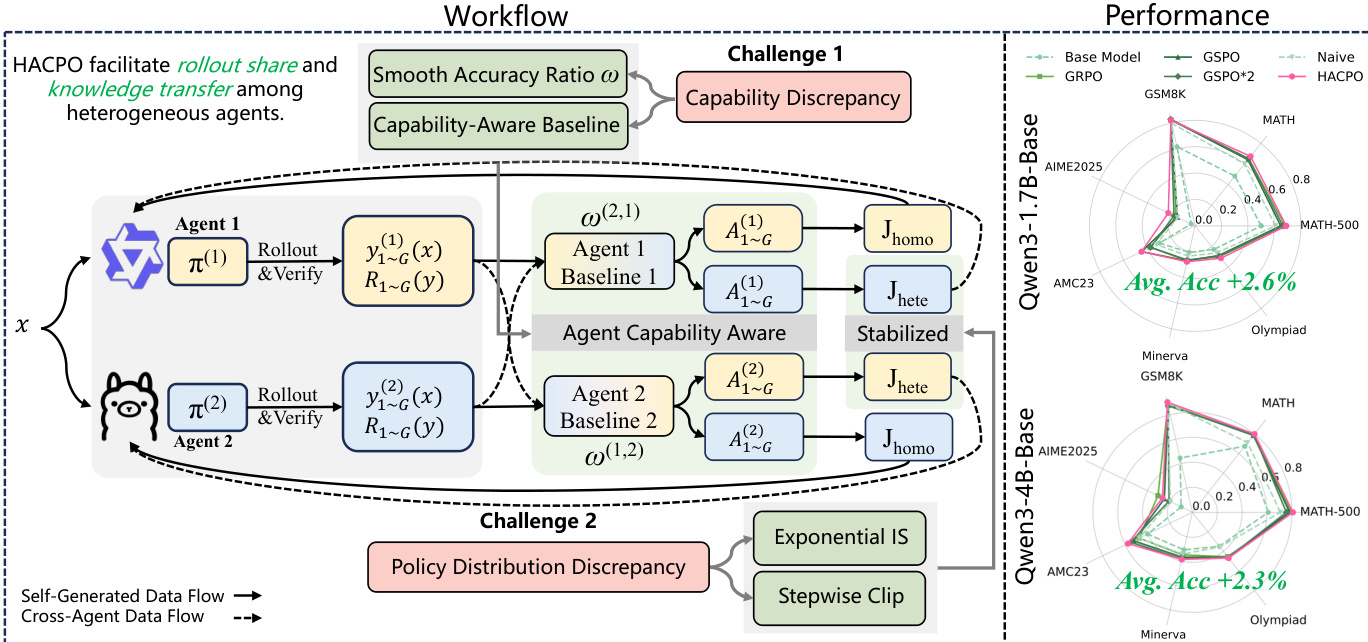
As illustrated in the workflow diagram, the training process involves two primary challenges: capability discrepancy and policy distribution discrepancy. To address these, HACPO incorporates four tailored modifications.
Agent-Capability-Aware Advantage Estimation Standard group-relative advantage estimation relies solely on self-generated rewards, which is suboptimal in heterogeneous settings. HACPO introduces a capability-adjusted baseline μ^t(k) that leverages rewards from all agents, reweighted by their relative capabilities. The advantage for a response yt,i(k) is defined as:
At,i(k)=σt,jointR(yt,i(k))−μ^t(k)where σt,joint is the standard deviation of rewards across all agents. The baseline μ^t(k) is computed using a capability ratio ωt(k,j):
μ^t(k)=nG1j=1∑ni=1∑Gωt(k,j)R(yt,i(j))Here, ωt(k,j) represents the smoothed performance ratio between agent k and agent j, ensuring that the baseline is properly calibrated across agents with different strengths.
Model Capabilities Discrepancy Coefficient To further handle capability gaps, the framework applies the capability ratio directly to the advantage when updating an agent using cross-agent samples. When agent k learns from a response generated by agent j, the effective advantage is scaled:
A~t,i(k)=ωt(j,k)At,i(j)This mechanism encourages aggressive learning from stronger agents while adopting a conservative update strategy for samples from weaker agents.
Exponential Importance Sampling To correct for distributional mismatches between the policy generating the sample and the policy being updated, HACPO employs sequence-level importance sampling. For a response yt,i(j) generated by agent j and used to update agent k, the importance ratio is:
st,i(k,j)=πθold(j)(yt,i(j))πθt(k)(yt,i(j))∣yt,i(j)∣1Given that inter-agent policy discrepancies can be large, the authors introduce a non-gradient exponential reweighting to mitigate aggressive updates:
s~t,i(k,j)=st,i(k,j)⋅(sg[st,i(k,j)])αwhere α≥0 controls the degree of conservativeness.
Stepwise Clipping Finally, to stabilize training and prevent cross-agent rollouts from dominating the gradient updates, HACPO utilizes an asymmetric clipping scheme. Unlike standard symmetric clipping, the upper bound for cross-agent importance ratios is strictly limited to 1.0:
st.i(k,j)∈[1.0−δ,1.0]Additionally, a stepwise clipping strategy is applied within each training step. As the number of parameter updates k increases, the lower bound tightens:
clip(st,i(k,j))=clip(st,i(k,j),1−δ+k⋅δstep,1.0)This ensures that cross-agent responses are subject to increasingly stricter constraints as the training step progresses, maintaining stability in the heterogeneous collaborative policy optimization process.
Experiment
- Experiments across three heterogeneity settings (state, size, and model architecture) validate that HACPO outperforms single-agent baselines and naive multi-agent approaches by enabling bidirectional knowledge exchange between agents of varying capabilities.
- Qualitative analysis confirms that stronger models benefit from the complementary exploration signals and informative errors of weaker agents, while weaker models gain from the guidance of stronger peers, proving that learning is not purely unidirectional.
- Ablation studies demonstrate that agent-capability-aware advantage estimation and gradient modulation are essential for correcting systematic biases and balancing learning rates between heterogeneous agents.
- The necessity of stepwise clipping is established as a critical mechanism for stabilizing training, preventing the severe instability caused by unpredictable importance sampling values in cross-agent responses.
- Results across diverse model combinations, including different architectures and tokenizers, confirm the robustness and generalizability of the proposed method in extracting transferable knowledge from heterogeneous rollouts.