Command Palette
Search for a command to run...
ArtLLM: 3D LLM을 통한 관절형 에셋(Articulated Assets) 생성
ArtLLM: 3D LLM을 통한 관절형 에셋(Articulated Assets) 생성
Penghao Wang Siyuan Xie Hongyu Yan Xianghui Yang Jingwei Huang Chungao Guo Jiayuan Gu
초록
게이밍, 로보틱스 및 시뮬레이션을 위한 상호작용형 디지털 환경을 구축하기 위해서는 부품의 기하학적 구조(geometry)와 운동학적 구조(kinematic structure)를 통해 기능이 구현되는 관절형 3D 객체(articulated 3D objects)가 필수적입니다. 그러나 기존의 접근 방식은 근본적인 한계를 가지고 있습니다. 최적화 기반의 재구성(reconstruction) 방식은 객체별로 느린 관절 피팅(joint fitting) 과정을 거쳐야 하며, 대개 단순한 단일 관절 객체만을 처리할 수 있습니다. 반면, 검색 기반 방식은 고정된 라이브러리에서 부품을 조립하기 때문에 기하학적 구조가 반복적이고 일반화 능력이 떨어진다는 단점이 있습니다.이러한 문제를 해결하기 위해, 본 논문에서는 완전한 3D 메쉬(mesh)로부터 고품질의 관절형 에셋(articulated assets)을 직접 생성하는 혁신적인 프레임워크인 ArtLLM을 소개합니다. ArtLLM의 핵심은 기존의 관절 데이터셋과 절차적 생성(procedurally generated) 객체를 결합하여 구축한 대규모 관절 데이터셋으로 학습된 3D 멀티모달 대형 언어 모델(multi-modal large language model)입니다. 기존 연구와 달리, ArtLLM은 객체의 포인트 클라우드(point cloud)로부터 가변적인 수의 부품과 관절을 자기회귀(autoregressively) 방식으로 예측하며, 이들의 운동학적 구조를 통합된 방식으로 추론합니다. 이렇게 도출된 관절 인지형 레이아웃(articulation-aware layout)은 3D 생성 모델의 조건(condition)으로 작용하여 고충실도(high-fidelity)의 부품 기하학적 구조를 합성합니다.PartNet-Mobility 데이터셋을 활용한 실험 결과, ArtLLM은 부품 레이아웃 정확도와 관절 예측 측면 모두에서 기존의 최첨단(state-of-the-art) 방식들을 크게 상회하였으며, 실제 환경의 객체에 대해서도 강력한 일반화 성능을 보여주었습니다.
One-sentence Summary
ArtLLM is a novel framework that generates high-quality articulated 3D assets by utilizing a 3D multi-modal large language model to autoregressively predict a variable number of parts and joints from point clouds, a method that outperforms state-of-the-art approaches in part layout accuracy and joint prediction on the PartNet-Mobility dataset.
Key Contributions
- The paper introduces ArtLLM, a 3D multi-modal large language model that autoregressively predicts a variable number of parts and joints by outputting a tokenized blueprint of an object's layout and kinematic relationships from an input point cloud.
- This framework integrates the predicted articulation-aware layout with a part-aware generative model to synthesize high-fidelity, novel part geometries, overcoming the geometric repetition found in retrieval-based methods.
- The method incorporates a physical constraint-based limit correction mechanism to optimize joint limits and mitigate mesh collisions, with experiments on the PartNet-Mobility dataset demonstrating superior performance in part placement, joint accuracy, and generalization to real-world objects.
Introduction
Creating interactive digital environments for gaming, robotics, and simulation requires articulated 3D assets that possess both functional part geometry and accurate kinematic structures. Existing optimization-based methods are often limited by slow per-object reconstruction and a tendency to produce only simple, single-joint objects. Meanwhile, retrieval-based approaches rely on fixed part libraries, which results in repetitive geometry and poor generalization to novel shapes. The authors leverage a 3D multi-modal large language model to bridge this gap by autoregressively predicting part layouts and joint relationships from point clouds. This framework produces a tokenized kinematic blueprint that guides a generative model to synthesize high-fidelity, novel part geometries, resulting in physically grounded and diverse articulated assets.
Dataset

-
Dataset Composition and Sources: The authors constructed a large scale dataset by aggregating existing articulation datasets and procedural data. The collection includes objects from PartNet-Mobility and PhysX3D, supplemented by 12k synthetic assets generated using the Infinite-Mobility procedural method. The final curated dataset contains 20,673 articulated objects across 43 categories.
-
Data Processing and Filtering:
- Filtering: The authors removed objects with more than 20 joints and excluded categories with excessively small parts (such as keyboards or remotes). Additionally, small components like buttons were filtered out based on volume thresholds.
- Structure Simplification: To reduce prediction complexity, all fixed joints were removed and their connected links were merged. Screw joints, typically represented by a combination of revolute and prismatic joints in URDF files, were merged into a single screw joint type.
- Normalization: All joint parameters and geometries were transformed into the global coordinate frame and normalized to a range of [−0.9,0.9].
- Normal Correction: For models in PartNet-Mobility with incorrect surface normals, the authors applied watertight reconstruction to ensure accuracy.
-
Training and Evaluation:
- Training: The authors use the curated dataset for multi task training. During this process, point clouds are replaced with point tokens produced by a point cloud encoder. The training data is formatted in ShareGPT style, utilizing concise text prompts to differentiate between tasks while minimizing token usage. The model is trained on both continuous values and discretized values.
- Evaluation: The evaluation is conducted using the PartNet-Mobility dataset. Following the SINGAPO split, the authors selected 7 categories (Storage, Table, Refrigerator, Dishwasher, Oven, Washer, and Microwave) comprising 77 held out objects for the test set. Generalization ability is further assessed using real world images, including objects from categories not present in the test set.
Method
The authors propose a framework for generating articulated assets from point clouds, which consists of three main stages: kinematic structure prediction, part geometry synthesis, and physical limit correction. As shown in the framework diagram below:
The first stage utilizes a novel 3D articulation language model (ArtLLM) to autoregressively predict the object's kinematic structure. To leverage the reasoning capabilities of Large Language Models (LLMs), the authors reformulate 3D articulation understanding as a language modeling problem. The entire kinematic structure, including part layouts and joint parameters, is represented as a unified sequence of discrete tokens. The input is a point cloud, which is processed through a Point Transformer v3 encoder. To bridge the modality gap, the encoder features are augmented with position embeddings and then projected via a two-layer MLP to align with the Qwen3 0.6B language model backbone.
To ensure numerical stability during training, the authors employ a quantization strategy for continuous geometric and kinematic parameters. For a part's axis-aligned bounding box (AABB), coordinates are quantized from a normalized range of [−1,1] into 128 discrete bins per axis using the following formula:
c^min=⌊2(cmin+1)×128⌋,c^max=⌈2(cmax+1)×128⌉
Joint parameters, including origins and limits, undergo similar discretization. The model is trained using a multi-task and multi-stage supervised fine-tuning (SFT) strategy, which involves part layout prediction, kinematic prediction, and end-to-end articulation prediction. This approach decouples geometric understanding from kinematic reasoning, establishing a robust foundation for the model.
In the second stage, the predicted structural blueprint serves as a condition for a part-aware generative model, specifically XPart, to synthesize high-fidelity part geometries. To prevent geometric truncation when predicted bounding boxes do not perfectly encompass the ground-truth geometry, the authors implement a bounding box expansion step. Any point in the input cloud not contained within a predicted box is assigned to its nearest box based on Euclidean distance, and the box is subsequently expanded to tightly enclose these points.
The final stage is a physically-constrained joint limit correction module designed to prevent inter-part collisions. Since the LLM predicts joint limits based on a single geometric state, the resulting assets might suffer from collisions during motion. The authors address this by articulating the child part through its predicted range and computing the collision volume against other static parts. As illustrated in the figure below, significant collisions are identified by sharp spikes in the derivative of the collision volume relative to the joint angle. A hierarchical search is then performed within the identified angular window to find the precise angle of initial contact, which is then set as the refined, collision-free joint limit.
Experiment
The authors evaluate their approach by comparing it against state-of-the-art articulation generation methods and conducting ablation studies to validate individual module contributions. Qualitative and quantitative assessments demonstrate that the proposed method superiorly recovers accurate part layouts, joint types, and kinematic hierarchies compared to baseline models that often struggle with misaligned axes or incorrect geometry. Furthermore, a real-to-sim evaluation confirms that the generated assets faithfully preserve real-world articulation properties, making them suitable for practical robotic simulation tasks.
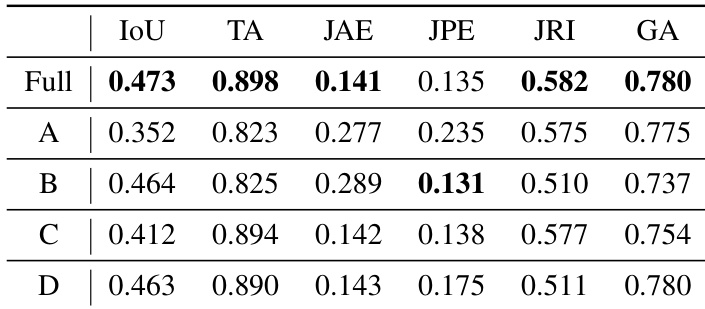
The authors conduct ablation studies to evaluate the impact of different components on the model's performance across several metrics. The results demonstrate that the full configuration achieves superior performance in most categories, particularly in part layout and joint type accuracy. The full model achieves the highest performance in part layout IoU, joint type accuracy, and graph accuracy. Removing multi-task learning or changing the training stage leads to declines in most key metrics. Data augmentation through random scaling and rotation is shown to be essential for improving part layout IoU.
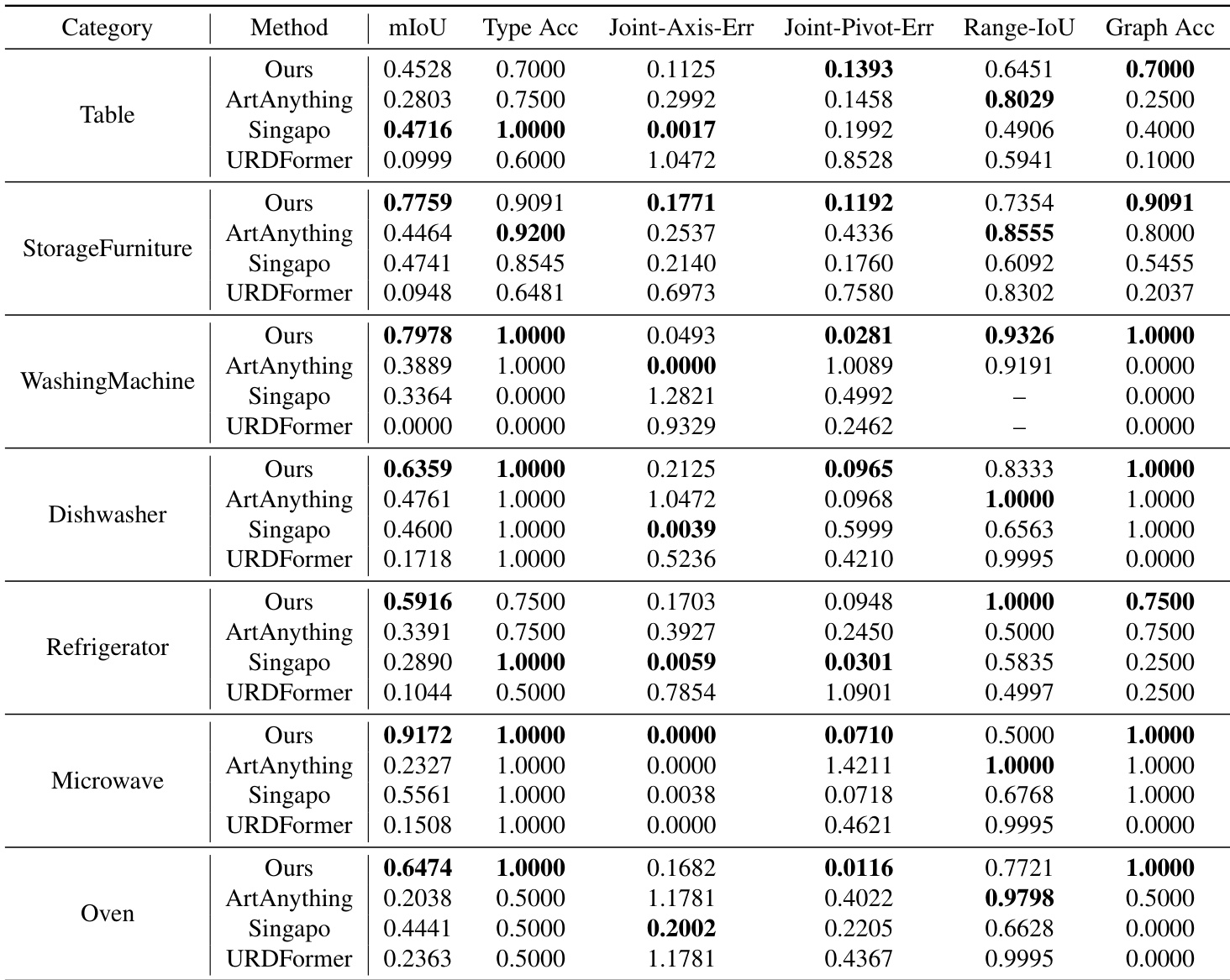
The authors compare their proposed method against several baseline approaches across various articulation and part prediction metrics. Results show that the proposed method outperforms existing models in most categories, including part layout, joint type accuracy, and hierarchical structure modeling, while also being significantly faster during inference. The proposed method achieves superior performance in part layout and joint origin prediction compared to the baselines. While some baseline methods show competitive results in specific areas like joint range, they generally lag in joint axis and pivot error metrics. The proposed approach demonstrates a substantial reduction in inference time compared to the other evaluated methods.
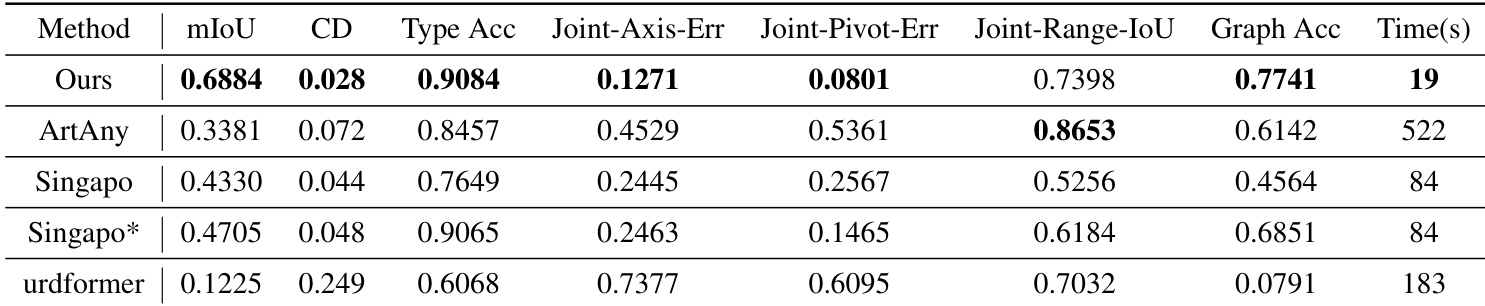
The authors perform ablation studies and comparative analyses to evaluate the effectiveness of individual model components and the overall performance against existing baselines. The ablation results confirm that multi-task learning and specific data augmentation techniques are critical for achieving high accuracy in part layouts and joint types. Furthermore, the proposed method demonstrates superior modeling of hierarchical structures and joint properties while offering significantly faster inference speeds than competing approaches.