Command Palette
Search for a command to run...
실험적 메모리 증강 LLM 에이전트: 하이브리드 온폴리시 및 오프폴리시 최적화를 통한 접근
실험적 메모리 증강 LLM 에이전트: 하이브리드 온폴리시 및 오프폴리시 최적화를 통한 접근
Zeyuan Liu Jeonghye Kim Xufang Luo Dongsheng Li Yuqing Yang
초록
강화학습을 통해 훈련된 대규모 언어 모델 에이전트의 핵심 과제는 탐색(Exploration)이다. 기존의 방법들은 사전 학습된 지식을 활용하지만, 새로운 상태를 탐지해야 하는 환경에서는 실패한다. 본 연구에서는 탐색을 위한 메모리 활용과 온-폴리시 및 오프-폴리시 업데이트의 결합을 통해 메모리가 있는 환경에서도 효과적으로 작동하면서도 메모리 없이도 강건성을 유지할 수 있도록 설계된 하이브리드 강화학습 프레임워크인 탐색용 메모리 증강형 온-오프-폴리시 최적화(Exploratory Memory-Augmented On- and Off-Policy Optimization, EMPO²)를 제안한다. ScienceWorld 및 WebShop 환경에서 EMPO²는 GRPO 대비 각각 128.6%, 11.3%의 성능 향상을 달성하였다. 또한 분포 외 테스트에서 EMPO²는 새로운 작업에 대해 뛰어난 적응성을 보였으며, 메모리 사용과 함께 몇 차례의 시도만으로도 효과적인 성능을 발휘했고, 파라미터 업데이트 없이도 가능했다. 이러한 결과들은 EMPO²가 더 탐색적이고 일반화 능력이 뛰어난 LLM 기반 에이전트를 구축하는 데 있어 매우 유망한 프레임워크임을 시사한다.
One-sentence Summary
Microsoft Research and KAIST researchers propose EMPO², a hybrid RL framework using memory-augmented exploration and dual-policy updates to enhance LLM agents’ adaptability, outperforming GRPO by 128.6% on ScienceWorld and 11.3% on WebShop while requiring minimal trials for new tasks.
Key Contributions
- EMPO² addresses the exploration bottleneck in LLM agents by introducing a hybrid RL framework that combines on- and off-policy learning with memory-augmented exploration, enabling agents to discover novel states beyond pretrained knowledge.
- The method dynamically updates both parametric policy weights and non-parametric memory during training, allowing agents to bootstrap exploration and improve robustness even when memory is unavailable during deployment.
- Evaluated on ScienceWorld and WebShop, EMPO² achieves 128.6% and 11.3% gains over GRPO, respectively, and demonstrates strong out-of-distribution adaptability with minimal trials and no parameter updates, validating its generalization capability.
Introduction
The authors leverage reinforcement learning to enhance LLM agents’ ability to explore unfamiliar environments, addressing a key gap: most current agents rely too heavily on pretrained knowledge and fail to systematically explore novel states. Prior memory-augmented methods improve short-term adaptation but stagnate due to fixed parameters, while online RL approaches like GRPO lack sufficient exploration to escape local optima. Their main contribution is EMPO², a hybrid on- and off-policy algorithm that jointly updates both model parameters and external memory, enabling continuous exploration, faster convergence, and strong few-shot generalization across tasks like ScienceWorld and WebShop.
Dataset
- The authors evaluate EMPO² on ScienceWorld and WebShop, two publicly available research benchmarks that contain no private or sensitive data.
- Both datasets are used as-is, with no modifications or additional data collection; all usage complies with original licenses and community standards.
- The study is confined to simulated environments to avoid risks associated with deploying online RL systems in safety-critical real-world settings.
- For real-world applications, the authors emphasize that LLM-generated responses must undergo stricter scrutiny to ensure safety.
- No dataset-specific preprocessing, cropping, or metadata construction is mentioned; the focus is on benchmark evaluation within existing environments.
Method
The authors leverage a hybrid learning framework called Exploratory Memory-augmented On- and Off-Policy Optimization (EMPO²) to address exploration challenges in online reinforcement learning with large language models. The method integrates both parametric updates—via policy gradient optimization—and non-parametric updates—via an external memory buffer that stores self-generated reflective tips. This dual mechanism enables the agent to learn from past experiences while gradually internalizing guidance into its policy parameters.
At the core of EMPO² is a memory buffer M that stores tips generated by the policy πθ itself after each episode. When an episode terminates, the policy is prompted to reflect on the final state and task, producing a tip such as “You focused on the red light bulb but did not complete the task of turning it on.” These tips are stored in memory and later retrieved during rollouts to condition action generation. The retrieval operator Retr(st;M) selects up to 10 tips most relevant to the current state st, typically via cosine similarity in an embedding space. This memory-augmented prompting allows the agent to avoid repeated mistakes and explore novel strategies.
Refer to the framework diagram, which illustrates the three learning modes enabled by combining two rollout modes and two update modes. In the first mode, the agent performs prompting without memory, generating actions conditioned only on the current state and task: at+1∼πθ(⋅∣st,u). In the second mode, memory-augmented prompting is used: at+1∼πθ(⋅∣st,u,tipst). During the update phase, trajectories from memory-augmented rollouts can be processed in one of two ways: on-policy, where the update uses the same tips as in the rollout, or off-policy, where the tips are removed and the policy is updated based on its unconditioned distribution πθ(⋅∣st,u).
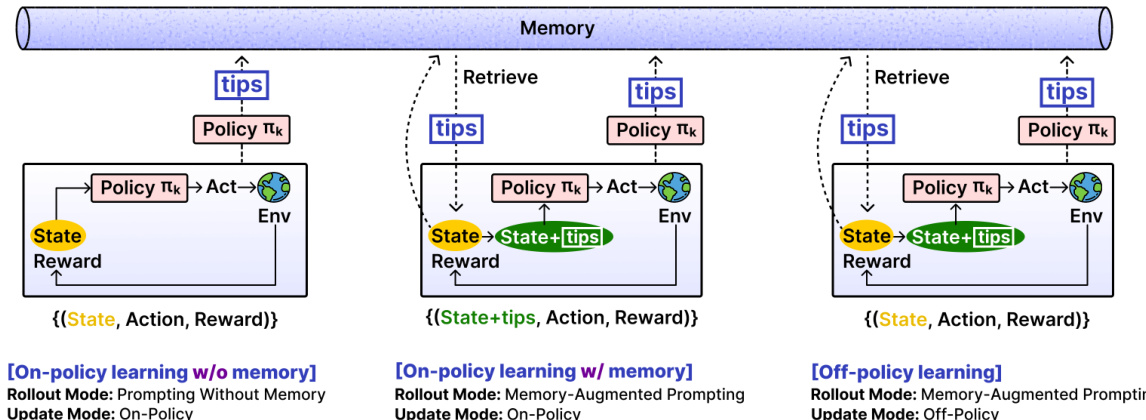
The off-policy update mode is particularly critical for knowledge internalization. It functions as a form of reward-guided knowledge distillation: trajectories sampled under tip-conditioned policies serve as teacher demonstrations, while the student policy πθ(⋅∣s,u) is updated to reproduce high-advantage actions and suppress low-advantage ones. The importance sampling ratio ρθ is adjusted accordingly: for off-policy updates, the log-probability under the tip-conditioned old policy is replaced with the log-probability under the unconditioned current policy. This mismatch enables the base policy to absorb the benefits of tip guidance without requiring tips at inference time.
To stabilize off-policy training, which is prone to gradient explosion, the authors introduce a masking mechanism. Tokens with probability below a threshold δ under πθ(⋅∣st,u) are excluded from the advantage-weighted loss. The modified GRPO loss becomes:
Eu∼p(U){τ(i)}∼πθold[NT1∑i=1N∑t=1Tmin(ρθ(i,t)A(at(i)),clip(ρθ(i,t),1−ϵ,1+ϵ)A(at(i)))⋅1πθ(at(i)∣st(i),u)≥δ]−βDKL(πθ(⋅∣u)∥πref(⋅∣u)),where ρθ(i,t)=πθold(at(i)∣st(i),u,tipst)πθ(at(i)∣st(i),u) for off-policy updates.
To further encourage exploration, EMPO² incorporates an intrinsic reward based on state novelty. A memory list stores distinct states, and for each new state, its cosine similarity with existing entries is computed. If similarity falls below a threshold, the state is added to memory and assigned an intrinsic reward rintrinsic=n1, where n is the number of similar past states. This mechanism promotes exploration of novel states even in the absence of extrinsic rewards and helps maintain policy entropy.
As shown in the figure below, the agent’s learning trajectory evolves from initial failures to successful task completion, guided by non-parametric memory updates and off-policy internalization. The policy π0 may fail to locate the red light bulb, but after reflecting and storing tips such as “The red light bulb isn’t here, so you need to find it first,” subsequent policies like π100 leverage these tips to explore more effectively and ultimately succeed.
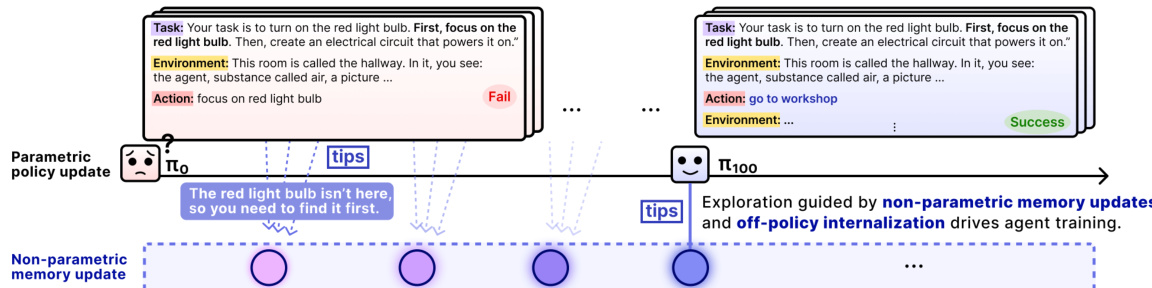
The overall architecture is implemented as a multi-step rollout with alternating policy updates. At each training iteration, the agent samples tasks, performs rollouts under either memory-augmented or memory-free prompting, generates and stores tips, and then updates the policy using one of the three learning modes. The memory buffer is implemented as a fast, retrievable key-value store with cosine similarity search and a fixed capacity, ensuring efficient access to relevant tips during rollouts.
Experiment
- EMPO² significantly improves exploration and generalization in LLM agents by combining memory-augmented on-policy and off-policy learning, outperforming baselines like GRPO, Reflexion, and Retrospex on ScienceWorld and WebShop.
- In ScienceWorld, EMPO² achieves over twice the performance gain of GRPO, mastering complex multi-step tasks and reaching maximum scores in several cases, demonstrating strong long-term planning and hypothesis testing.
- On WebShop, EMPO² surpasses all baselines including GiGPO, showing superior success rates and scores due to enhanced exploration in web navigation and decision-making.
- EMPO² adapts rapidly to novel tasks using memory updates, achieving 136% average improvement within 10 steps across diverse domains, while GRPO shows inconsistent or degraded performance.
- Ablation studies confirm that both on-policy memory and off-policy updates are essential; removing either degrades performance, highlighting their complementary roles in stable and efficient learning.
- Intrinsic reward is critical for preventing policy collapse and encouraging exploration, though its specific form or scale mainly affects learning speed, not final performance.
- Memory integration adds moderate computational overhead (~19% rollout time) but delivers substantial gains in learning efficiency, with EMPO² remaining more time-efficient than GRPO overall.
The authors use EMPO² to enhance large language model agents by combining memory-augmented exploration with hybrid on- and off-policy reinforcement learning. Results show that EMPO² consistently outperforms baseline methods across ScienceWorld tasks, achieving significantly higher average returns and solving previously failed tasks to completion. The framework also demonstrates strong generalization, adapting rapidly to new tasks with minimal memory updates and no parameter changes.
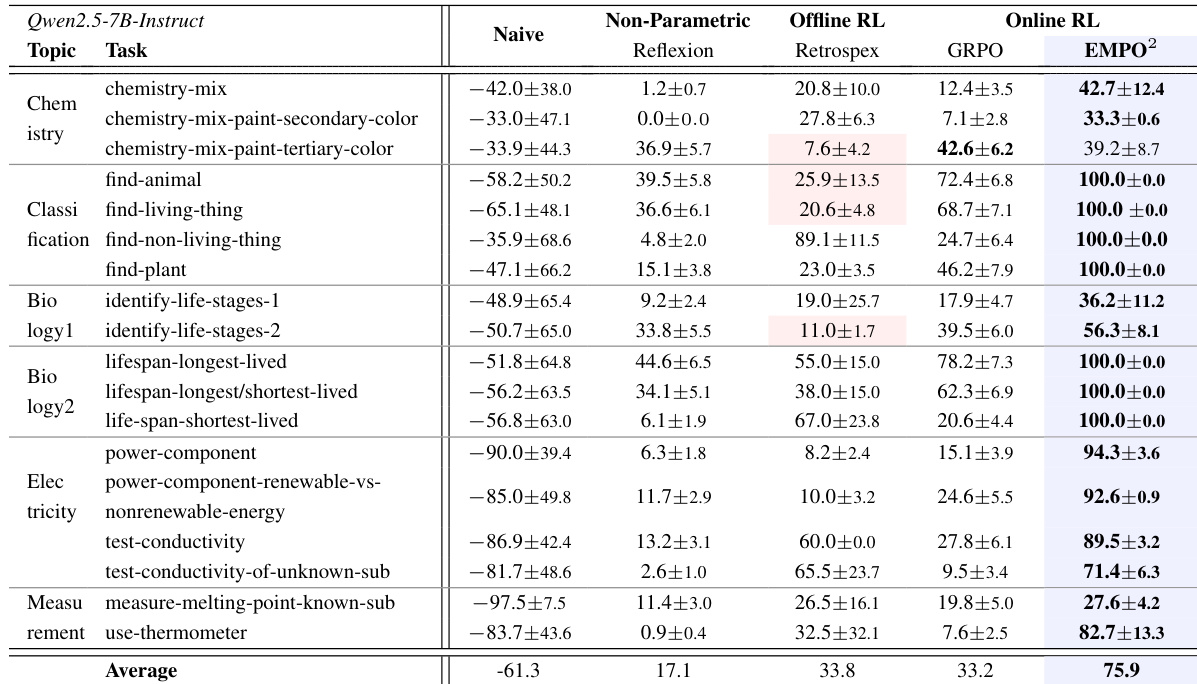
The authors use EMPO² to enhance large language model agents by combining memory-augmented exploration with hybrid on- and off-policy reinforcement learning. Results show EMPO² outperforms all baselines in both ScienceWorld and WebShop, achieving higher scores and success rates while demonstrating stronger adaptability to novel tasks with minimal memory updates. The framework’s effectiveness stems from the complementary roles of its components, enabling faster convergence and more robust generalization without requiring parameter updates during adaptation.
