Command Palette
Search for a command to run...
MobilityBench: 실제 이동 환경에서의 경로 계획 Agent 평가를 위한 벤치마크
MobilityBench: 실제 이동 환경에서의 경로 계획 Agent 평가를 위한 벤치마크
Zhiheng Song Jingshuai Zhang Chuan Qin Chao Wang Chao Chen Longfei Xu Kaikui Liu Xiangxiang Chu Hengshu Zhu
초록
대규모 언어 모델(Large Language Models, LLMs)을 기반으로 한 경로 계획 에이전트는 자연어 상호작용과 도구 기반 의사결정을 통해 일상적인 인간 이동을 지원하는 유망한 패러다임으로 부상하고 있다. 그러나 다양한 경로 요구사항, 비결정적(Non-deterministic)인 지도 서비스, 그리고 제한된 재현 가능성 등의 문제로 인해 실세계 이동 환경에서의 체계적 평가가 어려운 실정이다. 본 연구에서는 실세계 이동 시나리오에서 LLM 기반 경로 계획 에이전트를 평가하기 위한 확장 가능한 벤치마크인 MobilityBench를 제안한다. MobilityBench는 Amap에서 수집한 대규모 익명화 사용자 쿼리 데이터를 기반으로 구성되었으며, 세계 여러 도시를 아우르는 다양한 경로 계획 목적을 포괄한다. 재현 가능한 엔드투엔드 평가를 가능하게 하기 위해, 실시간 서비스에서 발생하는 환경적 변동을 제거하는 결정론적 API 재생 샌드박스를 설계하였다. 또한 결과의 타당성(Outcome Validity)을 중심으로 하는 다차원 평가 프로토콜을 제안하였으며, 지시 이해, 계획 수립, 도구 활용, 효율성 등 다양한 측면에서의 평가도 포함한다. MobilityBench를 활용해 다양한 실세계 이동 시나리오에서 다수의 LLM 기반 경로 계획 에이전트를 평가하고, 그 행동과 성능에 대해 심층 분석을 수행하였다. 연구 결과, 현재 모델들은 기본 정보 검색 및 경로 계획 작업에서는 충분한 성능을 보이지만, 선호도 제약이 있는 경로 계획(Preference-Constrained Route Planning)에서는 상당한 어려움을 겪고 있음을 확인하였으며, 이는 개인화된 이동 응용 분야에서 향상 여지가 크다는 점을 시사한다. 본 연구에서는 벤치마크 데이터, 평가 툴킷 및 문서를 공개하여 https://github.com/AMAP-ML/MobilityBench 에서 누구나 접근할 수 있도록 제공한다.
One-sentence Summary
Researchers from CNIC, CAS, and AMAP, Alibaba Group introduce MobilityBench, a scalable, reproducible benchmark for evaluating LLM-based route-planning agents using real-world Amap queries, revealing strengths in basic tasks but persistent gaps in preference-constrained planning for personalized mobility.
Key Contributions
- MobilityBench introduces a scalable, real-world benchmark for evaluating LLM-based route-planning agents, built from anonymized user queries across 350+ global cities and covering diverse intents like multi-waypoint routing, multimodal transit, and preference-aware navigation.
- To ensure reproducibility, the benchmark employs a deterministic API-replay sandbox that caches and replays mapping service responses, eliminating environmental variance from live traffic and service updates during evaluation.
- The evaluation protocol combines outcome validity with assessments of instruction understanding, planning, tool use, and efficiency, revealing that current models perform well on basic tasks but struggle with preference-constrained routing, highlighting gaps in personalized mobility support.
Introduction
The authors leverage large language models to build route-planning agents that can handle complex, real-world mobility requests via natural language and API interactions. Prior benchmarks fall short by focusing on high-level itinerary planning rather than fine-grained, constraint-rich navigation over real map data, and they suffer from non-deterministic live APIs that hinder reproducibility. MobilityBench addresses this by introducing a scalable, real-world benchmark built from anonymized Amap user queries across 350+ cities, paired with a deterministic API-replay sandbox to ensure consistent evaluation. Their multi-dimensional protocol evaluates not just outcome validity but also instruction understanding, planning, tool use, and efficiency—revealing that current models handle basic tasks well but struggle with preference-constrained routing, highlighting a key gap for future work. The benchmark, toolkit, and data are publicly released to support reproducible, extensible research.
Dataset

- The authors use MobilityBench, a scalable benchmark built from 100,000 anonymized mobility queries collected over six months from AMap, to evaluate route-planning agents in real-world scenarios.
- Each episode is a four-tuple: (x, z, S, y), where x is a natural-language query, z provides context like user location, S is a replayable API snapshot, and y is a structured ground-truth annotation used only for evaluation.
- Queries are voice-based, transcribed to text, and filtered to remove malformed or ambiguous requests; near-duplicates are deduplicated to ensure diversity.
- Task taxonomy is built using Qwen-4B for intent classification, expanded via open-set labeling, and refined by experts into 11 scenarios grouped into 4 families: Basic Information Retrieval, Route-Dependent Information Retrieval, Basic Route Planning, and Preference-Constrained Route Planning.
- Ground-truth annotations (y) are constructed via expert-defined SOPs, implemented as executable tool programs that extract slots, resolve locations, and invoke routing/weather/traffic tools; outputs are validated and archived for evaluation.
- All tool interactions run through a deterministic replay sandbox that caches AMap API responses; unmatched calls use fallback strategies like fuzzy matching or spatial nearest-neighbor lookup, with strict schema validation.
- The dataset spans 22 countries and 350+ cities, with task distribution: 36.6% Basic Info Retrieval, 9.6% Route-Dependent Info Retrieval, 42.5% Basic Route Planning, and 11.3% Preference-Constrained Route Planning.
- Episodes are filtered to retain only those with verifiable, executable outcomes; agents never see ground truth and cannot ask for clarification, ensuring self-contained, solvable queries.
Experiment
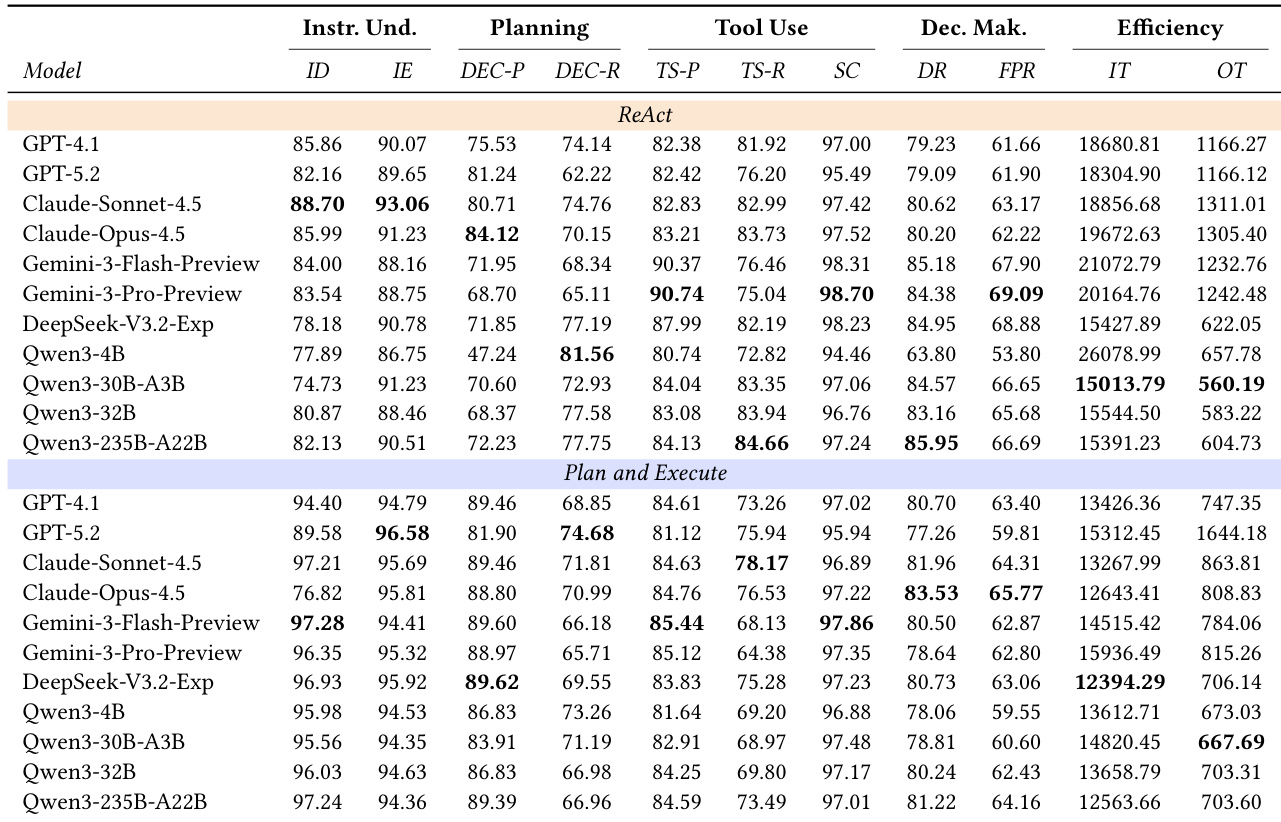
- Introduced a multi-dimensional evaluation protocol breaking down route-planning agents into four core capabilities: Instruction Understanding, Planning, Tool Use, and Decision Making, enabling fine-grained diagnosis beyond end-to-end success rates.
- Evaluated agents across 7,098 real-world mobility episodes using diverse LLMs (open-source and closed-source) under two frameworks: ReAct and Plan-and-Execute.
- Claude-Opus-4.5 and Gemini-3-Pro-Preview led in overall performance; open-source models like Qwen3-235B-A22B and DeepSeek-V3.2-Exp showed strong competitiveness, especially in cost-efficiency.
- ReAct outperformed Plan-and-Execute in task success due to its dynamic feedback loop, but incurred ~35% higher input token usage, increasing computational cost.
- Plan-and-Execute excelled in preference-constrained, logic-heavy scenarios by enforcing upfront planning, reducing deviation and hallucination.
- Larger models consistently improved performance, following scaling laws, with MoE architectures offering notable gains; larger models also generated longer, more exhaustive plans.
- Enabling “Thinking” mode boosted final pass rates across models (up to +6% for Qwen-30B-A3B) but significantly increased token output and latency, limiting real-time deployment viability.
The authors use a multi-dimensional evaluation protocol to assess route-planning agents across instruction understanding, planning, tool use, decision making, and efficiency, revealing that closed-source models like Claude-Opus-4.5 and Gemini-3-Pro-Preview generally lead in task success, while large open-source models such as Qwen3-235B-A22B show competitive performance with lower computational cost. Results show that the ReAct framework achieves higher final pass rates due to its dynamic feedback loop but incurs significantly higher token usage, whereas Plan-and-Execute offers better efficiency at the cost of reduced robustness in complex scenarios. Model scaling and reasoning modes both improve performance, with larger models and enabled thinking yielding higher success rates, though at the expense of increased latency and resource consumption.