Command Palette
Search for a command to run...
GUI-Libra: 동작 인지 감독과 부분 검증 가능한 RL을 통한 네이티브 GUI 에이전트의 추론 및 행동 훈련
GUI-Libra: 동작 인지 감독과 부분 검증 가능한 RL을 통한 네이티브 GUI 에이전트의 추론 및 행동 훈련
초록
오픈소스 네이티브 GUI 에이전트는 여전히 폐쇄형 시스템에 비해 장기 예측 탐색 작업에서 뒤처지고 있다. 이 격차는 두 가지 제약에 기인한다: 고품질의 동작과 일치하는 추론 데이터 부족과, GUI 에이전트만의 고유한 도전 과제를 간과한 일반화된 사후 훈련 파이프라인의 직접적 채택이다. 본 연구에서는 이러한 파이프라인 내에서 존재하는 두 가지 근본적인 문제를 규명한다. (i) 일반적인 CoT 추론을 사용한 SFT는 종종 지각(grounding)을 약화시킨다. (ii) 단계별 RLVR 유사 훈련은 부분적 검증성(partial verifiability) 문제를 겪는데, 여러 동작이 정확할 수 있지만 검증에는 단 하나의 예시 동작만 사용되기 때문이다. 이로 인해 오프라인 단계별 지표는 온라인 작업 성공률을 약한 예측자로 만든다. 본 연구에서는 이러한 과제를 해결하기 위해 GUI-Libra라는 맞춤형 훈련 레시피를 제안한다. 첫째, 동작과 일치하는 추론 데이터의 부족을 완화하기 위해 데이터 구성 및 필터링 파이프라인을 도입하고, 정교하게 추려낸 81,000개의 GUI 추론 데이터셋을 공개한다. 둘째, 추론과 지각의 조화를 도모하기 위해 추론-후-동작과 직접 동작 데이터를 혼합하는 동작 인식 SFT를 제안하며, 동작과 지각을 강조하기 위해 토큰 재가중 기법을 도입한다. 셋째, 부분적 검증성 하에서 RL의 안정성을 확보하기 위해 RLVR에서 KL 정규화의 간과된 중요성을 식별하고, KL 신뢰 영역이 오프라인에서 온라인으로의 예측 가능성을 향상시키는 데 필수적임을 보여준다. 더 나아가, 신뢰할 수 없는 음성 기울기를 감소시키기 위해 성공 기반 적응형 스케일링 기법을 도입한다. 다양한 웹 및 모바일 벤치마크에서 GUI-Libra는 단계별 정확도와 엔드투엔드 작업 완료율 모두에서 일관되게 성능 향상을 보였다. 본 연구 결과는 신중하게 설계된 사후 훈련 및 데이터 정제가 비용이 큰 온라인 데이터 수집 없이도 훨씬 강력한 작업 해결 능력을 발휘할 수 있음을 시사한다. 본 연구는 데이터셋, 코드, 모델을 공개하여 추론 능력을 갖춘 GUI 에이전트를 위한 데이터 효율적인 사후 훈련 연구를 촉진하고자 한다.
One-sentence Summary
Researchers from UIUC, Microsoft, and UNC-Chapel Hill introduce GUI-Libra, a tailored training framework that enhances open-source GUI agents by curating 81K reasoning data, refining SFT with action-aware supervision, and stabilizing RL via KL regularization—boosting task completion across Android, web, and mobile benchmarks without costly online data.
Key Contributions
- To address the scarcity of high-quality reasoning data for GUI agents, GUI-Libra introduces a scalable data construction and filtering pipeline, releasing a curated 81K dataset that aligns reasoning traces with executable actions for more effective supervision.
- The framework proposes action-aware supervised fine-tuning that mixes reasoning-then-action and direct-action supervision, reweighting tokens to prioritize grounding and action tokens, thereby mitigating the grounding accuracy drop typically caused by long chain-of-thought reasoning.
- For reinforcement learning under partial verifiability, GUI-Libra stabilizes training with KL regularization and success-adaptive scaling, improving offline-to-online predictability and achieving significant gains on AndroidWorld, Online-Mind2Web, and WebArena-Lite-v2 benchmarks.
Introduction
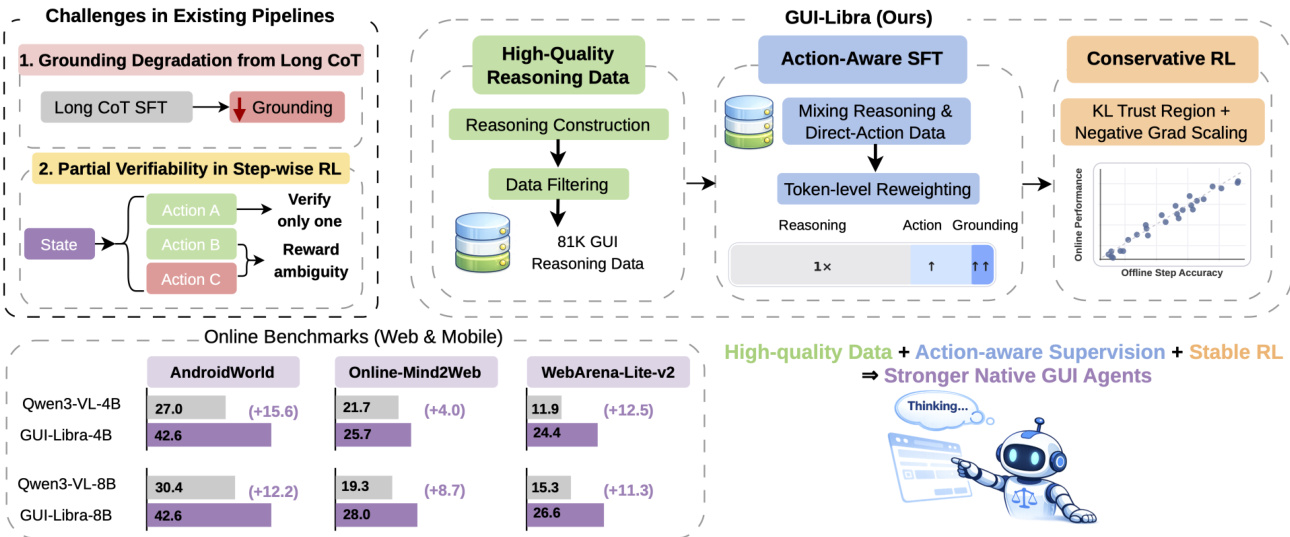
The authors leverage native GUI agents—end-to-end vision-language models that directly map instructions to executable actions—to tackle long-horizon navigation tasks where reasoning and precise grounding must coexist. Prior work struggles with two key issues: scarce, noisy reasoning data that weakens policy learning, and generic post-training pipelines that fail to account for GUI-specific challenges like partial verifiability, where multiple valid actions exist but only one is labeled, leading to reward ambiguity and unstable RL. Their main contribution is GUI-Libra, a unified training framework that introduces a curated 81K action-aligned reasoning dataset, action-aware supervised fine-tuning that prioritizes grounding tokens to prevent CoT-induced degradation, and conservative RL with KL regularization and success-adaptive gradient scaling to stabilize learning under partial feedback. This approach boosts task completion across mobile and web benchmarks without requiring costly online interaction, proving that smarter data curation and training design can close performance gaps with closed-source systems.
Dataset

), (2) structured action in JSON (wrapped in ...).
-
13 action types supported: Click, Write, Terminate, Swipe, Scroll, NavigateHome, Answer, Wait, OpenAPP, NavigateBack, KeyboardPress, LongPress, Select.
-
Action_target (natural-language UI element description) and action_description (brief rationale) are included for filtering and context.
-
Reasoning Augmentation:
- Uses GPT-4.1 (selected after comparing GPT-4o, o4-mini, GPT-4.1) with an enhanced prompt that includes GUI-specific guidelines for structured reasoning.
- Generator can override original action if justified; coordinates from original dataset are retained as point_2d.
- Mismatches (e.g., wrong target or action) are filtered post-generation.
-
Use in Training:
- SFT dataset trains the model to map visual + textual context to reasoning + action.
- RL dataset refines policy with balanced step and domain coverage.
- Bounding-box annotations from filtering support RL reward computation.
-
Evaluation Benchmarks:
- Grounding: ScreenSpot-V2 (1,269 tasks) and ScreenSpot-Pro (1,555 tasks, high-res) measure click accuracy within ground-truth bounding boxes.
- Navigation:
- MM-Mind2Web-v2 (3,349 samples across 3 subsets) uses natural-language rewritten action histories; success requires correct grounding + exact-match action execution.
- AndroidControl-v2 (398 cleaned samples) validates action type, value, and coordinate correctness using accessibility tree mapping — avoids fixed distance thresholds.
This pipeline enables training of GUI agents that reason step-by-step, act accurately, and generalize across platforms — while addressing the scarcity of high-quality, reasoning-rich interaction data.
Method
The authors leverage a two-stage training framework, GUI-Libra, to build native GUI agents capable of both reasoning and acting within a single model. The framework addresses key challenges in existing pipelines, including grounding degradation from long chains of thought (CoT) and the partial verifiability of step-wise rewards in reinforcement learning. The overall architecture is designed to produce agents that are not only accurate in action prediction but also robust to distribution shifts and reward ambiguity during long-horizon navigation.
Refer to the framework diagram, which illustrates the end-to-end pipeline. The process begins with the construction of high-quality reasoning data, followed by an action-aware supervised fine-tuning (ASFT) stage that mixes reasoning-then-action and direct-action supervision. This is succeeded by a conservative reinforcement learning (RL) stage that incorporates KL regularization and success-adaptive negative gradient scaling to stabilize policy optimization under partially verifiable rewards.
In Stage 1, the authors introduce Action-Aware SFT, which trains on a mixture of data with and without explicit reasoning traces. The mixed dataset includes both reasoning-then-action samples, where the model generates a thought process before outputting an action, and direct-action samples, where only the structured action output between and is retained. This dual-mode supervision increases the learning signal for action prediction while reducing reliance on verbose intermediate reasoning, thereby mitigating grounding degradation. The training objective further incorporates token-level reweighting, assigning higher weights to action and grounding tokens. Concretely, tokens inside ... are treated as the action output and split into action tokens (excluding the point_2d field) and grounding tokens (associated with point_2d). The ASFT objective is formulated as a weighted cross-entropy loss:
LASFT(θ)=−E(xt,ct,at,gt)∼Dmix∣ct∣+αa∣at∣+αg∣gt∣logπθ(ct∣xt)+αalogπθ(at∣xt,ct)+αglogπθ(gt∣xt,ct,at),where αa and αg control the relative importance of action and grounding tokens. This flexible weighting scheme allows the model to emphasize action-centric learning while preserving reasoning capability.
As shown in the figure below, Stage 2 employs Conservative RL, which builds upon the ASFT-initialized policy. The authors adopt a group-relative policy optimization (GRPO) framework under partially verifiable step-wise rewards. To address the challenges of distribution shift and reward ambiguity, they introduce two key components: KL regularization and success-adaptive negative gradient scaling (SNGS). KL regularization constrains policy drift by maintaining a trust region relative to a reference policy, typically the SFT initialization. This helps control the occupancy mismatch C(π) and the off-demo validity mass ηˉπ, ensuring that offline matching scores remain predictive of online success. SNGS further refines the policy gradient updates by downweighting gradients induced by ambiguous "negative" outcomes. Specifically, for each state, the empirical group success rate p^g(s) is computed from a group of G candidate actions, and a scaling factor λg(s) is applied only to negative advantages:
A~k≜{Ak,λg(s)Ak,Ak≥0,Ak<0.where λg(s)=min(λ0+κp^g(s),1). This conservative update strategy preserves reliable positive signals while attenuating updates driven by potentially valid but uncredited alternatives, leading to more robust policy optimization.
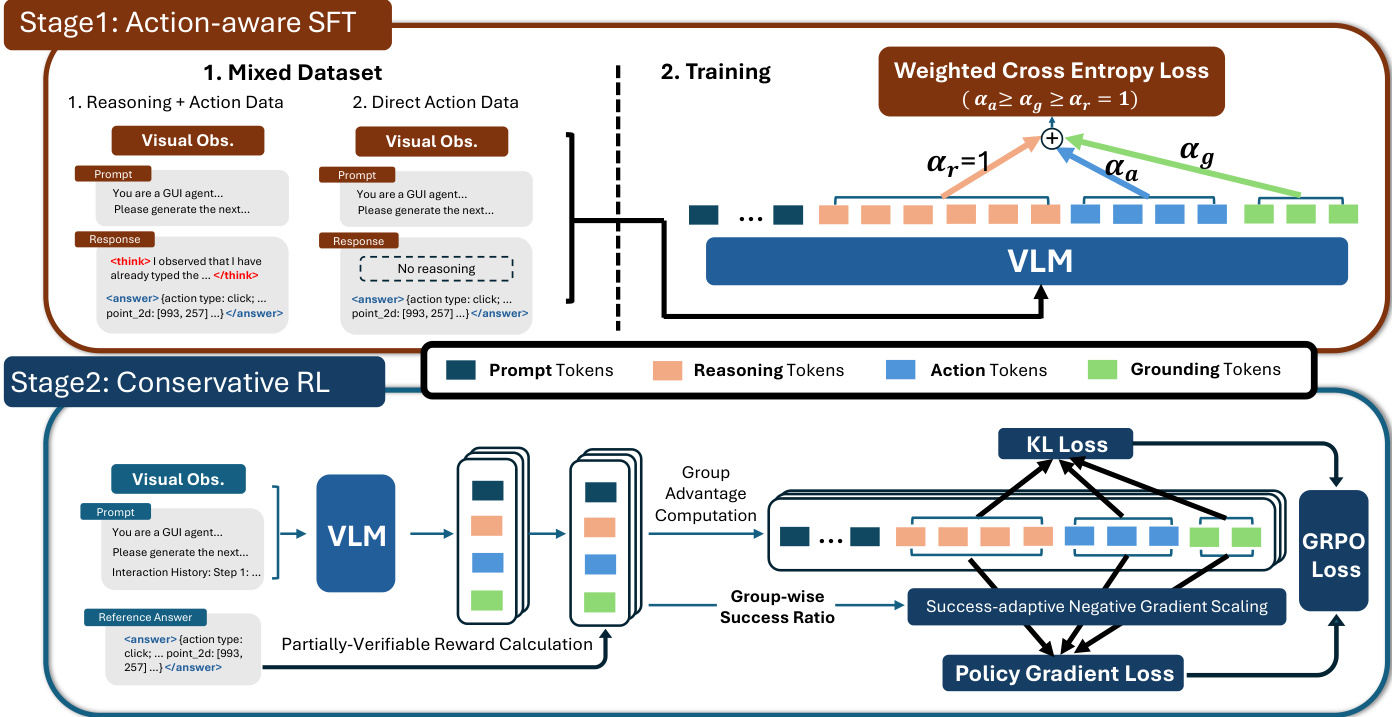
The reward function implemented in the RL stage is a weighted sum of format and accuracy rewards, with the latter being the primary focus. The accuracy reward evaluates semantic correctness by checking action type, value (using word-level F1), and grounding (whether the predicted point falls within the demonstrated bounding box). This design aligns with the partial-verifiability setting, where positive rewards indicate reliably correct predictions, while low rewards may arise from either incorrect actions or valid but uncredited alternatives.
Experiment
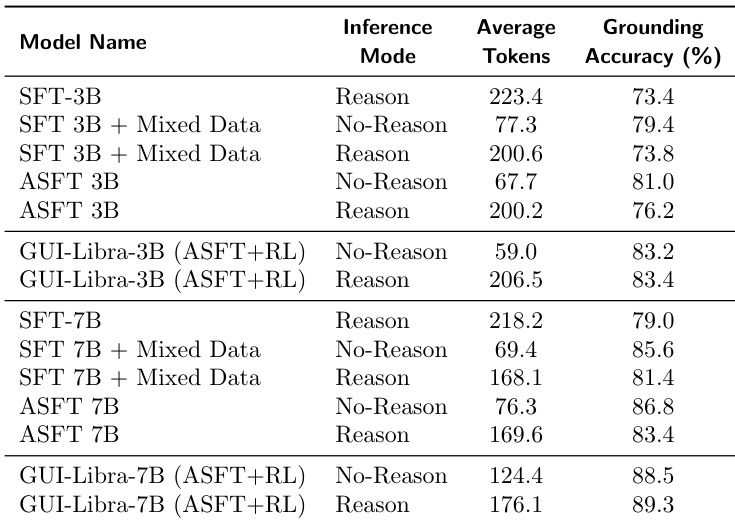
- Long CoT reasoning degrades GUI grounding accuracy, with performance declining as response length increases; removing CoT or using grounding-only training mitigates this but limits reasoning benefits.
- Action-aware SFT and RL training effectively counteract grounding degradation from long CoT by aligning reasoning with action execution, enabling high accuracy even with extended outputs.
- GUI-Libra consistently outperforms base models and many larger proprietary systems across offline and online benchmarks, particularly in long-horizon, real-world environments like AndroidWorld and live websites.
- KL regularization in RL stabilizes training, improves policy entropy, and strengthens the correlation between offline metrics and online task success, reducing reward hacking.
- Data filtering during SFT and RL enhances generalization by focusing on high-quality, balanced samples, yielding significant gains in both Pass@1 and Pass@4 metrics.
- Mixing direct grounding supervision into RL improves spatial localization but harms navigation performance, revealing a trade-off between grounding precision and reasoning capability.
- Explicit reasoning during both training and inference is critical for strong online generalization, especially in dynamic environments; removing CoT at inference degrades performance despite training with it.
- GUI-Libra’s gains stem primarily from improved grounding accuracy rather than action-type prediction, as shown by fine-grained offline metric analysis.
The authors find that longer reasoning outputs during inference consistently degrade grounding accuracy in GUI agents, but this effect is mitigated by action-aware supervised fine-tuning and further resolved through reinforcement learning. Models trained with mixed data and RL achieve high grounding accuracy even when generating long reasoning traces, outperforming both base models and standard SFT variants. Results show that RL enables models to maintain or exceed grounding performance in reasoning mode while producing significantly more tokens, indicating improved alignment between reasoning and action execution.
The authors find that GUI-Libra consistently outperforms both open-source and proprietary models across multiple benchmarks, achieving state-of-the-art results even with smaller parameter counts. Their method effectively mitigates the grounding degradation typically caused by long reasoning traces through action-aware SFT and RL, enabling robust performance in both offline and online settings. Results show that explicit reasoning during training and inference is critical for generalization, particularly in dynamic environments.
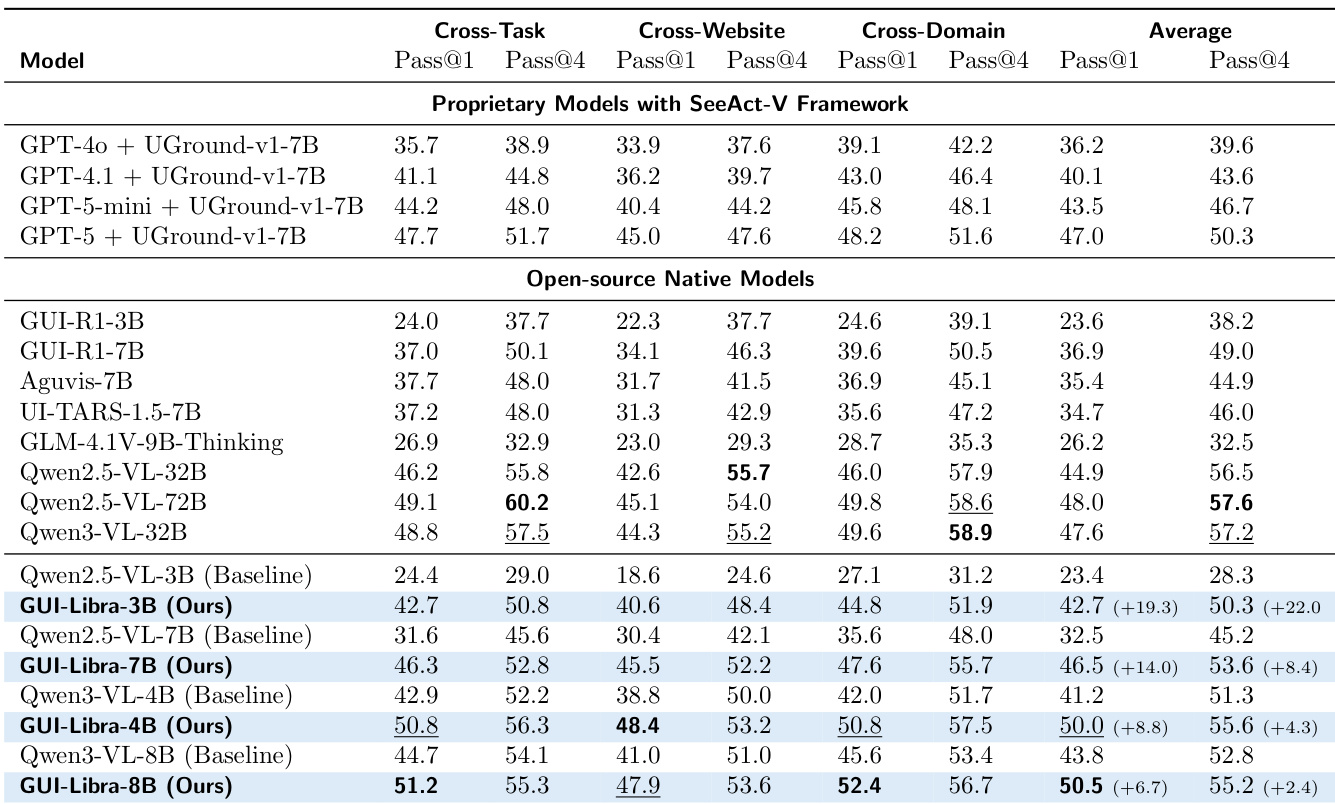
The authors show that GUI-Libra models consistently outperform both their base counterparts and other open-source and proprietary models across multiple benchmarks, achieving top-tier performance even at smaller scales. Results indicate that the method effectively closes the gap between smaller models and larger systems, particularly in cross-domain and cross-website settings, while maintaining strong average performance. The gains are attributed to the training pipeline’s ability to enhance reasoning and grounding without requiring large-scale or domain-specific data.
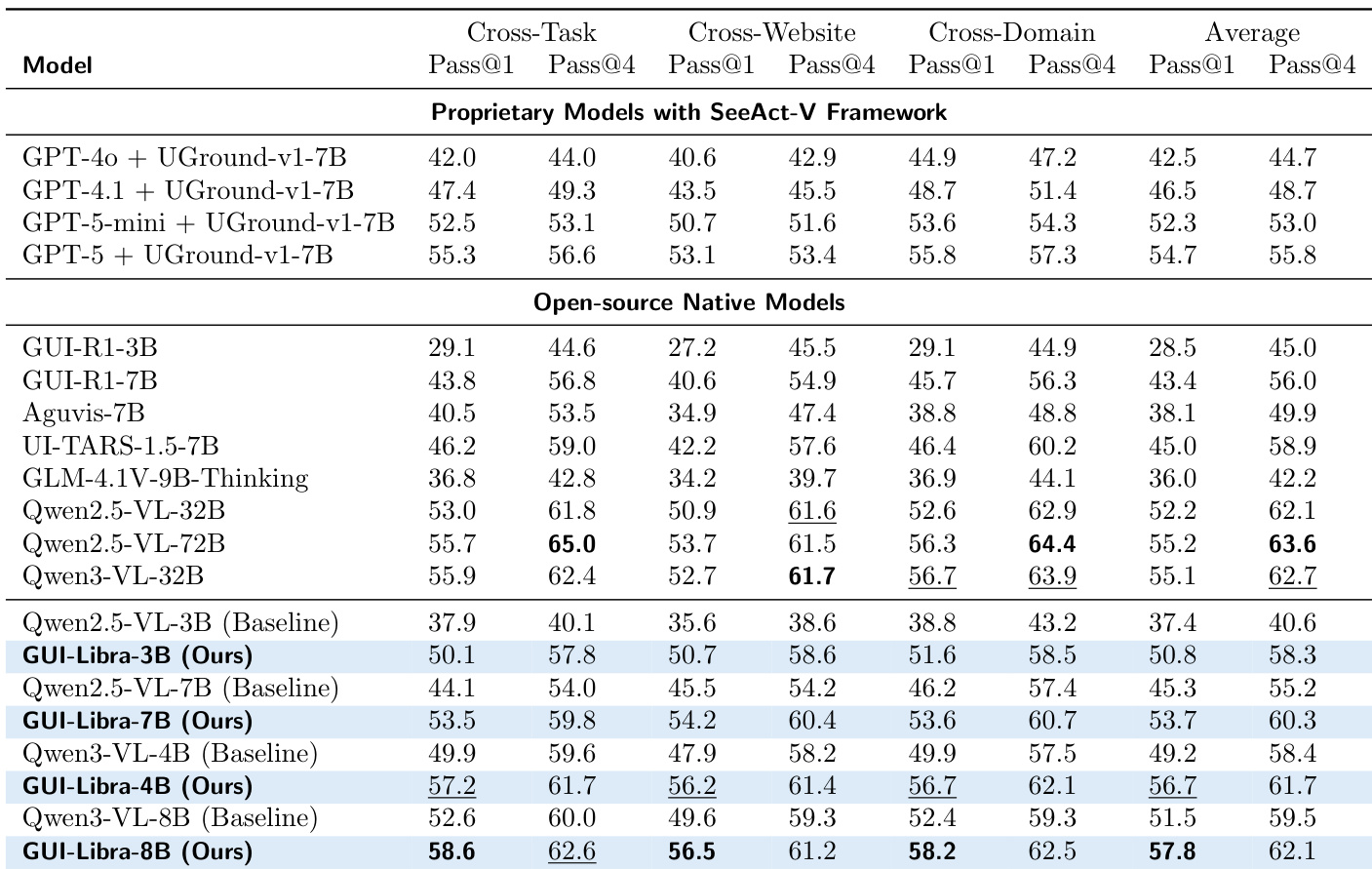
The authors find that adding step-wise summary modules to base models improves task success rates, with larger models generally achieving higher accuracy. However, GUI-Libra models without such modules still match or exceed the performance of these augmented systems, indicating that their training approach enhances native decision-making capability. This suggests that architectural simplicity combined with targeted training can rival more complex agent frameworks.

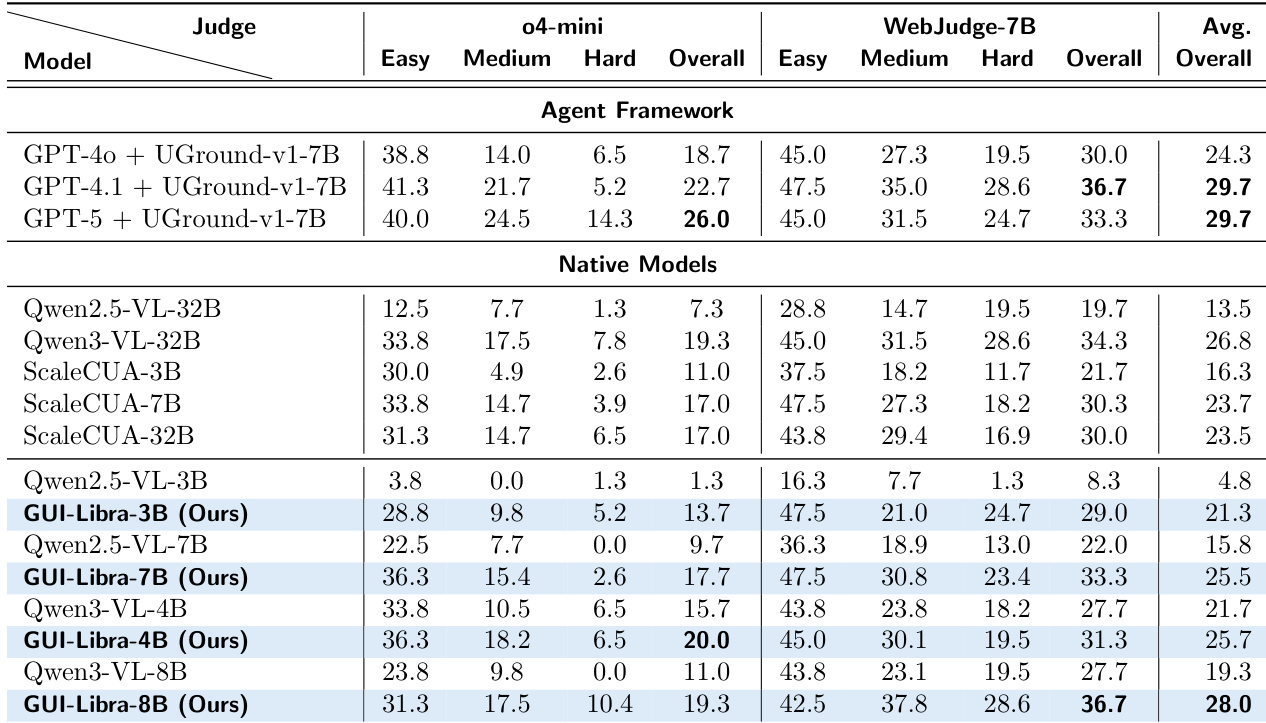
The authors find that GUI-Libra models consistently outperform both native and agent-framework baselines on Online-Mind2Web, achieving top scores under both o4-mini and WebJudge-7B evaluators. Performance scales with model size, with GUI-Libra-8B delivering the highest overall score among native models, surpassing larger open-source and proprietary systems. The results highlight GUI-Libra’s ability to generalize across difficulty levels and evaluator types while maintaining strong performance without relying on multi-module architectures.