Command Palette
Search for a command to run...
Tri-Modal Masked Diffusion Models의 Design Space
Tri-Modal Masked Diffusion Models의 Design Space
초록
이산 확산 모델(Discrete diffusion models)은 자기회귀(autoregressive) 언어 모델의 강력한 대안으로 부상하였으며, 최근 연구들은 이봉형(bi-modal) 생성을 위해 기초 단일 양식(unimodal) 모델을 초기화하고 파인튜닝하는 방식을 취해왔습니다. 본 연구에서는 기존 방식에서 벗어나, 텍스트, 이미지-텍스트, 오디오-텍스트 데이터에 대해 처음부터 사전 학습(pretrained from scratch)된 최초의 삼봉형(tri-modal) Masked Diffusion Models(MDM)를 소개합니다.본 논문에서는 멀티모달 스케일링 법칙(multimodal scaling laws), 양식 혼합 비율(modality mixing ratios), 노이즈 스케줄(noise schedules), 배치 사이즈(batch-size)의 효과를 체계적으로 분석하고 최적화된 추론 샘플링 기본 설정을 제공합니다. 배치 사이즈 분석을 통해 우리는 새로운 확률 미분 방정식(SDE) 기반의 재매개변수화(reparameterization) 기법을 도출하였으며, 이를 통해 최근 연구에서 보고된 최적 배치 사이즈 튜닝의 필요성을 제거했습니다. 이 재매개변수화는 계산 자원(GPU 포화도, FLOP 효율성, 실제 실행 시간)을 기준으로 선택되는 물리적 배치 사이즈(physical batch size)와 확률적 최적화 과정에서 그래디언트(gradient)의 분산을 조절하기 위해 선택되는 논리적 배치 사이즈(logical batch size)를 분리(decouple)합니다.마지막으로, 통합 설계의 역량을 보여주는 예비 모델을 사전 학습하였으며, 3B 모델 규모(6.4T tokens)에서 텍스트 생성, T2I(text-to-image), T2S(text-to-speech) 작업 모두에서 강력한 성능을 달성했습니다. 본 연구는 현재까지 수행된 멀티모달 이산 확산 모델에 대한 가장 대규모의 체계적인 오픈 스터디(open study)로서, 다양한 양식에 걸친 스케일링 동작(scaling behaviors)에 대한 가치 있는 통찰을 제공합니다.
One-sentence Summary
This study introduces the first tri-modal Masked Diffusion Models (MDM) pretrained from scratch on text, image-text, and audio-text data, providing a systematic analysis of multimodal scaling laws and a novel SDE-based reparameterization that decouples physical and logical batch sizes to optimize cross-modal generation.
Key Contributions
- This work introduces the first tri-modal Masked Diffusion Model (MDM) pretrained from scratch on a unified stream of text, image, and audio tokens using a single transformer backbone. The architecture enables flexible cross-modal tasks such as text-to-image and text-to-speech without requiring modality-specific heads or bespoke factorizations.
- The paper presents a novel stochastic differential equation (SDE) based reparameterization that decouples the physical batch size used for hardware efficiency from the logical batch size used for gradient variance control. This method eliminates the need for expensive manual tuning of optimal batch sizes during large-scale training.
- The study provides a systematic analysis of multimodal scaling laws, modality mixing ratios, and noise schedules, supported by a 3B parameter model trained on 6.4T tokens. Results demonstrate strong performance across text generation, text-to-image, and text-to-speech tasks, while also validating that interventions like anti-masking improve benchmark performance without increasing computational costs.
Introduction
While causal transformers dominate modern sequence modeling, they rely on a strict left-to-right factorization that may not be optimal for conditional generation tasks where evidence is scattered across different modalities. Discrete diffusion models offer a bidirectional alternative through iterative refinement, yet existing multimodal research often relies on adapting pretrained unimodal models or focuses only on bi-modal (text and image) setups. This limits the ability to create truly unified systems capable of handling diverse data streams like audio.
The authors leverage a tri-modal Masked Diffusion Model (MDM) pretrained from scratch on text, image, and audio data using a single transformer backbone and a unified discrete token space. They introduce an SDE-based reparameterization that decouples physical batch size from logical batch size, effectively eliminating the need to tune for an optimal batch size during training. Furthermore, the authors provide a systematic study of multimodal scaling laws and demonstrate that optimal inference parameters, such as noise schedules and guidance, must be tailored specifically to each modality.
Method
The authors propose a unified modeling framework designed to handle multiple modalities, specifically text, audio, and image, within a single transformer-based architecture. To achieve this, they construct a shared vocabulary V through the disjoint union of modality-specific vocabularies: V=Vtext⊔Vaudio⊔Vimage. This unified vocabulary is augmented with modality-specific special tokens, such as BOSm, EOSm, and MASKm for each modality m∈{text,audio,image}, as well as task-specific tokens Vtask that signal the intended operation, such as TASKtext or TASKaudio-text.
The training process relies on constructing sequences where modality tokens are wrapped with their respective boundary tokens. For instance, an audio-text sample is formatted as a sequence starting with a task token, followed by the audio segment (bounded by BOSaudio and EOSaudio), and ending with the text segment (bounded by BOStext and EOStext). To maintain a consistent sequence length L⋆ across a minibatch, the authors employ packing for text-only sequences and right-padding with PADtext for mixed-modality sequences that are shorter than the target length.
As shown in the figure below, the training data is organized into minibatches where different sequences follow these specific formatting and padding rules before being processed by the model:
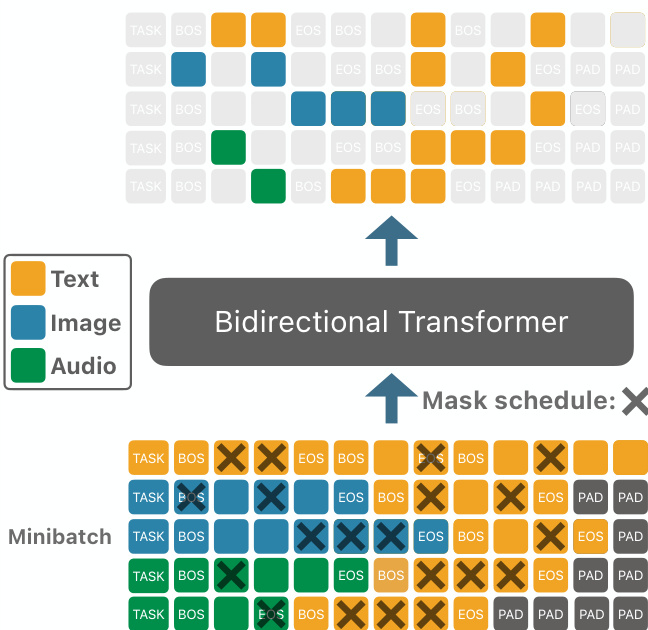
The core of the method is a continuous-time forward masking process indexed by t∈[0,1]. Each position in the sequence is independently corrupted according to a Bernoulli masking mechanism with a probability βt, where β is a monotonic function. The corrupted token sti is either replaced by a modality-specific mask token MASKm(i) or remains the same as the previous state st−1i. This process ensures that once a token is masked, it remains masked, smoothly interpolating from the original sequence at t=0 to a fully masked sequence at t=1.
To perform the reverse process, the authors utilize a denoising model fθ parameterized as a bi-directional transformer. This model predicts logits over the unified vocabulary for each position in the corrupted sequence st. The training objective is to minimize a per-token loss ℓi(θ,s) averaged over the set of masked, non-padding positions It. To ensure an unbiased estimator of the Evidence Lower Bound (ELBO) under the Bernoulli masking scheme, the authors apply an importance weighting w(t)=1/t. This weighting compensates for the fact that fewer tokens are masked at early time steps, ensuring that every token contributes equally to the loss in expectation across the entire diffusion process.
Experiment
The experiments evaluate the scaling properties, architectural design, and training dynamics of tri-modal Masked Discrete Diffusion Models (MDM) under SDE reparameterization. Results demonstrate that the critical batch size is independent of model size but scales sub-linearly with the token horizon, and that a polynomial masking schedule provides superior generation quality across modalities. Furthermore, the study establishes robust scaling laws for tri-modal MDMs, revealing that these models become increasingly data-efficient per parameter as they grow, requiring significantly more tokens than traditional autoregressive language models to reach compute optimality.
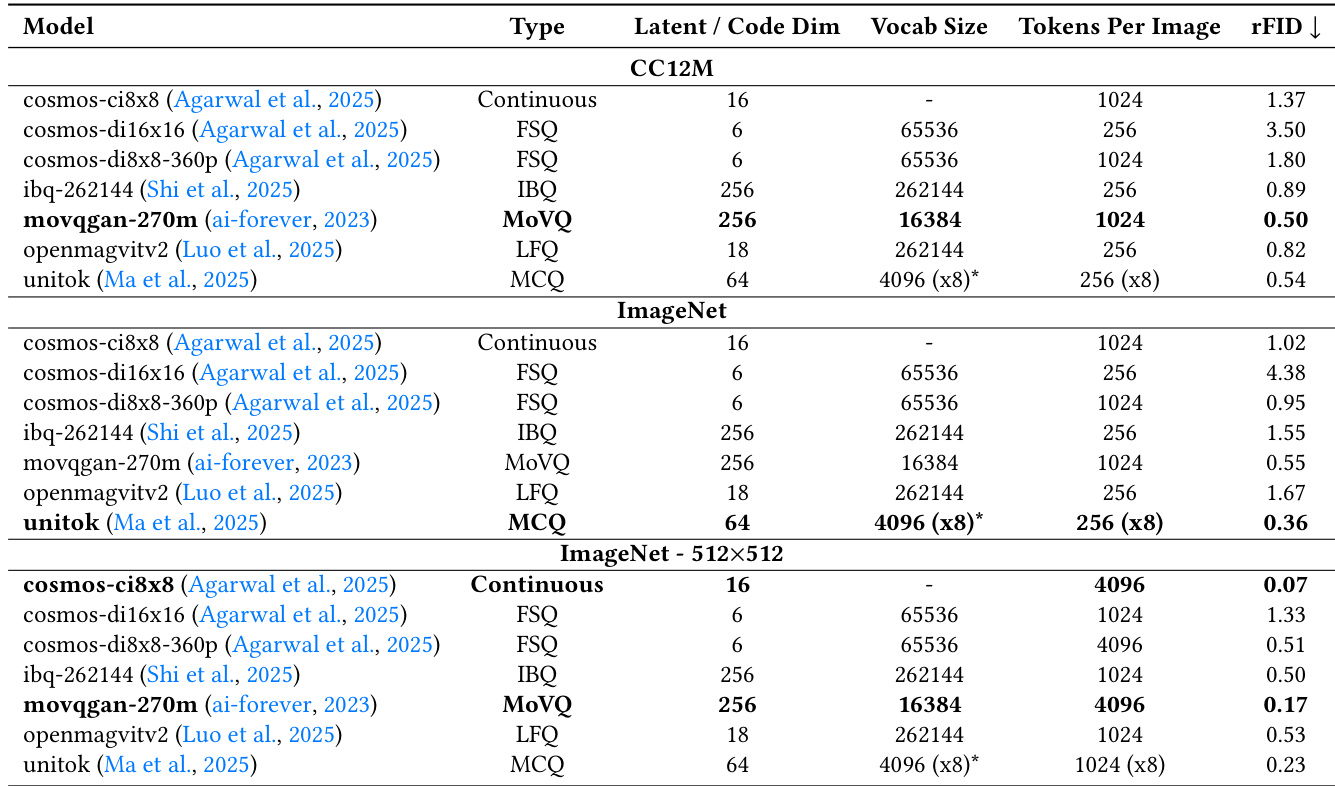
The authors compare various image tokenizers by evaluating their reconstruction performance on the CC12M and ImageNet datasets. The results demonstrate that different tokenizer types, including continuous, FSQ, IBQ, MoVQ, LFQ, and MCQ, yield varying levels of reconstruction fidelity. MoVQ-based tokenizers achieve high reconstruction performance across both datasets. MCQ tokenizers show strong performance on ImageNet at higher resolutions. Continuous models and certain discrete tokenizers exhibit different levels of effectiveness depending on the dataset and resolution used.
The authors compare standard MDM training against an anti-masking strategy across different modalities. Results indicate that the anti-masking approach improves generation quality for both images and audio. Anti-masking leads to lower FID scores for image generation on both training and CC12M datasets. The anti-masking method improves audio generation quality as measured by FAD on both training and LibriSpeech data. The performance gains from anti-masking are observed across both unimodal text and multimodal settings.

The authors compare the performance of standard MDM training against an anti-masking strategy across various text-based benchmarks. Results indicate that the anti-masking approach generally improves model accuracy across most evaluated tasks. Anti-masking leads to performance gains in reasoning and knowledge benchmarks such as BBH, MMLU, and ARC-Challenge The strategy shows consistent improvements in linguistic and common sense tasks including Winogrande and HellaSwag Most metrics demonstrate higher mean accuracy when using the anti-masking technique compared to the base model

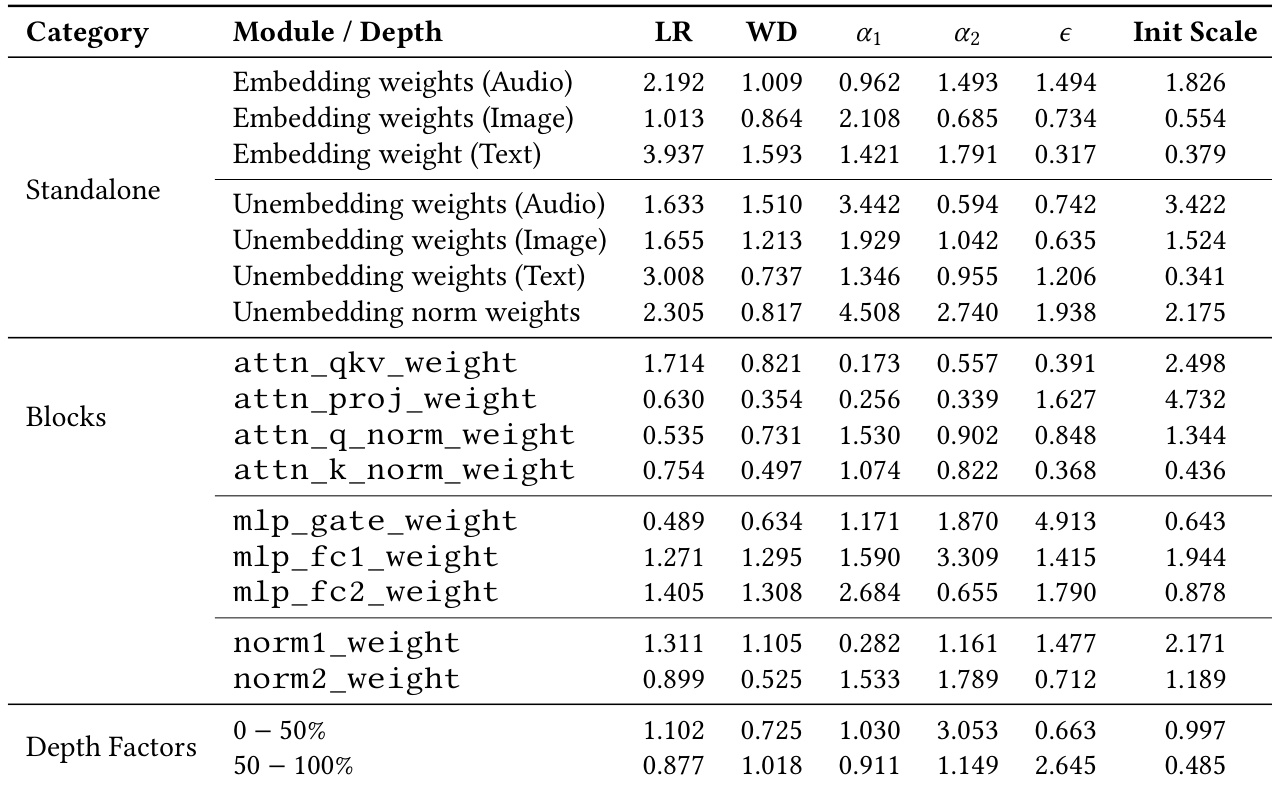
The authors present the results of a per-module hyperparameter search to optimize AdamW settings for the tri-modal MDM. The findings show that different components of the model, such as embedding weights and various transformer block parameters, require distinct learning rate multipliers, weight decay, and epsilon values to achieve optimal performance. Embedding and unembedding weights benefit from significantly larger effective learning rates compared to other modules. Attention projection and MLP gate weights are tuned more conservatively with specific adjustments to epsilon for numerical stability. The learned depth factors indicate that later blocks in the model benefit from smaller updates and increased stabilization.
The authors compare different audio tokenizers based on reconstruction and perceptual metrics. The results show that increasing the number of codebooks generally improves reconstruction performance, though it impacts the efficiency of the token rate. Higher codebook counts lead to better PESQ scores across different pretrained models The Higgs pretrained tokenizer demonstrates strong performance in content enjoyment and usefulness The DAC retrained model with fewer codebooks achieves high scores in content usefulness and probability quality

The researchers evaluate various image and audio tokenizers, training strategies, and hyperparameter configurations to optimize tri-modal model performance. The results show that MoVQ and MCQ tokenizers provide strong reconstruction fidelity, while an anti-masking strategy consistently enhances generation quality across image, audio, and text modalities. Furthermore, a per-module hyperparameter search reveals that different model components require specialized optimization settings, and increasing audio codebook counts generally improves perceptual quality.