Command Palette
Search for a command to run...
ACTIONENGINE: State Machine Memory를 통한 Reactive 방식에서 Programmatic GUI Agents로의 전환
ACTIONENGINE: State Machine Memory를 통한 Reactive 방식에서 Programmatic GUI Agents로의 전환
Hongbin Zhong Fazole Faisalal Luis França Tanakorn Leesatapornwongsa Adriana Szekeres Kexin Rong Suman Nath
초록
기존의 그래픽 사용자 인터페이스(GUI) 에이전트는 스크린샷을 찍고, 다음 동작을 추론하고, 이를 실행한 뒤 새로운 페이지에서 이 과정을 반복하는 방식으로 Vision Language Model(VLM)을 단계별로 호출하여 작동합니다. 이러한 방식은 추론 단계가 늘어남에 따라 비용과 지연 시간(latency)이 비례하여 증가하며, 이전에 방문한 페이지에 대한 지속적인 메모리가 없어 정확도가 제한된다는 단점이 있습니다.본 논문에서는 반응형 실행(reactive execution) 방식에서 프로그래밍 방식의 계획(programmatic planning)으로 전환하는 training-free 프레임워크인 ACTIONENGINE을 제안합니다. ACTIONENGINE은 혁신적인 2-agent 아키텍처를 채택하였습니다. 먼저, Crawling Agent는 오프라인 탐색을 통해 GUI의 업데이트 가능한 상태 머신(state-machine) 메모리를 구축하며, Execution Agent는 이 메모리를 활용하여 온라인 작업 실행을 위한 완전하고 실행 가능한 Python 프로그램을 합성합니다. 또한, 변화하는 인터페이스에 대한 견고성(robustness)을 보장하기 위해, 실행 실패 시 vision-based re-grounding fallback 메커니즘이 트리거되어 실패한 동작을 수정하고 메모리를 업데이트합니다.이러한 설계는 효율성과 정확도를 획기적으로 향상시킵니다. Web Arena benchmark의 Reddit 작업 수행 결과, 본 에이전트는 평균 단 한 번의 LLM 호출만으로 95%의 작업 성공률을 달성했습니다. 이는 가장 강력한 vision-only baseline의 성공률인 66%와 비교했을 때 월등한 수치이며, 동시에 비용은 11.8배 절감하고 end-to-end latency는 2배 단축했습니다.
One-sentence Summary
The proposed training-free framework, ACTIONENGINE, transitions GUI agents from reactive execution to programmatic planning through a two-agent architecture that utilizes a Crawling Agent to build state-machine memory and an Execution Agent to synthesize Python programs, achieving 95% success on Reddit tasks in the Web Arena benchmark while reducing costs by 11.8× and latency by 2× compared to vision-only baselines.
Key Contributions
- The paper introduces ACTIONENGINE, a training-free framework that shifts GUI agents from reactive step-by-step execution to a global programmatic planning paradigm using a two-agent architecture.
- This work presents a novel state-machine memory constructed by a Crawling Agent through offline exploration, which allows an Execution Agent to synthesize complete, executable Python programs for task execution in a single inference step.
- The framework incorporates a vision-based re-grounding fallback mechanism that repairs failed actions and dynamically updates the state-machine memory to ensure robustness against evolving interfaces.
- Empirical evaluations on the Reddit tasks within the Web Arena benchmark demonstrate that the method achieves a 95% success rate, reducing end-to-end latency by 2× and costs by 11.8× compared to strong vision-only baselines.
Introduction
Modern Graphical User Interface (GUI) agents are essential for automating complex digital tasks, yet most current systems rely on a reactive paradigm where a model observes a screenshot and predicts a single next action at every step. This iterative approach suffers from high latency and computational costs that scale linearly with task length, while also being prone to error accumulation where a single visual hallucination can derail the entire process. The authors leverage a novel two-agent architecture called ACTIONENGINE to transition from this reactive execution to programmatic planning. By using a Crawling Agent to build an updatable state-machine memory of the interface and an Execution Agent to synthesize complete Python programs for task completion, the framework reduces reasoning complexity from O(N) to O(1) and provides a robust mechanism for self-correction through vision-based re-grounding.
Dataset
Please provide the paper paragraphs you would like me to process. The text provided in your prompt appears to be a snippet of comment analysis rather than a technical description of a dataset.
Once you provide the relevant technical text, I will draft the description following your requirements.
Method
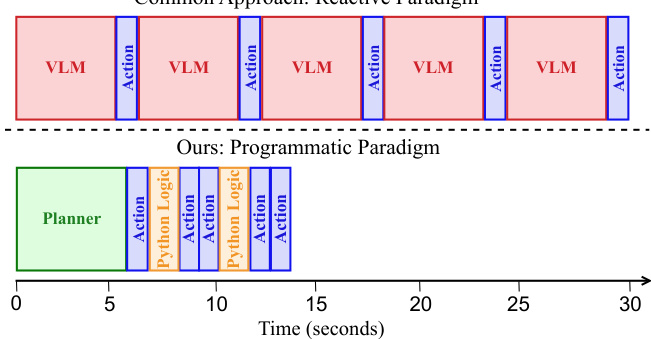
The authors introduce a novel two-agent architecture that separates application operation learning from task planning and execution. This approach shifts the computational burden from expensive runtime visual processing to amortized offline preprocessing, moving from a reactive paradigm to a programmatic one.
As shown in the framework diagram:
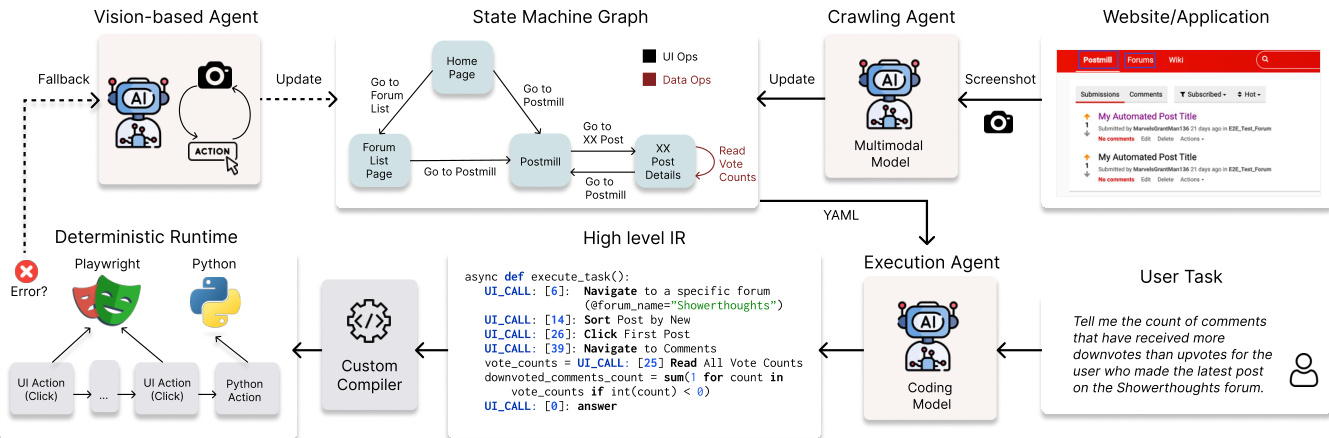
The system lifecycle consists of three primary phases involving a Crawling Agent and an Execution Agent. The Crawling Agent operates offline to systematically explore the target GUI application and construct a State Machine Graph (SMG). This SMG is a directed graph where nodes correspond to symbolic application states and edges represent GUI operations, such as clicks or text entry, that trigger state transitions. The agent identifies core atoms to generate unique State IDs, effectively capturing the application's topology independent of specific task requirements.
The SMG is formally defined as a state machine M=(S,O,T), where S is a set of discrete states, O is a set of executable operations, and T:S×O→S is the transition function.
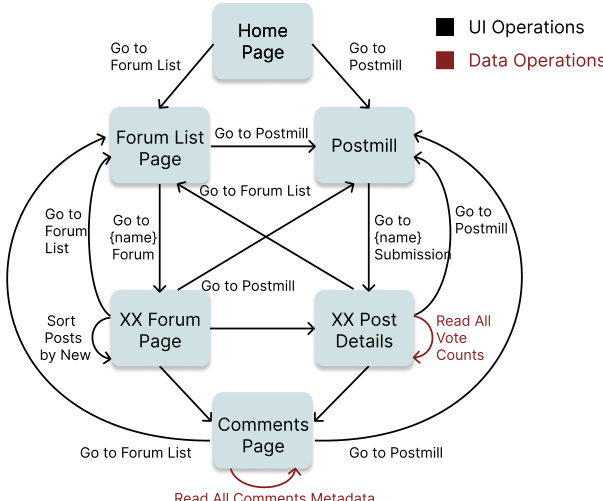
Refer to the illustration of the State-Machine Graph:
To prevent state explosion, the authors decouple the static topology from dynamic data content. A state is defined by its atom signature, where atoms represent sets of related UI elements that appear atomically. While static atoms encode invariant interface elements, dynamic atoms represent elements with data-dependent content. This allows multiple data instances to map to a single state template, ensuring the graph size scales with the number of distinct templates rather than the number of data items.
As shown in the figure below:
The Execution Agent performs online compilation by querying the SMG to solve user tasks. Given a goal, a code-generating LLM (the Planner) produces a Sketch Program in an intermediate representation (IR). This Python-based sketch captures the logical control flow using loops and conditionals while using placeholders for concrete UI interactions and symbolic variables, denoted by an @ prefix, for runtime data.
The linking phase then resolves these abstract placeholders into concrete execution paths by searching the SMG. The agent employs strategies such as breadth-first search (BFS) or loop-aware linking to find valid sequences of graph edges. Once linked, a compiler expands these operations into a fully specified program composed of UI Nodes for primitive browser actions, Python Nodes for local computation, and Control Flow Nodes to preserve the original nesting structure.
During runtime, if the environment deviates from the SMG, a feedback loop is triggered. An MLLM-based mechanism performs vision-based recovery to identify new interaction points, and these successful recoveries are committed back to the SMG to update the system's memory.
Experiment
The study evaluates ACTIONENGINE, a programmatic GUI agent framework, against reactive baseline agents using the WebArena benchmark, specifically focusing on complex, long-horizon tasks within the Reddit domain. By replacing iterative visual reasoning with a single-step planning phase that generates executable Python code based on a structured state-machine memory, the approach demonstrates superior reliability and efficiency. The results show that transitioning from stochastic, step-by-step interactions to deterministic programmatic execution significantly improves task success rates while drastically reducing latency, computational costs, and error accumulation.
The authors compare their programmatic approach, AEngine, against a reactive baseline, AOccam, across various task groups in the WebArena Reddit subset. Results demonstrate that the proposed method achieves higher success rates while significantly reducing latency, token consumption, and the number of required model calls. AEngine achieves a higher overall success rate compared to the reactive baseline across the evaluated tasks. The proposed method demonstrates substantial efficiency gains by reducing average latency and the number of LLM calls per task. AEngine significantly lowers both input and output token usage compared to the baseline approach.
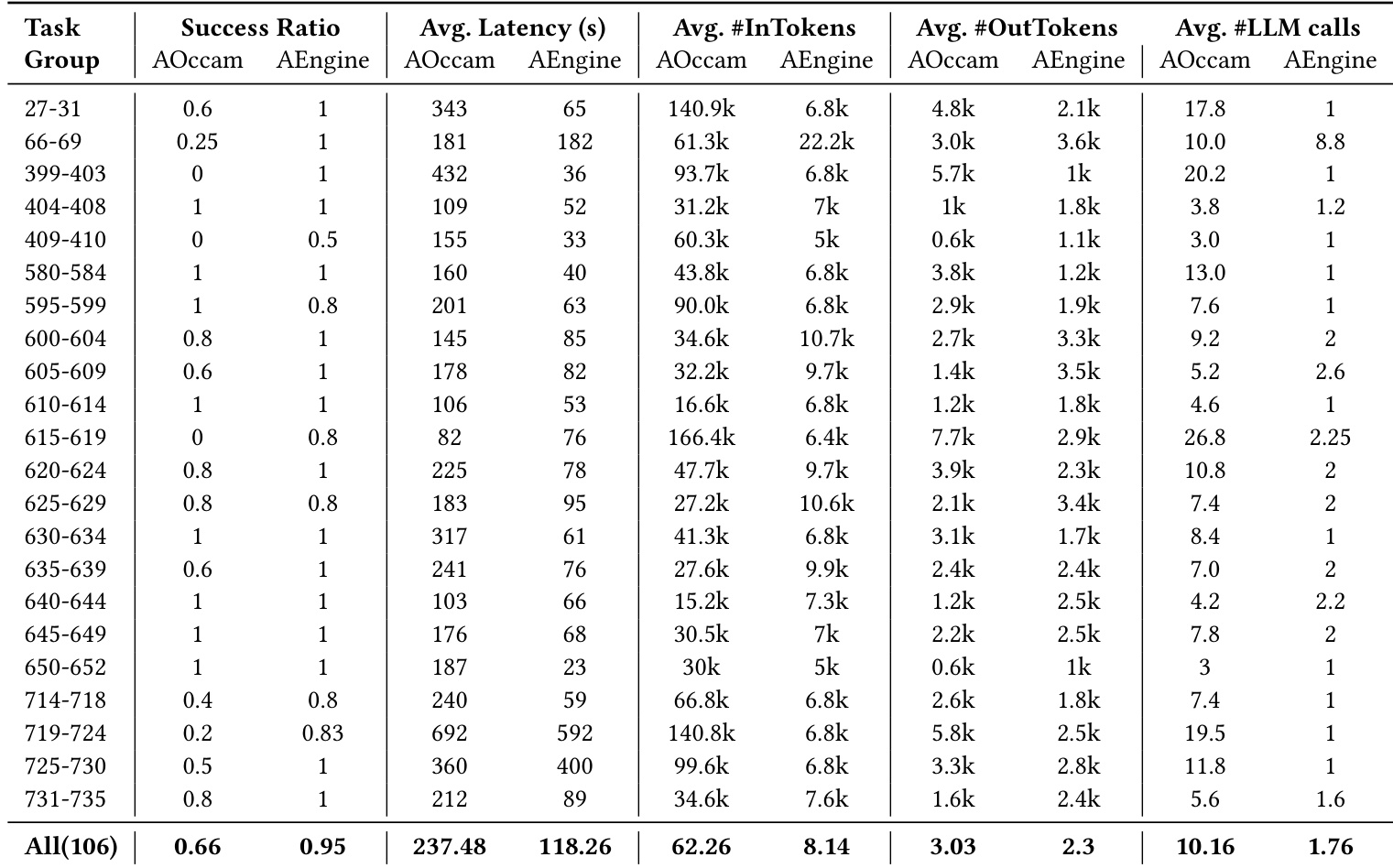
The authors compare their proposed framework, AEngine, against the reactive baseline AOccam on the WebArena Reddit subset. Results show that AEngine significantly outperforms the baseline in success rate, latency, and cost efficiency. AEngine achieves a higher task success rate compared to the baseline. The proposed method reduces average latency and the number of LLM calls required per task. AEngine demonstrates substantial improvements in cost efficiency and reduces both input and output token consumption.
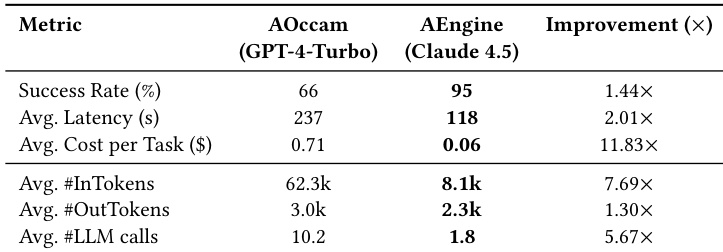
The authors evaluate the proposed AEngine framework against the reactive baseline AOccam using various task groups within the WebArena Reddit subset. The experiments demonstrate that AEngine achieves a higher success rate while providing substantial improvements in operational efficiency. Ultimately, the programmatic approach reduces latency, minimizes the number of required model calls, and lowers overall token consumption compared to the baseline.