Command Palette
Search for a command to run...
Mobile-O: 모바일 디바이스에서의 통합 다중모달 이해 및 생성
Mobile-O: 모바일 디바이스에서의 통합 다중모달 이해 및 생성
초록
통합 다중모달 모델은 단일 아키텍처 내에서 시각 콘텐츠를 이해하고 생성할 수 있다. 그러나 기존 모델들은 여전히 데이터에 과도하게 의존하며, 엣지 장치에 배포하기에 부담스러울 정도로 무겁다. 본 연구에서는 모바일 기기에서 통합 다중모달 지능을 실현하는 컴팩트한 시각-언어-디퓨전 모델인 Mobile-O를 제안한다. 핵심 모듈인 모바일 컨디셔닝 프로젝터(Mobile Conditioning Projector, MCP)는 깊이 분리형 합성곱(depthwise-separable convolutions)과 계층별 정렬(layerwise alignment)을 활용해 시각-언어 특징을 디퓨전 생성기와 융합한다. 이 설계는 최소한의 계산 비용으로 효율적인 다중모달 조건부 생성을 가능하게 한다. Mobile-O는 단 몇 백만 개의 샘플만으로 학습되었으며, 새로운 쿼드루플렛(quadruplet) 형식(생성 프롬프트, 이미지, 질문, 답변)으로 사후 학습을 진행함으로써 시각적 이해와 생성 능력을 동시에 향상시켰다. 효율성에도 불구하고 Mobile-O는 다른 통합 모델들과 비교해 경쟁력 있는 또는 더 뛰어난 성능을 달성하였으며, GenEval 기준으로 74%의 점수를 기록해 Show-O와 JanusFlow보다 각각 5%, 11% 높은 성능을 보였다. 또한 각각 6배, 11배 더 빠른 속도로 작동하였다. 시각적 이해 성능 측면에서는 7개 벤치마크 평균 기준으로 Show-O와 JanusFlow를 각각 15.3%, 5.1% 우수하게 나타냈다. 아이폰에서 512x512 이미지당 약 3초 내외로 실행되는 Mobile-O는 엣지 장치에서 실시간 통합 다중모달 이해 및 생성을 위한 최초의 실용적 프레임워크를 구축했다. 앞으로 실시간 통합 다중모달 지능이 클라우드 의존 없이 완전히 기기 내에서 실행될 수 있도록 하는 연구의 발전을 기대한다. 코드, 모델, 데이터셋, 모바일 앱은 모두 공개되어 있으며, https://amshaker.github.io/Mobile-O/ 에서 확인할 수 있다.
One-sentence Summary
Researchers from MBZUAI, CMU, and Linköping University propose Mobile-O, a compact vision-language-diffusion model with a Mobile Conditioning Projector that enables real-time unified multimodal understanding and generation on mobile devices, outperforming prior models in speed and accuracy while requiring minimal data and no cloud dependency.
Key Contributions
- Mobile-O introduces a compact vision-language-diffusion model optimized for edge devices, addressing the inefficiency and data hunger of existing unified multimodal models through a lightweight architecture and training on just a few million samples.
- Its core innovation, the Mobile Conditioning Projector (MCP), uses depthwise-separable convolutions and layerwise alignment to fuse vision-language features with diffusion generation efficiently, while a novel quadruplet training format (prompt, image, question, answer) jointly improves understanding and generation.
- Mobile-O achieves state-of-the-art results with 74% on GenEval, outperforming Show-O and JanusFlow by 5% and 11% respectively, and runs up to 11x faster, while also surpassing them by 15.3% and 5.1% on average across seven understanding benchmarks, all while generating 512x512 images in ~3s on an iPhone.
Introduction
The authors leverage unified multimodal models that combine visual understanding and image generation in a single architecture, aiming to bring this capability to edge devices like smartphones where compute and memory are limited. Prior models are too large and data-hungry, often requiring billions of parameters and hundreds of millions of training samples, making them impractical for on-device deployment. Mobile-O addresses this by introducing a lightweight Mobile Conditioning Projector that fuses vision-language features with a diffusion generator using depthwise-separable convolutions, enabling efficient cross-modal conditioning. It also introduces a novel quadruplet training format (prompt, image, question, answer) to jointly optimize understanding and generation with only 105k samples. As a result, Mobile-O achieves state-of-the-art performance on both tasks while running up to 11x faster than prior unified models and completing 512x512 image generation in ~3 seconds on an iPhone.
Method
The authors leverage a unified mobile-optimized architecture that jointly supports multimodal visual understanding and text-to-image generation. The framework integrates a vision-language encoder-decoder for understanding tasks with a diffusion-based image decoder for generation, connected via a lightweight Mobile Conditioning Projector (MCP) that enables efficient cross-modal alignment without introducing additional token sequences.
At the core, the visual understanding pathway begins with an image encoder and an autoregressive language model. Given an image and a question, the model generates an answer through an I2T (image-to-text) loss computed over the language model’s output tokens. For generation, a text prompt is processed by the same language model, whose hidden states are projected via the MCP into conditioning features for a DiT-style diffusion decoder. The generated image is then reconstructed via a VAE decoder, with training guided by a T2I (text-to-image) loss based on flow matching.
Refer to the framework diagram, which illustrates the dual pathways and their shared components. The Mobile Conditioning Projector, shown in detail on the right, fuses the final K layers of the VLM using temperature-scaled softmax weights, compresses the fused representation via a linear layer, and refines it using depthwise-separable 1D convolutions and lightweight channel attention. The output is projected to match the diffusion decoder’s conditioning dimension, enabling end-to-end alignment without query tokens.
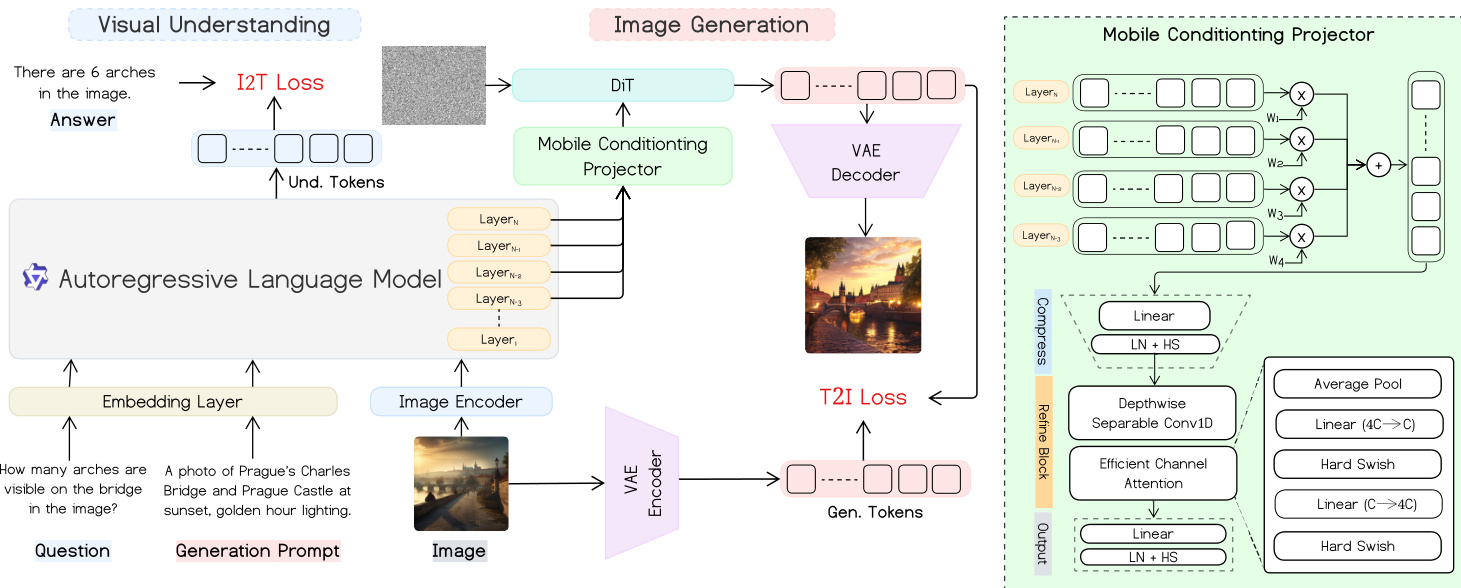
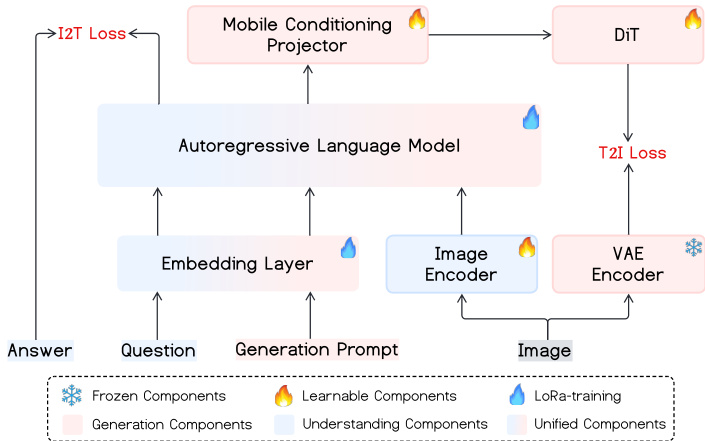
The training proceeds in three stages. In Stage 1, the visual encoder and language model are frozen while the DiT and MCP are trained on large-scale image-text pairs to establish cross-modal alignment. Stage 2 performs supervised fine-tuning on curated prompt-image pairs to address domain-specific weaknesses. Stage 3 introduces a unified multimodal post-training phase, where quadruplet samples (generation prompt, image, question, answer) are used to jointly optimize both I2T and T2I objectives. This stage enables bidirectional learning: the same embedding layer and language model support both understanding and generation, with the MCP serving as the shared conditioning interface.
As shown in the training dynamics diagram, components are selectively frozen or updated across stages. During Stage 1 and 2, only the generation components (DiT and MCP) are learnable, while the understanding backbone remains frozen. In Stage 3, the unified components—including the MCP and parts of the language model—are fine-tuned via LoRa, enabling joint optimization without destabilizing the pretrained representations.
The unified loss function combines the I2T language modeling loss and the T2I flow-matching loss with learnable weights:
Lunified=λlangLlang+λdiffLdiffThe I2T loss is standard cross-entropy over answer tokens conditioned on image and question. The T2I loss minimizes the weighted MSE between the predicted velocity field and the ground-truth flow, enabling stable and efficient training compared to traditional noise prediction objectives. The MCP’s design ensures minimal computational overhead, with complexity dominated by O(kdh+dh2) per token, avoiding expensive 2D convolutions or attention over new tokens.
Experiment
- Mobile-O validates efficient unified multimodal understanding and generation on mobile devices, outperforming prior models like Show-O and Janus in both speed and quality while fitting under 2GB memory.
- It achieves superior text-to-image generation and visual understanding via a shared Mobile Conditioning Projector and multi-task post-training, improving both capabilities without architectural changes.
- Image editing is enabled with minimal fine-tuning data, preserving scene structure while applying localized edits, demonstrating emergent capability from unified design.
- Ablation studies confirm the MCP’s effectiveness in cross-modal alignment and the value of joint quadruplet training for boosting both generation and understanding.
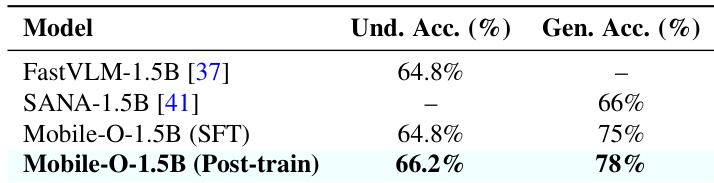
- Scaling to larger backbones (Mobile-O-1.5B) shows the framework generalizes, enhancing both understanding and generation beyond component baselines.
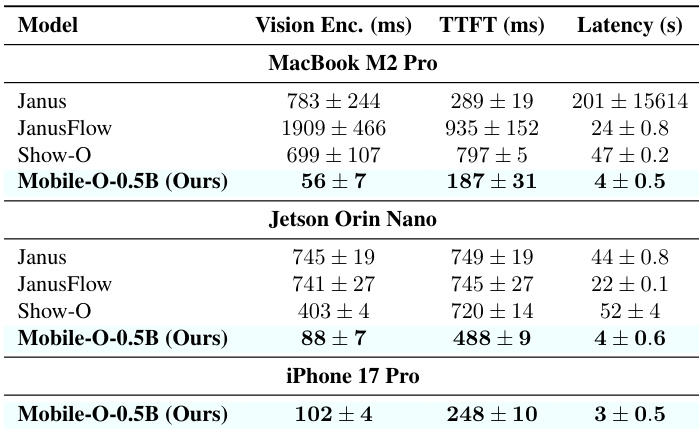
- Edge deployment on iPhone, Jetson, and MacBook proves real-time performance, with 3-second image generation and sub-0.5s text responses, enabling offline, privacy-preserving mobile AI.
- Qualitative results highlight superior fine detail rendering, prompt fidelity, and robust OCR/scene understanding, even under challenging real-world conditions.
- Limitations include constrained text representation due to shared lightweight LLM, trading expressiveness for deployability on resource-limited devices.
The authors evaluate different configurations of the Mobile Conditioning Projector (MCP) and find that using four layers with learnable fusion and a refinement block achieves the highest accuracy at 70.4% while keeping parameters under 2.4M. Results show that aggregating multiple VLM layers improves cross-modal alignment, and adding learnable weights and a refinement block further enhances performance without requiring excessive computational overhead.

The authors use a unified post-training strategy with quadruplet samples to jointly optimize both understanding and generation tasks. Results show that this approach improves average understanding accuracy by 1.6 percentage points and generation accuracy by 0.8 percentage points compared to using only image-text pairs or standard supervised fine-tuning. This demonstrates that multi-objective post-training enhances cross-modal alignment without requiring large-scale pre-training.

Mobile-O-0.5B achieves significantly faster inference speeds across all tested edge devices compared to prior unified models, with latency reductions of up to 46x for image generation on MacBook M2 Pro and under 3 seconds on iPhone 17 Pro. The model maintains efficient memory usage below 2GB while delivering real-time performance suitable for on-device deployment. Results confirm that architectural optimizations enable high-speed multimodal operations without compromising functional capabilities.
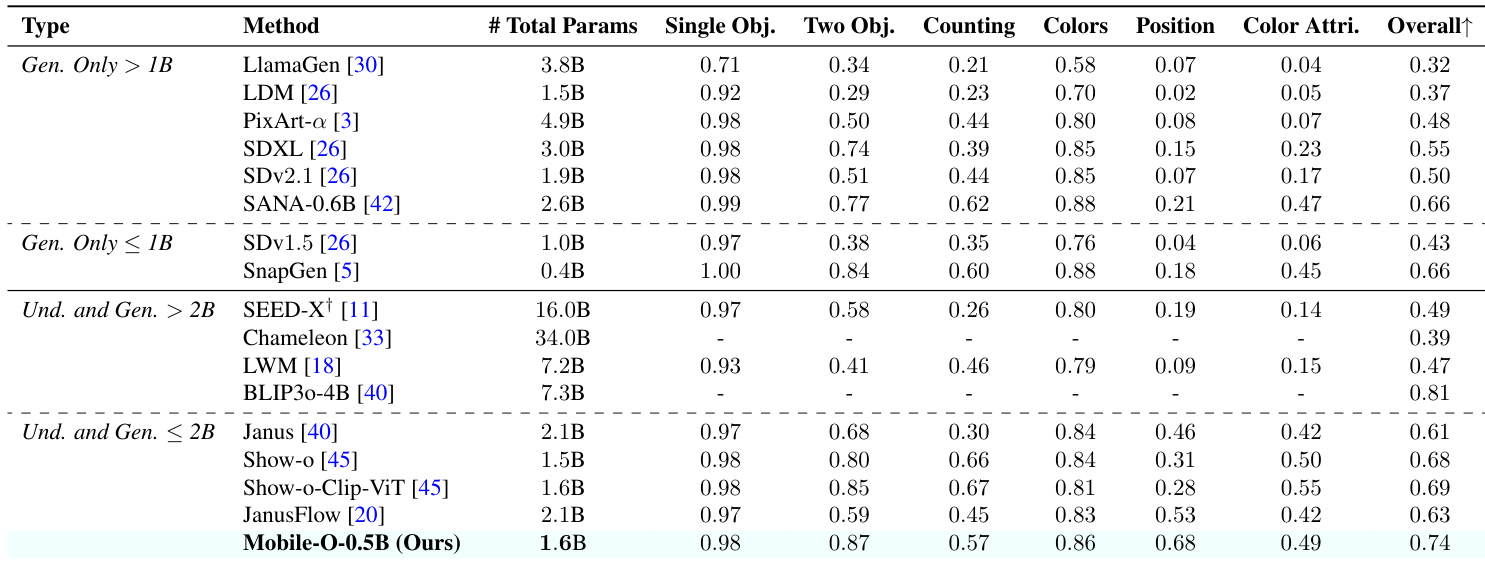
The authors evaluate Mobile-O-0.5B against other unified and generation-only models on text-to-image generation benchmarks, showing it achieves the highest overall score among models under 2B parameters. Results indicate Mobile-O-0.5B excels in generating images with accurate object counts, precise color attributes, and correct spatial positioning, outperforming comparable unified models like Show-O and JanusFlow. This performance is achieved while maintaining a compact parameter count and efficient inference, supporting its suitability for edge deployment.
The authors use a larger backbone configuration to scale Mobile-O to 1.5B parameters and evaluate its performance after supervised fine-tuning and post-training. Results show that post-training improves both understanding accuracy and generation quality, with the final model outperforming its individual component backbones. This confirms that the Mobile-O framework effectively enhances unified multimodal capabilities even when scaled to larger architectures.