Command Palette
Search for a command to run...
VLANeXt: 강력한 VLA 모델을 구축하기 위한 조리법
VLANeXt: 강력한 VLA 모델을 구축하기 위한 조리법
Xiao-Ming Wu Bin Fan Kang Liao Jian-Jian Jiang Runze Yang Yihang Luo Zhonghua Wu Wei-Shi Zheng Chen Change Loy
초록
대규모 기초 모델의 부상 이후, 시각-언어-행동 모델(Vision-Language-Action models, VLAs)이 등장하여 일반 목적의 정책 학습을 위해 강력한 시각적 및 언어 이해 능력을 활용하게 되었다. 그러나 현재의 VLA 생태계는 여전히 분산되어 있으며, 탐색적인 성격을 띠고 있다. 많은 연구팀이 각자의 VLA 모델을 제안하고 있으나, 훈련 프로토콜과 평가 환경의 일관성 부족으로 인해 어떤 설계 선택이 진정으로 중요한지 파악하기 어렵다. 이러한 진화하는 분야에 체계성을 부여하기 위해, 우리는 통합된 프레임워크와 평가 설정 하에서 VLA 설계 공간을 재검토한다. RT-2 및 OpenVLA와 유사한 간단한 VLA 베이스라인부터 출발하여, 기초 구성 요소, 인지 핵심 요소, 행동 모델링 관점의 세 가지 차원에 걸쳐 설계 선택을 체계적으로 분석한다. 본 연구를 통해 12가지 핵심 발견을 도출하였으며, 이는 강력한 VLA 모델을 구축하기 위한 실용적인 조리법을 형성한다. 이러한 탐구의 결과로, 단순하면서도 효과적인 모델인 VLANeXt가 제안된다. VLANeXt는 LIBERO 및 LIBERO-plus 벤치마크에서 기존 최고 성능 모델들을 능가하며, 실제 환경에서의 강력한 일반화 능력을 입증한다. 또한, 연구 결과의 재현, 설계 공간 탐색, 공통 기반 위에서 새로운 VLA 변형 모델 개발을 가능하게 하는 통합적이고 사용이 간편한 코드베이스를 공개할 예정이다.
One-sentence Summary
Researchers from multiple institutions propose VLANeXt, a streamlined VLA model that systematically evaluates design choices across components, perception, and action modeling, outperforming prior methods on LIBERO benchmarks and enabling real-world generalization via a unified, open codebase for community-driven VLA development.
Key Contributions
- The paper addresses the fragmented VLA landscape by introducing a unified evaluation framework and systematically analyzing design choices across foundational components, perception, and action modeling, distilling 12 practical findings into a reproducible recipe for effective VLA development.
- It proposes VLANeXt, a lightweight model derived from these insights, which outperforms prior state-of-the-art methods on LIBERO and LIBERO-plus benchmarks without relying on large-scale model scaling, demonstrating that principled design choices can yield strong performance.
- VLANeXt shows robust generalization in real-world manipulation tasks and is supported by a publicly released, modular codebase that enables community-driven exploration and reproduction of design decisions under standardized protocols.
Introduction
The authors leverage the growing field of Vision-Language-Action (VLA) models, which use large vision-language foundations to map visual and language inputs directly to robot actions—enabling scalable, general-purpose robotic control without task-specific training. Prior work has produced many VLA variants, but inconsistent training protocols and evaluation setups have made it hard to isolate which design choices actually improve performance. The authors address this by systematically exploring the VLA design space under a unified framework, evaluating across foundational components, perception inputs, and action modeling strategies. Their key contribution is VLANeXt, a lightweight model built from 12 distilled design principles, which outperforms larger prior models on LIBERO and LIBERO-plus benchmarks and generalizes well to real-world tasks—demonstrating that principled architecture choices matter more than scale or ad-hoc engineering. They also release an open, modular codebase to standardize future VLA research.
Method
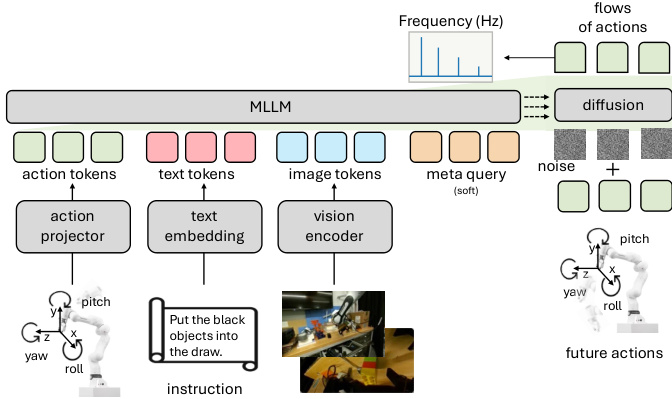
The authors leverage a systematic ablation framework to evolve a baseline VLA model into VLANeXt, focusing on three core dimensions: foundational components, perception essentials, and action modeling. The overall architecture integrates a multimodal LLM backbone with a dedicated policy module, conditioned on visual, textual, and proprioceptive inputs, and optimized via continuous action modeling with auxiliary objectives.
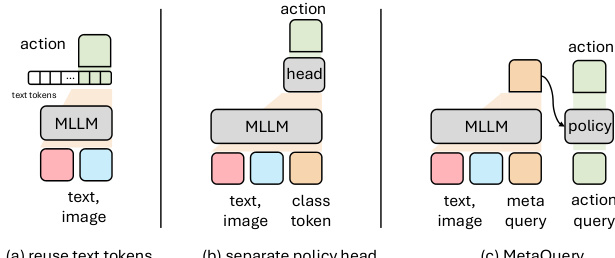
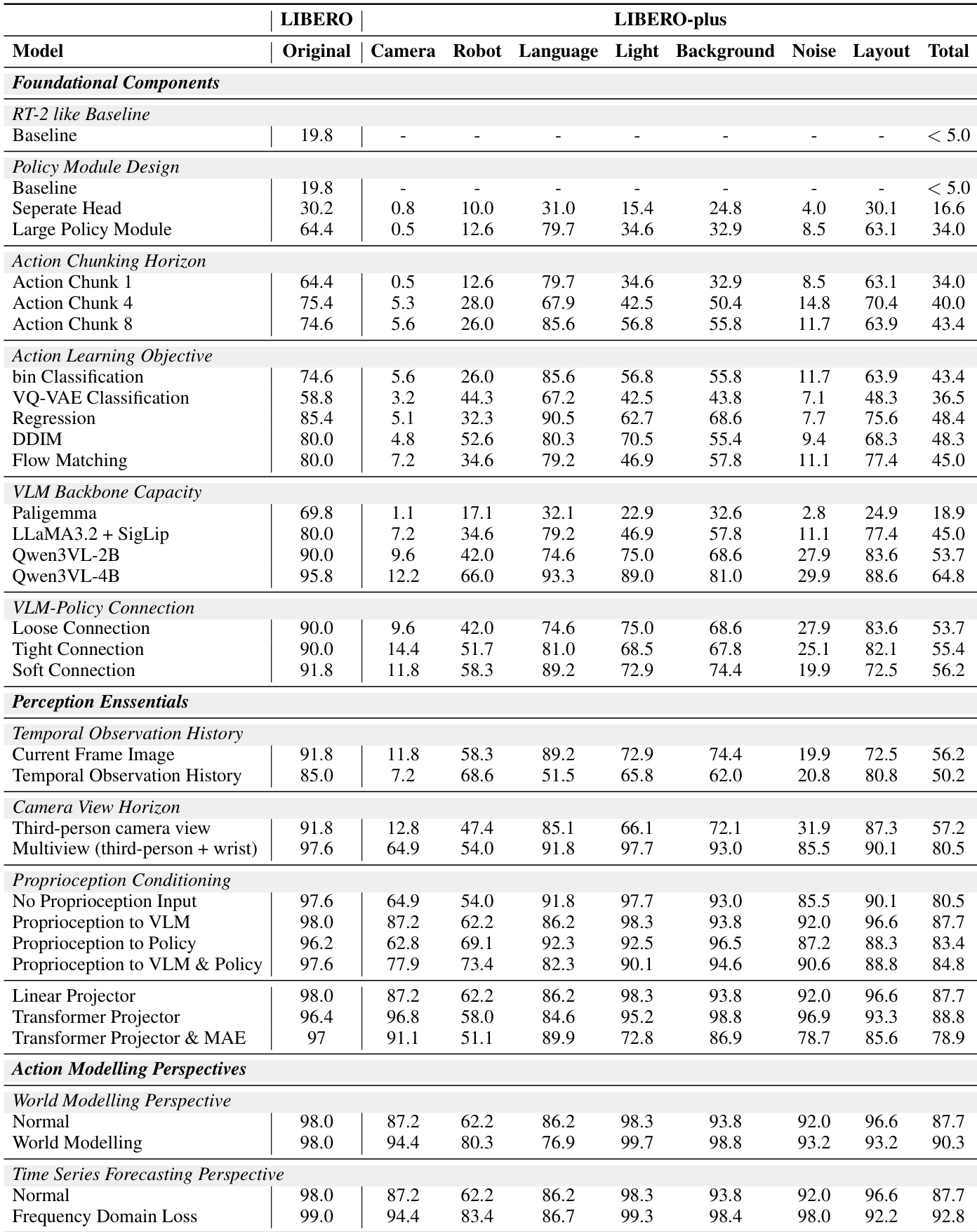
The foundational design begins with a baseline inspired by RT-2 and OpenVLA, using LLaMA as the language backbone and SigLIP2 as the vision encoder. Action prediction is initially handled by repurposing text tokens, but the authors find that introducing an explicit policy head—fed by a class token appended to the multimodal embedding—yields modest gains. Refer to the framework diagram illustrating policy module design, which contrasts token reuse with separate policy heads and MetaQuery-style multi-token policy modules. The final architecture adopts a 12-layer policy network with 16 query tokens, significantly enhancing performance by decoupling action prediction from the linguistic token space.
Action modeling is refined through chunking and loss function selection. Instead of predicting actions step-by-step, the model predicts action chunks of length 8, improving temporal coherence. The authors evaluate multiple learning objectives for these continuous action vectors: binning-based classification, direct regression, diffusion (DDIM), flow matching, and VQ-VAE codebook classification. Regression and flow matching outperform classification, with flow matching selected for its robustness to multimodal distributions. The action chunk is modeled as a continuous vector of shape (t,dim), normalized to [−1,1] and discretized into 256 bins for baseline comparison, though the final model uses flow matching for direct continuous prediction.
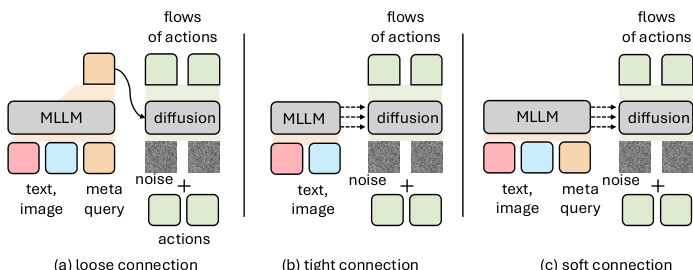
The VLM backbone is upgraded from LLaMA-3.2-3B to Qwen3-VL-2B, which offers a strong performance-efficiency trade-off. The connection between the VLM and policy module is also optimized: a “soft” strategy, which inserts learnable meta queries as a latent buffer between the modules and enables layer-wise interaction, outperforms both “loose” (fully decoupled) and “tight” (direct layer-wise) connections. As shown in the figure below, this soft connection facilitates more effective representation transfer by introducing a latent reasoning space between the perception and action modules.
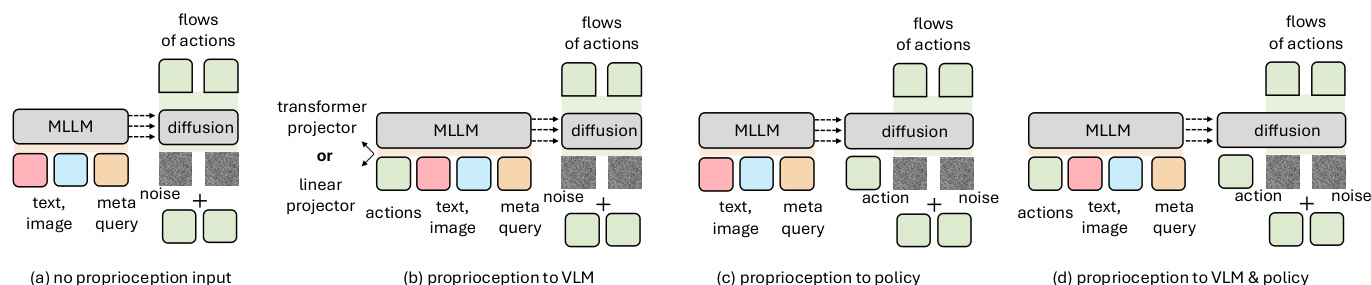
On the perception side, the model incorporates multi-view visual inputs (third-person and wrist cameras) and conditions proprioception either at the VLM or policy module. The authors find that conditioning proprioception at both stages yields the best performance, as illustrated in the proprioception conditioning diagram. Redundant temporal observation history is deemed unnecessary, simplifying the input pipeline.
To further enhance action generation, the authors introduce two auxiliary objectives. World modeling—predicting future image tokens using an Emu3.5 tokenizer—improves performance but triples training cost, leading to its exclusion from the final recipe. Instead, a lightweight frequency-domain auxiliary loss is adopted: the discrete cosine transform is applied to action chunks, and the model minimizes MSE between predicted and ground-truth frequency coefficients, weighted at 0.1–0.2 relative to the flow-matching loss. This exploits the low-rank, structured nature of robotic action sequences.
The final VLANeXt architecture integrates all these components: multi-view visual inputs, language instructions, and proprioception are tokenized and processed by the Qwen3-VL-2B backbone; meta queries enable soft interaction with the 12-layer policy module; action chunks are predicted via flow matching; and a frequency-domain loss provides additional regularization. The full system is depicted in the architecture diagram, which also highlights the frequency-domain objective and the robot’s 6-DoF action space (yaw, pitch, roll, x, y, z).
Experiment
- Adding temporal observation history does not improve performance and may introduce noise, suggesting current-frame inputs suffice for action generation.
- Multi-view camera inputs (third-person plus wrist camera) significantly enhance performance by resolving spatial ambiguities through complementary visual cues.
- Conditioning proprioception at the VLM level outperforms conditioning at the policy level or not using it, enabling better fusion with visual and language inputs.
- The transformer-based proprioception projector offers marginal gains over linear projection, but linear is retained for simplicity.
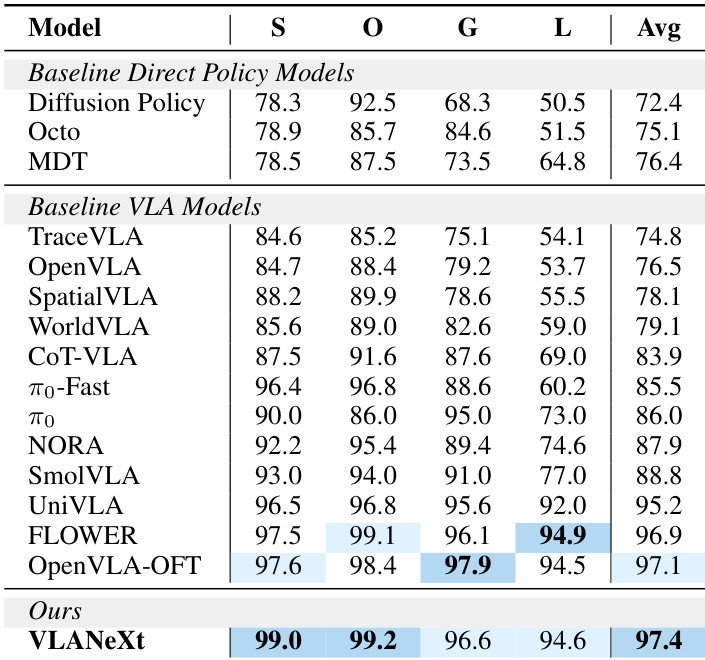
- VLANeXt achieves state-of-the-art results on the standard LIBERO benchmark, outperforming both direct policy learning and prior VLA methods.
- On the challenging LIBERO-plus benchmark with unseen visual, physical, and semantic perturbations, VLANeXt shows strong generalization, improving success rate by 10% over OpenVLA-OFT.
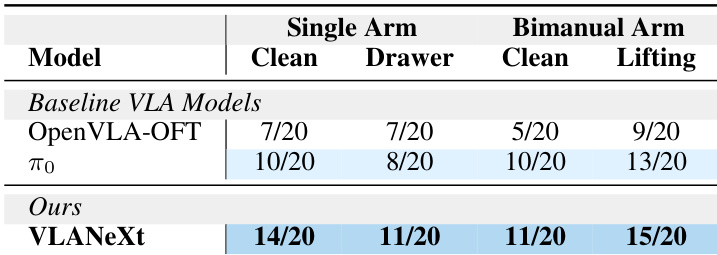
- In real-world evaluations across single-arm and bimanual tasks, VLANeXt performs robustly, even adapting to bimanual tasks without prior bimanual training, demonstrating cross-embodiment flexibility.
The authors evaluate their VLANeXt model on the LIBERO-plus benchmark, which introduces diverse perturbations across visual, physical, and semantic dimensions. Results show that VLANeXt outperforms prior VLA models, including OpenVLA-OFT, across nearly all perturbation types and achieves the highest average success rate, indicating stronger generalization under unseen conditions. The model’s consistent gains suggest that its design choices effectively enhance robustness to real-world variability.
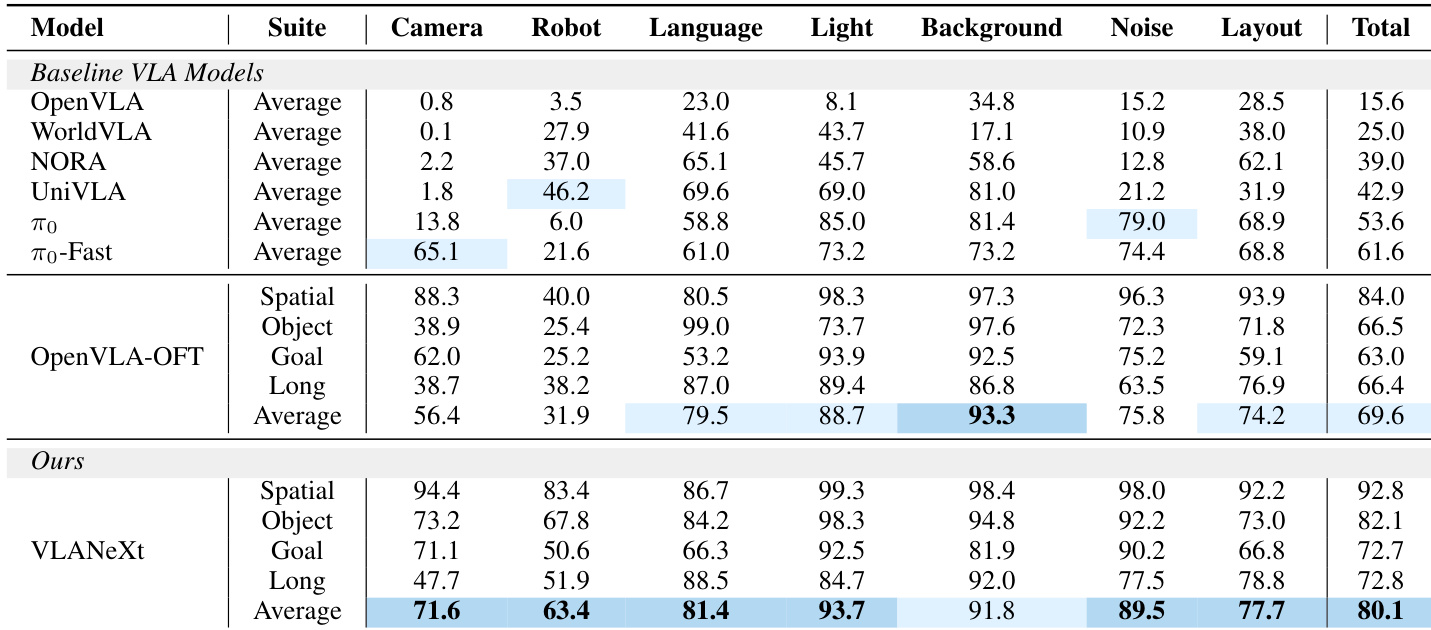
The authors evaluate multiple design choices for vision-language-action models, finding that multi-view camera inputs and conditioning proprioception at the VLM level yield the strongest performance gains, while adding temporal observation history offers no benefit and can degrade results. Their final model achieves state-of-the-art success rates on both standard and perturbed benchmarks, demonstrating robust generalization across visual, physical, and semantic variations. Real-world evaluations further confirm the model’s effectiveness and adaptability to both single-arm and bimanual tasks.
The authors evaluate their VLANeXt model against baseline VLA models in real-world robotic tasks, including both single-arm and bimanual setups. Results show that VLANeXt consistently outperforms the baselines across all tasks, achieving higher success rates even in bimanual scenarios despite being pretrained only on single-arm data. This indicates the model’s strong adaptability to new embodiments and real-world conditions.
The authors evaluate VLANeXt against multiple direct policy and VLA baselines on the LIBERO benchmark, showing it achieves state-of-the-art performance across all task categories. Results indicate that their design choices significantly improve success rates, particularly in object and goal-oriented tasks, outperforming prior methods by a clear margin. The model’s strong average performance suggests effective integration of visual, language, and action inputs for generalizable robotic policy learning.