Command Palette
Search for a command to run...
MolHIT: 계층적 이산 확산 모델을 통한 분자 그래프 생성의 진보
MolHIT: 계층적 이산 확산 모델을 통한 분자 그래프 생성의 진보
Hojung Jung Rodrigo Hormazabal Jaehyeong Jo Youngrok Park Kyunggeun Roh Se-Young Yun Sehui Han Dae-Woong Jeong
초록
확산 모델을 활용한 분자 생성은 인공지능 기반의 신약 개발 및 재료 과학 분야에서 매우 유망한 방향으로 부상하고 있다. 2차원 분자 그래프의 이산적 특성으로 인해 기존에는 그래프 확산 모델이 널리 채택되어 왔지만, 기존 모델들은 화학적 타당성(chemical validity)이 낮고, 1차원(1D) 모델링 대비 원하는 성질을 충족하는 데 어려움을 겪고 있다. 본 연구에서는 기존 방법의 오랜 성능 한계를 극복하는 강력한 분자 그래프 생성 프레임워크인 MolHIT를 제안한다. MolHIT는 계층적 이산 확산 모델(Hierarchical Discrete Diffusion Model)을 기반으로 하며, 화학적 사전 지식을 인코딩하는 추가적인 카테고리로 이산 확산을 일반화하고, 원자 유형을 그 화학적 역할에 따라 분리하는 분리된 원자 인코딩(decoupled atom encoding) 기법을 도입한다. 전체적으로 MolHIT는 MOSES 데이터셋에서 최신 기준(SOTA, State-of-the-Art) 성능을 달성하였으며, 그래프 기반 확산 모델로서는 최초로 거의 완벽한 타당성을 실현하였다. 또한 다양한 지표에서 강력한 1차원 기준 모델들을 초월하였으며, 다중 성질 유도 생성 및 스케일폴드 확장과 같은 후속 작업에서도 뛰어난 성능을 입증하였다.
One-sentence Summary
Researchers from KAIST AI, LG AI Research, and Seoul National University propose MolHIT, a hierarchical discrete diffusion model that enhances molecular graph generation by encoding chemical priors and decoupling atom roles, achieving near-perfect validity and SOTA performance on MOSES, with strong downstream applications in property-guided design and scaffold extension.
Key Contributions
- MolHIT introduces a Hierarchical Discrete Diffusion Model that encodes chemical priors through coarse-to-fine state transitions, addressing the low validity of prior graph diffusion models while preserving structural novelty.
- It proposes Decoupled Atom Encoding to split atom types by chemical roles like aromaticity and charge, resolving information loss in naive encodings and improving reconstruction and generation reliability.
- Evaluated on MOSES and other benchmarks, MolHIT achieves near-perfect validity and state-of-the-art performance across unconditional and conditional tasks, outperforming both 1D and existing 2D baselines.
Introduction
The authors leverage hierarchical discrete diffusion and chemically aware atom encoding to tackle molecular graph generation, where prior models struggle to balance validity and novelty. Existing graph diffusion approaches treat atoms as independent categories and use naive encodings that ignore chemical roles like aromaticity or charge, leading to invalid or unrealistic structures. MolHIT introduces a two-stage diffusion process that first learns coarse chemical identities before refining them, paired with Decoupled Atom Encoding that explicitly separates atom types by their functional roles—resulting in near-perfect validity on MOSES and outperforming both 1D and 2D baselines across benchmarks and downstream tasks like scaffold extension and multi-property generation.
Dataset
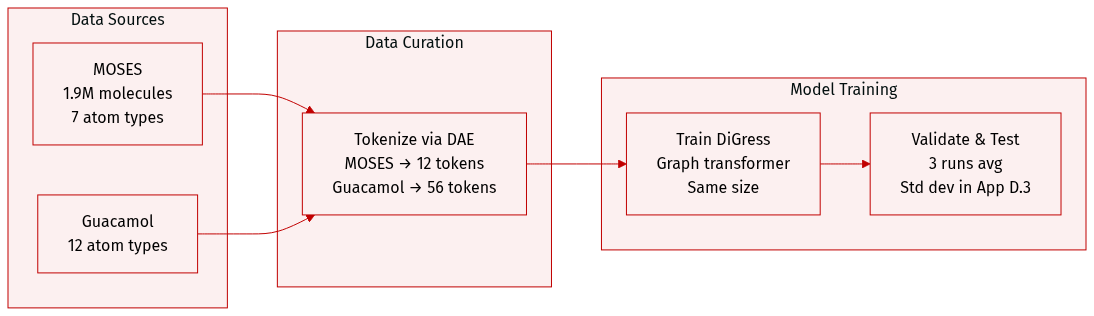
- The authors use two large molecular datasets: MOSES (1.9M molecules, 7 heavy atom types) and Guacamol (12 heavy atom types).
- Both datasets are processed via DAE: MOSES is augmented into 12 tokens, Guacamol is decoupled into 56 tokens.
- The model architecture follows DiGress, using the same graph transformer size.
- All results are averaged over three independent runs, with standard deviations in Appendix D.3.
Method
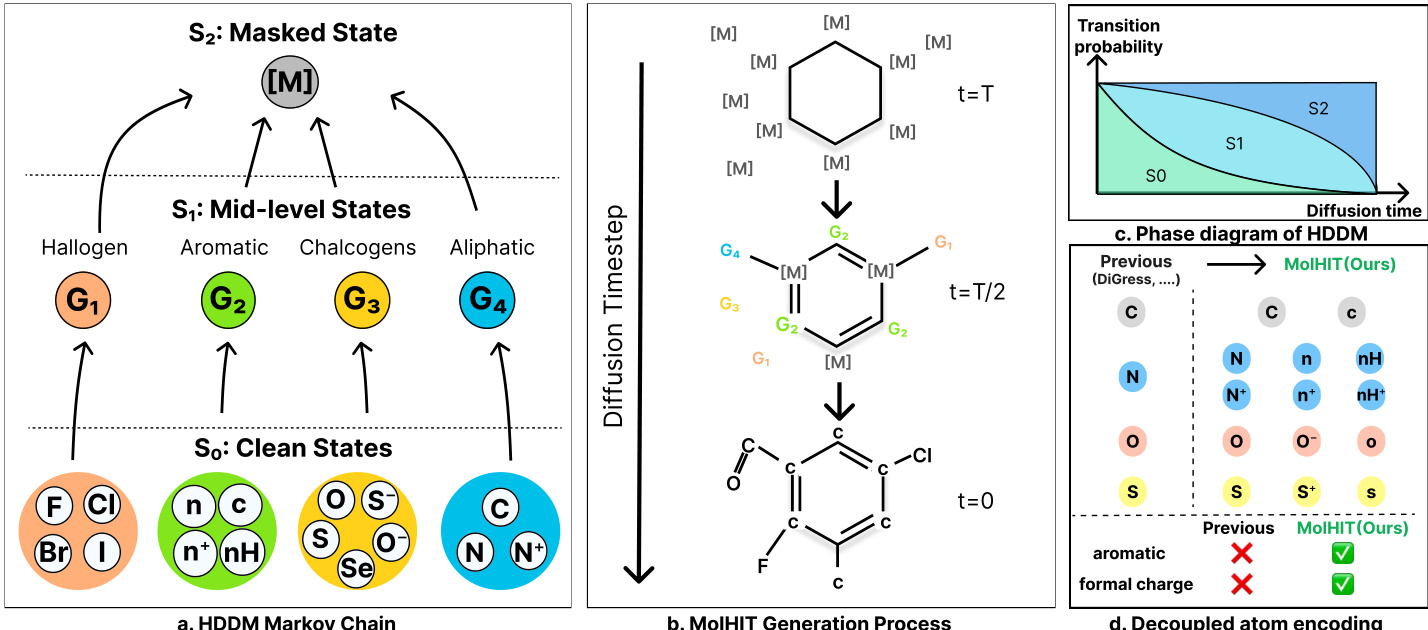
The authors leverage a Hierarchical Discrete Diffusion Model (HDDM) to generalize the standard discrete diffusion framework into a multi-stage corruption process, enabling more structured and chemically meaningful denoising for molecular graph generation. The core innovation lies in augmenting the state space with mid-level semantic categories that bridge the clean atom types and a final masked state, allowing the model to progressively refine predictions from broad chemical classes to specific atomic identities.
As shown in the framework diagram, the HDDM operates over a three-tiered state space: the clean state set S0, a set of mid-level states S1, and a single masked state S2={m}. The forward diffusion process is governed by a sequence of transition matrices that progressively map clean atoms into their semantic groups (e.g., halogens, aromatics, chalcogens, aliphatics) before ultimately transitioning to the masked state. This hierarchical structure is encoded via a block-structured transition kernel Q(1) that maps clean states to mid-level states, and Q(2) that maps all non-masked states to the mask. The cumulative forward transition at timestep t is defined as:
Qt=αtI+(βt−αt)Q(1)+(1−βt)Q(2),where αt and βt are monotonically decreasing diffusion schedules satisfying α0=β0=1 and αT=βT=0, with αt≤βt. This formulation ensures Chapman–Kolmogorov consistency, enabling tractable multi-step transitions.
For molecular graph generation, the authors decouple the diffusion process for atoms and bonds. Atoms are perturbed via the HDDM process, while bonds follow a uniform transition kernel to ensure structural diversity. The forward dynamics are thus:
QX,t=αX,tI+(βX,t−αX,t)QX,t(1)+(1−βX,t)QX,t(2),QE,t=αE,tI+(1−αE,t)1dE1dET.The model is trained to predict the clean graph G0=(X0,E0) from a noisy graph Gt, using a cross-entropy loss that independently optimizes atom and bond predictions:
Lθ=Et,Gt∼q(⋅∣G0)[i=1∑n−logpθX(X0,i∣Gt,t)+λ1≤i<j≤n∑−logpθE(E0,ij∣Gt,t)],where λ balances node and edge contributions.
To enhance chemical fidelity, the authors introduce Decoupled Atom Encoding (DAE), which expands the atom vocabulary by explicitly encoding aromaticity, hydrogen saturation, and formal charge as distinct token states. This resolves structural ambiguities present in coarse encodings (e.g., distinguishing [n] from [nH]) and enables near-perfect reconstruction of complex motifs like heteroaromatics and zwitterions. As illustrated in the figure, DAE allows MolHIT to generate molecules with formal charges at proportions matching the training distribution, a capability absent in prior models.
Sampling is performed via a Project-and-Noise (PN) sampler, which projects the model’s denoised prediction onto the discrete manifold via categorical sampling and then re-noises it to the previous timestep using the forward kernel. This bypasses posterior constraints and encourages structural diversity. Temperature and top-p sampling are applied selectively to atom predictions to control the quality-diversity trade-off. The overall generation process, depicted in the figure, shows a molecule evolving from a fully masked state at t=T, through mid-level semantic states at t=T/2, to a fully reconstructed structure at t=0, guided by the hierarchical transition probabilities.
Experiment
- MolHIT achieves state-of-the-art performance on MOSES across key metrics including Quality, Validity, FCD, and Scaffold Novelty, demonstrating strong navigation of the drug-like chemical manifold while exploring novel structures.
- On GuacaMol, MolHIT outperforms baselines across most metrics despite using the full unfiltered dataset, showing robustness to charged and complex molecules; performance gaps in FCD are attributed to modeling challenges with extended atom vocabularies.
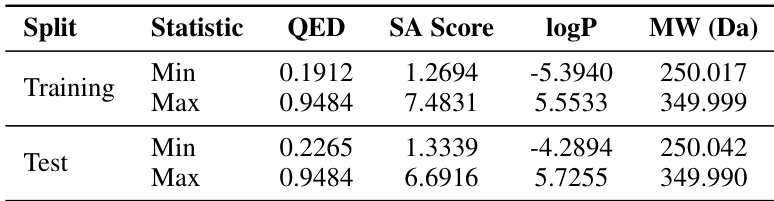
- In multi-property guided generation, MolHIT significantly improves conditioning precision (52.4% lower MAE) and reliability (Pearson r up to 0.950) without sacrificing validity, confirming effective control over chemical properties like QED, SA, MW, and logP.
- For scaffold extension, MolHIT surpasses DiGress in validity, diversity, and hit rates, indicating superior ability to generate chemically plausible and structurally diverse extensions while preserving fixed scaffolds.
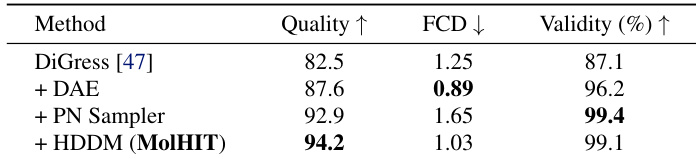
- Ablation studies confirm that DAE, PN Sampler, and HDDM each contribute meaningfully to overall performance, while temperature sampling reveals a trade-off between quality and novelty, with optimal settings yielding near-perfect validity and high quality.
The authors use MolHIT to generate molecules on the MOSES benchmark and compare it against both 1D sequence and 2D graph baselines. Results show MolHIT achieves the highest Quality and Scaffold Novelty while maintaining near-perfect validity, outperforming prior models in balancing structural innovation with chemical feasibility. The model also demonstrates strong distributional fidelity, as reflected in high Scaffold Retrieval and SNN scores, indicating it effectively captures the underlying drug-like chemical space without overfitting.
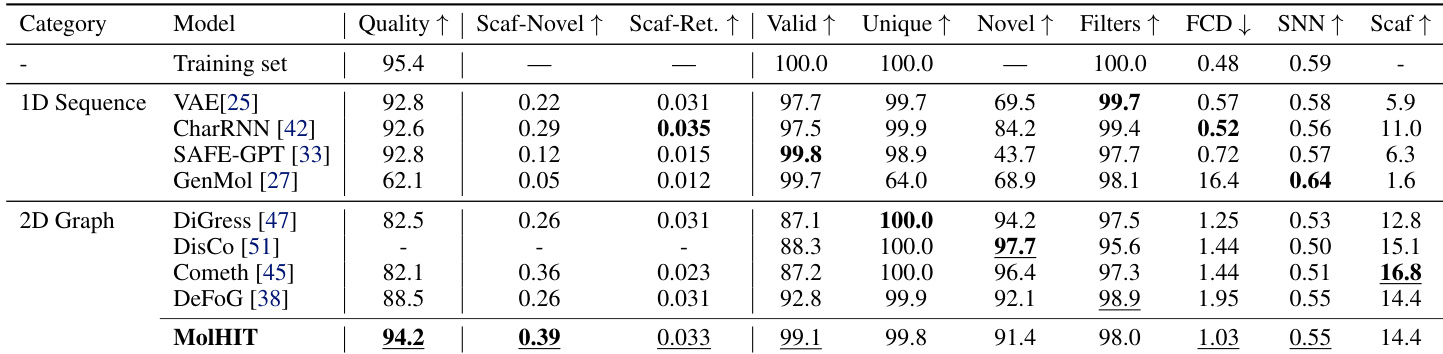
The authors use a full unfiltered GuacaMol dataset to evaluate MolHIT, contrasting with prior models trained on filtered subsets. Results show MolHIT achieves the highest validity and scaffold novelty while maintaining strong distributional fidelity, outperforming DiGress variants across most metrics despite using fewer training epochs. The model demonstrates robustness in handling charged atoms and broader chemical space without sacrificing structural quality.

The authors use the MOSES dataset to evaluate multi-property guided generation, conditioning models on QED, SA, logP, and MW. Results show MolHIT achieves high precision in matching target properties with low MAE and strong Pearson correlation, while maintaining validity above 95%. This indicates the model effectively balances property control with structural feasibility.
The authors use an ablation study to show that integrating decoupled atom encoding, the PN sampler, and HDDM into DiGress progressively improves molecular generation quality, validity, and distributional fidelity. Results show that MolHIT achieves the highest Quality and near-perfect Validity while maintaining competitive FCD, indicating effective navigation of the drug-like chemical space. Each component contributes meaningfully, with the full MolHIT configuration outperforming all intermediate variants.
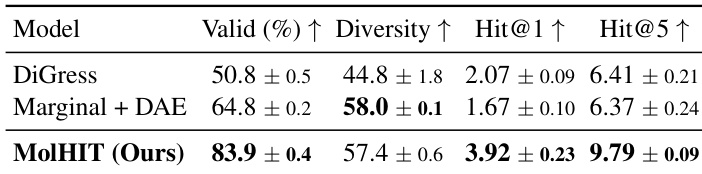
The authors evaluate MolHIT on scaffold extension tasks using the MOSES dataset, comparing it against DiGress and a marginal transition baseline with decoupled atom encoding. Results show MolHIT achieves significantly higher validity and Hit@1 and Hit@5 scores, indicating stronger capability to recover ground-truth molecular extensions while maintaining structural diversity. The improvements suggest MolHIT better balances fidelity to fixed scaffolds with exploration of valid chemical space.