Command Palette
Search for a command to run...
파니니: 구조화된 메모리를 통한 토큰 공간 내 지속적 학습
파니니: 구조화된 메모리를 통한 토큰 공간 내 지속적 학습
Shreyas Rajesh Pavan Holur Mehmet Yigit Turali Chenda Duan Vwani Roychowdhury
초록
언어 모델은 학습 과정에서 다루지 않은 콘텐츠, 예를 들어 새로운 문서, 변화하는 지식, 사용자 고유 데이터 등에 대해 추론하는 데 점점 더 널리 활용되고 있다. 일반적인 접근 방식으로는 검색 기반 생성(Retrieval-Augmented Generation, RAG)이 있다. 이 방식은 문서를 원문 그대로 외부에 청크 단위로 저장하고, 추론 시에 관련성이 높은 부분만 검색하여 언어 모델이 이를 기반으로 추론하게 한다. 그러나 이러한 접근은 테스트 시 계산 자원의 비효율적 사용을 초래한다(동일한 문서를 반복적으로 추론함); 또한 청크 검색 과정에서 관련 없는 맥락이 포함되어 모델이 근거 없는 생성을 할 가능성이 증가한다. 본 연구에서는 인간과 유사한 비매개변수적 지속 학습 프레임워크를 제안한다. 이 프레임워크에서는 기반 모델은 고정된 상태를 유지하고, 새로운 경험은 외부 의미 기억 상태에 통합되며, 이 기억 상태는 지속적으로 축적되고 강화된다. 이를 실현하기 위해 우리는 Panini를 제안한다. Panini는 문서를 생성형 의미 워크스페이스(Generative Semantic Workspaces, GSW)로 표현함으로써, 실현한다. GSW는 엔티티와 이벤트를 인지하는 QA(질의응답) 쌍의 네트워크로 구성되며, 언어 모델이 경험한 상황을 재구성하고, 네트워크 기반의 추론 체인을 통해 잠재된 지식을 탐색할 수 있도록 한다. 쿼리가 주어지면 Panini는 원문 문서나 청크를 직접 탐색하지 않고, 지속적으로 업데이트되는 GSW를 탐색하여 가장 가능성 높은 추론 체인을 검색한다. 여섯 개의 QA 벤치마크에서 Panini는 다른 경쟁적 기법보다 평균적으로 57% 높은 성능을 기록하였으며, 답변-맥락 토큰 사용량은 230배 적게 사용하였다. 또한 완전히 오픈소스 기반 파이프라인을 지원하고, 정제된 불가능한 질문에 대해 근거 없는 답변을 줄이는 데 기여하였다. 결과적으로, GSW 프레임워크를 통해 쓰기 시점에 경험을 효율적이고 정확하게 구조화하면, 읽기 시점에서의 효율성과 신뢰성 측면에서 모두 이점을 얻을 수 있음을 보여준다. 코드는 https://github.com/roychowdhuryresearch/gsw-memory 에서 공개되어 있다.
One-sentence Summary
Shreyas Rajesh, Pavan Holur, and colleagues from UCLA propose PANINI, a continual learning method that operates in token space using structured memory to mitigate forgetting, enabling efficient adaptation without retraining, ideal for dynamic NLP tasks with evolving vocabularies.
Key Contributions
- PANINI introduces a non-parametric continual learning framework that avoids retraining LLMs by storing new knowledge in structured Generative Semantic Workspaces (GSW), which encode documents as entity- and event-aware QA networks to support reasoning over accumulated experiences.
- It employs Reasoning Inference Chain Retrieval (RICR) to traverse GSW at query time, enabling efficient and targeted access to inference chains without reprocessing verbatim text, thereby reducing compute overhead and minimizing irrelevant context injection.
- Evaluated across six QA benchmarks, PANINI outperforms baselines by 5%–7% average accuracy while using 2–30× fewer tokens per answer and significantly reducing unsupported generations on unanswerable queries, demonstrating gains in both efficiency and reliability.
Introduction
The authors leverage non-parametric continual learning to address the inefficiency and unreliability of retrieval-augmented generation (RAG) systems, which store verbatim document chunks and force large language models to reprocess the same text repeatedly at inference time. Prior structured memory approaches like RAPTOR and GraphRAG focus on summarization rather than reasoning, while parametric methods suffer from catastrophic forgetting and high retraining costs. PANINI introduces Generative Semantic Workspaces (GSW)—an entity- and event-aware network of QA pairs—and a lightweight retrieval method called Reasoning Inference Chain Retrieval (RICR) that traverses this structured memory to answer queries without iterative LLM calls. This design achieves state-of-the-art performance across six QA benchmarks, using 2–30x fewer tokens and improving reliability on unanswerable questions, demonstrating that investing compute at write time to build structured memory pays off in efficiency and accuracy at read time.
Dataset

The authors use a mix of single-hop and multi-hop QA benchmarks to evaluate PANINI’s non-parametric continual learning capabilities, focusing on factual memory and associativity across documents.
-
Multi-hop datasets: MuSiQue, 2WikiMultihopQA, HotpotQA, and LV-Eval (hotpotwikiqa-mixup 256k) test multi-step reasoning. MuSiQue emphasizes compositional reasoning; 2WikiMultihopQA covers diverse reasoning patterns over Wikipedia; HotpotQA requires identifying supporting facts from multiple sources. LV-Eval is a large-scale variant used for scalability testing.
-
Single-hop datasets: NQ and PopQA assess basic factual retrieval, ensuring the model maintains performance on direct queries.
-
Platinum variants (MUSIQUE-PLATINUM, 2WIKI-PLATINUM): Constructed to evaluate reliability under missing evidence. Built using a multi-agent LLM system to generate answers from source documents, followed by manual review to label examples as answerable or unanswerable. Final splits: MuSiQue (766 answerable / 153 unanswerable), 2Wiki (906 / 94). Models are prompted to output “N/A” when evidence is insufficient; performance is measured via F1 on answerable examples and binary refusal accuracy on unanswerable ones.
-
Training and evaluation setup: The authors adopt the same dataset splits as HippoRAG2 for fair baseline comparison. All experiments use GPT-4.1-mini to generate Generative Semantic Workspace (GSW) memories — structured semantic networks capturing entities, roles, states, and bidirectional QA pairs — which are then consumed by Qwen3-8B (thinking mode) as the reader, with Qwen3-8B + LoRA handling question decomposition.
-
Processing details: GSW extraction follows a structured prompt guiding the model to identify entities, roles, states, aliases, and factual relationships from raw text. Abbreviations are preserved unless explicitly expanded in the source. No cropping is mentioned; all processing is document-level with structured semantic graph construction.
Method
The authors leverage a structured, non-parametric memory framework called the Generative Semantic Workspace (GSW) to enable efficient, reasoning-grounded question answering. The system, PANINI, operates in three core stages: structured memory construction, reasoning inference chain retrieval (RICR), and answer generation. Each stage is designed to minimize parametric reliance during inference, instead grounding responses in explicitly retrieved, atomic QA evidence.
The framework begins with the construction of per-document GSWs. Each document di is processed by an LLM to generate a semantic graph Gi=(Ei,Vi,Qi), where Ei represents entity nodes annotated with roles and states, Vi represents verb-phrase or event nodes, and Qi consists of question-answer pairs that form directed edges from verb phrases to entities. For example, the statement “Barack Obama was born on August 4, 1961” yields an entity node for Obama, a verb-phrase node “was born,” and QA pairs such as “When was Barack Obama born?” → “August 4, 1961.” This structure explicitly encodes event-attribute relationships in atomic, retrievable units. Refer to the framework diagram for a visual representation of how documents are transformed into individual GSWs and then reconciled into a continually learned global workspace.
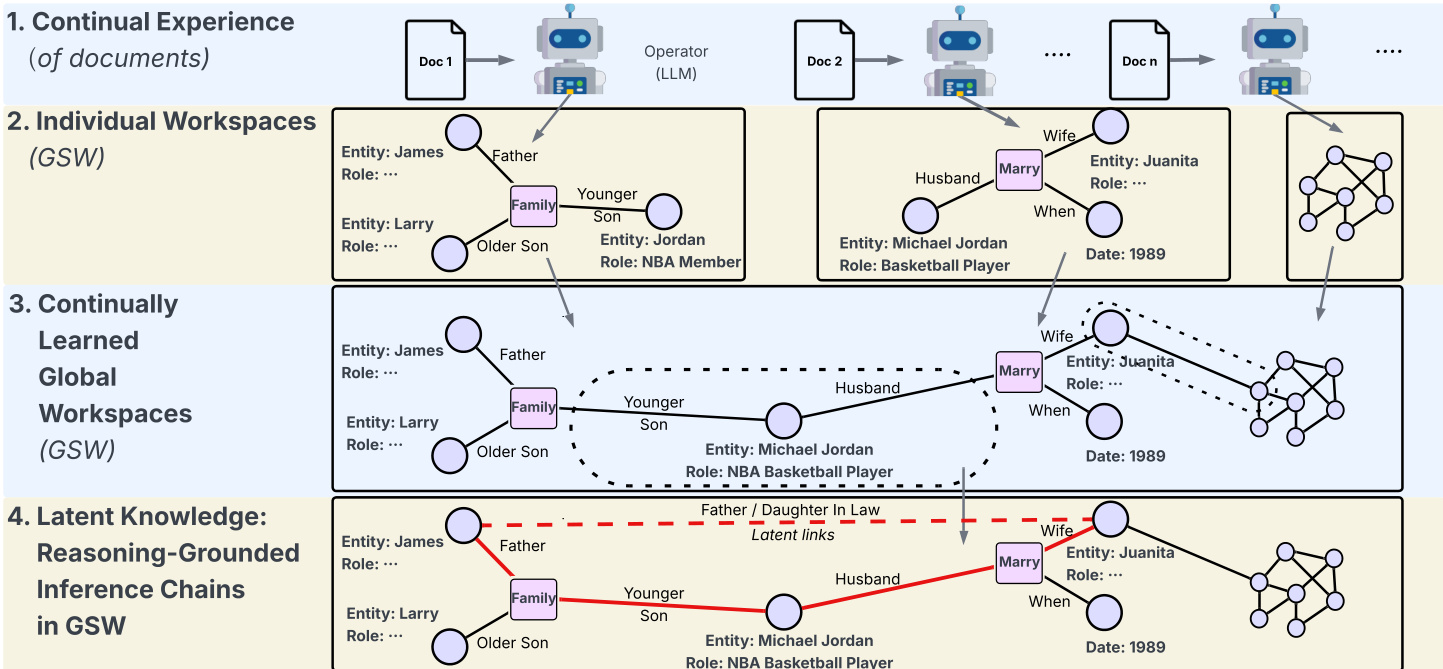
To enable efficient retrieval, the authors implement a dual indexing strategy over the corpus. A sparse BM25 index is built over entity nodes, incorporating both surface forms and their associated roles or states. A dense vector index is constructed over all QA pairs extracted from all GSWs. During retrieval, a query is simultaneously scored against both indices: the entity index provides entry points into local semantic graphs, while the QA index enables semantic matching to candidate facts. This dual approach ensures that evidence is composed solely of compact, targeted QA pairs rather than long passages or graph neighborhoods.
At inference time, PANINI processes a user query through a three-step pipeline. First, a decomposition LLM rewrites the query into a sequence of atomic, single-hop sub-questions. For instance, “When did Lothair II’s mother die?” becomes “Who was the mother of Lothair II?” followed by “When did <Entity_Q1> die?”. The decomposition is performed once and is non-parametric thereafter. As shown in the system overview, this planning step is followed by RICR, a beam-search procedure that navigates the GSWs to assemble evidence chains.
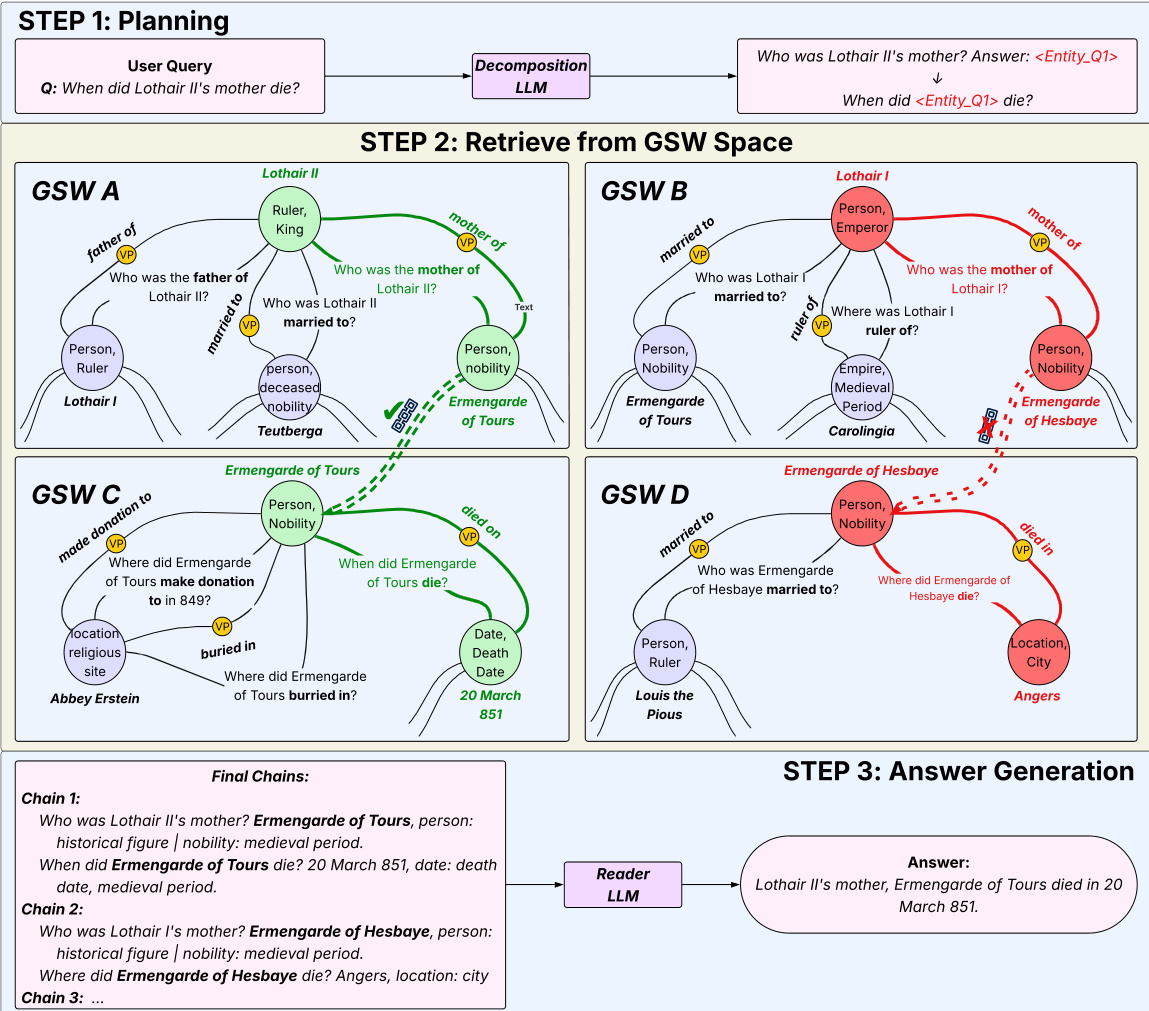
RICR operates hop-by-hop for each sub-question sequence. At each hop t, given a sub-question qt(xt), the system retrieves candidate QA pairs using the dual index: BM25 over entities and dense retrieval over QA pairs. The candidates are reranked using a cross-encoder, and the top-k pairs are retained. A chain C is an ordered sequence of QA pairs (q1G,a1G)⇒(q2G,a2G)⇒⋯⇒(qTG,aTG), where the answer atG from one hop instantiates the next sub-question. To mitigate error propagation, RICR maintains B parallel chains, scoring each by the geometric mean of its constituent relevance scores: score(Ct(j))=(∏l=1tsl,j)1/t. At each hop, chains are pruned to retain only the top-B with unique answers, ensuring diverse exploration of entity paths. After T hops, the top chains are deduplicated, and their QA pairs are passed to the answer model.
The final stage generates a grounded response using an LLM conditioned on the retrieved evidence. The answer model synthesizes the final output from the selected QA pairs, ensuring that responses are directly supported by the retrieved facts. For multi-sequence queries, RICR executes independently for each sequence, and the resulting evidence is combined before answer generation.
To improve GSW quality, especially when using smaller models, the authors introduce a two-pass refinement strategy. After an initial GSW is generated, a second LLM pass inspects and repairs structural deficiencies—adding missing entities, correcting malformed QA pairs, or ensuring bidirectional question coverage. The refinement prompt explicitly instructs the model to preserve correct elements, add missing entities, and enforce QA inversion rules. This lightweight refinement significantly improves downstream performance without requiring larger models for construction.
The entire pipeline is designed to be modular and adaptable. GSW construction, question decomposition, and answer generation can be implemented with different LLMs, and the retrieval and scoring components are non-parametric, enabling robust performance across model sizes and configurations. The system’s strength lies in its ability to dynamically construct inference chains at read time, rather than precomputing dense cross-document graphs, thereby avoiding spurious connections and leveraging LLM-guided scoring at each reasoning step.
Experiment
- PANINI outperforms chunk-based, structure-augmented, and agentic retrieval baselines on multi-hop QA tasks, achieving top average performance while using significantly fewer inference tokens.
- It breaks the typical trade-off between answering accuracy and refusal reliability under missing evidence, maintaining high accuracy on answerable questions while effectively abstaining on unanswerable ones.
- PANINI’s gains persist with fully open-source models, showing robustness to noisy or imperfect GSW construction and preserving advantages even when all components run locally on a single GPU.
- Ablations confirm that question decomposition, dual-index retrieval, QA reranking, and cumulative chain scoring are critical to its performance, especially for multi-hop reasoning.
- PANINI’s structured GSW memory improves not only its own retrieval but also boosts agentic systems like Search-R1 when substituted for their default chunk retrieval.
- It demonstrates superior resilience to corpus growth, maintaining stable performance as distractor documents increase, unlike embedding- or BM25-based methods.
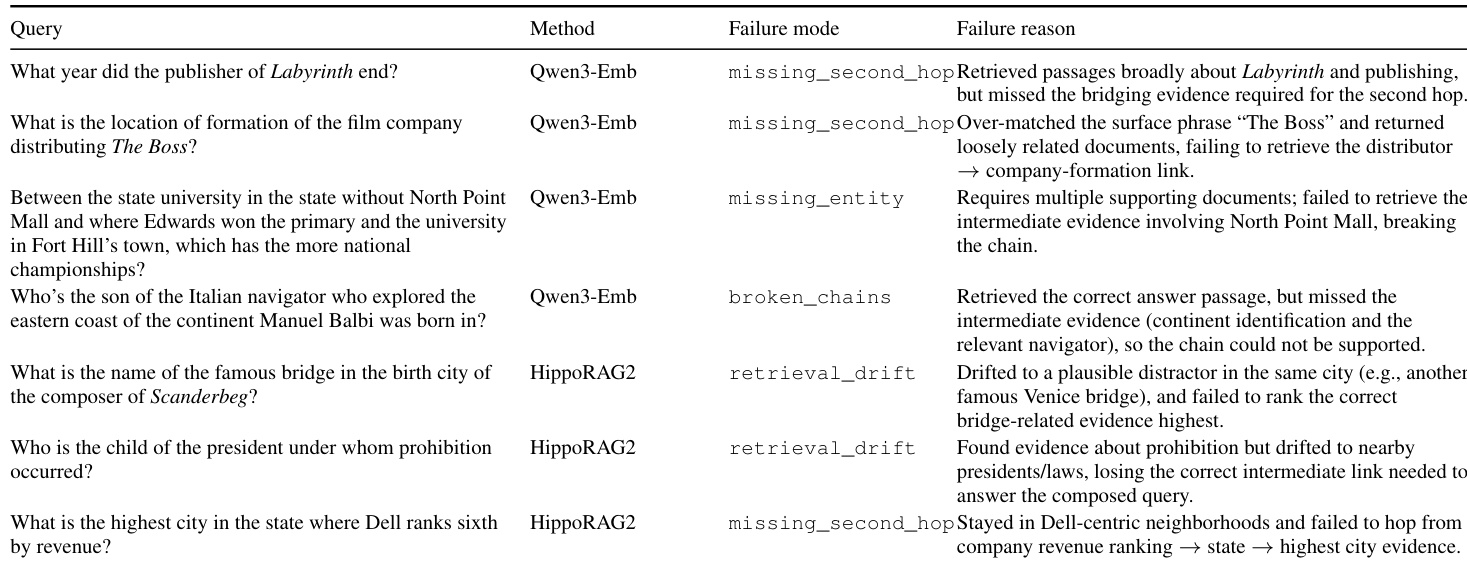
- Qualitative analysis reveals PANINI avoids common baseline failures—such as retrieval drift or broken chains—by enforcing explicit, context-aware, hop-conditioned evidence retrieval.
- Key failure modes stem from imperfect GSW construction (missing verb phrases or QA links) or flawed decomposition, but performance degrades gracefully, supported by beam search resilience.
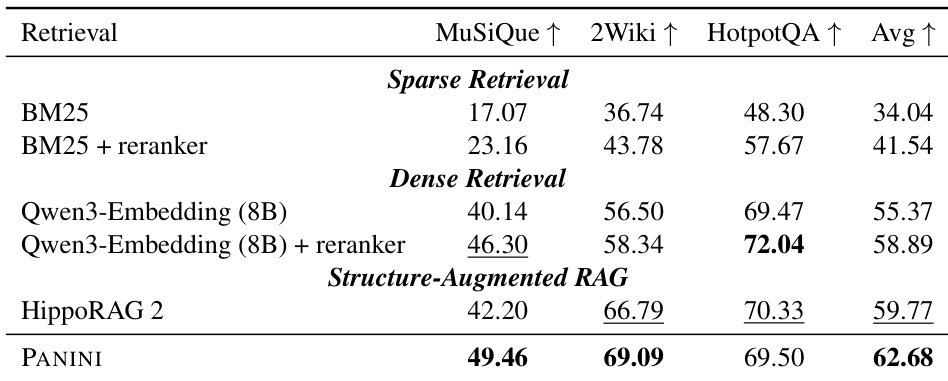
PANINI outperforms both sparse and dense retrieval baselines as well as structure-augmented methods like HippoRAG2 across multiple multi-hop QA benchmarks, achieving the highest average score. The gains are particularly evident on complex tasks such as MuSiQue and 2Wiki, where PANINI’s structured, chain-following retrieval design enables more accurate evidence assembly than traditional chunk-based or graph-based approaches. Results also show that PANINI maintains efficiency advantages while delivering stronger performance, indicating its framework effectively balances precision and computational cost.
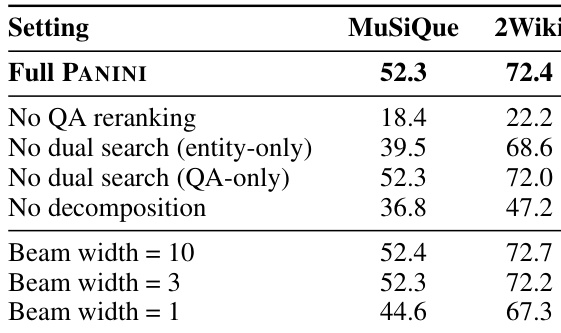
The authors use ablation studies to isolate the impact of key components in PANINI, showing that disabling QA reranking or question decomposition significantly reduces performance, while dual search and beam width adjustments have more nuanced effects. Results show that maintaining QA reranking and decomposition is critical for multi-hop accuracy, whereas reducing beam width to 3 preserves performance while cutting token usage. The framework remains robust across beam widths, with only minor degradation at width 1, indicating flexibility in computational trade-offs.
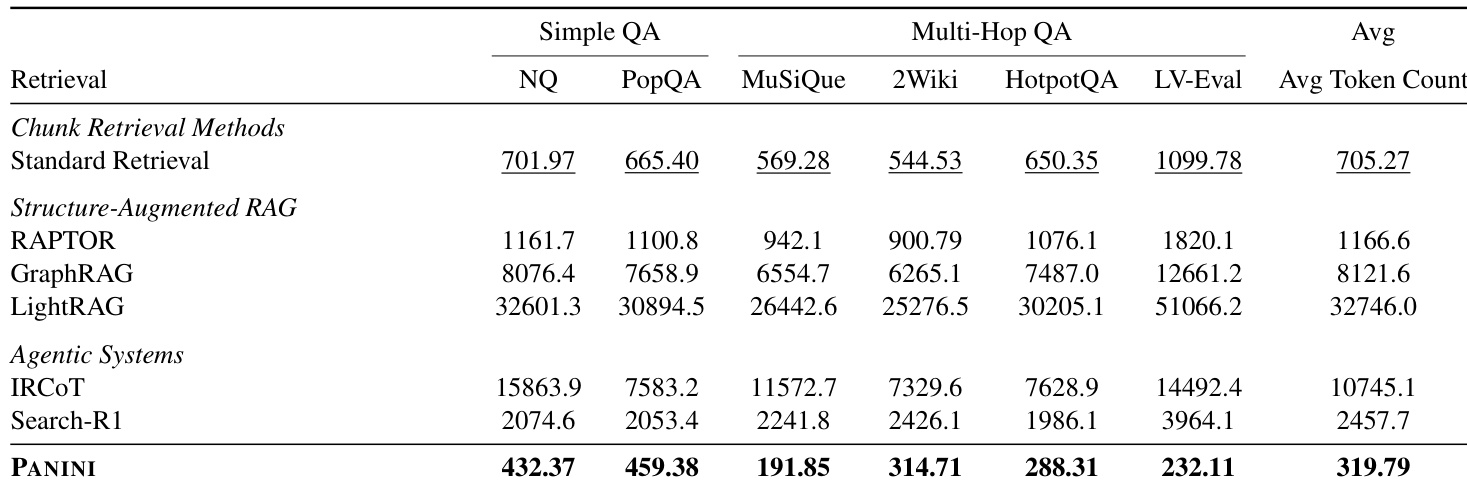
PANINI significantly reduces inference-time token usage compared to chunk-based, structure-augmented, and agentic retrieval methods, achieving the lowest average token count across all evaluated benchmarks. This efficiency stems from its design of conditioning the answer model on concise, targeted QA pairs rather than full document chunks or iterative retrieval traces. The results confirm that PANINI’s lightweight retrieval approach maintains strong performance while drastically cutting computational overhead during inference.
The authors use this table to define the scale of evaluation across six QA benchmarks, specifying the number of queries and passages per dataset. Results across these benchmarks show that PANINI consistently outperforms baselines in multi-hop reasoning while using significantly fewer inference tokens. The framework also maintains strong reliability under missing evidence, breaking the typical trade-off between answering correctly and refusing appropriately.

The authors use qualitative failure analysis to show that dense retrieval systems often miss bridging evidence or break reasoning chains, while graph-based methods like HippoRAG2 suffer from retrieval drift toward semantically related but incorrect entities. PANINI avoids these issues by enforcing explicit, hop-conditioned retrieval through structured QA pairs and dual indexing, which maintains chain integrity and reduces reliance on graph proximity. Results indicate that PANINI’s design improves multi-hop accuracy by aligning retrieval with evolving reasoning context rather than surface similarity or neighborhood structure.