Command Palette
Search for a command to run...
쿼리 앵커를 통한 시나리오 적응형 사용자 표현: 대규모 언어 모델을 통한 접근
쿼리 앵커를 통한 시나리오 적응형 사용자 표현: 대규모 언어 모델을 통한 접근
초록
산업 규모의 사용자 표현 학습은 강건한 보편성과 민감한 작업 적합성 사이의 균형을 유지하는 것이 요구된다. 그러나 기존의 접근 방식은 주로 하류 작업에 무관한 정적 임베딩을 생성하여 통합 벡터 공간 내에서 다양한 시나리오의 상이한 요구사항을 조화롭게 조율하는 데 어려움을 겪는다. 더불어, 이질적인 다중 소스 데이터는 본질적인 노이즈와 모달리티 간 충돌을 유발하여 표현 품질을 저하시킨다. 본 연구에서는 사용자 모델링을 정적 인코딩에서 동적이고 쿼리 인지형 합성으로 전환하는 'Query-as-Anchor' 프레임워크를 제안한다. 대규모 언어 모델(LLM)이 사용자에 대해 깊이 있는 이해를 가능하게 하기 위해, 먼저 다중 모달 행동 시계열과 사용자 이해 의미를 일치시키는 산업 규모의 사전 훈련 데이터셋인 UserU를 구축하였다. 또한, 쿼리 인지형 사용자 표현을 위한 Q-Anchor 임베딩 아키텍처는 이중 타워 LLM에 계층적 코어-파인 인코더를 통합하여 공동 대조-자기회귀 최적화를 통해 구현한다. 일반적인 사전 훈련과 특화된 비즈니스 로직 사이의 격차를 메우기 위해, 클러스터 기반 소프트 프롬프트 튜닝을 도입하여 구분 가능한 잠재 구조를 강제함으로써 모델의 주의 집중을 시나리오 특화 모달리티와 효과적으로 일치시킨다. 배포 측면에서는 시퀀스의 종단에 쿼리를 고정함으로써 KV 캐시 기반 가속 추론을 가능하게 하여 추가적인 지연 시간을 거의 초래하지 않는다. 알리페이 산업 기준 10개 벤치마크에서의 평가 결과, 지속적인 SOTA 성능, 뛰어난 확장성 및 효율적인 배포 능력을 입증하였다. 알리페이의 실제 운영 시스템에서 두 가지 실제 시나리오에 걸쳐 대규모 온라인 A/B 테스트를 수행한 결과, 본 방식의 실용적 효과가 추가로 검증되었다. 본 연구의 코드는 공개를 준비 중이며, 공개 예정 주소는 다음과 같다: https://github.com/JhCircle/Q-Anchor.
One-sentence Summary
Researchers from Ant Group and Zhejiang University propose Q-Anchor, a dynamic query-aware user representation framework that outperforms static embeddings by integrating multi-modal behavioral data with LLMs via hierarchical encoders and soft prompt tuning, enabling efficient, scalable deployment validated across 10 Alipay benchmarks and real-world A/B tests.
Key Contributions
- We introduce UserU, an industrial-scale pre-training dataset that aligns multi-modal user behaviors with semantic understanding through future behavior prediction and QA supervision, enabling LLMs to learn robust, generalizable user representations despite sparse and heterogeneous data.
- We propose Query-as-Anchor, a dynamic framework that generates scenario-specific user embeddings by conditioning LLM-based dual-tower encoders on natural language queries, allowing a single model to adaptively serve diverse downstream tasks without retraining.
- We implement Cluster-based Soft Prompt Tuning and KV-cache-accelerated inference to enforce discriminative latent structures and maintain low-latency deployment, validated by SOTA results across 10 Alipay benchmarks and online A/B tests in production.
Introduction
The authors leverage large language models to address the limitations of static, task-agnostic user embeddings that struggle with cross-scenario adaptability and noisy, sparse behavioral data. Prior methods either produce fixed representations ill-suited for diverse downstream tasks or fail to bridge the modality gap between language-centric LLM pretraining and symbolic user logs. Their main contribution is Query-as-Anchor, a framework that dynamically generates scenario-specific user embeddings by conditioning LLMs on natural language queries, supported by UserU—a large-scale pretraining dataset with behavior prediction and QA supervision—and optimized with cluster-based soft prompt tuning for efficient, low-latency inference. This enables unified, adaptable user modeling across marketing, risk, and engagement tasks without retraining.
Dataset
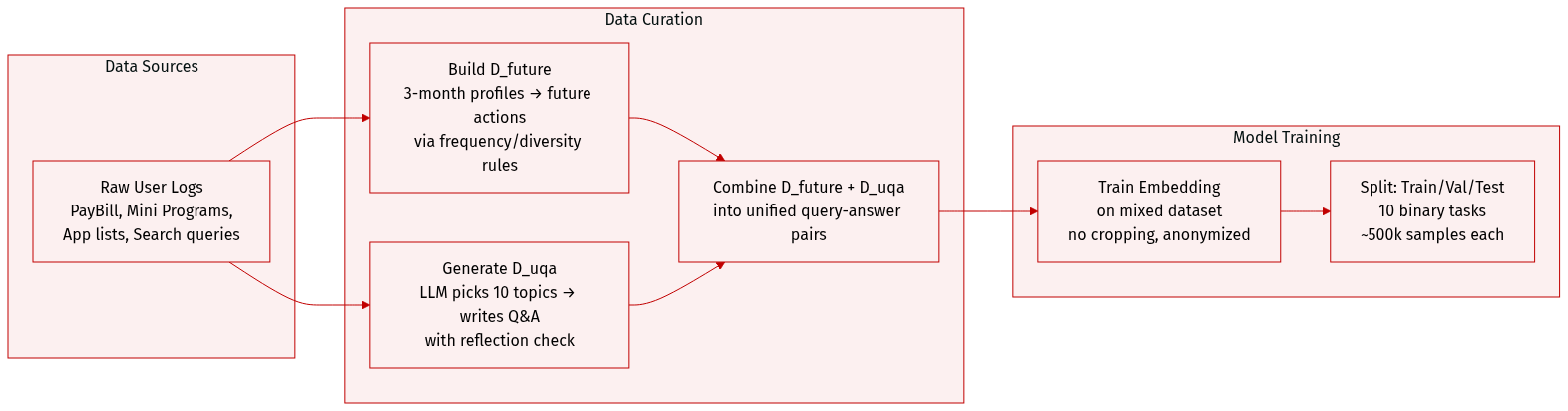
- The authors use the UserU Pretraining Dataset to improve user embedding performance across diverse tasks by combining behavior prediction and synthetic query-answer data.
- The dataset has two main subsets: D_future (behavior prediction) and D_uqa (LLM-generated user queries and answers).
- D_future contains N samples derived from three-month user behavior profiles, aggregated into future action summaries using frequency- and diversity-aware selection; each sample pairs a user profile + fixed template query with a predicted future action.
- D_uqa contains M synthetic samples generated via LLM: for each user profile, the model retrieves 10 relevant life topics, generates grounded queries, and produces answers with a post-generation reflection step to ensure faithfulness and context validity.
- Input data includes heterogeneous sources like PayBill transactions, Mini Program logs, App lists, and search queries, encoded as hierarchical user tokens followed by an optional instruction and a <USER_EMB> token to signal embedding extraction.
- The authors train using a mixture of both subsets, with no explicit ratio specified, but emphasize decoupling pretraining from downstream tasks to improve generalization.
- No cropping is applied; instead, user profiles are contextualized via concatenation with queries, and all data is anonymized or synthetic for privacy.
- Downstream evaluation uses 10 real-world binary classification tasks with ~500k test samples each, where labels are assigned based on whether a user triggers a target event within a prediction window.
Method
The authors leverage a hierarchical, query-driven framework called Q-Anchor Embedding to unify multi-modal user behavior into a semantically grounded, task-adaptive representation space. The architecture is structured around three core components: a coarse-to-fine user encoder, a dual-tower pretraining mechanism, and a soft prompt tuning module for downstream adaptation—all designed to operate efficiently at industrial scale.
The hierarchical user encoder processes raw behavioral signals from six modalities—Bill, Mini, SPM, App, Search, and Tabular—each represented as sequences of events over a 90-day window. For each modality m, event-level embeddings hm,t are first projected via modality-specific MLPs into refined event tokens zm,t(evt). These are then aggregated via mean-pooling into modality-level summaries zˉm(evt), which are further transformed by a shared modal adapter into zm(mdl). A global user representation z(usr) is derived by consolidating all modality embeddings through a dedicated user adapter. The final input token sequence ei is constructed by concatenating representations across all three levels: user, modality, and event, enabling the LLM to dynamically attend to either granular actions or high-level summaries based on the query context.
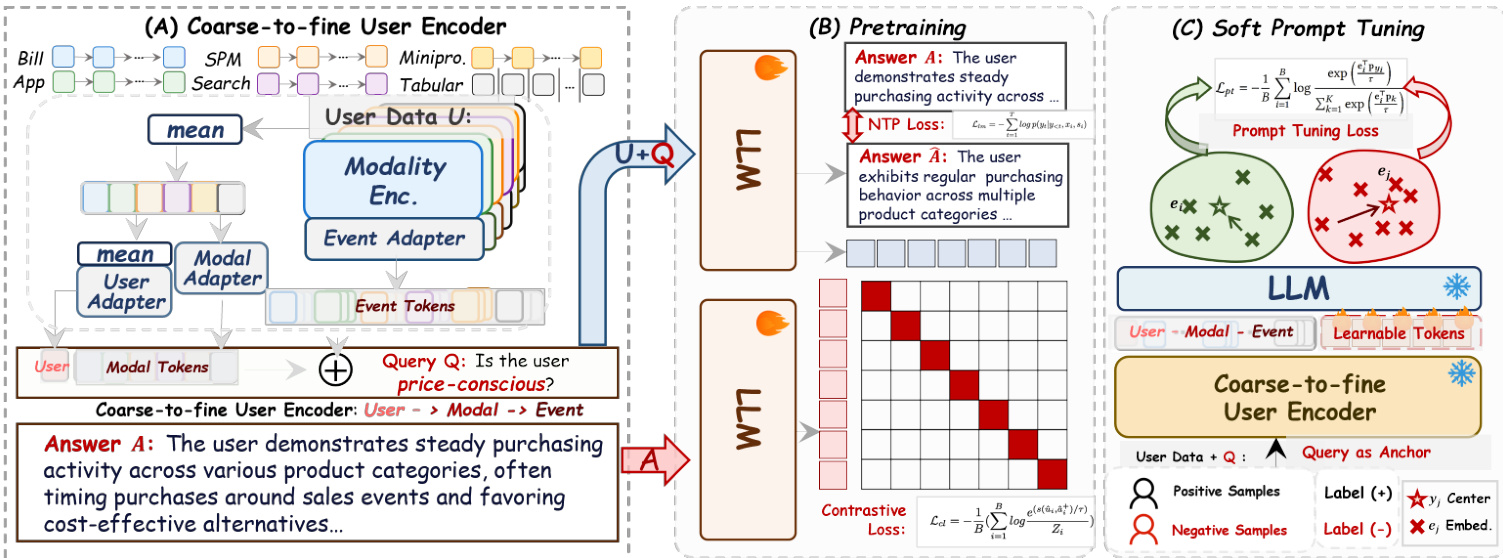
The pretraining phase employs a dual-tower architecture that aligns user behavior with semantic intent. The Anchor Tower ingests the hierarchical user tokens ei and appends a natural language query qi as a trailing anchor, producing a query-conditioned embedding ui,q=LLManc(ei,qi). The Semantic Tower encodes the target answer ai into vai=LLMsem(ai), using the same LLM backbone to ensure alignment in a shared latent space. Training is driven by a joint objective: a contrastive loss Lcl that pulls positive pairs (ui,q,vai) together while pushing apart negatives using a margin-based mask mij, and a generative Next-Token Prediction loss Lntp that reconstructs the answer sequence autoregressively. The total loss Ltotal=Lcl+Lntp ensures embeddings are both discriminative and semantically dense.
To adapt the pretrained model to downstream tasks without full fine-tuning, the authors introduce a soft prompt tuning mechanism. Learnable prompt tokens are inserted into the LLM’s input space to modulate the latent representation ui,q, while class prototypes {pk} are optimized via a prototypical contrastive loss Lpt that pulls user embeddings toward their assigned class centers. This enables task-specific alignment—such as distinguishing high-risk from low-risk users—while preserving the foundational multi-modal alignment learned during pretraining.
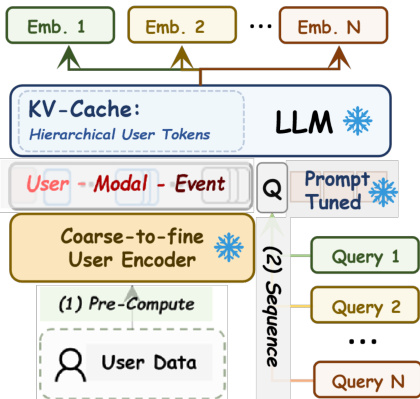
For deployment, the system leverages a KV-cache optimization to decouple user encoding from query processing. The hierarchical prefix ei is encoded once and cached, allowing multiple downstream queries {q1,…,qn} to be processed sequentially with only incremental computation for the query tokens. This amortizes the cost to O(Lqj) per query, enabling high-throughput, multi-scenario inference. Daily updates are performed incrementally: only modalities with new events are re-encoded, and their summary tokens are refreshed in a rolling buffer, ensuring fresh, bounded, and cost-efficient representations at scale.
Experiment
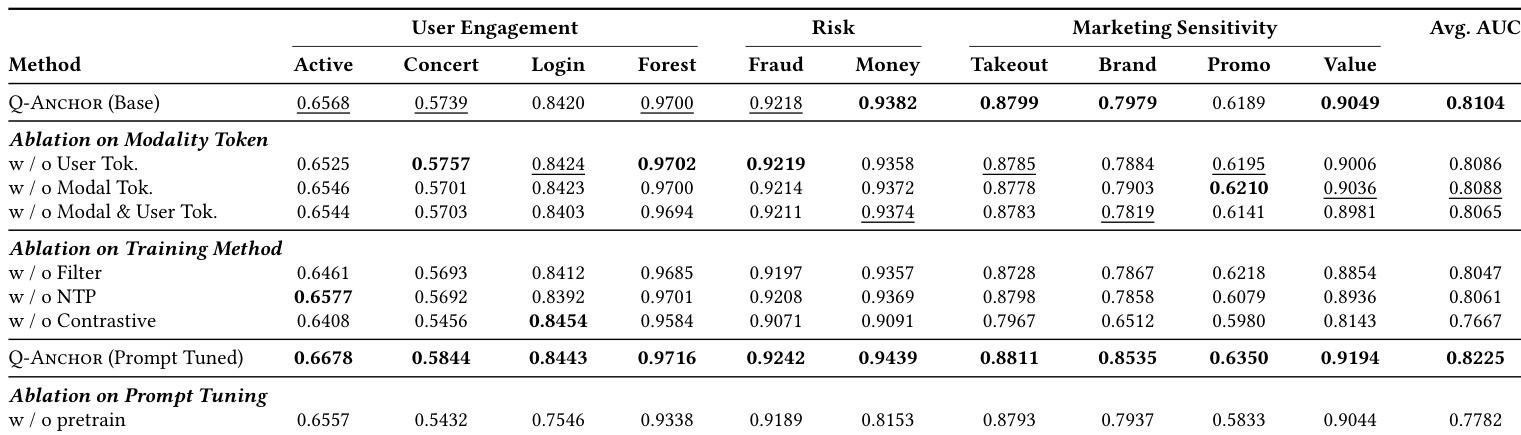
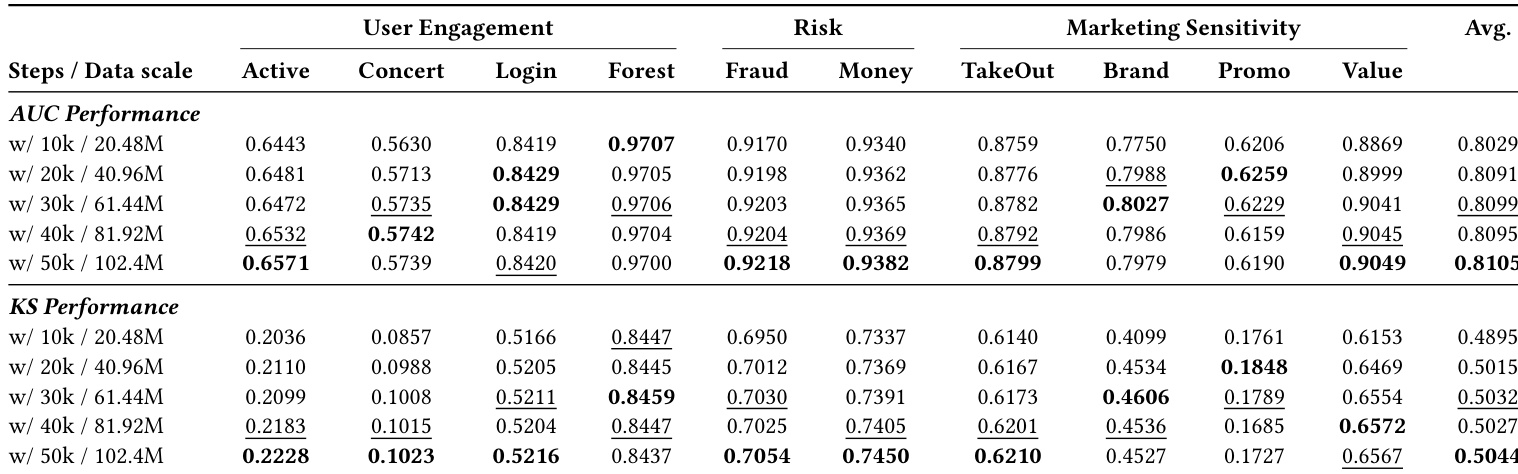
- Q-Anchor consistently outperforms general-purpose and user-specific baselines across 10 real-world binary classification tasks, demonstrating superior AUC and KS scores, especially in Risk and Marketing domains, validating that representation alignment matters more than semantic capacity alone.
- The model generalizes robustly across Engagement, Risk, and Marketing domains without task-specific architectures, supporting a “one-model-for-many” paradigm enabled by query-conditioned anchoring.
- Pretraining on larger datasets yields steady gains, while scaling model size beyond 0.5B parameters shows no consistent improvement and even regression, confirming data scale matters more than parameter scale for embedding quality.
- Prompt tuning with just 6 learnable tokens and 500 steps delivers most of the performance gain, saturating quickly and enabling efficient, interpretable specialization via attention shifts toward scenario-relevant modalities.
- Ablations confirm contrastive alignment is essential for embedding structure, while modality and user tokens provide critical inductive bias; pretraining is foundational, not optional, for capturing behavioral priors.
- Online A/B tests show tangible business impact: improved cash-reserve outreach engagement and credit delinquency detection, validating real-world efficacy.
- Deployment at scale leverages shared prefix computation, enabling multi-scenario serving with minimal incremental cost per scenario.
- PCA and t-SNE visualizations confirm prompt tuning sharpens cluster separation, aligning representations with downstream decision boundaries without architectural changes.
The authors use a lightweight 0.5B LLM backbone with modality-specific encoders and contrastive pretraining to generate user representations, then apply soft prompt tuning for scenario adaptation. Results show that their Q-Anchor method consistently outperforms both general text embeddings and specialized user representation models across all 10 tasks, with prompt tuning delivering significant gains in both AUC and KS while maintaining efficiency. The approach proves robust across domains and scales effectively with data and prompt tokens, but not with model size, highlighting that representation quality depends more on training signal alignment than parameter count.
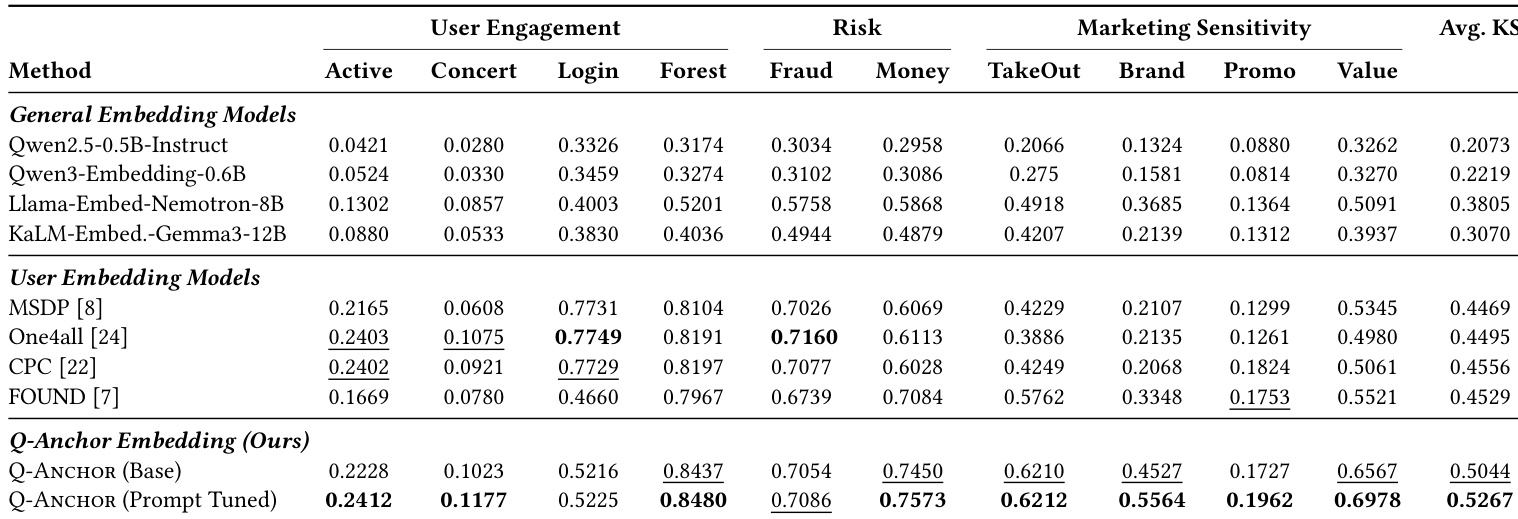
Results show that increasing the number of learnable prompt tokens from 1 to 6 consistently improves both AUC and KS across all evaluated scenarios, with performance plateauing beyond 6 tokens. The 6-token configuration achieves the highest average AUC and KS, indicating that minimal parameter updates are sufficient to specialize the universal representation for diverse downstream tasks. This efficiency supports scalable deployment, as further token increases yield diminishing returns and occasional performance degradation.
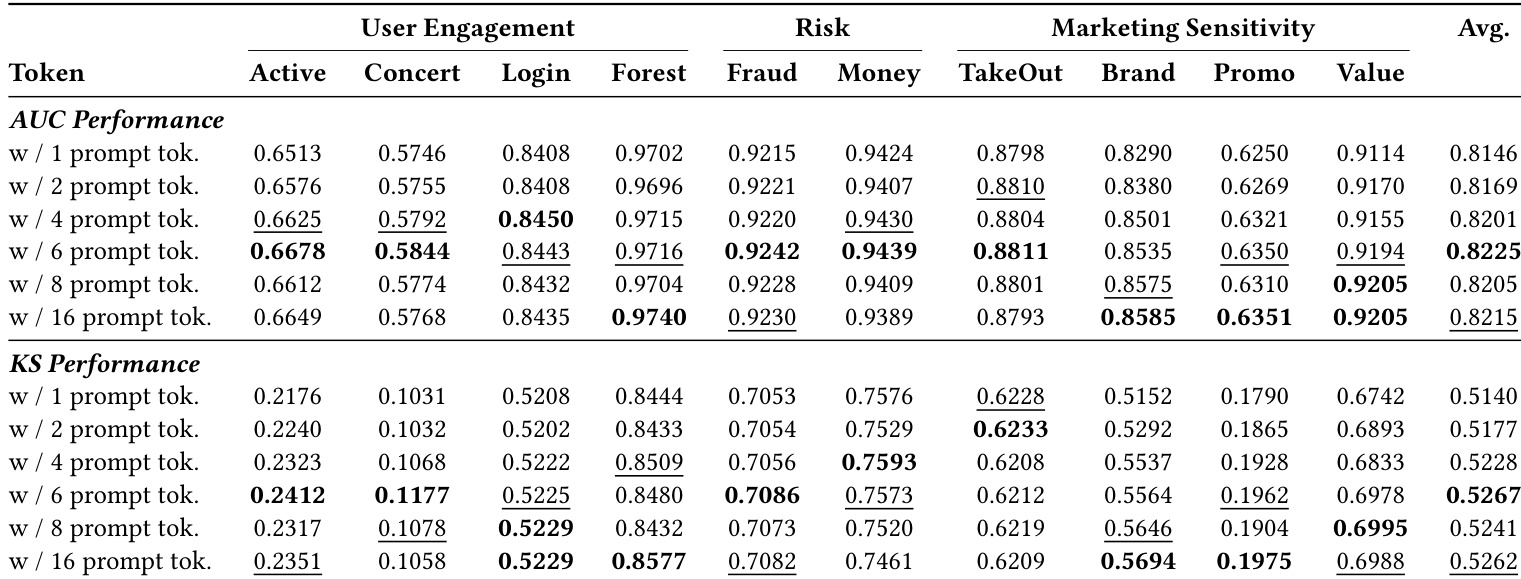
The authors use Q-Anchor embeddings to outperform existing business-specific models in two key Alipay scenarios, with prompt tuning delivering additional gains through minimal parameter updates. Results show consistent improvements in both AUC and KS metrics, confirming that a universal representation combined with lightweight scenario conditioning can surpass handcrafted features while maintaining computational efficiency. The method proves effective even without task-specific architecture, supporting scalable deployment across diverse business objectives.
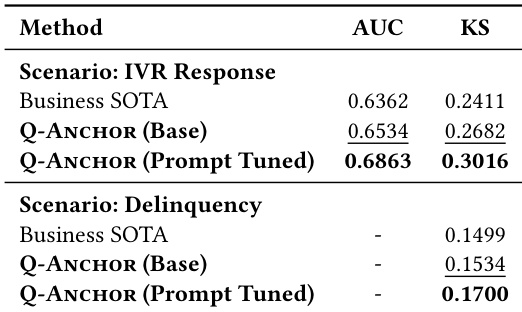
The authors use a 0.5B-parameter LLM backbone with fixed user representations and scale pretraining data from 20.5M to 102.4M samples, observing consistent gains in both AUC and KS across all 10 tasks as data increases. Results show that performance improves steadily with more pretraining data, with the highest average AUC (0.8105) and KS (0.5044) achieved at 50k steps, while larger model sizes do not yield consistent improvements under the same training budget. This indicates that for user representation learning, data scale contributes more reliably to performance than model scale.
The authors use a structured ablation study to isolate the contributions of modality tokens, training objectives, and prompt tuning in their Q-Anchor framework. Results show that removing modality or user tokens causes minor performance drops, while eliminating contrastive learning leads to the largest degradation, confirming its role in shaping the embedding space. Prompt tuning consistently boosts performance, but omitting pretraining causes a systemic collapse, underscoring that pretraining provides essential behavioral priors for effective downstream adaptation.