Command Palette
Search for a command to run...
InnoEval: 연구 아이디어 평가를 지식 기반의 다중 관점 추론 문제로 본다
InnoEval: 연구 아이디어 평가를 지식 기반의 다중 관점 추론 문제로 본다
초록
대규모 언어 모델(Large Language Models, LLM)의 급속한 발전은 과학적 아이디어 생산에 큰 촉매 역할을 했으나, 이와 함께 아이디어 평가 기술의 진보는 따라오지 못하고 있다. 과학적 평가의 본질은 전문 지식 기반, 공동 논의, 다기준 의사결정이 필수적이다. 그러나 기존의 아이디어 평가 방법은 좁은 지식 범위, 단순화된 평가 차원, 그리고 LLM을 심사자로 활용할 때 내재된 편향 문제로 인해 한계를 드러낸다. 이러한 문제를 해결하기 위해, 우리는 아이디어 평가를 지식 기반의 다각적 추론 문제로 재정의하고, 인간 수준의 아이디어 평가를 모방할 수 있도록 설계된 심층 혁신 평가 프레임워크인 InnoEval을 제안한다. InnoEval은 다양한 온라인 소스로부터 동적 증거를 검색하고 지식 기반으로 구속하는 이질적 심층 지식 검색 엔진을 도입한다. 또한, 각기 다른 학문적 배경을 가진 리뷰어들로 구성된 혁신 리뷰 보드를 통해 리뷰 합의를 도출함으로써, 다차원적이고 분리된 평가를 여러 지표에 걸쳐 수행할 수 있도록 한다. InnoEval의 성능을 평가하기 위해 권위 있는 동료 심사 논문 제출물에서 유래한 포괄적인 데이터셋을 구축하였다. 실험 결과, InnoEval은 개별 평가(point-wise), 쌍별 평가(pair-wise), 그룹별 평가(group-wise) 등 다양한 평가 과제에서 기존 기준 모델들을 일관되게 상회하며, 인간 전문가와 매우 유사한 판단 패턴과 합의 수준을 보여주었다.
One-sentence Summary
Researchers from Zhejiang University and University of Amsterdam propose InnoEval, a knowledge-grounded multi-perspective framework using dynamic evidence retrieval and diverse reviewer boards to overcome LLM biases in scientific idea evaluation, achieving human-aligned consensus across benchmark tasks.
Key Contributions
- InnoEval addresses the critical gap in evaluating scientific ideas generated by LLMs by framing evaluation as a knowledge-grounded, multi-perspective reasoning task, countering narrow knowledge horizons and LLM-as-a-Judge bias through a heterogeneous deep knowledge search engine that retrieves dynamic evidence from literature, web, and code sources.
- The framework simulates human review consensus via an innovation review board of persona-based evaluators with distinct academic backgrounds, each independently assessing ideas across five decoupled dimensions—Clarity, Novelty, Feasibility, Validity, and Significance—to preserve multi-criteria decision-making and mitigate single-judge bias.
- Evaluated on datasets derived from peer-reviewed submissions, InnoEval outperforms baselines by 16.18% F1 in point-wise prediction, 5% in pair-wise accuracy, and 7.56% in group-wise ranking, with human evaluations confirming high alignment in judgment patterns and consensus.
Introduction
The authors leverage large language models to address the growing gap between automated idea generation and human-level idea evaluation in scientific research. Existing methods suffer from narrow knowledge bases limited to static papers, biased single-judge evaluations, and flattened metrics that ignore the multidimensional nature of innovation. In response, they introduce InnoEval — a framework that treats idea evaluation as a knowledge-grounded, multi-perspective reasoning problem. It combines a heterogeneous deep knowledge search engine that pulls dynamic evidence from literature, web, and code sources, with a simulated innovation review board of diverse academic personas to generate consensus-driven, multi-dimensional assessments across clarity, novelty, feasibility, validity, and significance. Their approach outperforms baselines in point-wise, pair-wise, and group-wise tasks while aligning closely with human expert judgments.
Dataset

The authors use a multi-tiered dataset built from NeurIPS 2025 and ICLR 2025 papers via OpenReview, filtered to exclude withdrawn or placeholder submissions. They construct three core subsets:
-
Point-wise Dataset (D_point, 217 samples):
- Composed of 136 ICLR 2025 and 81 NeurIPS 2025 ideas.
- Stratified by final decision: 138 Reject, 66 Poster, 9 Spotlight, 4 Oral (Reject: 61.3%, Poster: 29.3%, Highlight: 9.4%).
- Each idea is extracted via agent M_e, then manually verified.
- Tasks: Binary classification (Reject vs. Accept) and ternary classification (Reject, Poster, Highlight).
- Metrics: Accuracy and macro F1.
-
Group-wise Dataset (D_group, 172 instances):
- Built by using each D_point idea’s abstract as a query to retrieve similar papers via bge-base-en-v1.5 (top 800), then reranked with bge-reranker-base to 120.
- One highest-similarity paper per decision stratum forms a group, enabling label-based ranking.
- Tasks: Best idea selection (Accuracy) and full ranking (LIS score + Accuracy).
- LIS measures alignment between predicted and gold rankings as length of longest increasing subsequence divided by group size.
-
Pair-wise Dataset (D_pair, 372 samples):
- Derived from D_group: 172 easy pairs (e.g., Reject vs. Highlight) and 200 hard pairs (e.g., Poster vs. Highlight).
- Tasks: Binary comparison, evaluated via Accuracy for each difficulty level separately.
All datasets are used for evaluation only — no training. The authors also deploy a persona-based review system (F. Innovation Review Board) to mitigate LLM bias, where synthetic reviewers with tailored backgrounds mask evidence proportionally to their expertise scores (e.g., 20% masking for Literature Familiarity = 8). These personas are generated using DeepSeek-V3.2 and embedded into prompts for dimension-specific agents.
Method
The authors leverage a multi-stage, agent-driven architecture called InnoEval to systematically evaluate research ideas by grounding them in dynamic, heterogeneous knowledge sources and synthesizing multi-perspective assessments. The framework begins with an Extraction Agent that parses raw textual input into a structured six-tuple representation—comprising TLDR, motivations, research questions, methods, experimental settings, and expected results—enabling precise downstream processing. This structured idea then feeds into a heterogeneous deep-knowledge search engine, which operates through iterative cycles of fast and slow search phases, query refinement, and knowledge ranking.
Refer to the framework diagram, which illustrates the end-to-end pipeline. The process initiates with Query Generation, where tailored queries are constructed for each idea component and dispatched across multiple search tools—including Google, arXiv, Semantic Scholar, and GitHub—each represented by distinct icons in the diagram. These queries are enriched with synonym expansions to account for terminological variance across domains. The Fast Search phase retrieves brief results from these tools, which are then ranked and filtered using a hybrid scoring function combining semantic similarity (Ssem) and model-as-judge scores (Sllm), weighted by a coefficient α. The top-m results per knowledge type (literature, web, code) are retained for subsequent enrichment.
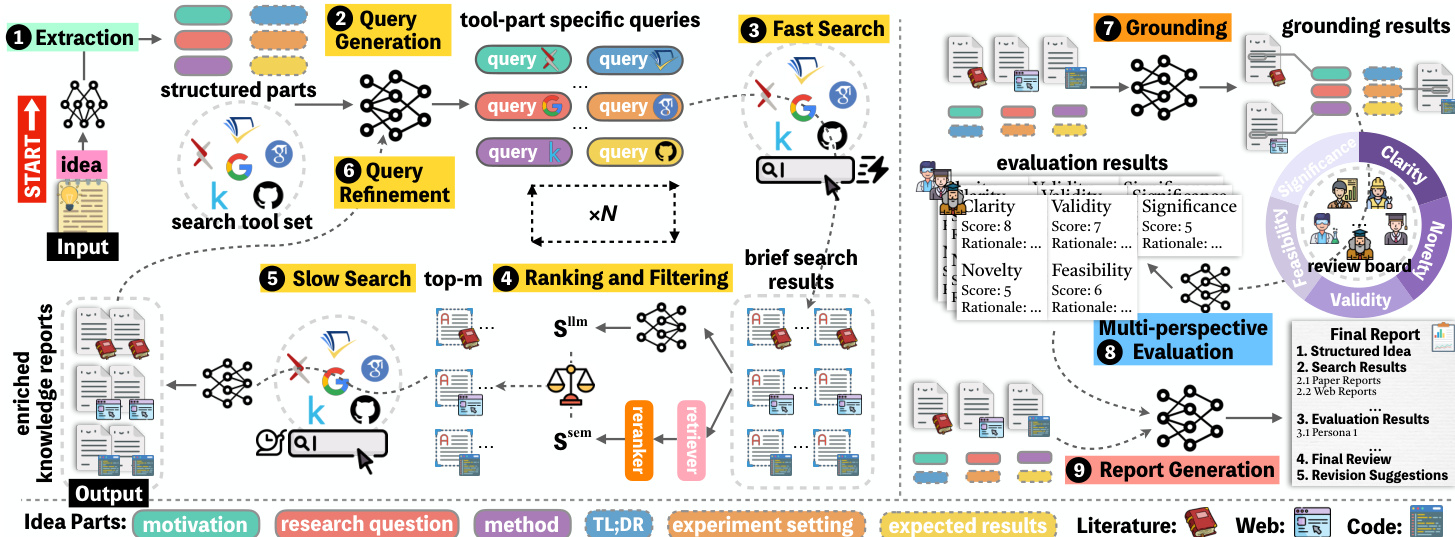
The Slow Search phase enriches the filtered results: for literature, full PDFs are parsed into structured text; for web content, pages are summarized; and for code repositories, call graphs and READMEs are analyzed to generate executable context. This enriched knowledge is then subjected to iterative Query Refinement, where the Search Agent revises queries based on prior retrieval outcomes—rewriting, generalizing, or concretizing them—to uncover deeper or more relevant background material. This loop repeats N times, progressively expanding the knowledge corpus.
Following retrieval, a Grounding Agent aligns each idea component with specific evidence from the retrieved knowledge, producing fine-grained relevance analyses that explicitly support or contradict the idea’s claims. These grounding results serve as the foundation for Multi-dimensional Multi-perspective Evaluation, conducted by a panel of persona-based evaluators. Each persona, drawn from an Innovation Review Board, is assigned a subset of knowledge based on their simulated familiarity, and evaluates the idea across five dimensions—Clarity, Validity, Novelty, Feasibility, and Significance—using dedicated agent evaluators Mψ. Each evaluation yields a score and narrative rationale, aggregated into a meta-review.
Finally, a Report Agent synthesizes the enriched knowledge, grounding results, and evaluation outputs into a structured final report. For point-wise evaluation, this includes background knowledge, revision suggestions derived from future-oriented knowledge, and a meta-review with a final decision. For group-wise evaluation, the system compares all ideas across dimensions and produces a ranked list alongside comparative analyses. The entire architecture is designed to be modular, extensible, and grounded in real-time, diverse knowledge sources, ensuring both timeliness and depth in evaluation.
Experiment
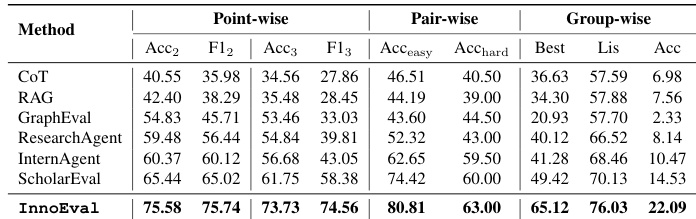
- InnoEval outperforms multiple baselines across point-wise, pair, and group evaluation tasks by leveraging multi-source retrieval, multi-perspective review, and grounded analysis, achieving higher F1 scores and better label dispersion.
- Qualitative evaluations show InnoEval’s reports are more rational, well-supported, deeper, and more constructive than baselines, with strong alignment to human and peer-review judgments across five dimensions.
- Ablation studies confirm that grounding, personalized reviewer personas, and diverse retrieval sources (including web and code) are critical to performance, while removing them degrades results.
- InnoEval’s multi-perspective test-time scaling improves with more personas, demonstrating that authentic reviewer diversity outperforms synthetic opinion generation.
- The system’s deep knowledge search engine uniquely balances relevance, coverage, and diversity better than baseline search modules.
- InnoEval’s feedback enhances idea generation pipelines, producing more refined problem formulations, methodologies, and experimental designs than ScholarEval or vanilla baselines.
- Novelty is the strongest predictor of idea acceptance, while feasibility becomes critical for achieving highlight status, indicating the need for well-rounded evaluation.
- Dimensional correlations reveal that clarity and significance are foundational, while novelty trades off slightly with validity and feasibility, aligning with scholarly intuition.
- InnoEval demonstrates robustness across different backbone models (DeepSeek-V3.2 and o4-mini) and can recognize real-world innovation through comprehensive, multi-angle review, mitigating single-viewpoint bias.
The authors use InnoEval to evaluate scientific ideas across point-wise, pair-wise, and group-wise tasks, outperforming multiple baselines including CoT, RAG, ResearchAgent, and ScholarEval. Results show that InnoEval achieves state-of-the-art performance by leveraging multi-dimensional, multi-perspective evaluation and evidence-rich grounding, which mitigates label collapse and improves alignment with human judgments. Ablation studies confirm that components like personalized personas, diverse retrieval sources, and grounding are critical to its robustness and effectiveness.
The authors use LLM-as-judge to compare InnoEval against multiple baselines across five qualitative dimensions, finding that InnoEval consistently outperforms them in rationality, supportiveness, depth, and constructiveness. Results show that InnoEval’s multi-source search and multi-perspective evaluation yield significantly higher win rates, especially in depth and overall quality, while ScholarEval remains competitive in some dimensions but lags in constructiveness. The findings highlight that integrating diverse evidence and structured review personas enhances evaluation robustness and actionable feedback.
