Command Palette
Search for a command to run...
시각적 추론에 대해 RL은 무엇을 개선하는가? 프랑켄슈타인 스타일의 분석
시각적 추론에 대해 RL은 무엇을 개선하는가? 프랑켄슈타인 스타일의 분석
Xirui Li Ming Li Tianyi Zhou
초록
시각-언어 모델에서 시각적 추론 성능을 향상시키기 위한 표준 후처리 단계로, 검증 가능한 보상(reward)을 갖춘 강화학습(RL)이 널리 도입되고 있으나, 이 기법이 감독 미세조정(supervised fine-tuning)을 초기화 방법(IN)으로 사용했을 때 실제로 어떤 능력을 향상시키는지에 대한 명확한 이해는 여전히 부족하다. 종합적인 벤치마크 성능 향상은 여러 요인을 혼합하여 나타내므로, 성능 향상이 특정 기술에 기인하는지 정확히 파악하기 어렵다. 이러한 격차를 메우기 위해, 우리는 다음과 같은 프랭켄슈타인 스타일의 분석 프레임워크를 제안한다: (i) 인과적 탐지(causal probing)를 통한 기능적 위치 규명; (ii) 파라미터 비교를 통한 업데이트 특성 분석; (iii) 모델 병합을 통한 전이 가능성 테스트. 분석 결과, RL은 주로 중간에서 후반층에 걸쳐 일관된 추론 시점의 변화를 유도하며, 이러한 중후반층의 개선은 모델 병합을 통해 전이 가능할 뿐만 아니라, RL 성능 향상에 필수적임이 확인되었다. 종합적으로, 본 연구 결과는 RL이 시각적 인지 능력을 균일하게 향상시키는 것이 아니라, 시각에서 추론으로의 일치도를 높이고 추론 성능을 개선하는 중후반층 트랜스포머 계산의 체계적 정교화를 통해 시각적 추론 능력을 향상시킨다는 점을 시사한다. 이는 다중모달 추론 향상에 대한 이해를 위해 벤치마크 중심의 평가 방식의 한계를 강조한다.
One-sentence Summary
Xirui Li and Ming Li (University of Maryland) with Tianyi Zhou (MBZUAI) propose a Frankenstein-style framework revealing that RL for visual reasoning refines mid-to-late transformer layers—not vision perception—to improve vision-to-reasoning alignment, validated via causal probing, parameter analysis, and model merging.
Key Contributions
- RL post-training for vision-language models does not uniformly enhance visual perception but instead induces consistent, layer-specific refinements in mid-to-late transformer layers that improve vision-to-reasoning alignment.
- Using a Frankenstein-style framework combining causal probing, parameter comparison, and model merging, the study localizes RL’s functional impact and demonstrates that these mid-late layer updates are both transferable and necessary for performance gains.
- Experiments across training recipes show that freezing mid or late layers during RL training largely eliminates gains, confirming that RL’s reliable contribution lies in refining late-stage computation rather than early visual encoding or standalone reasoning.
Introduction
The authors leverage reinforcement learning (RL) to enhance visual reasoning in vision-language models (VLMs), building on the widely adopted two-stage pipeline of supervised fine-tuning followed by RL with verifiable rewards. While prior work reports benchmark gains, it remains unclear whether RL improves vision perception, reasoning, or their alignment—and end-to-end metrics obscure these distinctions. The authors’ main contribution is a Frankenstein-style analysis framework that decomposes VLMs by transformer layer, using causal probing, parameter comparison, and model merging to isolate RL’s functional impact. They find that RL consistently refines mid-to-late layers—not early vision modules—boosting vision-to-reasoning alignment and reasoning performance, with these changes being both transferable and necessary for gains. This challenges the assumption that RL uniformly improves visual capabilities and highlights the need to look beyond aggregate benchmarks.
Dataset
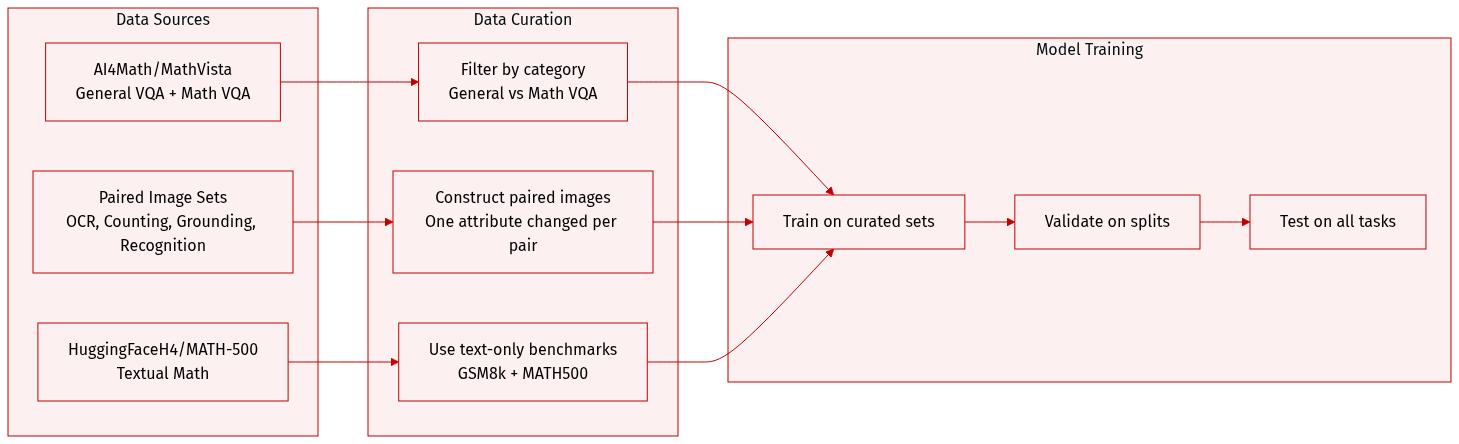
The authors use a multi-component dataset to evaluate model capabilities across vision, reasoning, and vision-to-reasoning tasks:
-
Vision (General VQA): Uses the AI4Math/MathVista testmini split filtered by metadata['category'] = 'general-vqa'. This tests broad visual question answering.
-
Vision-to-Reasoning (Math VQA): Uses the same AI4Math/MathVista testmini split but filtered by metadata['category'] = 'math-targeted-vqa'. Focuses on visual math problems requiring reasoning.
-
Reasoning (Textual Math): Uses the HuggingFaceH4/MATH-500 test split. Evaluates pure mathematical reasoning without visual input.
-
Paired Image Datasets (for functional attribution): Constructed to isolate specific visual functions by creating image pairs differing in exactly one attribute:
-
OCR: Images with different words on blank backgrounds, sampled from a deduplicated arXiv corpus. Queries ask for text content; change rate measured by text output difference.
-
Object Counting: Adapted from CLEVR. Pairs vary only in object count, with fixed appearance and background. Change rate measured by whether predicted count differs.
-
Object Grounding: Identical objects placed at different locations on clean backgrounds. Queries request bounding boxes; change measured by IoU < 0.5 between predicted and swapped ground truth.
-
Object Recognition: COCO images with target objects paired with blank canvases. Queries ask for object presence; change rate is proportion of “No” responses after token swapping.
-
-
Reasoning Benchmarks: GSM8k and MATH500 are used to assess reasoning sensitivity. These text-only benchmarks require multi-step inference and symbolic manipulation, isolating reasoning from perception.
No training splits, mixture ratios, or cropping strategies are specified in this section. Metadata is used for filtering (e.g., category tags), and paired datasets are synthetically constructed to enable causal attribution of model behavior to specific visual functions.
Method
The authors leverage a Frankenstein-style analysis framework to dissect how reinforcement learning (RL) consistently modifies visual reasoning behavior across training recipes. This framework operates at the granularity of transformer layers and is structured around three core components: functional localization via causal probing, update characterization via parameter comparison, and transferability testing via model merging. Each component is designed to isolate and validate the consistent effects of RL on specific computational regions within the model.
The first component, functional localization, identifies which transformer layers are responsible for processing visual information versus those engaged in higher-level reasoning. This is achieved through a targeted vision-token intervention strategy. For each pair of images differing in a single visual attribute—such as text in an OCR task or object count—the authors swap the visual token representations at a specific layer ℓ while preserving all other hidden states and the prompt. If the model’s prediction changes as a result, that layer is deemed functionally sensitive to the swapped attribute. The sensitivity is quantified using the change rate:
Change Rate(ℓ)=N1n=1∑NI[f(in(ℓ),pn)=f(in′(ℓ),pn)],where f(⋅) denotes the model’s predicted answer, pn is the prompt, and in(ℓ) and in′(ℓ) represent inputs with visual tokens sourced from the original and paired images, respectively. This intervention preserves architectural structure and numerical stability, ensuring that output shifts reflect genuine changes in visual evidence processing. As shown in the figure below, this method enables the authors to map distinct visual tasks—such as recognition, OCR, grounding, and counting—to specific layer regions.
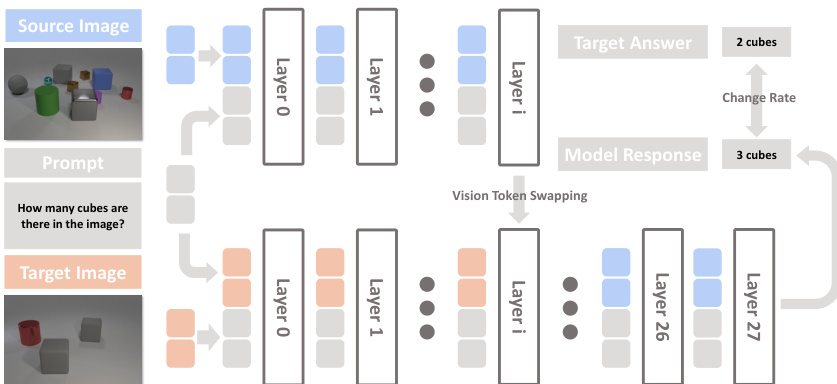
Based on these interventions, the authors partition the transformer into three functional regions: Early, Mid, and Late layers. Early layers primarily handle basic visual recognition, while Mid layers are involved in more complex visual tasks such as OCR and object counting. Late layers are associated with reasoning tasks that rely less on raw visual input and more on linguistic inference. This stratification allows the authors to decouple vision and reasoning functionalities within the VLM.
The second component characterizes how RL modifies parameter updates across these regions compared to initial training (IN). The authors compute per-layer Frobenius norms of parameter updates and observe that while both IN and RL concentrate optimization in the Mid layers, RL exhibits a distinct redistribution of update magnitude. Specifically, RL allocates more energy to the Mid layers and exhibits a steeper rank spectrum in the Early to Late layers, indicating a more structured and targeted adaptation of parameters. Refer to the framework diagram for a visual comparison of update energy and diversity between IN and RL.

The third component tests the transferability of RL-induced improvements by merging layers from IN-trained and RL-trained models. The authors construct hybrid models by combining Early, Mid, and Late layers from different training regimes and evaluate their performance. The results demonstrate that RL-induced improvements in the Mid-Late layers are transferable and consistently enhance performance across tasks, validating that RL systematically modifies these regions to improve visual reasoning. The framework diagram illustrates the merging process and the resulting performance gains.

Together, these components form a cohesive methodology for isolating, characterizing, and validating the consistent effects of RL on visual reasoning within transformer-based VLMs. The approach enables fine-grained analysis of how training dynamics reshape functional regions of the model, providing insight into the mechanisms underlying RL-driven performance gains.
Experiment
- Fine-grained analysis reveals that visual reasoning benchmarks mask inconsistent improvements: vision and reasoning abilities do not improve monotonically from Base to IN to RL models.
- RL consistently shifts inference behavior by increasing attention from reasoning tokens to visual tokens, concentrated in mid-late transformer layers.
- RL induces structured parameter updates primarily in mid-late layers, characterized by concentrated, low-diversity refinements that enhance vision-to-reasoning alignment and reasoning.
- Model merging confirms these mid-late layer refinements are transferable and sufficient to preserve gains in alignment and reasoning across training recipes.
- Freezing mid-late layers during RL training eliminates performance gains, establishing that refinement in these regions is causally necessary for RL improvements.
- Functional localization shows vision processing is anchored in early-mid layers, while reasoning computations are concentrated in late layers, providing a reference frame for interpreting RL effects.
The authors use model merging to isolate the functional impact of reinforcement learning across transformer layers, revealing that improvements in vision-to-reasoning alignment and reasoning stem primarily from refinements in mid-late layers. These gains are transferable and consistently preserved when RL-trained parameters from those layers are transplanted into other models, while early layers contribute minimally. Results show that RL does not uniformly enhance all capabilities, and its benefits are causally dependent on updates to late-stage layers rather than overall model scale or training duration.
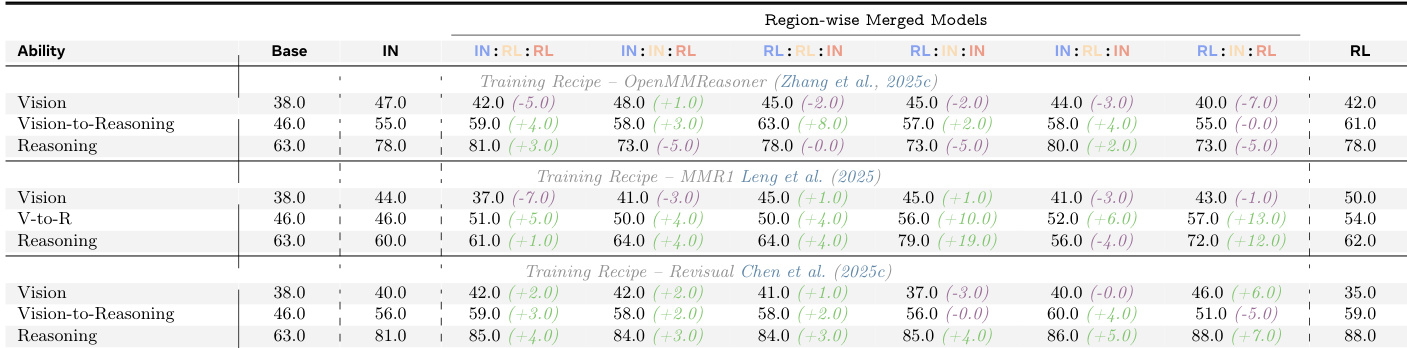
Results show that while end-to-end benchmark scores improve with RL training, fine-grained analysis reveals no consistent gains in vision or reasoning ability alone. Instead, RL consistently enhances vision-to-reasoning alignment and reasoning performance by refining mid-late transformer layers, with these improvements being both transferable and causally necessary for overall gains. Freezing late layers during RL training eliminates most benefits, confirming their critical role in mediating RL-induced improvements.
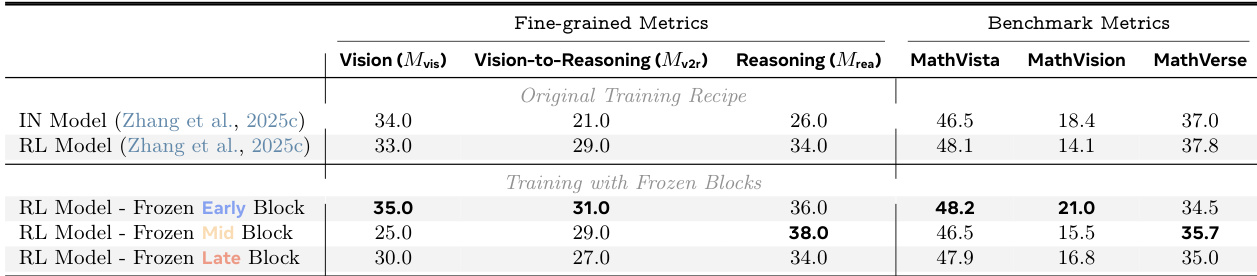
The authors use a systematic analysis across multiple training recipes to show that reinforcement learning improves visual reasoning not by enhancing vision or reasoning in isolation, but by refining how reasoning tokens attend to visual information, primarily in mid-late transformer layers. These refinements are structurally consistent, transferable through model merging, and causally necessary for performance gains, indicating that RL optimizes vision-to-reasoning alignment rather than raw perceptual or linguistic capabilities.