Command Palette
Search for a command to run...
쿼리 중심형 및 메모리 인지형 리랭커: 긴 컨텍스트 처리를 위한 접근
쿼리 중심형 및 메모리 인지형 리랭커: 긴 컨텍스트 처리를 위한 접근
Yuqing Li Jiangnan Li Mo Yu Guoxuan Ding Zheng Lin Weiping Wang Jie Zhou
초록
대규모 언어 모델 내 검색 헤드에 대한 기존 분석을 기반으로, 선택된 헤드의 어텐션 점수를 활용하여 문서-질의 관련성(Relevance)을 추정하도록 모델을 훈련시키는 대안적인 재정렬 프레임워크를 제안한다. 이 방법은 전체 후보 목록 내의 포괄적인 정보를 활용하는 리스트와이즈(listwise) 솔루션을 제공하며, 자연스럽게 연속적인 관련성 점수를 생성함으로써, 리커트 척도(Likert-scale) 감독 없이도 임의의 검색 데이터셋에서 훈련이 가능하다. 제안하는 프레임워크는 가볍고 효과적이며, 단지 소규모 모델(예: 4B 파라미터)만으로도 뛰어난 성능을 달성할 수 있다. 광범위한 실험을 통해 본 연구 방법은 위키백과 및 긴 서사형 데이터셋을 포함한 여러 도메인에서 기존 최고 수준의 포인트와이즈(pointwise) 및 리스트와이즈 재정렬 모델들을 모두 능가함을 입증하였다. 또한, 대화 이해 및 메모리 사용 능력을 평가하는 LoCoMo 벤치마크에서 새로운 최고 성능을 수립하였다. 더 나아가 본 프레임워크가 유연한 확장이 가능함을 보여주었다. 예를 들어, 후보 문서에 맥락 정보를 추가하면 정렬 정확도가 더욱 향상되며, 중간 계층의 어텐션 헤드를 훈련시키는 방식은 성능을 희생하지 않으면서도 효율성을 높이는 데 기여한다.
One-sentence Summary
Researchers from CAS, UCAS, and Tencent propose a lightweight reranking framework using attention scores from selected LLM heads to estimate passage-query relevance, enabling listwise ranking with continuous scores and outperforming SOTA on Wikipedia, narrative, and dialogue benchmarks like LoCoMo.
Key Contributions
- We introduce QRRanker, a listwise reranking framework that trains LLMs to estimate passage-query relevance via attention scores of selected retrieval heads, enabling continuous scoring without requiring Likert-scale supervision and leveraging holistic context from the entire candidate shortlist.
- Our method achieves strong performance using small-scale models (e.g., 4B parameters), and supports efficient extensions such as prepending shared context to candidates or training middle-layer heads—maintaining accuracy while reducing inference latency.
- Experiments show QRRanker outperforms state-of-the-art pointwise and listwise rerankers across Wikipedia, long narrative, and dialogue datasets, setting a new benchmark on LoCoMo for dialogue memory and understanding.
Introduction
The authors leverage attention heads in large language models that naturally exhibit retrieval behavior—specifically Query-focused Retrieval (QR) heads—to build a lightweight, listwise reranker called QRRanker. While prior rerankers either rely on pointwise scoring (losing global context) or listwise generation (requiring Likert-scale labels and suffering from unstable outputs), QRRanker trains QR heads to output continuous relevance scores directly from attention weights, enabling training on any retrieval dataset without format constraints. It supports efficient inference by using smaller backbones (e.g., 4B parameters), allows optional global context injection via prepended summaries, and remains robust when trained on mid-layer heads—enabling further latency reduction by pruning top layers. Evaluated across long-context QA and dialogue tasks, QRRanker outperforms both general-purpose and domain-specific rerankers while maintaining practical efficiency.
Dataset

- The authors use a unified training set built by combining MuSiQue (Trivedi et al., 2022) and NarrativeQA (Kočiský et al., 2018), each contributing question-evidence pairs.
- For MuSiQue, they directly use the official supporting facts as gold evidence; for NarrativeQA, they construct silver evidence chunks following Li et al. (2025a) since no gold chunks are provided.
- For each question, they retrieve a top-50 candidate set using Qwen3-Embedding-8B and form listwise training instances: candidates matching pre-constructed evidence are labeled positive, others negative.
- Optionally, they prepend a summary prefix (M) to the candidate chunks (C), forming input as X = [M; C], where summaries are mapped from retrieved chunks—this enhances context awareness in the model.
- The same evidence and chunk construction procedure applies to both datasets, with NarrativeQA’s process detailed in Algorithm 1.
- The model, QRRanker, uses this structured input to score documents via dedicated QR heads, supporting a rank-rerank pipeline for narratives, dialogues, and wiki content without complex design.
Method
The authors leverage a listwise reranking framework called QRRanker, which operates by extracting and aggregating attention scores from a predefined set of retrieval-focused attention heads—termed QR heads—within a large language model. This method avoids autoregressive generation and instead relies solely on the prefill phase of the model to compute relevance scores, making it computationally efficient. The core idea is to treat the reranking task as a contrastive learning problem over the entire candidate list, enabling the model to learn holistic ranking signals from the full context of retrieved documents.
The framework begins with the construction of listwise training instances. For each question, the authors retrieve a top-K list of candidate documents (typically K=50) using an initial retriever such as Qwen3-Embedding. Gold documents are identified via SILVEREVIDENCE, and each candidate is labeled as positive or negative. Optionally, memory-enhanced context—such as summaries—is prepended to the document list to provide coarse-grained semantic guidance. Two summary construction strategies are employed: block-based summaries for narrative texts, which group consecutive chunks into blocks and generate one summary per block, and event-centric summaries for dialogue data, which extract structured events linked to source utterances for traceability. Refer to the framework diagram for a visual breakdown of how these memory components are integrated into the pipeline.
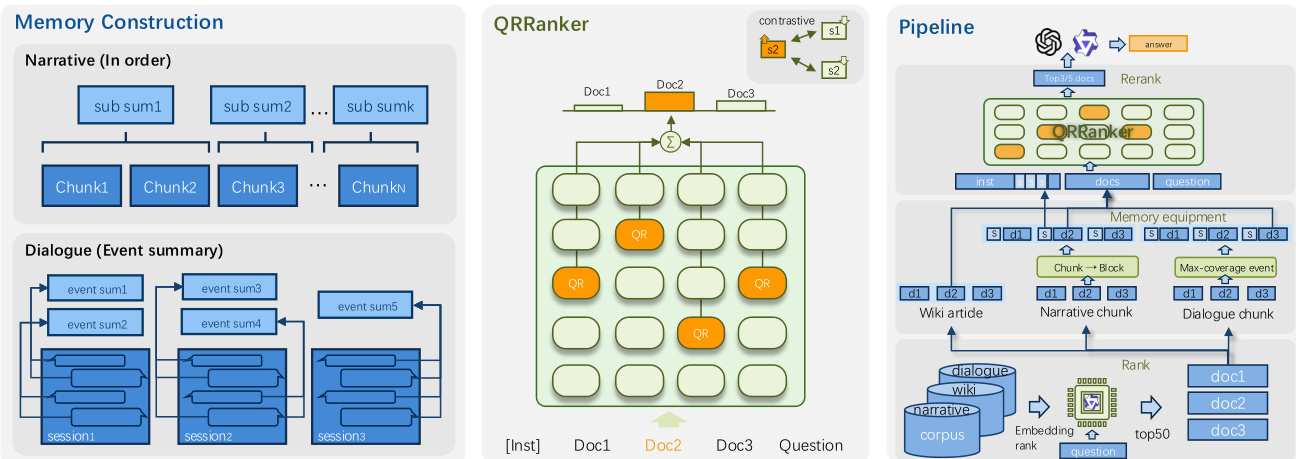
The QRRanker model itself is built upon a preselected set of QR heads, identified via QR scores computed on a seed dataset (e.g., 1000 samples from NarrativeQA). These heads are selected from the Qwen3-4B-Instruct-2507 model, which contains 36 layers of 32-head self-attention; the top 16 heads by QR score are retained for reranking. During inference, the model receives a prompt composed of an instruction, the candidate documents, and the question. For each QR head h, the attention matrix AhQ→ci is extracted between the question tokens and each candidate chunk ci. The retrieval score for chunk ci under head h is computed as:
scih=∣Q∣1i∈ci∑j∈Q∑AhQ→ci[i,j],where the summation aggregates attention weights across all token pairs between the question and the chunk. As shown in the figure below, this involves averaging attention scores along the question dimension for each document, then summing across all QR heads to produce the final score sci=∑h∈HQRscih.
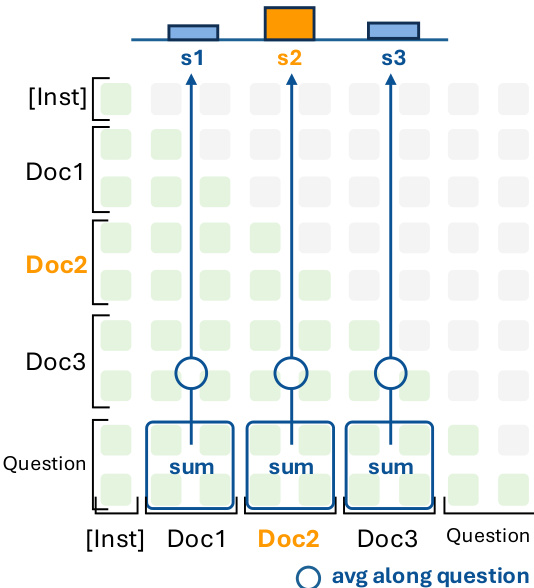
Training proceeds by optimizing these scores using a group contrastive loss. Unlike conventional contrastive loss that samples one positive per batch, this variant accounts for multiple positive documents within the top-K list by averaging the loss over all positives:
Lsample=∣G∣1cp∈G∑logτ(scp)+∑cn∈C∖Gτ(scn)τ(scp),where τ denotes the exponential function. To stabilize training, scores are normalized using max-min scaling to a fixed range [0, scale], mitigating instability caused by attention sink effects or instruction-induced biases. The model is trained end-to-end to refine the QR heads’ ability to discriminate relevant from irrelevant documents, with optional memory prefixes incorporated during training to enhance contextual awareness.
A variant of the framework introduces semi-automatic head selection, where instead of using a static set of QR heads, a router mechanism dynamically selects 16 heads per sample from a predefined layer range. This is implemented via a gate network that computes head scores based on hidden states of a repeated question token sequence, followed by softmax and top-k selection. The selected heads contribute to the final score weighted by their gate scores, enabling gradient flow and adaptive head selection during training.
Experiment
- QRRanker consistently outperforms embedding-only and strong reranking baselines across Wikipedia multi-hop QA, long-context story QA, and dialogue memory tasks, establishing new state-of-the-art recall performance.
- It significantly improves downstream QA accuracy by selecting evidence better aligned with reasoning needs, particularly in narrative and detective story benchmarks.
- On dialogue memory (LoCoMo), QRRanker achieves top F1 scores using only minimal context (top-3 chunks), outperforming memory-augmented frameworks that require larger input budgets or complex memory structures.
- Adding a summary prefix enhances performance in long-context dialogue and story tasks but offers no benefit—and may degrade results—in Wikipedia QA, where evidence is highly localized.
- Middle-to-top model layers yield optimal performance; training with middle-layer heads (17–24) matches full-model performance, enabling efficient truncation without sacrificing accuracy.
- QRRanker offers superior inference efficiency—lower latency, compute, and memory—compared to baselines, with a truncated middle-layer variant providing further speed and cost advantages.
The authors use QRRanker to rerank retrieval candidates and find it achieves lower latency and reduced compute and memory usage compared to Qwen3-Reranker-4B under equivalent settings. Truncating the model after middle layers further improves efficiency, delivering the fastest response times and lowest resource consumption. Results show QRRanker provides a better performance-to-cost trade-off, especially in its lightweight middle-layer variant.

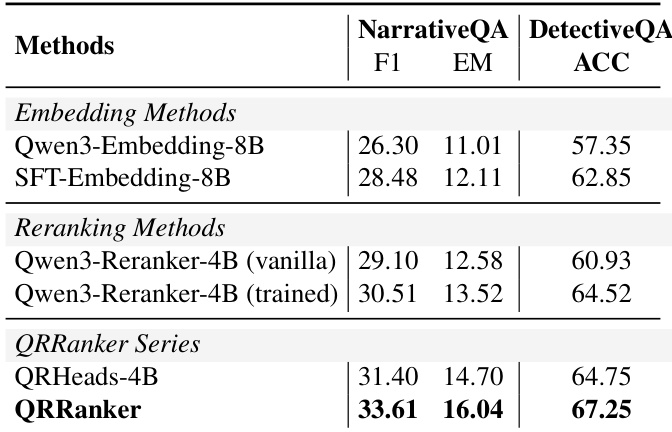
The authors use QRRanker to rerank retrieved passages for long-context story QA tasks and observe consistent improvements over both embedding-only and trained reranker baselines. Results show that QRRanker achieves the highest F1 and exact match scores on NarrativeQA and the highest accuracy on DetectiveQA, indicating its effectiveness in selecting context that better supports downstream answer generation. This performance gain holds even when using only a small number of top-ranked chunks as input, highlighting its efficiency and alignment with reasoning needs.
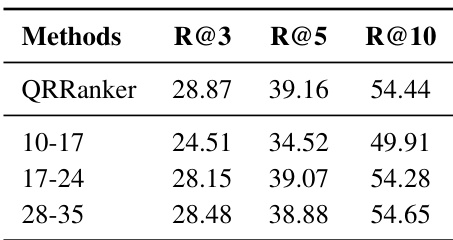
The authors evaluate QRRanker variants using heads from different transformer layers and find that models trained with middle (17-24) or top (28-35) layers achieve comparable retrieval performance, while lower layers (10-17) significantly underperform. This suggests that middle-to-top layers are more suitable for retrieval tasks, and the method can effectively activate retrieval potential even in non-specialized heads from these layers.
The authors use QRRanker to evaluate retrieval performance with and without a summary prefix across multiple long-context benchmarks. Results show that adding the summary prefix improves Recall@3 on LoCoMo, NarrativeQA, and DetectiveQA, but offers no benefit or slightly degrades performance on Wikipedia-based datasets like HotpotQA and Musique. This suggests that global summaries enhance retrieval in dialogue and story contexts but are less effective when evidence is localized in factual passages.

The authors use QRRanker to rerank top-50 candidates across multiple QA and dialogue benchmarks, showing consistent gains over embedding-only and existing reranking methods. Results show it outperforms larger models like GroupRank-32B and specialized systems like HippoRAG, particularly in long-context and multi-hop settings. Its effectiveness extends to downstream generation tasks, indicating strong alignment between retrieved evidence and reasoning needs.
