Command Palette
Search for a command to run...
DreamID-Omni: 제어 가능한 인간 중심의 오디오-비디오 생성을 위한 통합 프레임워크
DreamID-Omni: 제어 가능한 인간 중심의 오디오-비디오 생성을 위한 통합 프레임워크
Xu Guo Fulong Ye Qichao Sun Liyang Chen Bingchuan Li Pengze Zhang Jiawei Liu Songtao Zhao Qian He Xiangwang Hou
초록
최근 기초 모델(Basis Model)의 발전은 음성-영상 공동 생성 분야에 혁신을 가져왔다. 그러나 기존의 접근 방식은 참조 기반 음성-영상 생성(R2AV), 영상 편집(RV2AV), 음성 주도 영상 애니메이션(RA2V) 등 인간 중심의 작업들을 각각 독립된 목표로 다루는 경향이 있다. 더불어, 단일 프레임워크 내에서 여러 인물의 정체성과 음성 톤을 정밀하고 분리된 방식으로 제어하는 것은 여전히 해결되지 않은 과제이다. 본 논문에서는 제어 가능한 인간 중심 음성-영상 생성을 위한 통합적 프레임워크인 DreamID-Omni를 제안한다. 구체적으로, 비동질적인 조건 입력 신호를 대칭적 조건 주입 방식으로 통합하는 대칭적 조건부 확산 트랜스포머(Symmetric Conditional Diffusion Transformer)를 설계하였다. 다수 인물이 등장하는 상황에서 흔히 발생하는 정체성-음성 톤의 결합 오류 및 화자 혼동 문제를 해결하기 위해, 신호 수준에서의 동기화된 RoPE(Synchronized RoPE)와 의미 수준에서의 구조화된 캡션(Structured Captions)을 활용한 이중 수준 분리 전략(Dual-Level Disentanglement)을 도입하였다. 이는 주의 공간 내에서 강한 결합을 보장하고, 속성과 주제 간의 명시적 맵핑을 형성함으로써 정확한 제어를 가능하게 한다. 또한, 강한 제약 조건을 가진 작업을 정규화하고 과적합을 방지하며, 서로 다른 목적 간의 조화를 이루기 위해 약한 제약을 가진 생성 사전 지식을 활용하는 다중 작업 점진적 학습(Multi-Task Progressive Training) 전략을 제안한다. 광범위한 실험을 통해 DreamID-Omni가 영상, 음성, 음성-영상 일관성 측면에서 종합적으로 최고 수준의 성능을 달성함을 입증하였으며, 일부 측면에서는 선도적인 상용 모델들보다도 우수한 성능을 보였다. 본 연구의 코드는 학계 연구와 상용 수준 응용 간 격차를 좁히기 위해 공개될 예정이다.
One-sentence Summary
Researchers from Tsinghua University and ByteDance’s Intelligent Creation Lab propose DreamID-Omni, a unified framework using a Symmetric Conditional Diffusion Transformer and Dual-Level Disentanglement to enable precise, multi-character audio-video generation, outperforming commercial models while advancing academic-commercial alignment.
Key Contributions
- DreamID-Omni introduces a unified Symmetric Conditional Diffusion Transformer framework that jointly supports reference-based audio-video generation, video editing, and audio-driven animation, overcoming the fragmentation of prior task-specific approaches.
- To address identity-timbre binding failures in multi-person scenes, it employs a Dual-Level Disentanglement strategy using Synchronized RoPE for signal-level alignment and Structured Captions for semantic-level attribute mapping.
- Through a Multi-Task Progressive Training scheme that gradually introduces constrained tasks, DreamID-Omni achieves state-of-the-art performance across video, audio, and audio-visual consistency, surpassing leading proprietary models.
Introduction
The authors leverage recent advances in diffusion-based audio-video generation to tackle the fragmentation of human-centric tasks—reference-based generation, video editing, and audio-driven animation—which have previously been handled by isolated models. Prior work struggles with identity-timbre binding in multi-person scenes and lacks unified architectures that can flexibly switch between tasks without architectural changes. DreamID-Omni introduces a Symmetric Conditional Diffusion Transformer that fuses heterogeneous inputs like reference images, voice timbres, and driving audio into a shared latent space, enabling seamless task switching. To resolve speaker confusion, it employs Dual-Level Disentanglement: Syn-RoPE for rigid signal-level binding and Structured Captions for explicit semantic mapping. A Multi-Task Progressive Training strategy further harmonizes weakly and strongly constrained objectives, preventing overfitting while maintaining high fidelity across video, audio, and cross-modal consistency—even outperforming leading commercial models.
Dataset
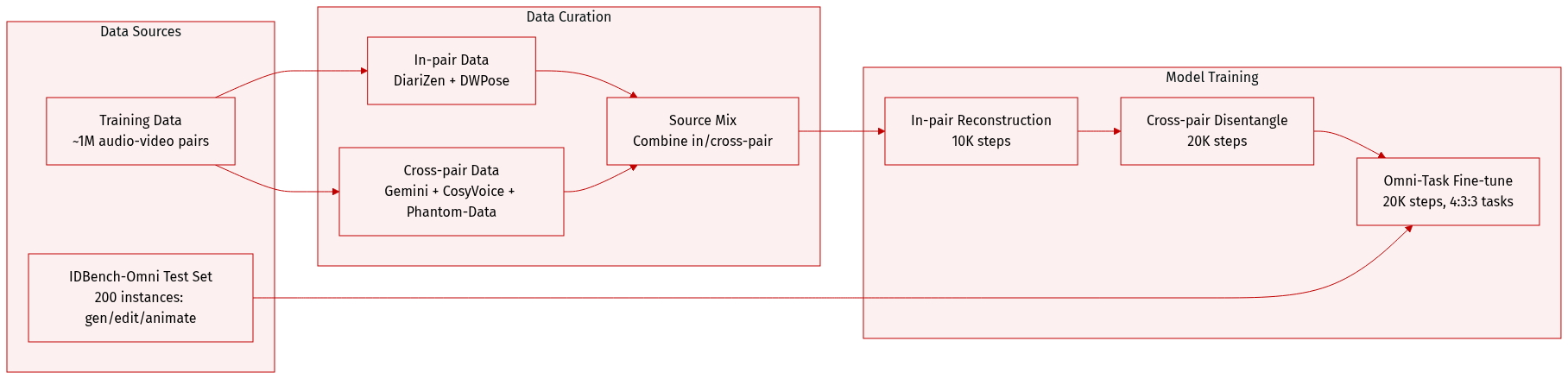
-
The authors use IDBench-Omni, a new benchmark with 200 high-quality test instances split into three subsets: 100 identity-timbre-caption triplets for generation, 50 masked videos for controlled editing, and 50 driving audios for audio-driven animation — all designed to stress-test multi-person, in-the-wild, and cross-modal control scenarios.
-
For training, they draw from a dataset of ~1M audio-video pairs, constructed in two stages: In-pair data uses DiariZen for speaker diarization to extract timbre references and DWPose to crop face regions for identity references; Cross-pair data leverages DiariZen and Gemini to label multi-speaker segments, then uses CosyVoice and ClearerVoice to generate clean cloned voices, while video identities follow the Phantom-Data pipeline.
-
Training begins with In-pair Reconstruction (10K steps), followed by Cross-pair Disentanglement and Omni-Task Fine-tuning (20K steps each). In the final stage, data is sampled in a 4:3:3 ratio for R2AV, RV2AV, and RA2V tasks, with a global batch size of 32 and learning rate of 1e-5.
-
Evaluation metrics span video (AES, ViCLIP text-video similarity, ArcFace ID-Sim), audio (AudioBox-Aesthetics PQ, CLAP semantic consistency, Whisper WER, WavLM T-Sim), and audio-visual sync (SyncNet Sync-C/D). Speaker Confusion in multi-person scenes is judged by Gemini-2.5-Pro using a structured prompt.
Method
The authors leverage a unified probabilistic framework to model the conditional generation of synchronized video-audio streams, given a text prompt T, reference identities I, and reference voice timbres A. To support flexible task switching between reference-based generation (R2AV), editing (RV2AV), and animation (RA2V), the framework optionally incorporates a source video context Vsrc and a driving audio stream Adri, modeling the joint distribution P(Y∣T,I,A,Vsrc,Adri). This conditional structure enables seamless transitions between tasks by toggling the presence of structural inputs, as summarized in the accompanying task unification table.
Refer to the framework diagram, which illustrates the core architecture of DreamID-Omni: a dual-stream Diffusion Transformer (DiT) with symmetric conditioning and bidirectional cross-attention. The video and audio streams operate in parallel, each processing their respective latent representations through a series of DiT blocks. These blocks are interconnected via cross-attention layers that enforce fine-grained temporal synchronization and semantic alignment between modalities. The architecture is designed to handle heterogeneous inputs—identity references, structural contexts, and text prompts—through a unified latent space.
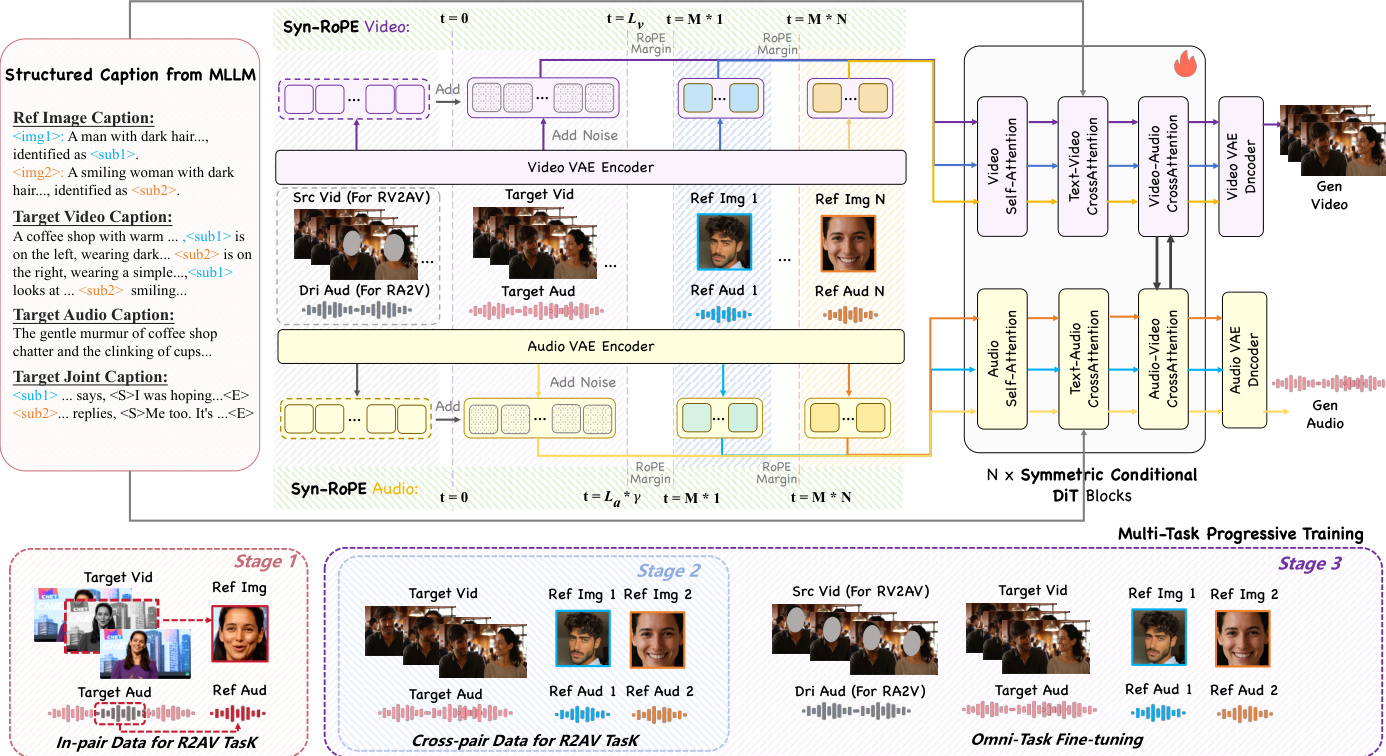
A key innovation is the Symmetric Conditional DiT, which composes conditioning signals with structural parity. Let zv and za denote the noisy target video and audio latents. The model constructs two conditional sequences, Xv and Xa, by concatenating reference features with the noisy latents and adding structural context via element-wise operations:
Xv=[zv;Ev(I)]+[Ev(Vsrc);0Ev(I)]Xa=[za;Ea(A)]+[Ea(Adri);0Ea(A)]This dual-injection strategy decouples identity preservation from structural guidance, allowing the model to adaptively switch between tasks without architectural changes. When structural inputs are absent, the additive term vanishes, effectively reverting to R2AV mode.
To address identity-timbre entanglement in multi-person scenarios, the authors introduce a Dual-Level Disentanglement strategy. At the signal level, Syn-RoPE assigns distinct temporal positional segments to each reference identity within the attention space. The target video and audio latents occupy the initial range [0,L−1], while each identity k is allocated a reserved segment [k⋅M,(k+1)⋅M−1], where M≫L. This design ensures inter-identity decoupling via rotational subspace separation and intra-identity synchronization by mapping visual and acoustic features of the same identity to identical positional slots. At the semantic level, Structured Captioning binds each reference identity Ik to a unique anchor token ⟨subk⟩, which is consistently used across video, audio, and joint caption fields to resolve attribute-content misattribution.
Training proceeds via a Multi-Task Progressive Strategy across three stages. Stage 1, In-pair Reconstruction, trains the model on R2AV using masked reconstruction loss to prevent copying and encourage synthesis. The loss is computed only on unmasked regions of the latents, defined as:
Linpair=Ez,t,C[λv∥(1−Mv)⊙(ϵv−e^θ(zv,t,t,C))∥22+λa∥(1−Ma)⊙(ϵa−e^θ(za,t,t,C))∥22]Stage 2, Cross-pair Disentanglement, sources identity and timbre references from different clips to enforce abstract concept learning, with loss computed over the full stream by nullifying masks. Stage 3, Omni-Task Fine-tuning, unifies all tasks by training on a mixed dataset of R2AV, RV2AV, and RA2V samples, enabling the model to switch modes based on input conditions.
At inference, the authors apply a multi-condition Classifier-Free Guidance strategy independently to each stream, using a chained formulation to ensure identity and timbre guidance operate on a text-aligned basis:
ϵ^final=ϵ^θ(zt,∅,∅)+wT⋅(ϵ^θ(zt,T,∅)−ϵ^θ(zt,∅,∅))+wS⋅(ϵ^θ(zt,T,S)−ϵ^θ(zt,T,∅))where S is I for video and A for audio, and wT, wS are guidance scales. This ensures stable, coherent generation across all modalities.
Experiment
- Validates superior performance across R2AV, RV2AV, and RA2V tasks, outperforming or matching SOTA methods in video, audio, and cross-modal consistency.
- Demonstrates accurate identity-timbre binding and speaker attribution, especially in multi-person dialogues, where baselines suffer from mismatch and misattribution.
- Ablation studies confirm dual-level disentanglement (Structured Caption + Syn-RoPE) is critical for preserving speaker identity, timbre, and textual alignment.
- Multi-task progressive training proves essential: starting with weakly constrained tasks (R2AV) before introducing stricter ones (RV2AV/RA2V) prevents overfitting and improves generalization.
- Qualitative results and user studies consistently show higher visual quality, better text-following, and stronger audio-visual synchronization compared to baselines.
The authors compare their method with several state-of-the-art baselines on audio-visual generation tasks, showing that their approach achieves leading or competitive scores across video quality, identity preservation, and audio-visual alignment metrics. Results indicate superior performance in binding specific speakers to their timbres and maintaining lip-sync accuracy, particularly in multi-person scenarios where competing methods often misattribute speech. Ablation studies further confirm that their dual-level disentanglement and progressive training strategies are critical for handling complex, structured generation tasks without introducing speaker confusion or identity-timbre mismatches.

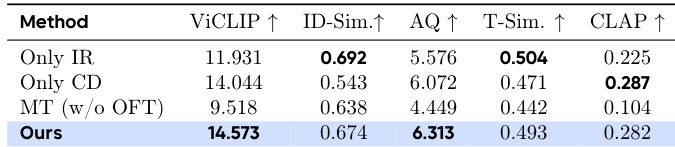
The authors evaluate ablation variants of their model on key generation metrics, showing that their full method achieves the highest ViCLIP and AQ scores while maintaining competitive performance on identity and timbre similarity. Removing progressive training or disentanglement components leads to degraded text adherence and audio-visual coherence, confirming the necessity of their multi-stage design. Results indicate that joint training without task progression or structured captioning significantly harms speaker attribution and instruction following.
The authors compare their method with leading video editing models on the RV2AV task, showing that their approach achieves state-of-the-art performance on video quality and identity preservation metrics while also generating high-quality synchronized audio. Results indicate superior audio-visual alignment and text-following capability compared to baselines that lack audio generation support.

The authors evaluate their method against ablated variants on multi-person dialogue scenarios, showing that removing Syn-RoPE or structured captions degrades timbre binding and speaker identity consistency. Their full model achieves the highest scores across visual, audio, and synchronization metrics while minimizing speaker confusion. Results confirm that both components are critical for accurate multi-speaker audio-visual generation.

The authors compare their method against several baselines on the R2AV task using human evaluation scores across multiple dimensions. Results show their approach achieves the highest scores in text-video alignment, identity similarity, video quality, text-audio alignment, timbre similarity, audio quality, and lip-sync accuracy, outperforming all compared methods. This indicates superior overall performance in generating coherent, identity-consistent, and multimodally aligned audio-visual content.
