Command Palette
Search for a command to run...
줌(zoom) 없이 줌(zoom)하기: 세부적인 다중모달 인지 위한 영역-이미지 디스틸레이션
줌(zoom) 없이 줌(zoom)하기: 세부적인 다중모달 인지 위한 영역-이미지 디스틸레이션
초록
다중모달 대규모 언어 모델(Multimodal Large Language Models, MLLMs)은 광범위한 시각적 이해 능력에서 뛰어나지만, 결정적 증거가 미세하고 전반적인 맥락에 쉽게 휩쓸릴 수 있는 세부 인지(task)에서는 여전히 어려움을 겪는다. 최근의 ‘이미지와 함께 생각하기(Thinking-with-Images)’ 기법은 추론 과정에서 관심 영역을 반복적으로 확대 및 축소함으로써 이러한 문제를 완화하고 있으나, 반복적인 도구 호출과 시각적 재인코딩으로 인해 높은 지연(latency)을 초래한다. 이를 해결하기 위해 우리는 ‘영역에서 이미지로의 정련(Region-to-Image Distillation)’을 제안한다. 이 기법은 확대 기능을 추론 시점의 도구가 아니라 훈련 시점의 기본 원리로 전환함으로써, 에이전트 기반 확대의 이점을 단일 전방 전파(forward pass) 내에 내재화한다. 구체적으로, 강력한 교사 모델이 고해상도의 미세 자르기 영역을 확대하여 고품질의 VQA 데이터를 생성한 후, 이 영역 기반의 지도 정보를 전체 이미지로 다시 정련한다. 이러한 데이터를 기반으로 훈련된 소형 학습자 모델은 도구 사용 없이도 ‘한 번의 시선’으로도 세부 인지 능력을 향상시킬 수 있다. 이러한 능력을 철저히 평가하기 위해, 세부 인지의 여섯 가지 차원을 아우르는 총 845개의 VQA 데이터로 구성된 하이브리드 애너테이션 기반 벤치마크인 ZoomBench를 제시하며, 전역과 지역 간 ‘확대 갭(zooming gap)’을 정량화하는 이중 시점(dual-view) 평가 프로토콜도 함께 제공한다. 실험 결과, 제안 모델은 여러 세부 인지 벤치마크에서 최상의 성능을 달성하였으며, 시각적 추론과 GUI 에이전트와 같은 일반적인 다중모달 인지 과제에서도 성능 향상을 보였다. 또한, ‘이미지와 함께 생각하기’가 언제 필수적인지, 그리고 그 성능 향상이 단일 전방 전파로 정련될 수 있는지에 대해 논의한다. 본 연구의 코드는 https://github.com/inclusionAI/Zooming-without-Zooming 에서 공개되어 있다.
One-sentence Summary
Researchers from Shanghai Jiao Tong University, Ant Group, and collaborators propose Region-to-Image Distillation, enabling MLLMs to internalize fine-grained perception during training—replacing costly iterative zooming with single-pass inference—validated on ZoomBench and boosting performance across multimodal tasks without runtime tools.
Key Contributions
- We introduce Region-to-Image Distillation, a training method that uses micro-cropped regions to generate high-quality, region-grounded VQA supervision for full-image models, enabling single-pass fine-grained perception without inference-time tool use or re-encoding.
- We present ZoomBench, a hybrid-annotated benchmark of 845 VQA samples spanning six fine-grained perceptual dimensions, paired with a dual-view protocol to quantify the global-regional “zooming gap” and evaluate model acuity rigorously.
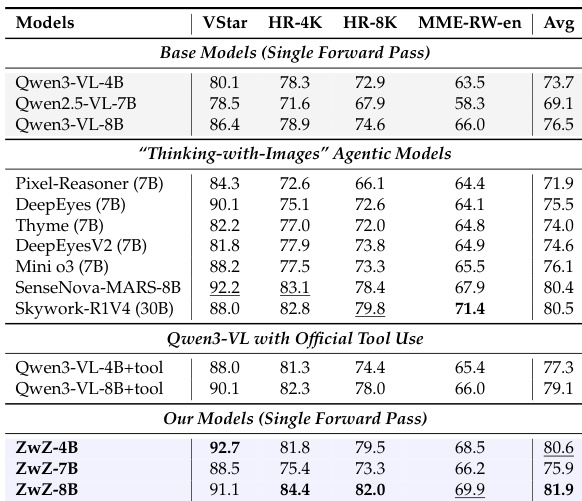
- Experiments show our distilled models (ZwZ-4B/7B/8B) achieve state-of-the-art performance on fine-grained perception tasks, outperforming larger MLLMs and agentic “Thinking-with-Images” methods while improving general multimodal cognition across visual reasoning and GUI agent benchmarks.
Introduction
The authors leverage Region-to-Image Distillation to address the persistent challenge in multimodal large language models (MLLMs) of detecting fine-grained visual details—like tiny text or subtle attributes—where global context drowns out critical micro-evidence. Prior methods, such as “Thinking-with-Images,” rely on iterative, tool-based zooming during inference, which improves accuracy but introduces high latency due to repeated visual re-encoding and tool calls. The authors’ key contribution is reframing zooming as a training-time operation: they generate high-quality VQA data from micro-cropped regions using strong teacher models, then distill that region-grounded supervision back into smaller student models trained on full images, enabling single-pass fine-grained perception at inference without tool use. They also introduce ZoomBench, a hybrid-annotated benchmark with a dual-view protocol to quantify the global-regional “zooming gap,” and show their models outperform larger MLLMs and agentic baselines while maintaining low latency.
Dataset
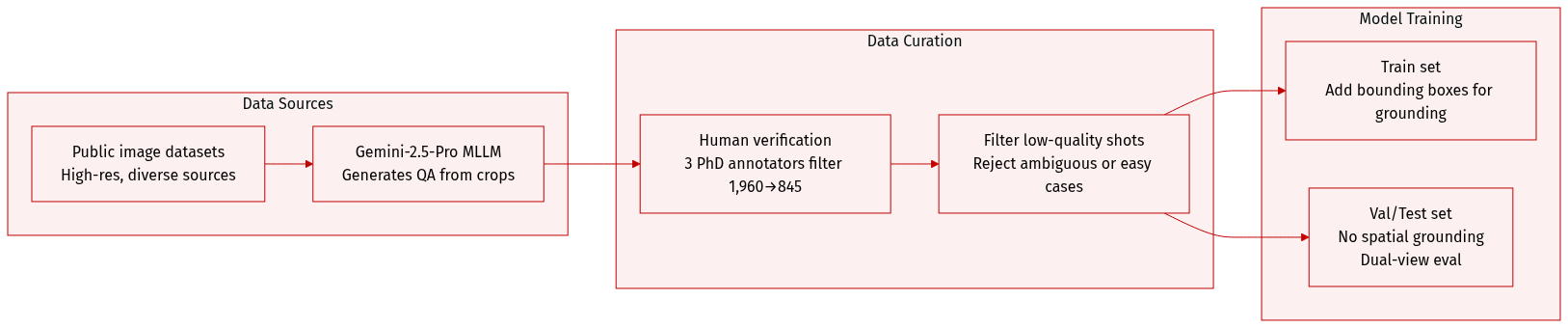
- The authors construct ZoomBench using a Region-to-Image Distillation method: a powerful MLLM (Gemini-2.5-Pro) generates questions and candidate answers from cropped micro-regions, then maps them to full images to form spatially ungrounded but evidence-backed QA pairs.
- ZoomBench contains 845 high-quality, diverse, and challenging QA pairs drawn from high-resolution images sourced across multiple public datasets (detailed in appendices), with no overlap between training and benchmark splits to prevent data leakage.
- Each instance includes a full image and a small-ratio cropped region (typically <10% of image area) that serves as visual evidence; this dual-view setup enables evaluation of “zooming” ability and attention-based interpretation.
- Human verification is applied: three PhD-level annotators validate each QA pair for clarity, answerability, and correctness against both full and cropped views; ~1,960 raw samples are filtered down to 845, removing overly easy or ambiguous cases.
- The benchmark covers six fine-grained perception dimensions: Fine-Grained Counting, OCR, Color Attributes, Structural Attributes, Material Attributes, and Object Identification.
- Evaluation includes 224 open-ended questions with canonical answers and 621 multiple-choice questions; scoring follows a hybrid protocol detailed in Appendix 9.3.
- For training data, the authors introduce explicit visual grounding (bounding boxes) to resolve ambiguity observed in cropped views, unlike the benchmark which intentionally omits spatial grounding to test model robustness.
- Core generation rules require image-based, concise, factual answers; encourage diversity in question types (counting, OCR, structure, material, etc.); and reject low-quality images by returning empty lists.
Method
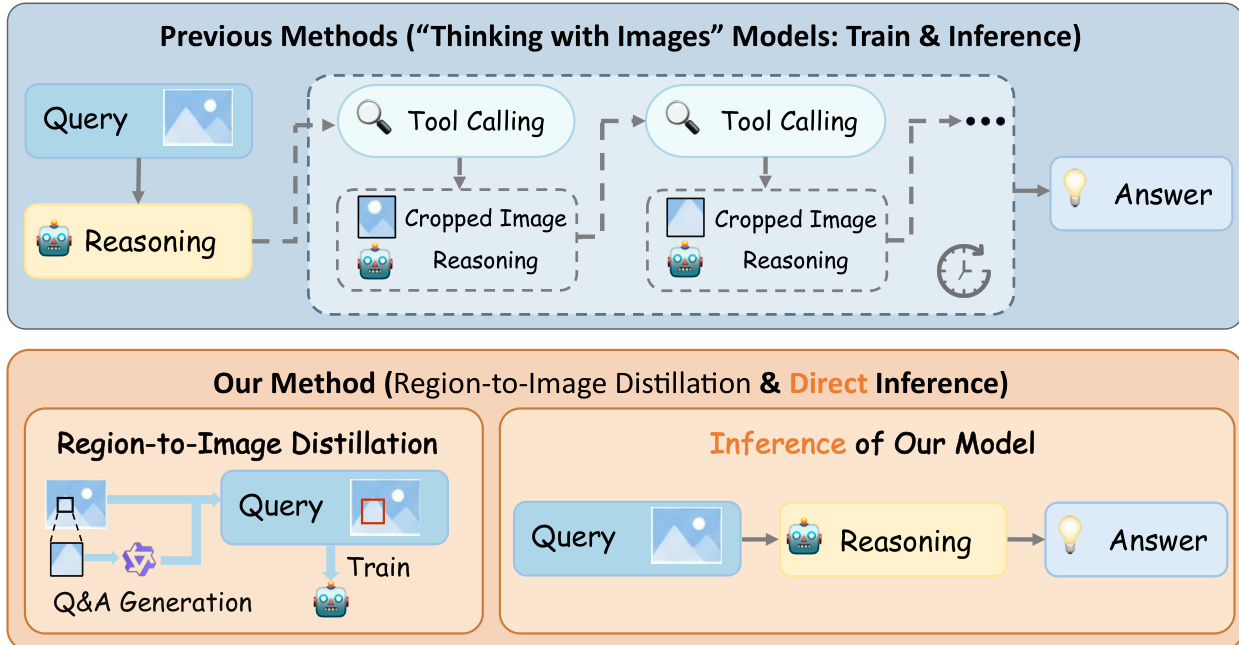
The authors leverage Region-to-Image Distillation (R2I) to synthesize high-veracity, fine-grained VQA training data from unlabeled image corpora, enabling single-pass inference without test-time tool use. The core idea is to distill regional-view expertise from strong teacher models into a student model’s global-view predictions, thereby internalizing the benefits of “zooming in” during training while preserving inference efficiency.
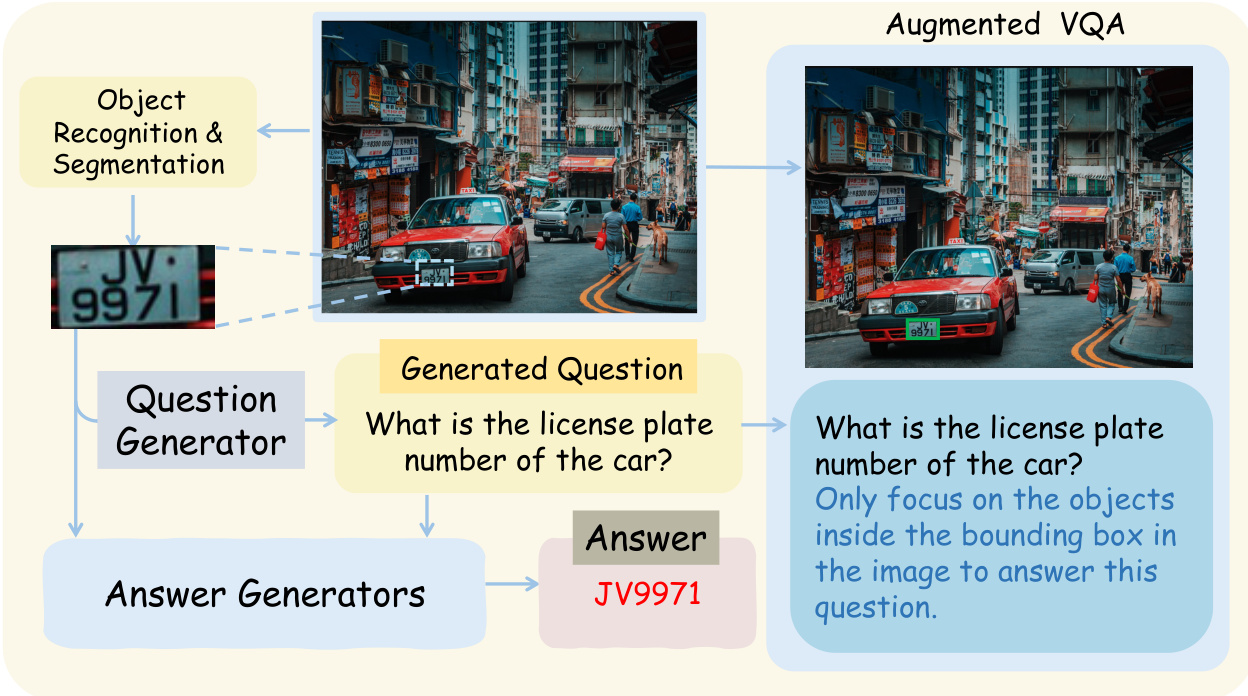
The pipeline begins with object-centric region proposal. Given a raw image I, an object recognition and segmentation system generates candidate bounding boxes {B1,…,Bn}, each covering at least one visible object. To target fine-grained perception, only micro-regions Ri satisfying Area(Bi)/Area(I)<τ (e.g., τ=0.1) are retained, ensuring the decisive visual evidence is sparse and easily overlooked in the global view. For each such region R, a teacher model generates perception-centric questions QR that are strictly answerable from R alone—focusing on subtle cues like tiny text, symbols, or small-instance counts.
To ensure label veracity without manual annotation, multiple teacher models independently answer each question Q∈QR on the cropped region R. The authors employ majority voting across teacher responses; only triplets (R,Q,A) with high consensus (e.g., >6/8 agreement) are retained, substantially reducing hallucinated or invalid samples.
Refer to the framework diagram: the distillation phase maps these region-level QA pairs back to the full image. A grounding transformation G(I,Q,B) overlays the bounding box B onto the original image I to form I′, and appends a spatial constraint to Q to form Q′. This yields an augmented training triplet (I′,Q′,A), where I′ and Q′ jointly anchor the question to the intended micro-region, resolving referential ambiguity that arises when the question is viewed in the global context. The authors further filter the synthetic dataset using a smaller multimodal model to remove overly easy samples, producing the final distilled dataset Dsyn.
The student model is then trained to maximize the expected task reward over this synthetic data:
θmaxE(I′,Q′,A)∼Dsyn,A∼πθ(⋅∣I′,Q′)[r(A,A)],where πθ is the student policy and r(A,A) is a task-specific reward function. During inference, the bounding box is removed, but the model retains the ability to attend to the critical micro-region due to the structural hint provided during training. This aligns with the privileged information paradigm: the model learns P(A∣I,Q,B) during training, and generalizes to P(A∣I,Q) at test time.
As shown in the figure below, the overall architecture contrasts with prior “Thinking with Images” methods that require iterative tool calls at inference. R2I decouples the tool-use phase (zoom-in synthesis) from inference, enabling direct, single-pass reasoning on the full image. The authors formalize this as a tool-action distillation framework: a tool-call action f(⋅) (e.g., zoom-in) generates an altered observation I, from which a teacher synthesizes (Q,A); an inverse transformation f−1 maps (I,Q) back to (I,Q), yielding a distilled dataset that trains the student to solve the task directly from the full image.
The authors instantiate this framework using Qwen3-VL-235B for region proposal and question generation, and Qwen3-VL-235B and GLM-4.5V as answer generators. They curate a high-resolution image pool from SA-1B, LAION, MetaCLIP, Visual Genome, CC12M, and STPLS3D, and synthesize 74K training samples after consensus and difficulty filtering. The method is generalizable to other tool actions such as flipping, 3D grounding, or expert model calls, as the core distillation mechanism remains agnostic to the specific tool used during synthesis.
Experiment
- Region-to-Image Distillation enables models to internalize zooming expertise, achieving fine-grained perception in a single forward pass without iterative tool use.
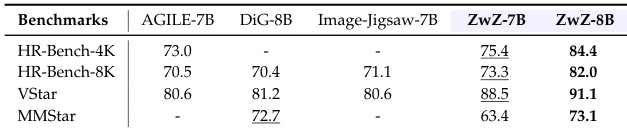
- ZwZ variants consistently outperform baseline Qwen-VL models across general, specific, and OOD benchmarks, including surpassing larger open-source models and rivaling closed-source SOTA in accuracy.
- Training on distilled synthetic data proves more effective than using larger public datasets or proxy-task synthetic data, highlighting the value of fine-grained, high-quality supervision over data volume.
- The method narrows the “zooming gap” between global and regional view performance, particularly improving on structure, material, and counting tasks where attention dilution is common.
- Visual grounding via bounding boxes overlaid on images during training significantly enhances attention localization, leading to better real-world generalization without requiring boxes at test time.
- ZwZ models outperform agentic and tool-use baselines while being substantially faster, demonstrating that inference-time zooming benefits can be internalized into model weights.
- Attention map analysis confirms ZwZ models concentrate more relevant visual attention on key regions, aligning with improved perception and reduced perceptual oversight.
- The approach validates that “information-neutral” image actions (like zooming) can be effectively distilled into models, while “information-gain” actions (like web search) remain essential for external interaction.
The authors use Region-to-Image Distillation to train compact vision-language models that achieve fine-grained perception in a single forward pass, without relying on inference-time zooming tools. Results show these models consistently outperform larger open-source baselines and match or exceed closed-source models on diverse benchmarks, while also demonstrating superior attention localization and generalization to real-world tasks. This approach effectively internalizes the benefits of tool-based zooming into model weights, achieving higher accuracy with significantly lower inference latency.
The authors use Region-to-Image Distillation to train compact vision-language models on synthetic data, enabling them to achieve fine-grained perception from full images in a single forward pass. Results show consistent improvements over baseline models and outperform larger open-source systems across general, specific, and out-of-distribution benchmarks, even surpassing agentic models that rely on iterative zooming. The method also demonstrates superior data efficiency and internalizes tool-use benefits while maintaining significantly lower inference latency.

The authors use Region-to-Image Distillation to train models that internalize fine-grained perception without requiring test-time zooming. Results show that ZwZ variants consistently achieve higher attention coverage on key image regions compared to their Qwen-VL baselines, indicating improved localization of task-relevant visual evidence. This enhanced focus directly contributes to narrowing the performance gap between global and regional views in fine-grained tasks.

The authors use Region-to-Image Distillation with bounding box overlays on images to train models that internalize fine-grained perception without requiring inference-time zooming. Results show that this approach significantly outperforms direct synthesis and alternative grounding strategies, narrowing the performance gap between global and regional views while improving attention focus on task-relevant regions. The method proves more effective than training on larger public datasets or proxy-task synthetic data, achieving strong generalization across diverse benchmarks with minimal data.

The authors use Region-to-Image Distillation to train compact vision-language models that achieve fine-grained perception in a single forward pass, without relying on inference-time zooming tools. Results show these models consistently outperform both larger open-source baselines and agentic systems across multiple benchmarks, while maintaining significantly lower inference latency. The method effectively internalizes the benefits of region-focused reasoning, narrowing the performance gap between global and regional views without requiring test-time tool calls.