Command Palette
Search for a command to run...
에이전트형 AI 시스템의 구성 학습
에이전트형 AI 시스템의 구성 학습
Aditya Taparia Som Sagar Ransalu Senanayake
초록
LLM 기반 에이전트 시스템을 구성하는 과정은 다양한 워크플로우, 도구, 토큰 예산, 프롬프트 등을 대규모 조합 설계 공간에서 선택하는 것으로, 현재는 고정된 대규모 템플릿이나 수작업으로 조정된 히ュ리스틱 방식으로 처리된다. 이는 동일한 복잡한 구성이 쉬운 입력 쿼리와 어려운 입력 쿼리에 모두 동일하게 적용되기 때문에, 시스템이 취약한 동작을 보이고 불필요한 계산 자원을 소모하게 만든다. 본 연구에서는 에이전트 구성 문제를 쿼리별 결정 문제로 재정의하고, 강화학습을 활용해 가벼운 계층적 정책을 학습하는 ARC(Agentic Resource & Configuration learner)를 제안한다. 이 정책은 입력 쿼리에 따라 동적으로 구성 파라미터를 조정함으로써 효율성을 극대화한다. 여러 추론 및 도구 보강형 질의응답 벤치마크에서, 학습된 정책은 강력한 수작업 설계된 기준 모델과 다른 기존 대안들을 지속적으로 능가하며, 최대 25% 높은 작업 정확도를 달성하면서도 토큰 사용량과 실행 시간 비용을 감소시켰다. 이러한 결과는 ‘일괄적 적용’ 방식에 대한 대안으로, 쿼리별로 에이전트 구성 설정을 학습하는 것이 매우 효과적인 전략임을 보여준다.
One-sentence Summary
Researchers from MIT and Stanford propose ARG, a reinforcement learning-based policy that dynamically configures LLM agents per query, outperforming static templates by up to 25% in accuracy while cutting token and runtime costs, enabling efficient, adaptive agent deployment across reasoning and tool-augmented QA tasks.
Key Contributions
- ARG frames agent configuration as a per-query decision problem, using a lightweight hierarchical RL policy to dynamically select workflows, tools, and token budgets—avoiding the inefficiency of static, one-size-fits-all setups that waste compute on trivial queries.
- The method introduces a hybrid training pipeline combining masked RL with supervised fine-tuning on elite trajectories, enabling stable learning over a combinatorial space of 10^5+ configurations without modifying the underlying LLM.
- Evaluated on reasoning and tool-augmented QA benchmarks, ARG improves task accuracy by up to 25% over hand-designed and flat RL baselines while simultaneously reducing token usage and runtime, demonstrating the value of adaptive configuration.
Introduction
The authors leverage reinforcement learning to dynamically configure LLM-based agent systems per query, addressing the inefficiency of static, one-size-fits-all designs that waste compute on simple tasks and degrade performance on complex ones due to long-context noise. Prior work relies on hand-tuned heuristics or fixed templates, which fail to adapt workflows, tool usage, or token budgets to input difficulty—leading to brittleness and unnecessary cost. Their main contribution is ARC, a lightweight hierarchical RL policy that selects workflows and tools at a high level and composes prompts at a low level, trained via a hybrid masked RL and SFT pipeline to navigate the combinatorial design space efficiently. Experiments show up to 25% higher accuracy with reduced token and runtime costs across reasoning and tool-augmented QA benchmarks.
Method
The authors leverage a hierarchical reinforcement learning framework to train an Adaptive Resource Controller (ARC) that dynamically configures agentic systems for each input query. The core objective is to maximize a utility function that balances task correctness against computational cost, formalized as U(q,c)=I[a^=a]−λCcost(c), where c=(ω,t,b,p) encodes the selected workflow, tools, budget tiers, and prompt instructions. To make this optimization tractable, the policy π is decomposed into two distinct components: a structure policy πstruct and a prompt policy πprompt. This hierarchical design replaces a single joint decision with sequential structural and prompt decisions, reducing search complexity and improving sample efficiency.
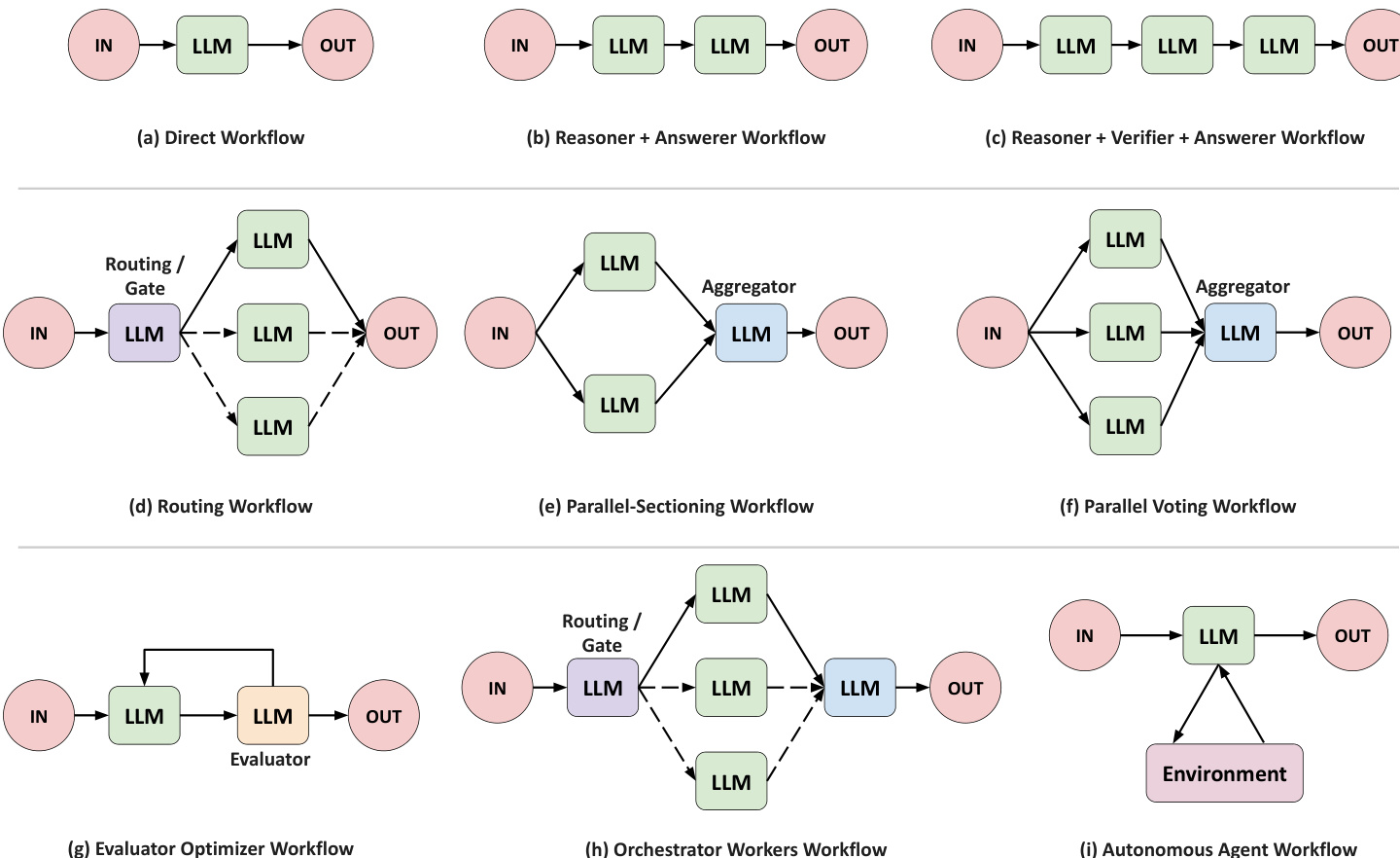
The structure policy πstruct operates as a high-level decision-maker that selects the architectural blueprint for a given query. Its action space outputs a composite configuration astruct=(ω,t,b), where ω denotes one of nine predefined agentic workflows, t specifies the subset of enabled tools (e.g., calculator, web search, OCR), and b allocates token-budget tiers per agent. The workflows range from simple single-call patterns like Direct to complex multi-agent orchestrations such as Orchestrator-Workers or Evaluator-Optimizer, each defining a distinct computation graph over LLM calls. As shown in the figure below, the structure policy must navigate a combinatorial space of possible configurations, which is pruned via action masking to exclude structurally invalid combinations—for instance, allocating tools to non-existent agents in a Direct workflow.
The prompt policy πprompt operates sequentially after the structure policy, conditioning on the selected workflow and resources to compose semantic instructions for each agent. Its action space is compositional, drawing from a library of instruction fragments (e.g., “Decompose the problem”, “Verify intermediate steps”) and terminating with a STOP action. These prompts are dynamically generated via meta-prompting to ensure task-specific relevance, outperforming static or hand-crafted alternatives. The policy constructs the final prompt p by iteratively selecting instruction components, effectively operationalizing the high-level architectural decision into executable agent directives.
The training process is implemented as a short episodic Markov decision process, where each episode corresponds to configuring and executing the agent system for a single query. The state sq is constructed by concatenating a semantic embedding ϕ(q)—generated via MetaCLIP-H/14—with a feature vector fq encoding query length, word count, and numerical density. The reward signal, received at the end of each episode, is a shaped composite of three interpretable terms: task success (α⋅I[correct]), efficiency penalties (−βs⋅nsteps−βt⋅ntokens/Tmax), and tool shaping (η⋅Rtool). The tool shaping term is asymmetric: it rewards tool invocation when the answer is correct and penalizes allocated-but-unused tools, aligning the structure policy’s provisioning with the LLM’s actual usage.
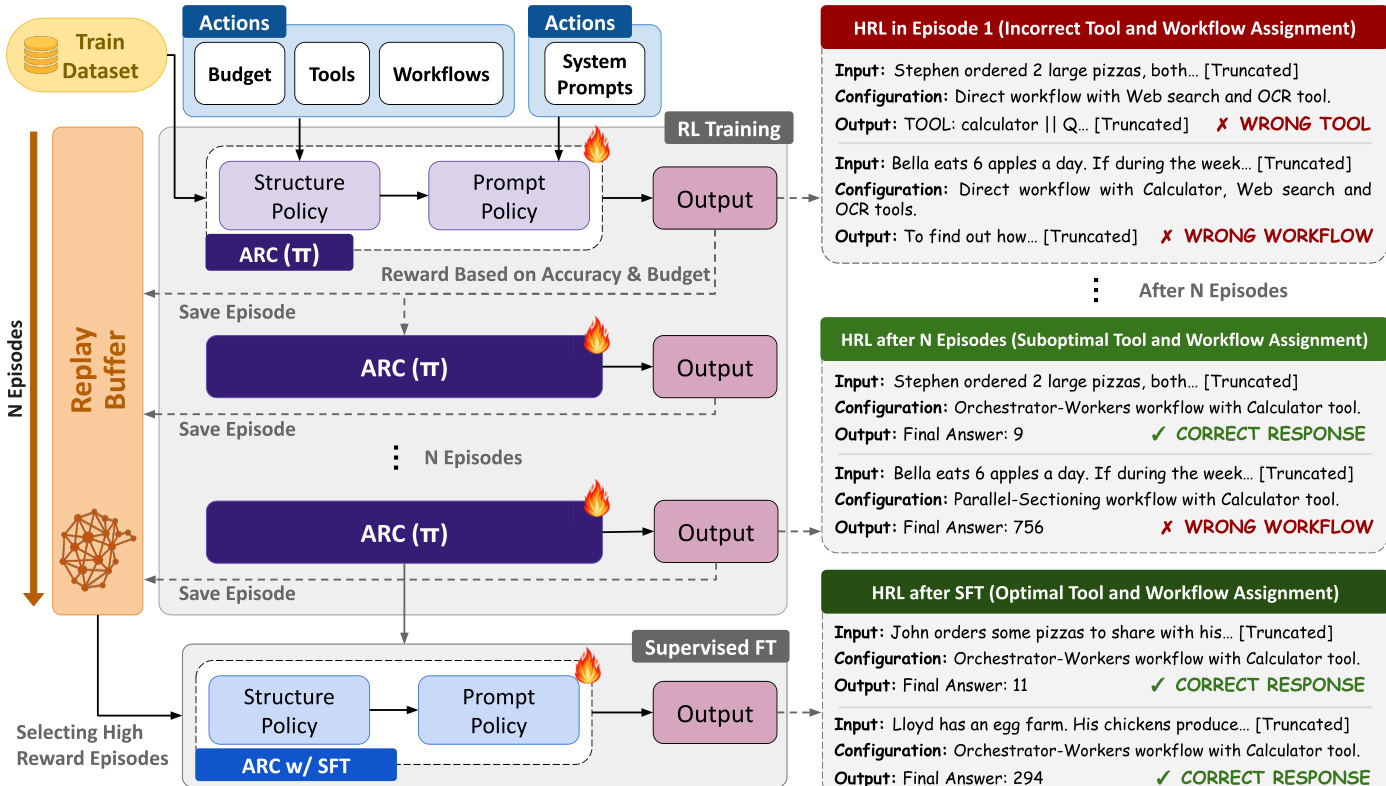
Both policies are optimized end-to-end using Proximal Policy Optimization (PPO), with separate value networks for advantage estimation and per-batch advantage normalization to stabilize learning. The clipped surrogate objective prevents destructive updates, and entropy regularization encourages early exploration. As illustrated in the training pipeline, episodes are stored in a replay buffer during RL training. After convergence, the authors extract elite trajectories—those that are both correct and exceed a reward threshold—and fine-tune the policies via supervised learning on this distilled dataset. This post-training refinement phase stabilizes the policy by restricting its support to high-performing configurations, providing formal performance guarantees.
The entire system is designed to dynamically allocate workflows, tools, and budgets based on the input query, as depicted in the high-level architecture diagram. The ARC module receives the query and, through its hierarchical policy, selects the appropriate configuration from the space of many possibilities, producing an agent response along with metadata on the selected workflow, tools, and budget tier.
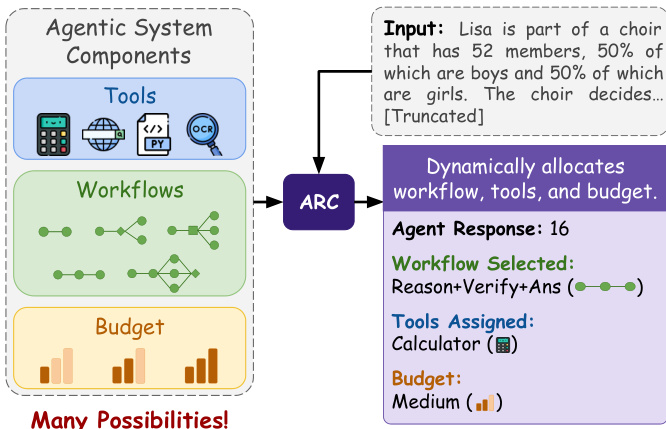
This architecture enables the system to adapt its computational resources to the complexity of each query, balancing accuracy and efficiency without requiring manual tuning or fixed configurations.
Experiment
- Learned configurations via ARC consistently outperform fixed architectures and search-based methods across reasoning and tool-use benchmarks, validating adaptive structural design.
- Adaptive allocation enables superior accuracy-cost trade-offs, with ARC achieving high performance at lower token costs by dynamically selecting lightweight or complex workflows per query.
- Policies show moderate transfer across similar reasoning tasks but limited transfer to dissimilar tool-use tasks, indicating structural compatibility matters more than semantic similarity.
- ARC generalizes well across model scales, maintaining effectiveness when applied to larger variants of the same model family without retraining.
- SFT refinement improves performance and stability by distilling elite trajectories, reducing variance while preserving learned structural priors.
- Error analysis confirms policy configuration errors are minimal (<10%), with most failures stemming from inherent LLM reasoning or knowledge gaps, not structural misselection.
- Ablations confirm PPO with shaped rewards outperforms GRPO and DPO, and learned embeddings and prompt atoms significantly impact downstream policy effectiveness.
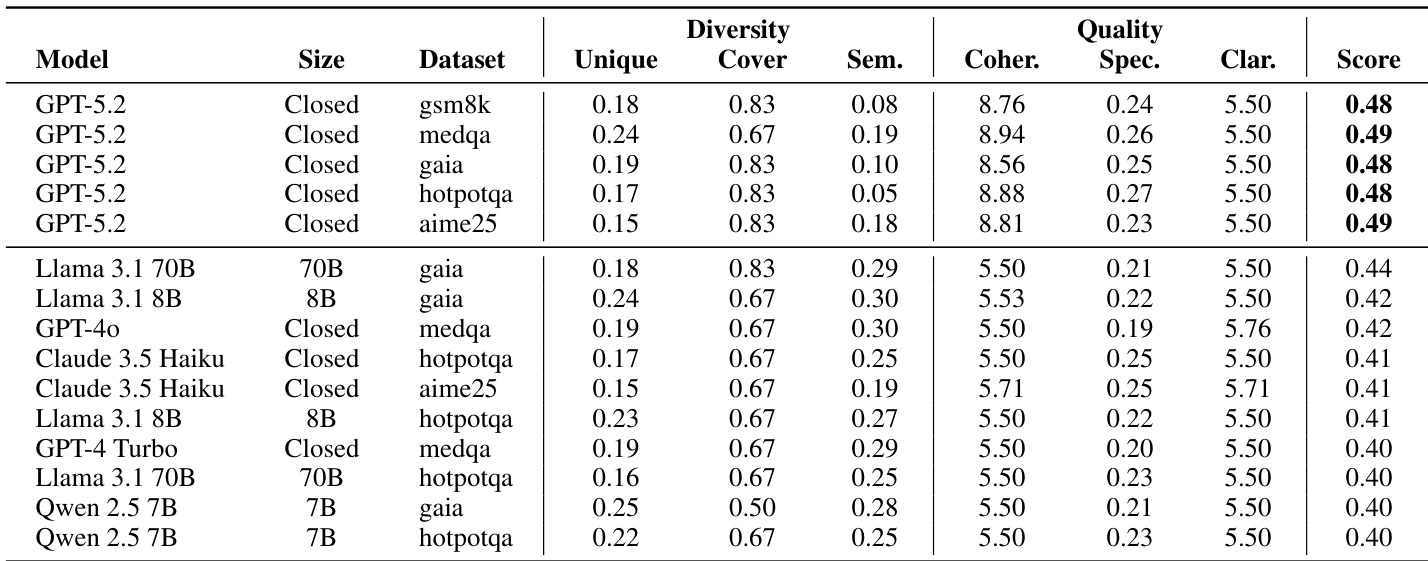
The authors use GPT-5.2 to generate prompt atoms for their framework, as it achieves the highest combined score across diversity and quality metrics compared to other LLMs like Llama 3.1, Claude 3.5, and Qwen 2.5. Results show GPT-5.2 consistently outperforms alternatives in coherence, clarity, and strategy coverage, making it the optimal choice for constructing the prompt library.
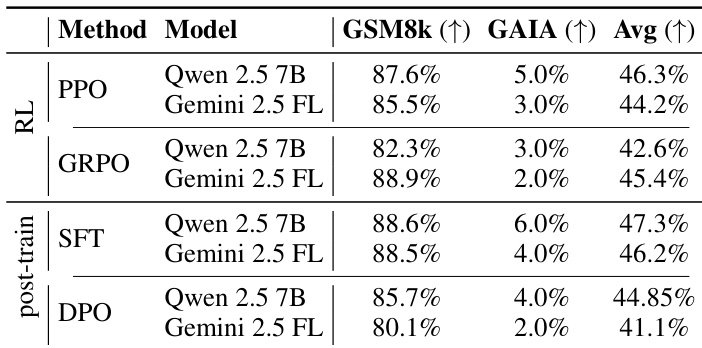
The authors use a post-training refinement phase to improve policy performance, with SFT consistently outperforming DPO and baseline RL methods across both Qwen and Gemini models. Results show that SFT achieves higher average accuracy and better task-specific gains, particularly on GAIA, indicating that distilling elite trajectories enhances generalization and stability. This refinement step proves critical for elevating the performance floor without requiring additional environment interactions.
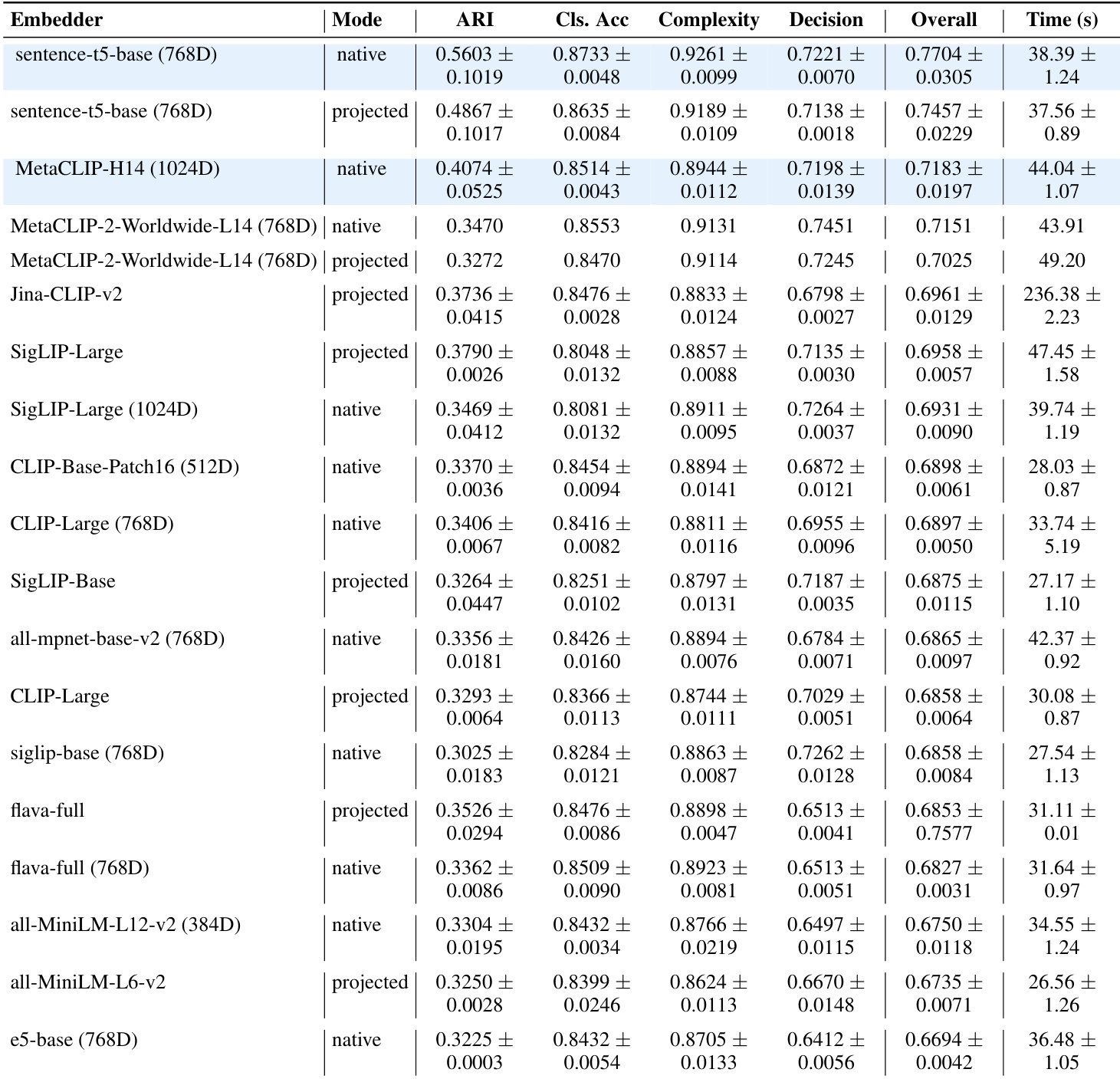
The authors evaluate multiple embedding models to determine which best supports downstream policy learning, measuring performance across clustering, classification, complexity ranking, and decision prediction tasks. Sentence-T5-base and MetaCLIP-H14 emerge as top performers, balancing high overall scores with reasonable computational cost, indicating their suitability for encoding query states in adaptive configuration systems. Results confirm that embedding quality directly influences policy effectiveness, with text-only and multimodal models both capable of strong performance depending on task requirements.
The authors use a learned configuration framework (ARC) to adaptively select workflows and tools for LLM-based tasks, outperforming fixed architectures and search-based baselines across reasoning and tool-use benchmarks. Results show that ARC achieves higher accuracy while maintaining efficiency, with gains consistent across model sizes and partial transferability across tasks sharing structural or tool similarities. The framework’s effectiveness is further supported by low policy configuration error rates and improved performance after supervised fine-tuning refinement.

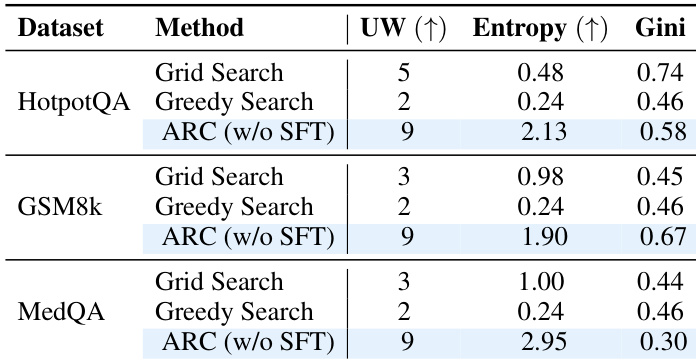
The authors use ARC to learn adaptive workflow configurations and observe significantly higher workflow diversity compared to grid or greedy search baselines, as measured by unique workflows, entropy, and Gini coefficient. Results show that ARC explores a broader and more balanced set of structural patterns, indicating its ability to dynamically tailor configurations to task demands rather than relying on fixed or exhaustively searched strategies.