Command Palette
Search for a command to run...
GENIUS: 생성형 유동지능 평가 세트
GENIUS: 생성형 유동지능 평가 세트
초록
통합 다중모달 모델(UMMs)은 시각 생성 분야에서 놀라운 진전을 보이고 있다. 그러나 기존의 평가 벤치마크는 주로 축적된 지식과 학습된 구조를 회상하는 데 의존하는 '고정 지능(Crystallized Intelligence)'을 평가하는 데 치중하고 있다. 이러한 접근은 시각적 패턴을 유추하고 제약 조건을 기반으로 추론하며 새로운 상황에 즉각적으로 적응할 수 있는 '생성형 유동 지능(Generative Fluid Intelligence, GFI)'을 간과하고 있다. 이러한 능력을 엄격히 평가하기 위해 우리는 GENIUS(GEN Fluid Intelligence EvalUation Suite)를 제안한다. 우리는 GFI를 세 가지 기본 요소의 통합으로 정의한다. 이는 은유적 패턴 유추(예: 개인화된 시각적 선호도 추론), 임시 제약 조건 실행(예: 추상적 은유 시각화), 그리고 맥락 지식에 대한 적응(예: 직관에 어긋나는 물리 법칙 시뮬레이션)을 포함한다. 이 세 가지 요소는 모델이 즉각적인 맥락에 기반한 문제를 해결하도록 요구한다. 12개의 대표적 모델에 대한 체계적 평가 결과, 이러한 작업에서 모델들은 심각한 성능 저하를 보였다. 특히 진단 분석을 통해 이러한 실패 유형을 분리해내었으며, 성능 저하의 근본 원인이 내재된 생성 능력 부족이 아니라 제한된 맥락 이해 능력에 있음을 입증하였다. 이 격차를 해소하기 위해 우리는 학습이 필요 없는 어텐션 간섭 전략을 제안한다. 결론적으로, GENIUS는 GFI에 대한 엄격한 평가 기준을 제시하며, 지식 활용을 넘어서 동적이고 보편적인 추론으로 나아가야 할 방향을 제시한다. 본 연구의 데이터셋과 코드는 다음 링크에서 공개될 예정이다: https://github.com/arctanxarc/GENIUS
One-sentence Summary
Researchers from Tsinghua University and collaborators propose GENIUS, a benchmark evaluating Generative Fluid Intelligence in multimodal models via pattern induction, constraint execution, and contextual adaptation; they introduce a training-free attention intervention to address context comprehension gaps, advancing dynamic reasoning beyond static knowledge recall.
Key Contributions
- We introduce GENIUS, the first benchmark suite designed to evaluate Generative Fluid Intelligence (GFI) in multimodal models, formalizing GFI through three primitives: inducing implicit patterns, executing ad-hoc constraints, and adapting to contextual knowledge, with tasks decoupled from static knowledge to isolate dynamic reasoning.
- Our evaluation of 12 state-of-the-art models reveals consistent deficits in GFI tasks, with diagnostic analysis showing failures stem from poor context comprehension rather than weak generative capacity, highlighting a critical gap in current UMMs’ ability to reason dynamically.
- To address this, we propose a training-free attention intervention strategy that improves model performance across GENIUS tasks by enhancing focus on contextual rules, validating our theoretical insight that imbalanced attention undermines implicit in-context learning.
Introduction
The authors leverage the Cattell-Horn-Carroll theory to define Generative Fluid Intelligence (GFI) as the ability to induce patterns, execute ad-hoc constraints, and adapt to novel contextual knowledge—capabilities critical for true general intelligence in visual generation. Prior benchmarks largely assess crystallized intelligence (knowledge recall), ignoring GFI, and lack formal definitions, fine-grained tasks, or diagnostic analysis of failure modes. Their main contribution is GENIUS, the first benchmark dedicated to evaluating GFI through 510 expert-curated samples across three dimensions, revealing that even top models fail due to poor context comprehension rather than weak generative capacity—and they propose a training-free attention intervention that boosts performance across tasks.
Dataset

The authors use GENIUS, a multimodal benchmark designed to evaluate flexible intelligence (FI), composed of three core dimensions: Implicit Pattern Induction, Ad-hoc Constraint Execution, and Contextual Knowledge Adaptation. Each dimension includes novel, expert-curated tasks requiring tight integration of visual and textual modalities — removing either modality renders the task unsolvable.
-
Implicit Pattern Induction includes Implicit Pattern Generation: models must infer unstated stylistic preferences from interleaved image-text inputs and apply them in generation. Relying on only one modality leads to failure — images alone cause feature conflation, text alone leaves preferences undefined.
-
Ad-hoc Constraint Execution features two tasks: Visual Constraint Generation and Symbolic Constraint Generation. Models must reason under novel, context-defined rules (e.g., a blue square means “remove an object,” or a function f means “melt an object”). These rules deliberately use semantically neutral elements to test abstract reasoning; missing either modality breaks rule establishment.
-
Contextual Knowledge Adaptation comprises Prior-Conflicting Generation (e.g., “weight is determined by color”) and Multi-Semantic Generation (e.g., interpreting “green hand” as novice vs. skin tone). Models must override pretrained knowledge or resolve ambiguity based on context — failure occurs if either modality is absent.
GENIUS contains 5 tasks across 3 dimensions, totaling 20 sub-tasks. The dataset is structured to test dynamic reasoning, adaptation, and cross-modal integration — no training split or mixture ratios are specified, as it is a pure evaluation benchmark. No cropping or metadata construction is mentioned; the focus is on carefully designed, modality-dependent test cases.
Method
The authors leverage a theoretical framework rooted in In-Context Learning (ICL) as Implicit Fine-Tuning to analyze and enhance the generative capabilities of the Bagel model, which employs a Mixture-of-Experts (MoE) Transformer architecture. Their core insight is that the ICL process during multimodal generation can be mathematically formalized as an implicit gradient descent over specific model parameters—namely, the Up projection layer and the bias term within the decoder blocks. This theoretical grounding, derived from the model’s forward pass, reveals that context tokens induce parameter updates that steer the generation trajectory. The authors formalize this relationship through Theorem 4.1, which establishes that a perturbation in the context input u can be compensated by a corresponding perturbation in the Up and bias parameters, such that the output remains invariant. This equivalence is expressed as LUp+ΔUp,b+Δb(u′,g)=LUp,b(u,g), where the perturbations ΔUp and Δb are explicitly defined in terms of the normalized attention difference δA and the attention function A(u,g).
Building on this, Theorem 4.2 further refines the analysis by deriving gradient descent update rules for these parameters across iterative context token processing. The authors show that the Up and bias parameters evolve according to Upi+1=Upi−h∇UpLi(Upi) and bi+1=bi−∇b(tr(δi⊤bi)), where the learning rate h and loss function Li are derived from the attention mechanism’s output. This theoretical analysis identifies a critical deficit in Guided Fine-tuning (GFI): an imbalanced attention distribution over context tokens leads to noisy, stochastic gradient updates that fail to overcome pre-trained priors.
To address this, the authors propose a training-free Attention Adjustment Mechanism, designed to recalibrate the implicit gradient direction by suppressing the influence of irrelevant “noise” tokens. The mechanism operates as a three-stage pipeline. First, in the Keyword Distillation phase, the model is prompted to extract task-critical visual cues from the context images as a set of region-specific keywords K. This step is guided by a structured prompt template, which instructs the model to parse multimodal instructions and map each image to its specific role—whether as a target canvas, a source of features, or an irrelevant reference. The prompt enforces a strict JSON output format to ensure precise, machine-readable keyword generation.

Second, during Relevance Mapping, the model computes a semantic relevance map S by evaluating the alignment between the distilled keywords and the visual context tokens. This map serves as a proxy for the token’s contribution to the effective gradient signal. Finally, in the Bias Injection stage, the authors inject a spatial bias F(S) directly into the attention logits of selected decoder layers and generation steps. The modulated attention logits A^l,h are computed as A^l,h(i,j)=Al,h(i,j)+λ⋅F(Si), where the function F(⋅) normalizes the relevance scores to a bipolar distribution, effectively amplifying the attention weights of signal tokens and suppressing those of noise tokens. The final attention weights are then computed via the standard Softmax operation, ensuring that the gradient norm contribution from noise is exponentially dampened.

This intervention transforms the implicit gradient from a noisy, signal-plus-noise composition into a clean, signal-dominated update, as illustrated in the conceptual diagram. The authors demonstrate that this method deterministically steers the optimization trajectory, enabling the model to overcome pre-trained priors and achieve more accurate, instruction-following generation. The entire process is implemented without modifying the model’s weights, making it a lightweight, post-hoc enhancement to existing multimodal architectures.
Experiment
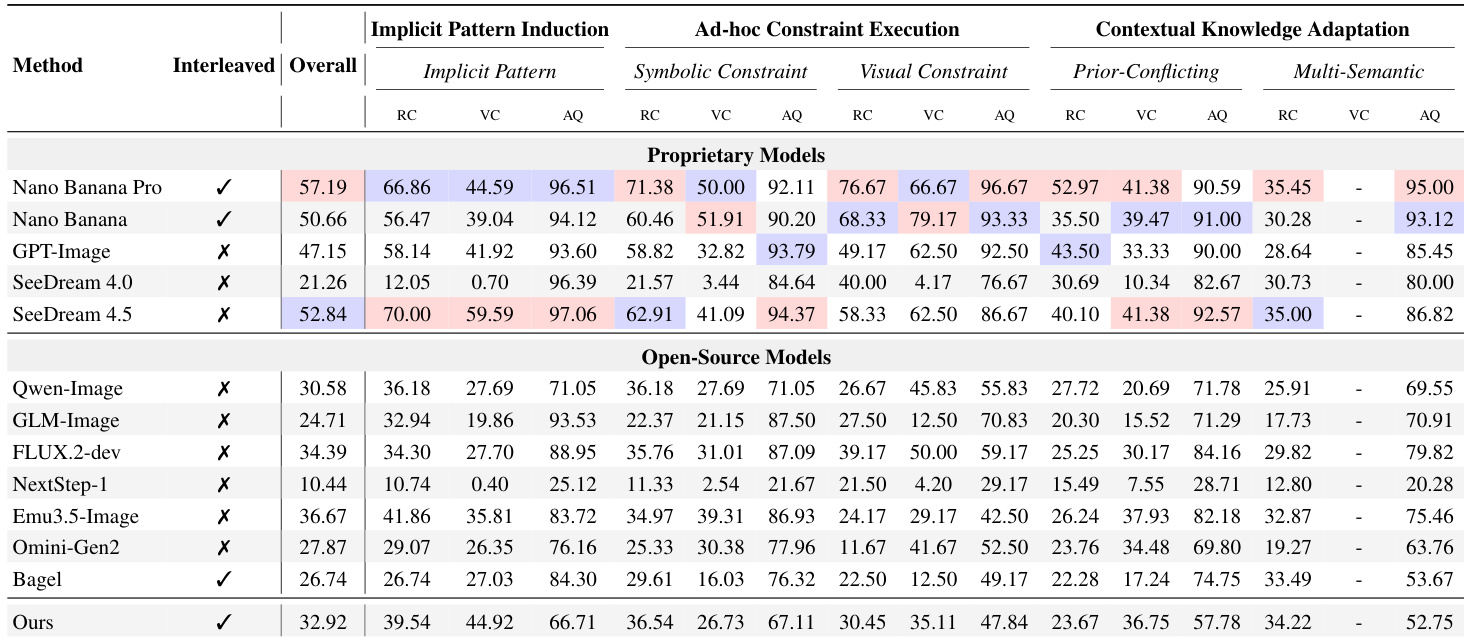
- Evaluated 12 models using a hybrid LMM-based framework (Gemini-3-Pro) with three metrics: Rule Compliance, Visual Consistency, and Aesthetic Quality, grounded in human-curated hints to ensure rigor.
- State-of-the-art models, including Nano Banana Pro, scored below passing thresholds, revealing a fundamental gap in fluid intelligence despite strong aesthetic output.
- Models consistently fail to override pre-trained priors when faced with conflicting or novel rules, showing cognitive inertia rather than adaptive reasoning.
- Aesthetic quality masks deeper failures: models generate visually plausible images but violate logical or rule-based constraints, exposing a bias toward surface realism over contextual fidelity.
- Inference-time strategies like pre-planning or post-reflection yield minimal gains, indicating architectural limitations in leveraging reasoning for generation.
- Human-curated hints significantly improve performance, especially for stronger models, confirming that context comprehension is critical—but insufficient without robust generative capability.
- Reformulating tasks as VQA reveals models often understand instructions but fail to execute them visually, pointing to a “know-but-cannot-draw” gap in decoder efficiency.
- LMM-as-judge validation shows high correlation with human ratings (r > 0.96), and cross-judge consistency (Qwen2.5-VL-72B) confirms results reflect intrinsic model gaps, not evaluator bias.
- Attention visualization reveals noisy, unfocused context processing in baseline models; a proposed intervention sharpens attention on key tokens, boosting performance without parameter updates.
- Context ablation confirms its necessity: removing contextual input causes severe performance drops, especially in tasks requiring inductive reasoning or overriding priors.
The authors use a large multimodal model as an evaluator to assess 12 image generation models across multiple dimensions of generative fluid intelligence, revealing that even top proprietary models score below 60% overall and struggle with rule compliance and contextual adaptation. Results show a consistent gap between models’ ability to comprehend instructions and their capacity to generate visually accurate outputs, with aesthetic quality often masking deeper logical failures. Interventions that improve attention focus yield measurable gains, suggesting that architectural improvements in context processing are key to advancing generative adaptability.
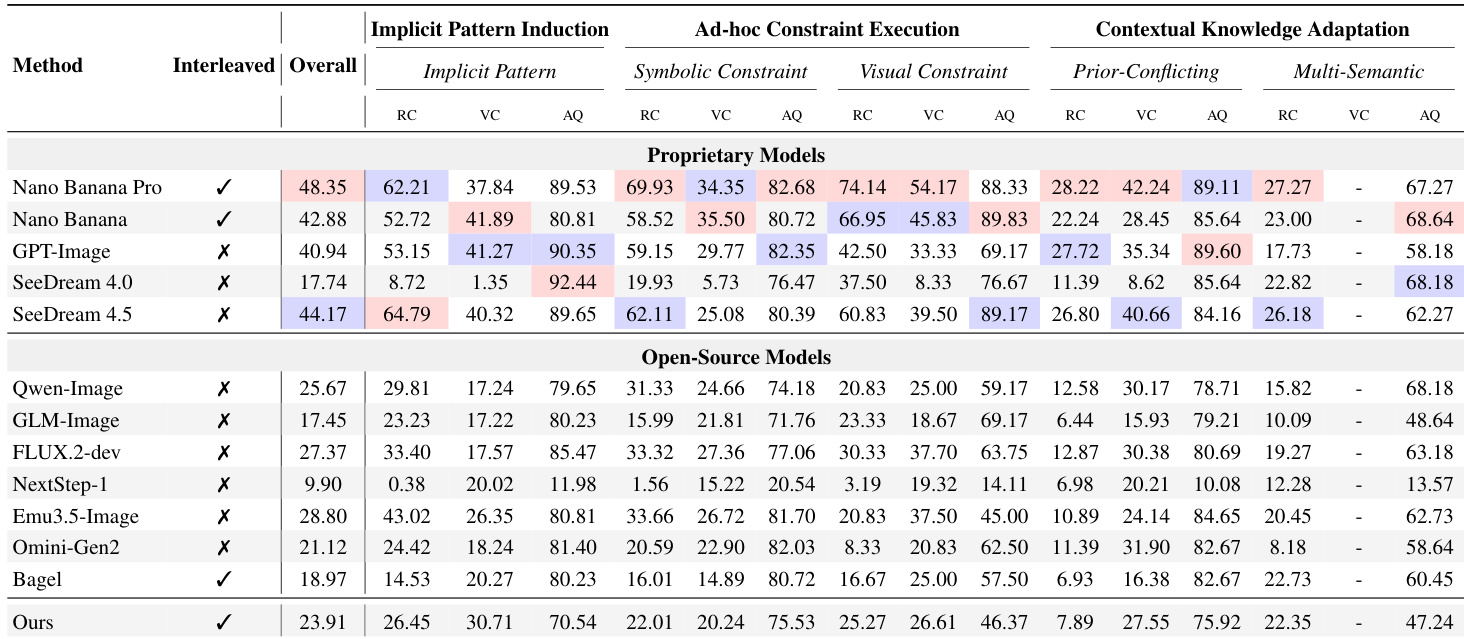
The authors use a structured evaluation framework with a large multimodal model as judge to assess 12 models on Generative Fluid Intelligence tasks, revealing that even top proprietary models score below 60% overall due to poor adaptation to novel rules and context. Results show a consistent gap between models’ ability to comprehend instructions and their capacity to generate visually compliant outputs, with aesthetic quality often masking deeper logical failures. The proposed GENIUS benchmark introduces multimodal interleaved context and hybrid evaluation to expose these limitations, confirming that current architectures struggle to override pre-trained priors when faced with conflicting or ad-hoc instructions.
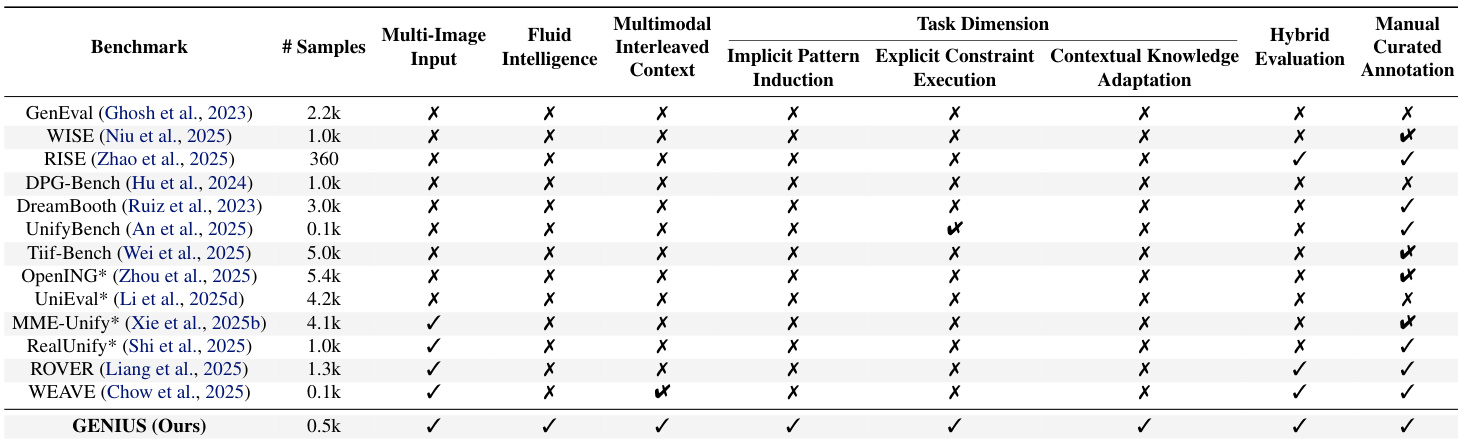
The authors use a large multimodal model as an evaluator to assess 12 image generation models across three dimensions: rule compliance, visual consistency, and aesthetic quality. Results show that even top proprietary models like Nano Banana Pro score below 60 overall, revealing a significant gap in fluid intelligence—particularly in adapting to novel or conflicting rules—while open-source models lag further behind. Aesthetic quality scores often mask deeper failures in logical adherence, indicating current models prioritize surface realism over contextual reasoning.