Command Palette
Search for a command to run...
dnaHNet: 유전체 서열 학습을 위한 확장 가능하고 계층적인 Foundation Model
dnaHNet: 유전체 서열 학습을 위한 확장 가능하고 계층적인 Foundation Model
Arnav Shah Junzhe Li Parsa Idehpour Adibvafa Fallahpour Brandon Wang Sukjun Hwang Bo Wang Patrick D. Hsu Hani Goodarzi Albert Gu
초록
유전체 파운데이션 모델(Genomic foundation models)은 DNA 구문을 해독할 수 있는 잠재력을 지니고 있으나, 입력 표현 방식(input representation)에 있어 근본적인 트레이드오프(tradeoff) 문제에 직면해 있습니다. 표준적인 고정 어휘 토크나이저(fixed-vocabulary tokenizer)는 코돈(codon)이나 조절 요소(regulatory elements)와 같이 생물학적으로 유의미한 모티프(motif)를 파편화하는 반면, 뉴클레오타이드(nucleotide) 단위 모델은 생물학적 일관성을 유지할 수 있지만 긴 컨텍스트(context)를 처리할 때 막대한 계산 비용이 발생합니다.본 연구에서는 유전체 서열을 엔드투엔드(end-to-end)로 분할하고 모델링하는 최첨단 토크나이저 프리(tokenizer-free) 자기회귀(autoregressive) 모델인 dnaHNet을 소개합니다. dnaHNet은 미분 가능한 동적 청킹(differentiable dynamic chunking) 메커니즘을 사용하여 원시 뉴클레오타이드를 잠재적 token으로 적응형 압축하며, 이를 통해 압축률과 예측 정확도 사이의 균형을 맞춥니다. 원핵생물(prokaryotic) 게놈을 바탕으로 사전 학습된 dnaHNet은 확장성(scaling)과 효율성 측면에서 StripedHyena2를 포함한 기존의 선도적인 아키텍처들을 능가합니다. 이러한 재귀적 청킹(recursive chunking) 방식은 연산량(FLOP)을 이차 함수적으로(quadratic) 감소시켜, Transformer 대비 3배 이상의 추론(inference) 속도 향상을 실현합니다.제로샷(zero-shot) 태스크에서 dnaHNet은 단백질 변이 적합도(protein variant fitness) 및 유전자 필수성(gene essentiality) 예측에서 탁월한 성능을 달성하였으며, 감독(supervision) 없이도 계층적인 생물학적 구조를 자동으로 발견합니다. 이러한 결과는 dnaHNet이 차세대 유전체 모델링을 위한 확장 가능하고 해석 가능한(interpretable) 프레임워크임을 입증합니다.
One-sentence Summary
By employing a differentiable dynamic chunking mechanism to adaptively compress raw nucleotides into latent tokens, the tokenizer-free autoregressive foundation model dnaHNet achieves superior scaling and efficiency over architectures like StripedHyena2 and Transformers, delivering over 3x inference speedup and state-of-the-art performance on zero-shot tasks such as predicting protein variant fitness and gene essentiality.
Key Contributions
- The paper introduces dnaHNet, a tokenizer-free autoregressive model that utilizes a differentiable dynamic chunking mechanism to adaptively compress raw nucleotides into latent tokens.
- This architecture achieves significant computational efficiency by employing recursive chunking to reduce FLOPs quadratically, resulting in over 3x faster inference speeds compared to Transformer models.
- Experiments on prokaryotic genomes demonstrate that the model outperforms leading architectures like StripedHyena2 in scaling and efficiency, while also showing superior zero-shot performance in predicting protein variant fitness and gene essentiality.
Introduction
Genomic foundation models are essential for decoding DNA syntax to advance fields like drug discovery and synthetic biology. However, current approaches face a fundamental tradeoff between computational efficiency and biological accuracy. Fixed-vocabulary tokenizers are efficient but often fragment critical biological motifs like codons, while nucleotide-level models preserve biological coherence but suffer from prohibitive computational costs when processing long genomic contexts. The authors leverage a hierarchical, tokenizer-free architecture called dnaHNet to resolve this tension. By using a differentiable dynamic chunking mechanism, the model adaptively compresses raw nucleotides into latent tokens, allowing it to achieve superior scaling, faster inference, and state-of-the-art performance on zero-shot tasks such as protein variant fitness prediction.
Dataset
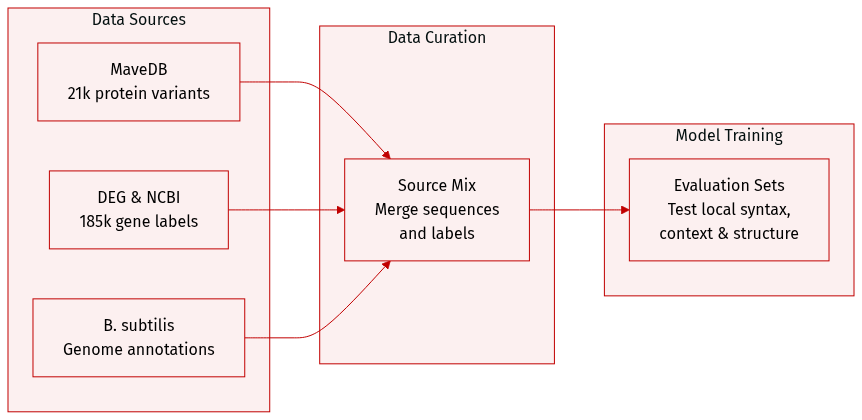
The authors evaluate dnaHNet using three distinct datasets designed to test different biological modeling capabilities:
- Protein Variant Effects (MaveDB): This subset consists of 21,250 nucleotide-level data points compiled from 12 experimental fitness datasets for E. coli K-12. It is used to assess the model's ability to capture local coding syntax and predict protein fitness landscapes.
- Gene Essentiality (DEG): Comprising 185,226 data points, this dataset was constructed by generating binary essentiality labels for genes across 62 bacterial organisms from the Database of Essential Genes. The authors sourced base sequences and annotations from NCBI and labeled genes as essential if they matched DEG entries by name or sequence identity greater than 99 percent. This subset evaluates the model's capacity to integrate genomic context and long-range dependencies.
- Genomic Structure Interpretation (NCBI): To perform interpretability analysis, the authors used the B. subtilis genome and functional annotations from NCBI. They partitioned the genome into distinct functional regions based on these annotations to determine how the model's segmentation aligns with known biological structures.
Method
The authors introduce dnaHNet, a scalable, tokenizer-free foundation model designed for genomic sequence learning. The model formulates genomic learning as an autoregressive sequence modeling problem. Given a nucleotide sequence X=(x1,…,xL) where xt∈{A,C,G,T}, the objective is to model the probability distribution P(X)=∏t=1LP(xt∣x<t). To handle long genomic contexts efficiently, dnaHNet utilizes a recursive hierarchical architecture consisting of three primary differentiable modules: an Encoder (E), a Main Network (M), and a Decoder (D).
Refer to the framework diagram:
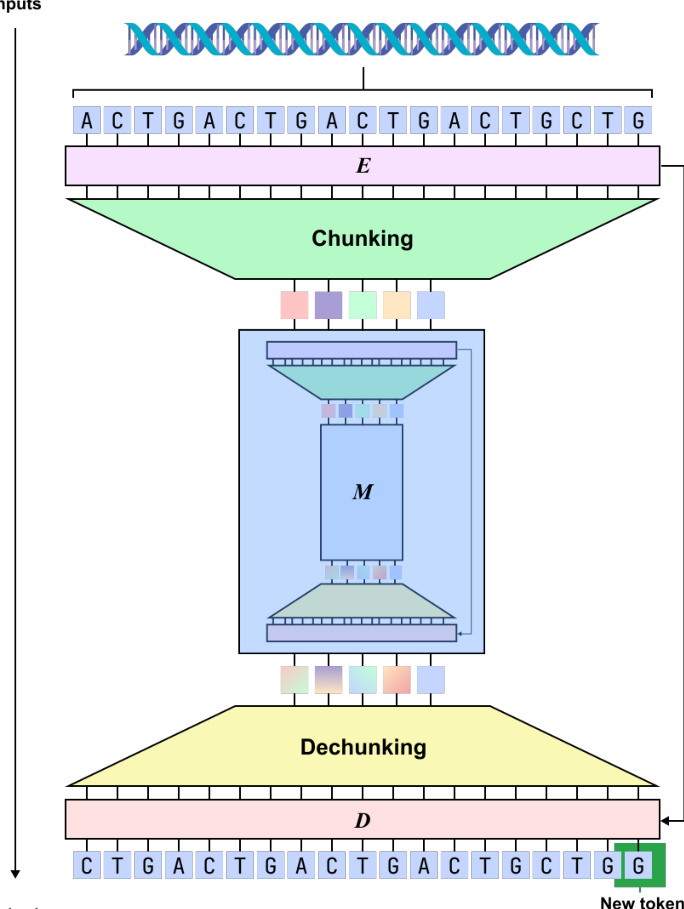
The Encoder is responsible for compressing nucleotide-level inputs into latent chunks through a dynamic segmentation mechanism. It employs a hybrid backbone consisting of four Mamba layers and one Transformer layer. The Encoder transforms input embeddings into hidden states h1:L∈RL×D. To determine segmentation boundaries, a boundary prediction module computes probabilities pt∈[0,1] using the following formulation: \npt=21(1−CosineSim(Wqht,Wkht−1)) where Wq and Wk are learnable projection matrices. High boundary probabilities are assigned to nucleotides with dissimilar representations, which encourages the model to segment at biologically significant transitions, such as codon boundaries. The Chunking layer then downsamples the output by selecting representations at these predicted boundaries, resulting in a compressed sequence E=(e1,…,eL′) where L′≤L.
As shown in the figure below:
The compressed sequence E is then processed by the Main Network M. This module can be a standard Transformer or another H-Net module, which allows for recursive chunking to capture multiple levels of abstraction. In a two-stage hierarchy, the first stage captures high-frequency local patterns like codon periodicity, while the second stage models long-range dependencies across functional regions. The Main Network outputs processed latent states E^=(e^1,…,e^L′)∈RL′×D.
The Decoder D maps these latent states back to the original nucleotide resolution through a two-step process. First, a smoothing module refines the latent states into smoothed representations Eˉ=(eˉ1,…,eˉL′) using a recurrence that interpolates discrete chunks: eˉj=Pje^j+(1−Pj)eˉj−1 where Pj is the boundary probability for the j-th chunk. Second, an upsampler expands these smoothed latents to the original length L by copying the vector eˉc(t) to every nucleotide position t corresponding to the chunk index c(t). The Decoder then utilizes four Mamba layers and one Transformer layer to model autoregressive dependencies, with a linear head projecting the output to the nucleotide vocabulary logits to produce the next-nucleotide distribution.
The training process is conducted end-to-end using a composite objective. The primary component is the autoregressive next-token prediction loss: LNLL=−∑t=1LlogPθ(xt∣x<t) To prevent degenerate segmentation during training, the authors incorporate a ratio loss that regularizes the dynamic chunking toward a target downsampling ratio Rs for each stage s: Lrate(s)=Rs−1Rs((Rs−1)FsGs+(1−Fs)(1−Gs)) where Fs is the actual fraction of selected chunks and Gs is the average boundary probability. The total loss is defined as L=LNLL+α∑sLrate(s), where α is a regularization coefficient.
Experiment
The experiments compare dnaHNet against StripedHyena2 and Transformer++ architectures through scaling law analyses, zero-shot biological prediction tasks, and structural interpretability studies. Results demonstrate that dnaHNet achieves superior compute and inference efficiency, consistently outperforming baselines in perplexity scaling and downstream performance on protein variant effect and gene essentiality predictions. Furthermore, the model demonstrates an emergent ability to learn biological hierarchies without supervision, effectively discovering codon structures and functional genomic regions through its hierarchical compression mechanism.
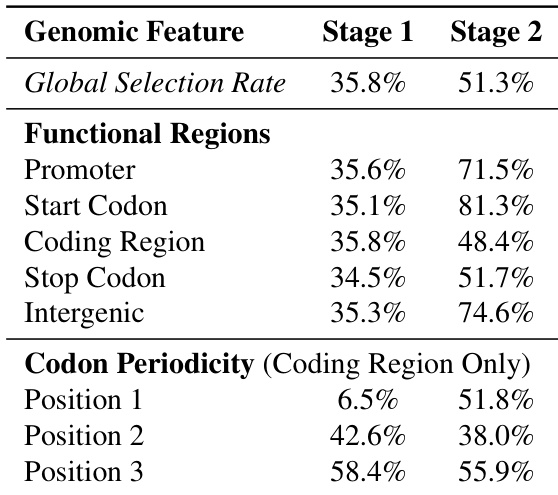
The authors analyze the learned hierarchical chunking boundaries of the dnaHNet model across different stages. The results demonstrate that the first stage captures local triplet codon structure, while the second stage identifies broader functional genomic organization. The first stage shows strong periodicity within coding regions, with selection rates varying significantly by codon position. The second stage exhibits higher selection rates for functional regions like promoters and intergenic areas compared to coding regions. The overall global selection rate increases from the first stage to the second stage.
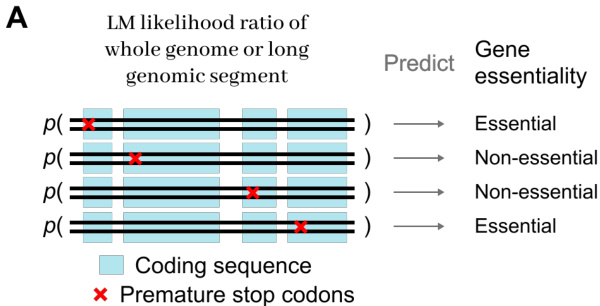
The authors evaluate the zero-shot protein variant effect prediction performance of dnaHNet against StripedHyena2 and Transformer baselines across various training compute budgets. Results show that dnaHNet consistently achieves higher Spearman correlation for predicting experimental fitness as training FLOPs increase. dnaHNet demonstrates superior predictive accuracy compared to both StripedHyena2 and Transformer architectures. The predictive performance of dnaHNet improves steadily as the amount of training compute increases. The performance gap between dnaHNet and the baseline models widens at higher training compute scales.
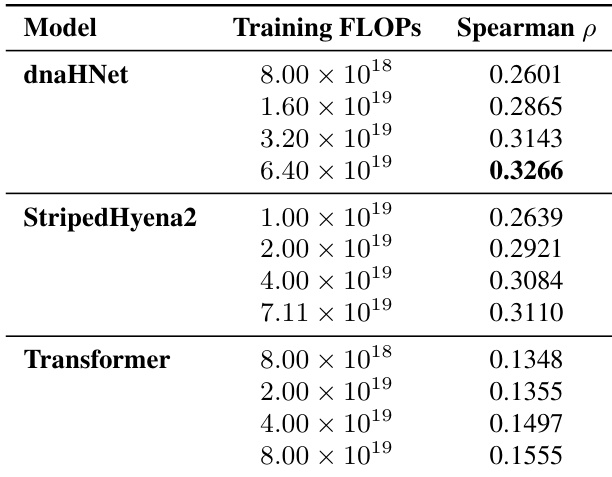
The authors compare the gene essentiality prediction performance of two dnaHNet hierarchical configurations against a StripedHyena2 baseline across various compute budgets. Results show that both dnaHNet architectures consistently outperform the baseline in AUROC as training compute increases. Both dnaHNet hierarchy versions demonstrate improved predictive accuracy as training FLOPs increase. The dnaHNet (3,2) hierarchy achieves higher AUROC scores compared to the (2,2) hierarchy at matched compute levels. dnaHNet models maintain a performance advantage over StripedHyena2 across the tested compute range.
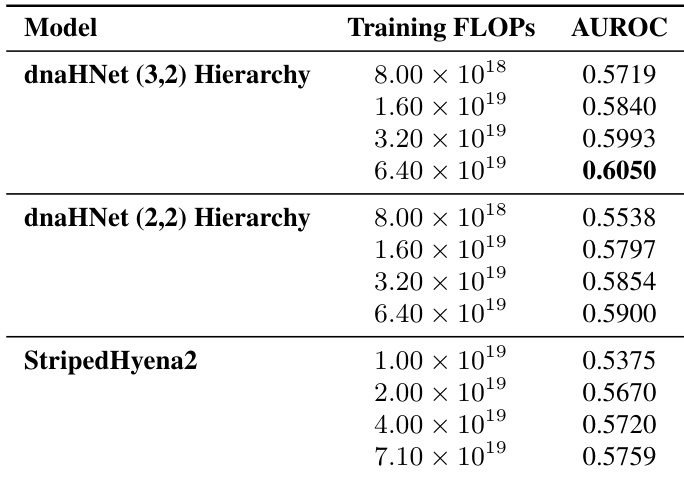
The researchers evaluate the dnaHNet model by analyzing its hierarchical chunking boundaries and testing its predictive capabilities for protein variant effects and gene essentiality. The findings reveal that the model successfully captures both local codon structures and broader functional genomic organization through its multi-stage hierarchy. Across various compute budgets, dnaHNet consistently outperforms StripedHyena2 and Transformer baselines, demonstrating superior scaling and predictive accuracy in both protein fitness and gene essentiality tasks.