Command Palette
Search for a command to run...
긴 컨텍스트 추론을 위한 게이트형 순환 기억: 언제 기억할 것인가, 언제 멈출 것인가
긴 컨텍스트 추론을 위한 게이트형 순환 기억: 언제 기억할 것인가, 언제 멈출 것인가
Leheng Sheng Yongtao Zhang Wenchang Ma Yaorui Shi Ting Huang Xiang Wang An Zhang Ke Shen Tat-Seng Chua
초록
긴 컨텍스트에 대한 추론은 다양한 실-world 응용 분야에서 필수적이지만, 대규모 언어 모델(Large Language Models, LLMs)은 컨텍스트 길이가 길어질수록 성능 저하를 겪으며 여전히 도전 과제로 남아 있다. 최근 연구인 MemAgent는 RNN 유사 루프를 활용해 컨텍스트를 청크 단위로 처리하고 최종 답변을 위해 텍스트 메모리를 갱신하는 방식으로 이 문제를 시도해왔다. 그러나 이러한 단순한 순환 메모리 갱신 방식은 두 가지 핵심적인 단점에 직면해 있다. 첫째, 증거가 없는 청크에서도 무분별하게 메모리가 갱신되면서 메모리 크기가 급격히 증가(메모리 폭주)할 수 있다는 점이며, 둘째, 루프에 종료 메커니즘이 부재하여 충분한 증거가 수집된 이후에도 불필요한 계산이 지속된다는 점이다. 이러한 문제를 해결하기 위해 우리는 더 안정적이고 효율적인 긴 컨텍스트 추론을 위한 GRU-Mem을 제안한다. GRU-Mem은 두 개의 텍스트 제어 게이트를 도입하여 메모리 갱신과 루프 종료를 보다 정교하게 제어한다. 구체적으로, GRU-Mem에서는 업데이트 게이트가 열려 있을 때만 메모리가 갱신되며, 종료 게이트가 열리면 즉시 루프를 종료한다. 이러한 기능을 구현하기 위해, 엔드 투 엔드 강화 학습(Reinforcement Learning) 내에서 두 가지 보상 신호인 ( r^{\text{update}} )와 ( r^{\text{exit}} )를 도입하여 각각 적절한 메모리 갱신과 종료 행동을 보상한다. 다양한 긴 컨텍스트 추론 작업에 대한 실험 결과는 GRU-Mem이 뛰어난 효과성과 효율성을 보였음을 입증하며, 기존의 메모리 기반 메모리 업데이트 방식인 MemAgent 대비 최대 400%의 추론 속도 향상을 달성했다.
One-sentence Summary
Researchers from ByteDance Seed, NUS, and USTC propose GRU-Mem, a gated memory agent that stabilizes long-context reasoning in LLMs via controlled updates and early exits, outperforming MemAgent with up to 400% faster inference while reducing memory bloat and redundant computation.
Key Contributions
- GRU-Mem addresses key limitations of prior recurrent memory methods like MemAgent by introducing two text-controlled gates—an update gate that prevents memory explosion by updating only on relevant chunks, and an exit gate that halts computation once sufficient evidence is gathered.
- The model is trained end-to-end via reinforcement learning with two distinct reward signals, rupdate and rexit, which explicitly guide the agent to learn when to update memory and when to terminate the loop.
- Evaluated on long-context QA tasks, GRU-Mem outperforms vanilla MemAgent while achieving up to 400% faster inference speed, demonstrating both improved accuracy and computational efficiency.
Introduction
The authors leverage recurrent memory architectures to tackle long-context reasoning, where LLMs must locate sparse evidence across millions of tokens—a challenge known as the “needle in a haystack” problem. Prior work like MemAgent processes context chunk-by-chunk but suffers from uncontrolled memory growth and no early exit, wasting computation even after sufficient evidence is found. Their main contribution, GRU-Mem, introduces two text-controlled gates—an update gate to selectively refresh memory and an exit gate to terminate processing early—trained via end-to-end reinforcement learning with distinct reward signals for each behavior. This yields both higher accuracy and up to 400% faster inference compared to vanilla MemAgent.
Method
The authors leverage a gated recurrent memory framework, GRU-Mem, to address the instability and inefficiency inherent in vanilla recurrent long-context reasoning. The core innovation lies in augmenting the memory agent with two text-controlled binary gates — an update gate (UG) and an exit gate (EG) — which dynamically regulate memory evolution and workflow termination. This design draws inspiration from gating mechanisms in GRUs, aiming to mitigate memory explosion and enable early exit when sufficient evidence is gathered.
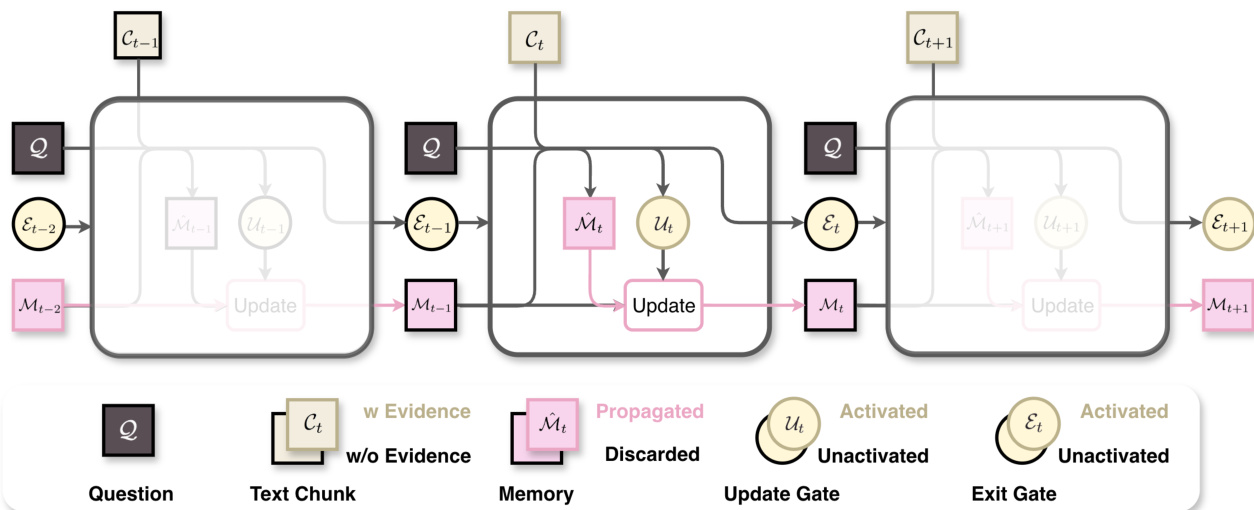
The workflow begins by splitting the long context C into T fixed-size chunks {C1,⋯,CT}. At each step t, the memory agent ϕθ, conditioned on the question Q, current chunk Ct, and previous memory Mt−1, generates three outputs: a candidate memory M^t, an update gate status Ut, and an exit gate status Et. This is formalized as:
Ut,M^t,Et=ϕθ(Q,Ct,Mt−1).The update gate determines whether to overwrite the memory: if Ut is True, Mt←M^t; otherwise, Mt←Mt−1. The exit gate controls workflow continuation: if Et is True, the loop terminates and the answer agent ψθ immediately generates the final answer A^ from Mt and Q. This selective update and conditional termination are critical for maintaining memory stability and reducing unnecessary computation.
Refer to the framework diagram, which illustrates how the update gate discards irrelevant candidate memories and how the exit gate halts processing once the last evidence is encountered, preventing memory explosion and avoiding redundant chunk processing.
To enforce this structured behavior, the memory agent is constrained to output in a predefined format. As shown in the prompt specification, the agent must first reason within tags, then emit yes or no to activate or deactivate the update gate, followed by the candidate memory within tags, and finally continue or end to control the exit gate. This structured output ensures parseability and enforces the gating logic during inference.
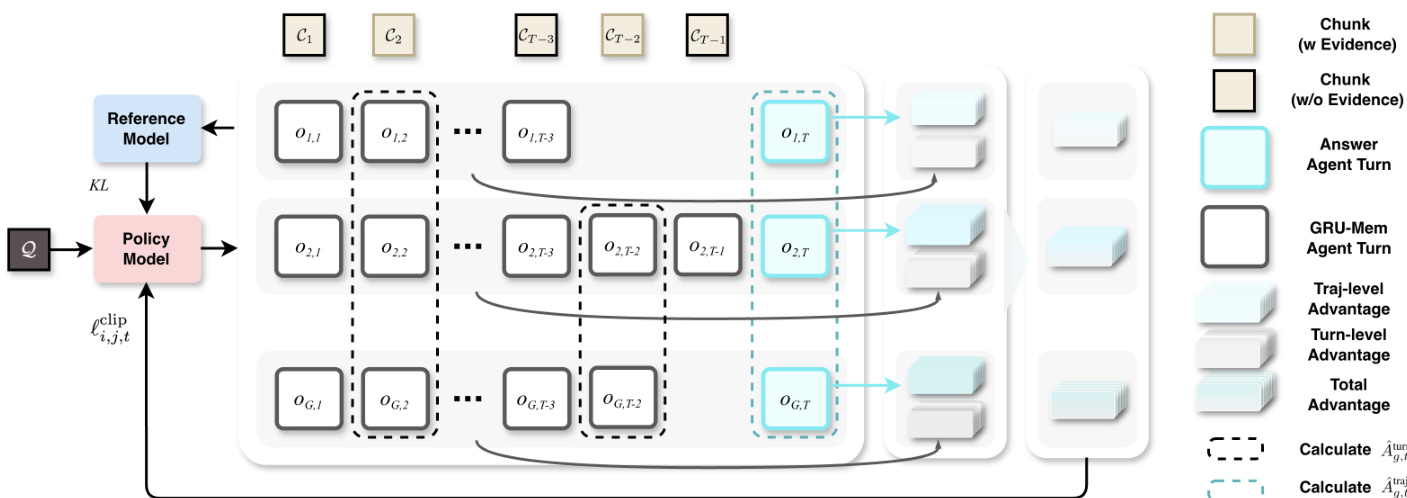
Training is conducted end-to-end via reinforcement learning, extending the Multi-Conv DAPO algorithm. The policy model is optimized using a composite loss that incorporates multiple reward signals: outcome reward for answer correctness, update reward for accurate gate activation per turn, exit reward for terminating at the correct evidence chunk, and format reward for adhering to the structured output. The advantage calculation is disentangled into trajectory-level and turn-level components, which are combined with a hyperparameter α to balance global and local optimization signals. This dual advantage structure stabilizes training by separately evaluating the impact of gate decisions across turns and trajectories.
As shown in the advantage calculation diagram, the policy model receives feedback from both the trajectory-level advantage (comparing across entire workflows) and the turn-level advantage (comparing gate decisions at each step), enabling fine-grained control over the gating behavior.

During inference, the authors provide flexibility by supporting two modes: with exit gate (w EG) and without exit gate (w/o EG). The w EG mode terminates early when Et is True, while the w/o EG mode processes all chunks regardless of gate status, accommodating tasks requiring full context traversal. This dual-mode inference ensures adaptability across diverse long-context reasoning scenarios.
Experiment
- GRU-Mem outperforms vanilla MemAgent across diverse QA and NIAH tasks, especially on out-of-distribution and multi-key benchmarks, with greater stability under long contexts and smaller model sizes.
- GRU-Mem achieves substantial inference speedups—up to 400% faster with early exit—without sacrificing accuracy, thanks to efficient memory management and adaptive termination.
- The update gate curbs memory explosion by selectively updating only evidence-relevant chunks, while the exit gate enables early termination when evidence is found early, improving flexibility in unbalanced evidence scenarios.
- Ablation studies show that α=0.9 balances update accuracy and reward stability; RL training further boosts performance, especially on harder tasks, by refining gating behaviors during training.
- Training dynamics reveal rapid learning of correct formatting and exit behavior, with response length and exit deviation stabilizing over time as the model learns to update and stop precisely.
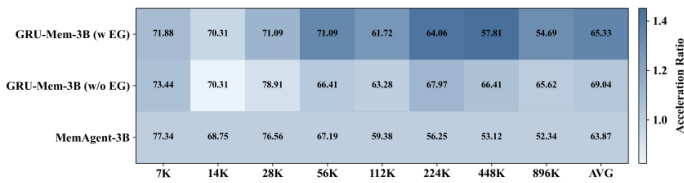
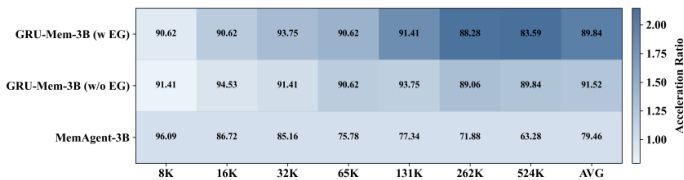
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show GRU-Mem maintains strong performance on out-of-distribution tasks while achieving up to 2x faster inference without early exit and even greater acceleration when early exit is enabled. The method’s gating mechanisms help control memory growth and enable timely termination, contributing to stable and efficient long-context reasoning.
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show GRU-Mem achieves up to 400% faster inference with early exit mechanisms while maintaining or improving task performance, especially on out-of-distribution and multi-key tasks. The gating mechanisms enable more selective memory updates and earlier termination, reducing computational overhead without sacrificing accuracy.
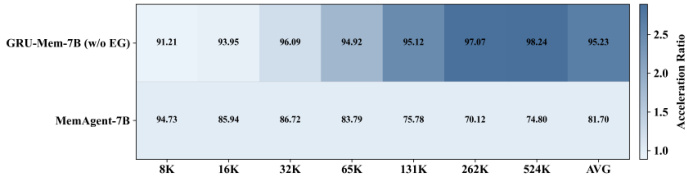
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show that GRU-Mem achieves up to 2x faster inference without sacrificing performance, particularly benefiting from its gating mechanisms that control memory updates and early exit decisions. The model maintains stable performance even as context scales, with efficiency improvements becoming more pronounced at longer lengths.
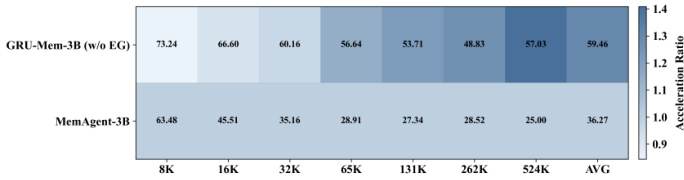
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show that GRU-Mem with early exit achieves up to 4x faster inference while maintaining or improving task performance, especially under longer contexts. The efficiency gains are more pronounced as context size increases, indicating better scalability for long-context reasoning tasks.
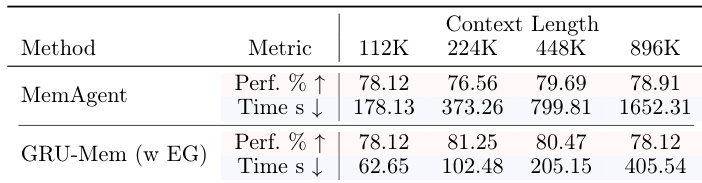
The authors use GRU-Mem to enhance memory agent performance and efficiency across varying context lengths, showing consistent gains over MemAgent in both accuracy and inference speed. Results show GRU-Mem maintains stronger performance on out-of-distribution tasks and achieves up to 400% faster inference with early exit mechanisms, while also stabilizing memory growth through gated updates. The method proves particularly effective under long-context and evidence-unbalanced scenarios, with performance improvements scaling with context size.