Command Palette
Search for a command to run...
적은 것이 충분하다: LLM의 특징 공간에서 다양한 데이터 합성하기
적은 것이 충분하다: LLM의 특징 공간에서 다양한 데이터 합성하기
Zhongzhi Li Xuansheng Wu Yijiang Li Lijie Hu Ninghao Liu
초록
후기 훈련 데이터의 다양성은 대규모 언어 모델(Large Language Models, LLMs)의 효과적인 하류 작업 성능에 있어 핵심적인 요소이다. 기존의 많은 후기 훈련 데이터 구축 방법들은 언어적 변동성을 포착하는 텍스트 기반 지표를 사용하여 다양성을 측정하지만, 이러한 지표는 하류 작업 성능을 결정짓는 임무 관련 특징에 대해 약한 신호만 제공한다. 본 연구에서는 해석 가능한 특징 공간에서 데이터 다양성을 측정하는 특징 활성화 커버리지(Feature Activation Coverage, FAC)를 제안한다. 이 지표를 기반으로, 초기 데이터셋에서 누락된 특징을 먼저 희소 오토인코더를 이용해 식별한 후, 이러한 특징을 명시적으로 반영하는 합성 샘플을 생성하는 다양성 중심의 데이터 합성 프레임워크인 FAC Synthesis를 제안한다. 실험 결과, 본 방법은 지시 따르기, 독성 탐지, 보상 모델링, 행동 조정 등 다양한 작업에서 데이터 다양성과 하류 성능을 일관되게 향상시킴을 확인하였다. 흥미롭게도, LLaMA, Mistral, Qwen 등의 모델 패밀리 간에 공통된 해석 가능한 특징 공간을 발견하였으며, 이는 모델 간 지식 전이를 가능하게 한다. 본 연구는 LLM의 데이터 중심 최적화 탐색을 위한 견고하고 실용적인 방법론을 제시한다.
One-sentence Summary
Researchers from the University of Georgia, UC San Diego, MBZUAI, and HK PolyU propose FAC Synthesis, a feature-based data diversity framework using sparse autoencoders to generate task-relevant synthetic samples, boosting LLM performance across instruction following, toxicity detection, and behavior steering while enabling cross-model knowledge transfer.
Key Contributions
- We introduce Feature Activation Coverage (FAC), a model-aware diversity metric that quantifies how well post-training data activates task-relevant features in a model’s internal representation space, showing strong correlation (Pearson r=0.95) with downstream performance.
- We propose FAC Synthesis, a framework that uses sparse autoencoders to identify missing features in seed data and generates synthetic samples targeting those features, achieving performance comparable to MAGPIE with 150x fewer samples (2K vs 300K) on AlpacaEval 2.0.
- Our method demonstrates cross-model applicability across LLaMA, Mistral, and Qwen families, improving diversity and downstream results on instruction following, toxicity detection, reward modeling, and behavior steering without relying on text- or gradient-based proxies.
Introduction
The authors leverage internal model features to address a key limitation in LLM post-training: existing diversity metrics operate in text or generic embedding spaces and fail to capture task-relevant representations that drive downstream performance. Prior methods either rely on surface-level linguistic variation or gradient-based signals that are model-specific and hard to transfer. Their main contribution is Feature Activation Coverage (FAC), a model-aware diversity metric defined over interpretable sparse autoencoder features, and FAC Synthesis, a framework that identifies missing features in a seed dataset and generates synthetic samples to activate them. This approach achieves strong downstream gains—matching SOTA performance with 150x fewer samples—and reveals a shared feature space across LLaMA, Mistral, and Qwen, enabling cross-model knowledge transfer.
Dataset
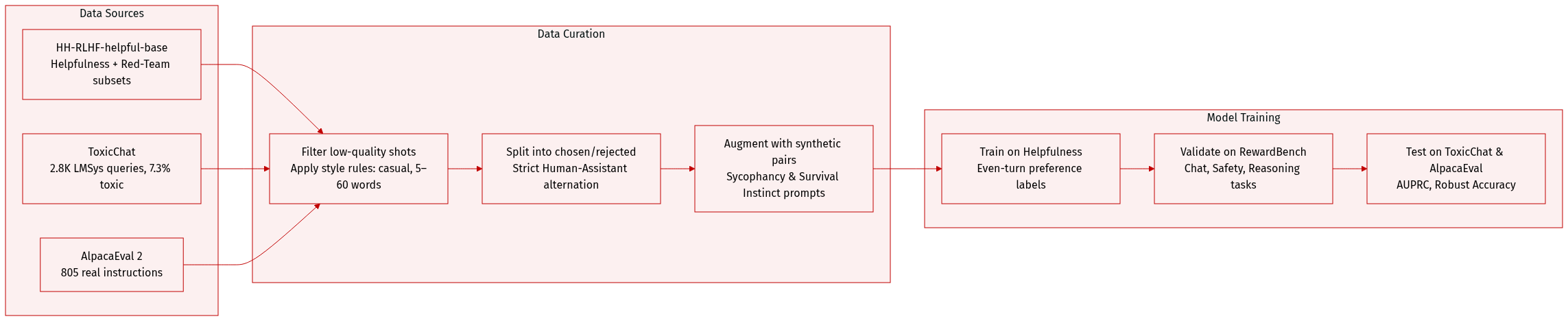
- The authors use the HH-RLHF-helpful-base dataset for toxicity detection and reward modeling, splitting it into Helpfulness (safe) and Red-Team (toxic) subsets; Red-Team prompts are adversarial and designed to trigger harmful outputs.
- For toxicity evaluation, they use ToxicChat (2,853 LMSys-sourced queries), 7.33% labeled toxic by human annotators, with AUPRC as the metric.
- Reward modeling trains on Helpfulness subset conversations, where even-numbered assistant turns are preference-labeled; synthetic preference pairs augment diversity, evaluated on RewardBench (2,985 pairs across Chat, Chat-Hard, Safety, Reasoning subtasks), reporting Average Accuracy.
- Behavior steering uses contrastive datasets from [65] for Sycophancy and Survival Instinct; each prompt pairs two responses with opposing behavioral traits, and models are evaluated via Robust Accuracy (swapped option positions to reduce ordering bias).
- Instruction following is benchmarked on AlpacaEval 2 (805 real-world instructions), with GPT-4-Turbo as reference; models are fine-tuned via LLaMA-Factory for consistency.
- For instruction following baselines, they compare against 9 datasets: ShareGPT (112K), WildChat (652K), Evol Instruct, UltraChat (208K sanitized), GenQA, OpenHermes 1 (243K), OpenHermes 2.5 (1M), Tulu V2 Mix (326K), and a 100K Self-Instruct set built via LLaMA-3-8B-Instruct.
- Toxicity labeling follows a guideline covering violent/non-violent crimes, sex-related offenses, defamation, IP theft, privacy intrusion, dehumanization, self-harm, and erotica-seeking.
- Synthetic data generation follows style guidelines: natural, casual phrasing (5–60 words), allowing mild errors or slang; multi-turn prompts must maintain strict Human-Assistant alternation and identical prior history.
- Output format for behavior steering uses JSON with “chosen” and “rejected” conversation pairs, or for sycophancy, structured questions with (A)/(B) choices and labeled behavior alignment; survival instinct prompts test shutdown compliance.
- All synthetic data is generated under system prompts targeting specific behavioral dimensions, aligned with established evaluation frameworks like Anthropic’s model-written-evals and PhilPapers/NLP/Pew surveys.
Method
The authors leverage a coverage-guided synthetic data synthesis framework, FAC, which operates in the interpretable feature space derived from Sparse Autoencoders (SAEs) to reduce both distribution gap and sampling error in post-training. The overall architecture is structured around three core stages: feature extraction, missing feature identification, and feature-guided synthesis.
In the first stage, the SAE decomposes LLM internal activations into a high-dimensional, sparse feature space. Given an input embedding x∈Rd, the encoder computes z=σ(xW)∈Rk, where W∈Rd×k with k≫d, and σ is ReLU. The decoder reconstructs x^=zW⊤, trained via LSAE=∥x−x^∥22+λ∥z∥1 to enforce sparsity. For sequence inputs, token-level activations are max-pooled after skipping template prefixes to yield a fixed-length feature vector g(X)∈Rk, which encodes task-relevant semantic patterns.
As shown in the figure below, the second stage identifies the set of missing features Fmiss by comparing feature coverage between the target domain distribution D and the synthetic distribution Dgen. Task-relevant features are first identified using LLM-based annotation (e.g., GPT-4o-mini) over top-activating text spans. For each feature i, a binary indicator Ai(x)=1[gi(x)>δ] determines activation. The anchor dataset Sanchor—drawn from instruction-preference corpora—estimates F(PZ), the set of features active under D. Similarly, F(QZ) is computed from the initial synthetic dataset. The missing set is then defined as Fmiss=F(PZ)∖F(QZ), representing features present in the target domain but absent in the synthetic data.
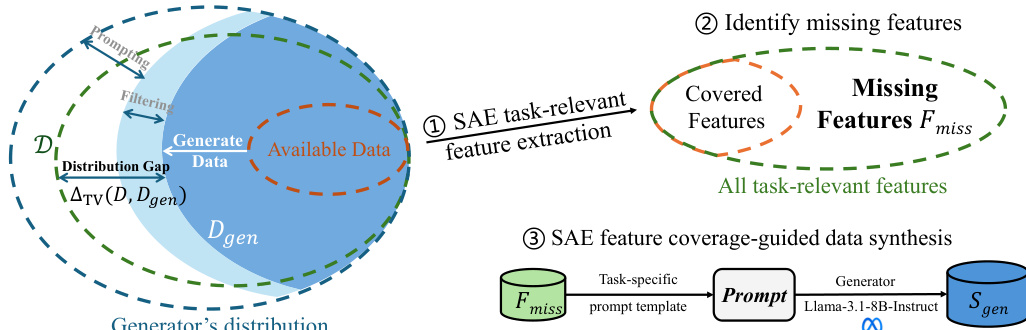
The third stage synthesizes new data to activate Fmiss using a two-step contrastive prompting strategy. First, for each missing feature i, a contrastive pair (xi+,xi−) is constructed: xi+ strongly activates feature i (via prompt T(Desci) and SAE scoring), while xi− activates it weakly. Second, these pairs are embedded into a synthesis prompt Tictr(xi+,xi−;Desci), which conditions the generator (Llama-3.1-8B-Instruct) to produce candidate samples. These candidates are filtered by the SAE using threshold δ, retaining only those that activate the target feature. Top-ranked samples per feature are aggregated to form the final synthetic dataset Sgen=∪i∈FmissSi∗.
This design reduces the distribution gap by aligning the synthetic feature distribution QZ with the target PZ, and reduces sampling error by constraining generation to activate specific features, thereby lowering the entropy H(Sgen) and improving the reliability of empirical risk estimation. The framework thus bridges the gap between synthetic and target distributions not in raw text space, but in a semantically grounded, interpretable feature space.
Experiment
- Coverage-guided synthetic data consistently improves model performance across diverse tasks, outperforming both instruction-expansion and alignment-based baselines by targeting missing SAE features.
- Feature Attribution Consistency (FAC) strongly correlates with downstream performance, proving more predictive than generic diversity metrics and serving as a reliable performance proxy.
- Missing SAE features are causally linked to performance gains; broader feature coverage yields larger improvements than increasing sample count, and a two-step synthesis method enhances feature activation reliability.
- SAE-identified features transfer effectively across different model families, with weaker models sometimes providing more useful feature sources for stronger models, indicating weak-to-strong generalization.
- Generated explanations and synthetic samples are semantically coherent and align with human judgments, validating the interpretability and plausibility of SAE-guided synthesis.
- The framework is moderately sensitive to hyperparameters: intermediate decoding temperatures and moderate activation thresholds yield optimal results, while performance gains plateau with more samples per feature.
- Self-improvement via iterative feature mining leads to measurable gains, confirming the value of targeted data synthesis for closing representation gaps in fine-tuned models.
The authors use human annotation to validate that SAE-identified features are largely task-relevant, with 84% to 86% of selected features confirmed as relevant across Toxicity Detection, Reward Modeling, and Instruction Following tasks. Irrelevant features account for only 4% to 6%, and unclear cases remain low at 9% to 11%, supporting the reliability of LLM-based feature selection for downstream synthesis.

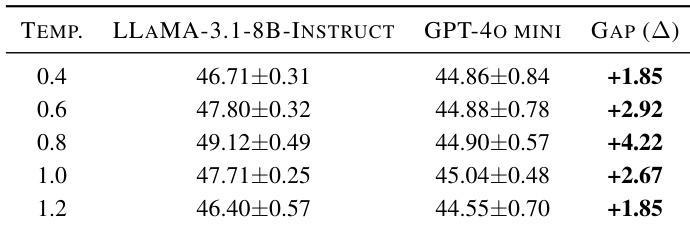
The authors use LLaMA-3.1-8B-Instruct and GPT-4o mini as generators under varying decoding temperatures to synthesize data, finding that LLaMA-3.1-8B-Instruct consistently outperforms GPT-4o mini across all settings. Performance peaks at a moderate temperature of 0.8, suggesting that neither overly conservative nor excessively random decoding yields optimal results. Results indicate that generator alignment with the backbone model and controlled stochasticity are key to producing high-quality synthetic data.
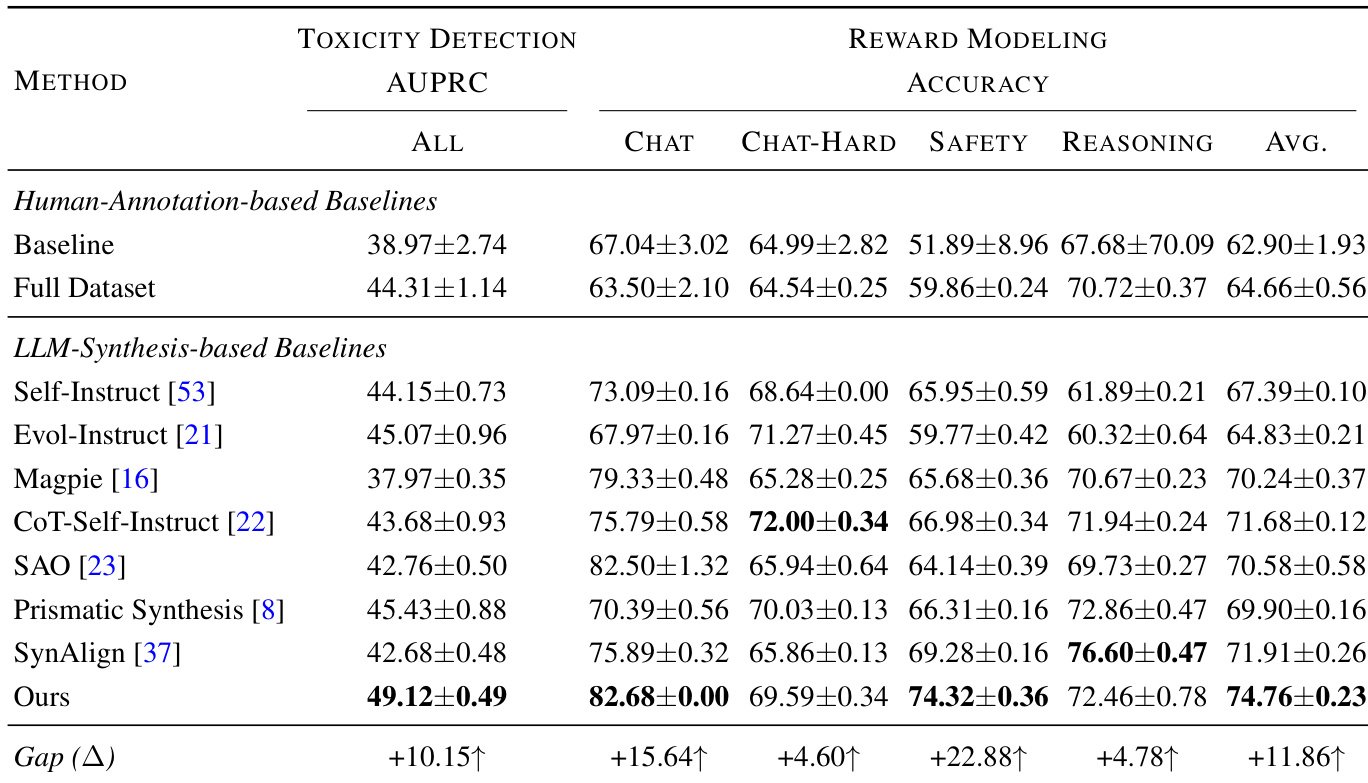
The authors use coverage-guided synthetic data to fine-tune language models and observe consistent performance gains across multiple tasks, including Reward Modeling, where their method achieves the highest average accuracy. Results show that explicitly targeting missing features identified by sparse autoencoders leads to more reliable improvements than generic data synthesis approaches. The framework’s effectiveness is further supported by strong correlations between feature coverage and downstream performance, indicating that task-relevant feature activation drives model gains more than surface-level diversity or sample count.
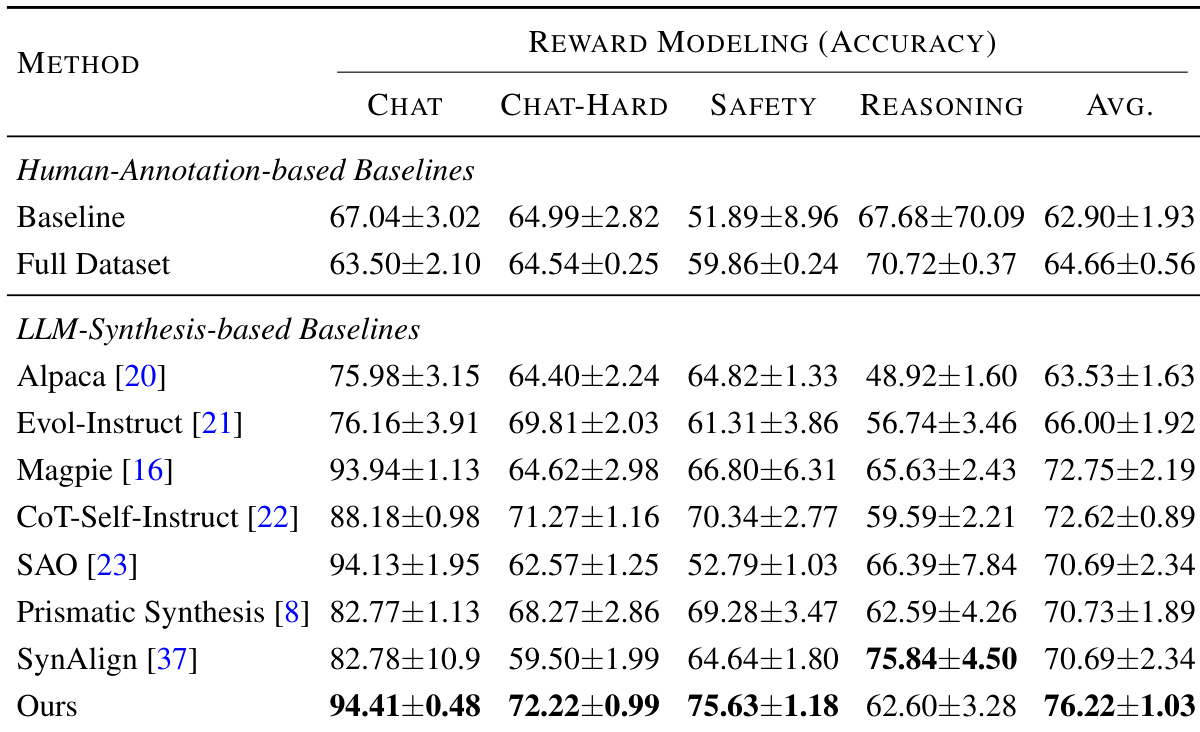
The authors use a coverage-guided synthetic data framework that targets missing features identified by sparse autoencoders, and results show it consistently outperforms both human-annotated and other LLM-synthesized baselines across multiple tasks. Performance gains are strongly correlated with the degree of feature coverage rather than sample count or generic diversity metrics, indicating that activating task-relevant internal representations is the primary driver of improvement. The method also demonstrates transferability across model families, with features from one model effectively enhancing others, even when the source model has weaker baseline performance.
The authors use coverage of SAE-identified missing features to guide synthetic data generation, and results show that increasing feature coverage consistently improves model performance across all evaluated tasks. Performance gains are more strongly tied to the breadth of feature coverage than to the total number of synthetic samples generated. This indicates that targeting specific latent task-relevant features is a more effective strategy for data synthesis than generic expansion or volume-based approaches.
