Command Palette
Search for a command to run...
LLM을 초월하여 검색 증강 모델이 얼마나 많은 추론을 추가하는가? 하이브리드 지식에 대한 다단계 추론을 위한 벤치마킹 프레임워크
LLM을 초월하여 검색 증강 모델이 얼마나 많은 추론을 추가하는가? 하이브리드 지식에 대한 다단계 추론을 위한 벤치마킹 프레임워크
Junhong Lin Bing Zhang Song Wang Ziyan Liu Dan Gutfreund Julian Shun Yada Zhu
초록
대규모 언어 모델(Large language models, LLMs)은 최신 정보가 요구되거나 다단계 추론이 필요한 지식 집약형 질문에 여전히 어려움을 겪고 있다. 지속적인 사전 훈련에 비해 비용이 더 적게 드는 하이브리드 외부 지식(예: 비구조화된 텍스트와 구조화된 지식 그래프)을 LLM에 통합하는 것은 이러한 문제를 해결할 수 있는 유망한 대안이다. 이에 따라 모델의 검색 및 추론 능력을 신뢰할 수 있게 평가하는 것이 더욱 중요해지고 있다. 그러나 기존의 많은 벤치마크는 LLM의 사전 훈련 데이터와 점점 더 많은 중복을 보이며, 이로 인해 정답이나 지원 지식이 이미 모델 파라미터에 인코딩되어 있어, 진정한 검색 및 추론 능력과 파라미터 기반의 기억 능력을 구분하기 어려운 문제가 발생한다. 우리는 하이브리드 지식 기반의 검색 집약형 다단계 추론을 평가하기 위한 프레임워크인 HybridRAG-Bench를 제안한다. HybridRAG-Bench는 arXiv에 게시된 최신 과학 논문에서 자동으로 추출한 비구조화된 텍스트와 구조화된 지식 그래프 표현을 결합하고, 명시적인 추론 경로에 기반한 지식 집약형 질문-답변 쌍을 생성한다. 이 프레임워크는 유연한 도메인 및 시기 선택 기능을 지원하여, 모델과 지식의 진화에 따라 오염 여부를 고려한 사용자 정의 평가가 가능하다. 인공지능, 거버넌스 및 정책, 생물정보학 세 가지 도메인에서 수행한 실험을 통해 HybridRAG-Bench가 진정한 검색 및 추론을 보상하고 파라미터 기반 기억을 유도하지 않음을 입증하며, 하이브리드 지식 증강 추론 시스템을 평가하기 위한 체계적인 테스트베드를 제공한다. 코드와 데이터는 github.com/junhongmit/HybridRAG-Bench에서 공개한다.
One-sentence Summary
Researchers from MIT, IBM, and UCF introduce HYBRIDRAG-BENCH, a contamination-aware framework that evaluates LLMs’ multi-hop reasoning over hybrid knowledge by coupling arXiv-derived text and knowledge graphs, enabling domain-specific, time-bound assessments that distinguish true retrieval from parametric recall.
Key Contributions
- HYBRIDRAG-BENCH introduces a contamination-aware benchmark framework that constructs multi-hop reasoning tasks from recent arXiv literature, ensuring questions rely on external retrieval rather than parametric recall by using time-framed, evolving scientific corpora.
- The framework automatically generates hybrid knowledge environments combining unstructured text and structured knowledge graphs, producing diverse question types grounded in explicit reasoning paths to evaluate genuine retrieval and reasoning across domains like AI, policy, and bioinformatics.
- Experiments show HYBRIDRAG-BENCH effectively discriminates between models that perform true retrieval-based reasoning and those relying on pretraining memorization, offering a scalable, customizable testbed for evaluating hybrid knowledge-augmented systems.
Introduction
The authors leverage retrieval-augmented generation (RAG) and structured knowledge graphs to tackle knowledge-intensive, multi-hop reasoning tasks where large language models (LLMs) often fail due to outdated knowledge or insufficient reasoning. Prior benchmarks suffer from pretraining contamination—where models answer correctly by memorization rather than retrieval—making it hard to assess whether systems truly reason or just recall. To address this, they introduce HYBRIDRAG-BENCH, a framework that automatically constructs contamination-aware benchmarks from recent arXiv papers, coupling unstructured text with structured knowledge graphs and generating questions tied to explicit reasoning paths. Their method enables fair, scalable evaluation across domains and timeframes, distinguishing genuine retrieval and multi-hop reasoning from parametric recall.
Dataset

The authors use HYBRIDRAG-BENCH, a dynamically constructed, domain-specific benchmark for evaluating retrieval-augmented and knowledge-grounded LLMs. Key details:
-
Dataset Composition and Sources
- Built from arXiv papers collected per domain using subject categories (e.g., cs.AI) and optional keywords.
- Each domain has its own evolving knowledge graph derived from documents within a user-specified time window, postdating LLM pretraining cutoffs to prevent parametric memorization.
- No shared entities or relations across domains.
-
Key Subset Details
- Question Types: Single-hop, single-hop with conditions, multi-hop, difficult multi-hop (via high-degree entities), counterfactual, and open-ended.
- Size: Varies by domain; distribution per type shown in Table 2.
- Filtering: Questions must be answerable solely from hybrid context (KG path + supporting text), pass LLM-as-a-judge faithfulness checks, and avoid document-local references or ambiguity.
- Metadata: Includes paper title, authors, categories, and timestamps; text is segmented by section (abstract, methods, etc.).
-
Data Usage in Model Training/Evaluation
- Questions are generated by conditioning an LLM on: (1) a sampled KG reasoning path, (2) associated textual evidence, and (3) in-context examples.
- Each QA pair is tied to a specific knowledge graph snapshot at time t_i, ensuring temporal isolation.
- Used exclusively for evaluation—not training—of LLMs to measure ability to integrate structured and unstructured evidence.
-
Processing and Cropping Strategy
- Reasoning paths are sampled from the domain’s knowledge graph; textual spans are retrieved for each entity/relation.
- Questions are synthesized to obscure intermediate nodes (in multi-hop cases) or include counterfactual perturbations.
- Final QA pairs undergo normalization (lowercasing, punctuation) and multi-stage filtering for clarity, faithfulness, and independence.
Method
The authors leverage a four-stage automated pipeline to construct HYBRIDRAG-BENCH, a benchmark designed to evaluate retrieval-augmented reasoning over hybrid knowledge sources. The framework begins with user-specified parameters—such as time frame, topic area, and question types—which guide the collection of a time-framed arXiv corpus. This corpus serves as the foundational data source for both unstructured text chunks and structured knowledge graphs.
Refer to the framework diagram for an overview of the pipeline’s architecture. The first stage, Time-Framed Corpus Collection, ingests documents from arXiv based on user constraints. These documents are then processed in parallel to generate two complementary knowledge representations: unstructured text chunks and a structured knowledge graph. The knowledge graph is constructed using EvoKG, a document-driven framework that extracts entities and relations via large language models. Entity extraction is followed by context-aware alignment, which resolves lexical variation and semantic ambiguity by matching new mentions against existing nodes using joint embeddings of type, name, and description. If no sufficiently similar node exists, a new entity is created; otherwise, the mention is merged, preserving provenance.
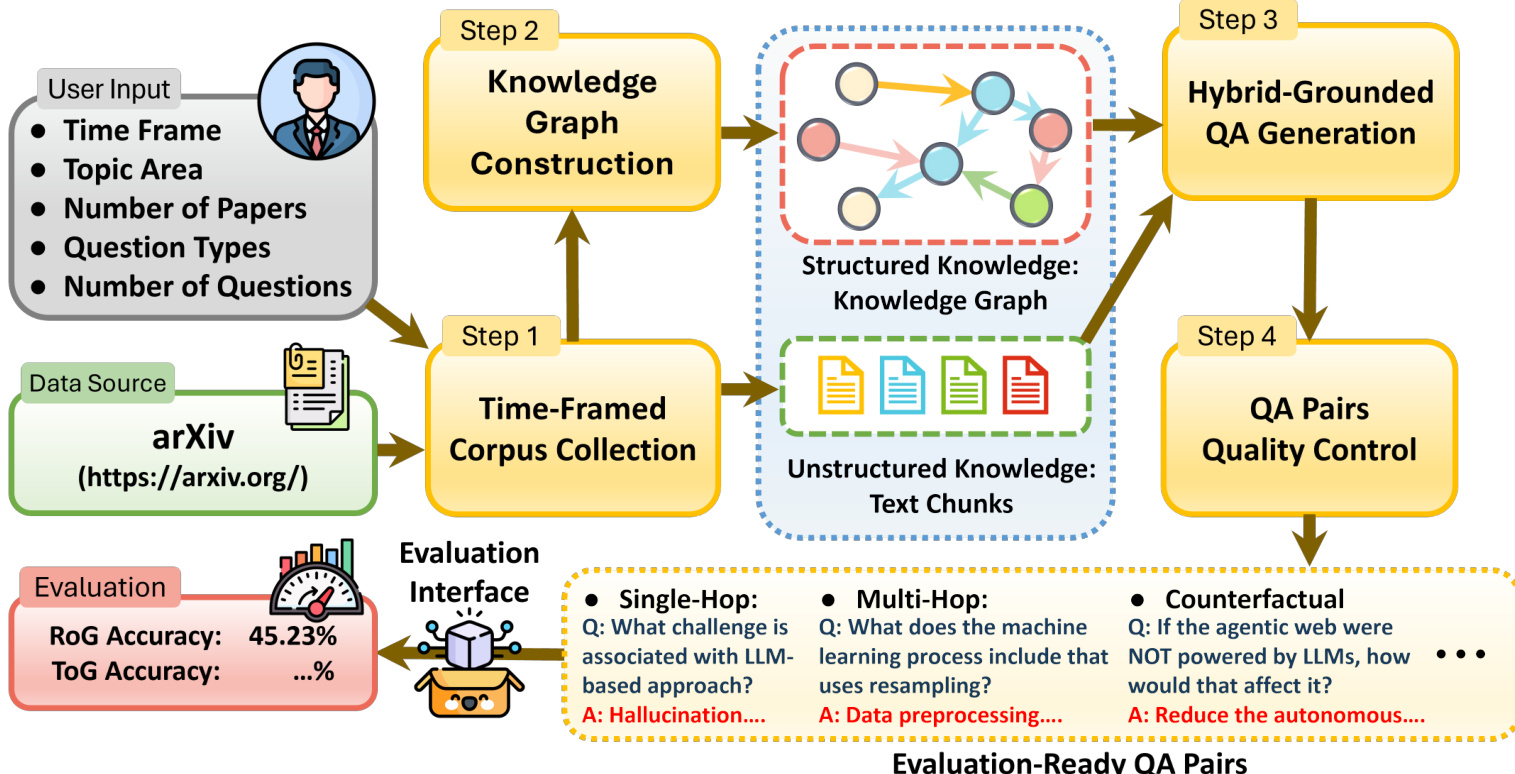
Relation normalization follows, where extracted relations are mapped to a domain-specific schema and linked to supporting textual evidence. The graph retains multiple candidate relations when supported by the corpus, annotated with confidence scores derived from frequency, recency, and textual support—thereby preserving the uncertainty and variation inherent in scientific literature.
In the third stage, Hybrid-Grounded QA Generation, the system synthesizes diverse question-answer pairs grounded in explicit reasoning paths that traverse both the knowledge graph and retrieved text chunks. These questions span single-hop, multi-hop, conditional, counterfactual, and open-ended reasoning types. The final stage, QA Pairs Quality Control, applies automated filters to ensure answerability, independence from document phrasing, and non-redundancy, yielding evaluation-ready QA pairs.
The resulting benchmark enables controlled, reproducible evaluation of RAG and KG-RAG systems by providing both structured and unstructured knowledge sources that reflect real-world scientific discourse. The model’s prediction is formally defined as a^=f(q,Gtq(m),Dtq(m)), where the model f reasons over the knowledge graph snapshot Gtq(m) and retrieved documents Dtq(m) available at query time tq.
Experiment
- HYBRIDRAG-Bench poses persistent challenges across LLM scales, confirming questions cannot be reliably answered by parametric knowledge alone and require external retrieval and reasoning.
- External retrieval is essential: text-based RAG significantly improves performance over LLM-only methods, while naive KG injection often degrades results due to noise.
- Structured knowledge adds complementary value: hybrid KG-RAG methods consistently outperform text-only RAG, especially on relational, multi-hop, and disambiguation tasks.
- The benchmark effectively discriminates between reasoning strategies: performance varies meaningfully by question type, with structured methods excelling on multi-hop and counterfactual queries, while text retrieval dominates open-ended questions.
- KG construction is effective and scalable: the pipeline recovers ~71% of verifiable facts and scales near-linearly in cost and latency, ensuring practical deployment without performance bottlenecks.
The authors evaluate their KG construction pipeline against prior methods and find that EvoKG captures significantly more verifiable facts from source documents, achieving a 71.36% recovery rate compared to 66.46% for KGen and lower rates for OpenIE and GraphRAG. This indicates that the knowledge graphs used in HybridRAG-Bench are robust and not a limiting factor in the benchmark’s difficulty. Results confirm that the challenge stems from retrieval and reasoning demands rather than incomplete or inaccurate knowledge extraction.

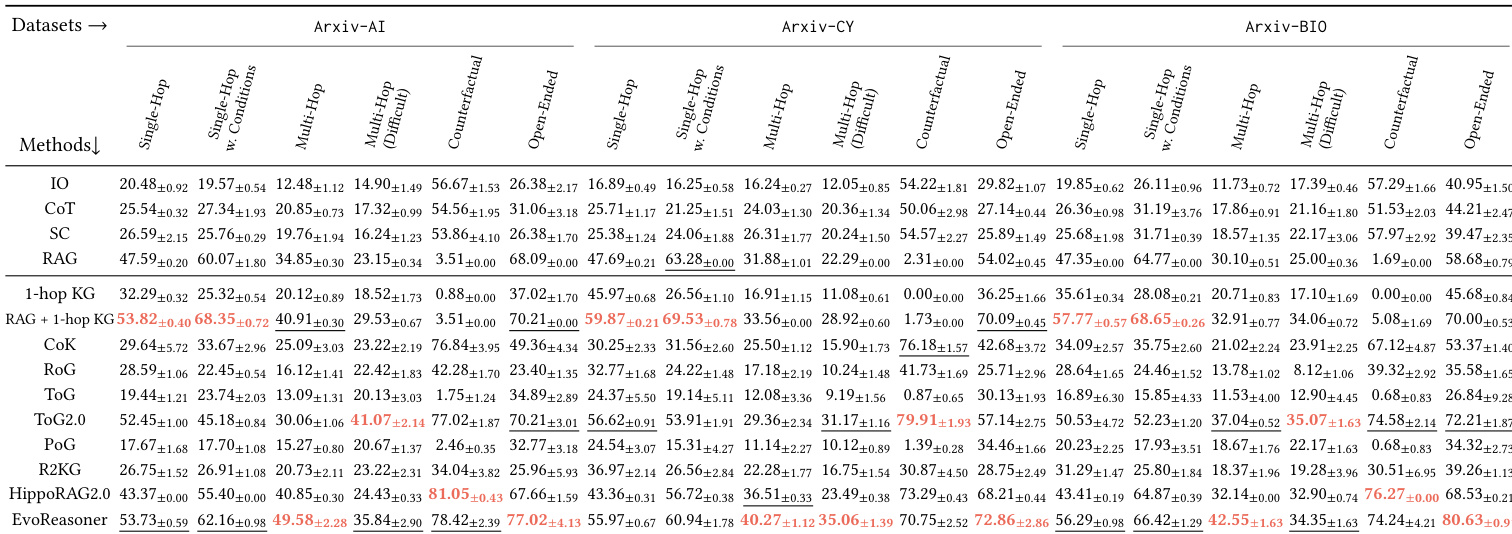
The authors use HybridRAG-Bench to evaluate how different retrieval and reasoning strategies perform across domain-specific tasks, finding that LLM-only approaches consistently underperform regardless of model scale. Results show that combining structured knowledge graphs with text-based retrieval yields the strongest performance, especially on multi-hop and counterfactual questions, indicating that effective reasoning requires more than just access to external information. The benchmark meaningfully distinguishes between methods by question type, revealing that hybrid approaches outperform both pure text retrieval and naive graph augmentation.
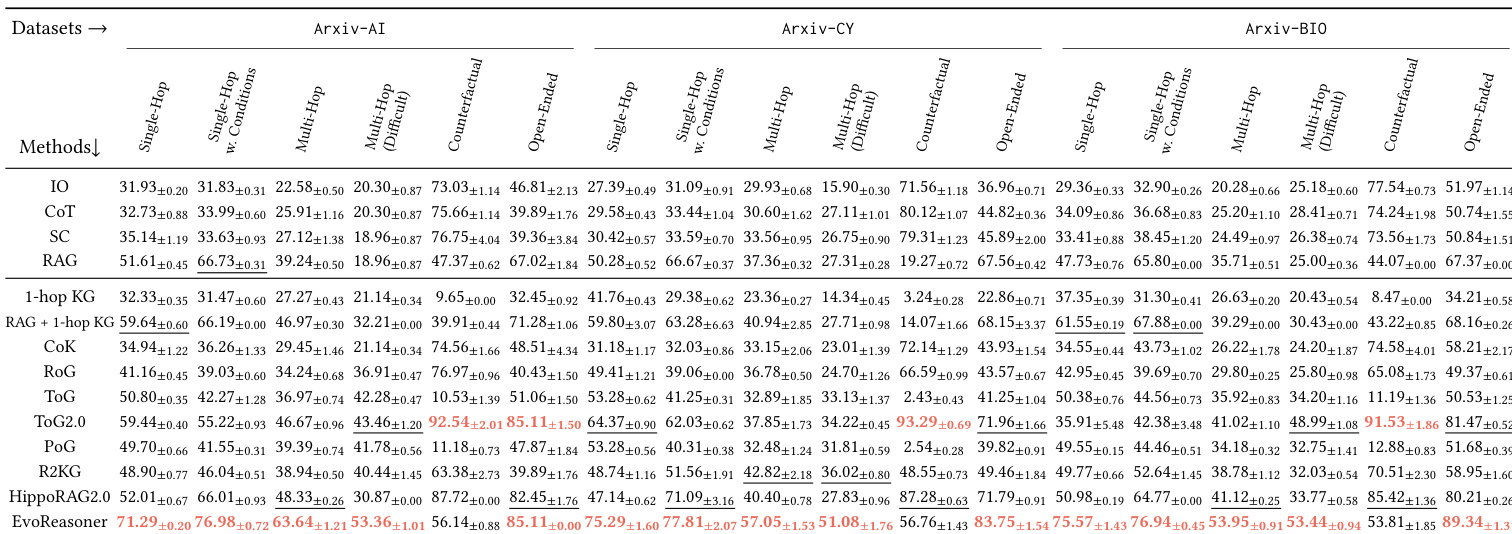
The authors use HybridRAG-Bench to evaluate how different retrieval and reasoning strategies perform across domain-specific tasks, finding that LLM-only approaches consistently underperform regardless of model scale. Results show that combining structured knowledge graphs with text-based retrieval yields the strongest performance, especially on multi-hop and counterfactual questions, indicating that effective reasoning requires more than just access to external information. The benchmark meaningfully distinguishes between methods by question type, revealing that hybrid approaches outperform both pure text retrieval and naive graph augmentation.
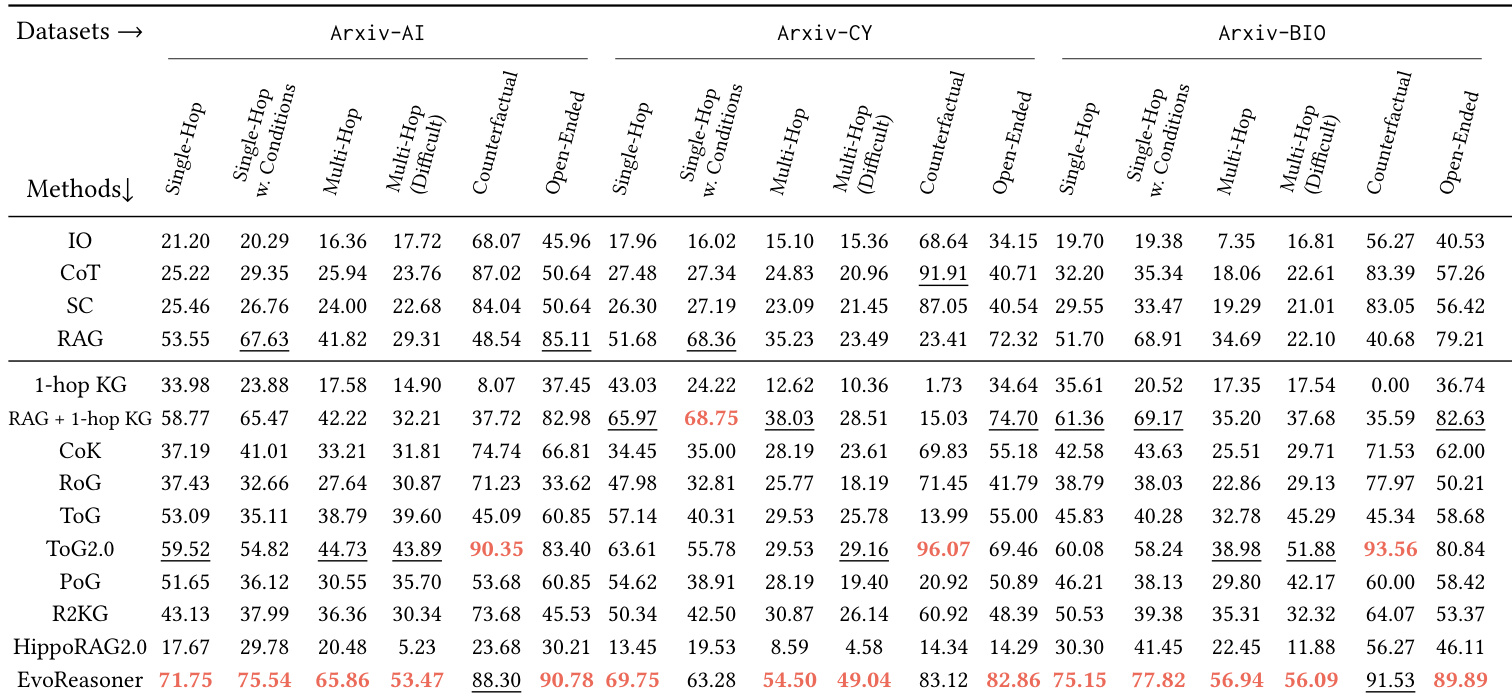
The authors use HybridRAG-Bench to evaluate how different LLMs and retrieval strategies perform on knowledge-intensive reasoning tasks across three domains. Results show that LLM-only approaches perform poorly regardless of model scale, while hybrid methods combining structured knowledge graphs with text retrieval consistently outperform text-only RAG, especially on multi-hop and counterfactual questions. The benchmark effectively discriminates between reasoning strategies, revealing that success depends more on how knowledge is integrated than on model size alone.
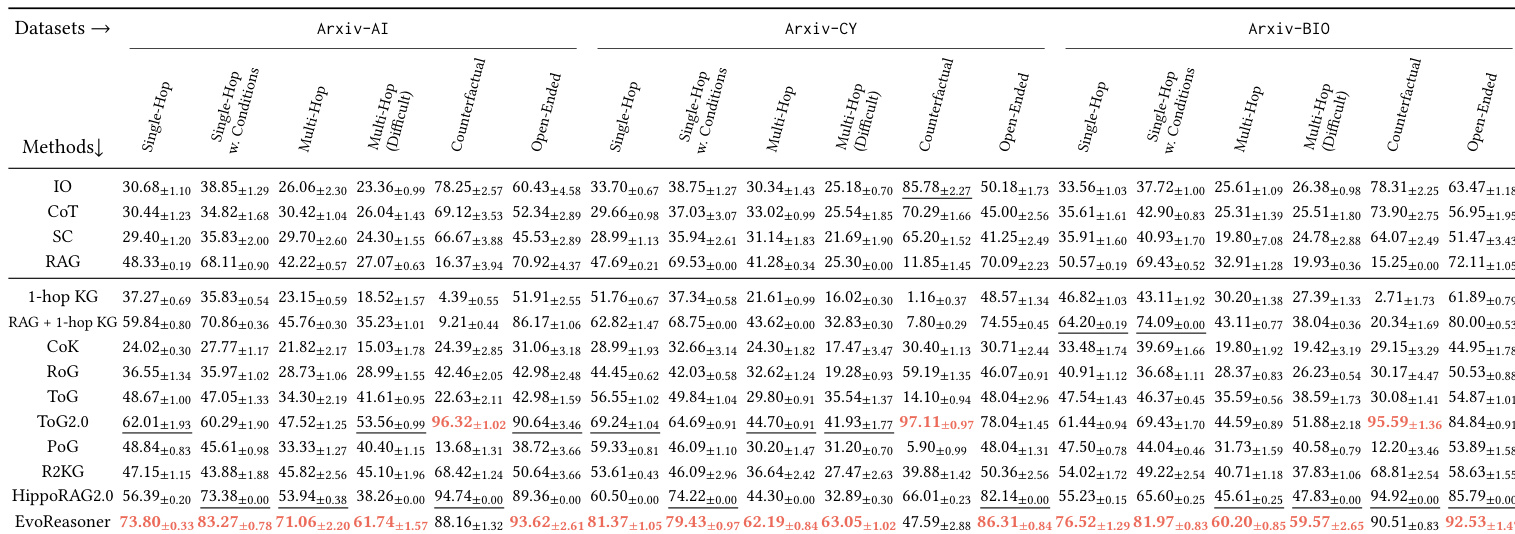
The authors use HybridRAG-Bench to evaluate how different retrieval and reasoning strategies perform across domain-specific tasks, finding that LLM-only approaches consistently underperform regardless of model scale. Results show that combining structured knowledge graphs with text-based retrieval yields the strongest performance, especially on multi-hop and counterfactual questions, indicating that effective reasoning requires more than just access to external information. The benchmark meaningfully distinguishes between methods by question type, revealing that hybrid approaches outperform text-only or naive graph augmentation strategies across all domains.