Command Palette
Search for a command to run...
자율 수학 연구로 나아가기
자율 수학 연구로 나아가기
초록
최근 기초 모델의 발전으로 인해 국제 수학 올림피아드에서 금메달 수준의 성과를 달성할 수 있는 추론 시스템이 등장하였다. 그러나 대회 수준의 문제 해결에서 전문 연구로의 전환은 방대한 문헌을 탐색하고 장기적인 증명 체계를 구성하는 것을 필요로 한다. 본 연구에서는 자연어 기반으로 해결책을 반복적으로 생성하고 검증하며 개선하는 엔드투엔드 방식의 수학 연구 에이전트인 Aletheia를 소개한다. 구체적으로 Aletheia는 도전적인 추론 문제 해결을 위해 고도화된 Gemini Deep Think 모델을 기반으로 하며, 올림피아드 수준을 넘어서는 새로운 추론 시점 스케일링 법칙(inference-time scaling law)과 수학 연구의 복잡성을 다루기 위한 집중적인 도구 활용을 결합하고 있다. 우리는 Aletheia가 올림피아드 문제에서 박사 수준의 연습 문제까지의 능력을 입증함과 동시에, 인공지능 지원 수학 연구 분야에서 여러 가지 독보적인 성과를 달성했다는 점을 보여준다: (a) 수학적 기하학에서 ‘에이전웨이트(eigenweights)’라 불리는 특정 구조 상수를 계산하는 과정에서 인간의 개입 없이 AI에 의해 생성된 연구 논문(Feng26); (b) 상호작용 입자 시스템인 ‘독립 집합(independent sets)’의 경계를 증명하는 과정에서 인간과 AI의 협업을 보여주는 연구 논문(LeeSeo26); (c) Bloom의 에르되시 추측 데이터베이스에 등재된 700개의 미해결 문제에 대한 광범위한 반자율적 평가(Feng 등, 2026a), 이 과정에서 네 가지 미해결 문제에 대해 자율적으로 해결책을 제시하였다. 인공지능과 수학 분야의 발전을 보다 명확히 이해할 수 있도록 대중이 접근할 수 있도록 하기 위해, 우리는 AI 지원 연구 결과의 자율성과 창의성 수준을 정량화하는 표준 체계를 제안한다. 본 연구는 수학 분야에서 인간과 인공지능의 협업에 대한 성찰로 마무리된다.
One-sentence Summary
Google DeepMind researchers introduce Aletheia, a math research agent powered by Gemini Deep Think and novel inference scaling, enabling end-to-end natural language proof generation, verification, and revision; it autonomously solved open Erdős problems, generated research papers, and demonstrated human-AI collaboration in advanced mathematical discovery.
Key Contributions
- Aletheia introduces an autonomous math research agent that iteratively generates, verifies, and revises proofs in natural language, addressing the gap between competition-level problem solving and open-ended research by integrating advanced reasoning, inference-time scaling, and tool use like web search.
- The system achieves state-of-the-art performance on Olympiad benchmarks (95.1% on IMO-ProofBench) and PhD-level exercises, and demonstrates real research impact by autonomously solving four Erdős open problems and producing a fully AI-generated paper on eigenweights in arithmetic geometry.
- Aletheia enables human-AI collaboration in proving bounds on independent sets and contributes to multiple research papers, while the authors propose a standardized taxonomy to classify AI autonomy and novelty in mathematical results to improve transparency and public understanding.
Introduction
The authors leverage advances in large language models to bridge the gap between competition-level math problem solving and professional mathematical research, where problems require synthesizing vast literature and constructing long-horizon proofs—tasks that prior models often fail at due to hallucinations and shallow domain understanding. They introduce Aletheia, a math research agent that iteratively generates, verifies, and revises solutions using an enhanced Gemini Deep Think model, a novel inference-time scaling law, and tool integration like web search. Aletheia demonstrates capability across Olympiad, PhD-level, and open research problems, including fully autonomous derivation of structure constants in arithmetic geometry, human-AI co-authored proofs on particle systems, and semi-autonomous resolution of four Erdős conjectures—marking the first steps toward scalable AI-assisted mathematical discovery.
Method
The authors leverage a multi-agent orchestration framework, internally codenamed Aletheia, to address the challenges of autonomous mathematics research. This framework is built atop Gemini Deep Think and is designed to overcome the limitations of large language models in handling advanced, research-grade mathematical problems, which often require deep domain knowledge and rigorous validation beyond the scope of standard contest problems.
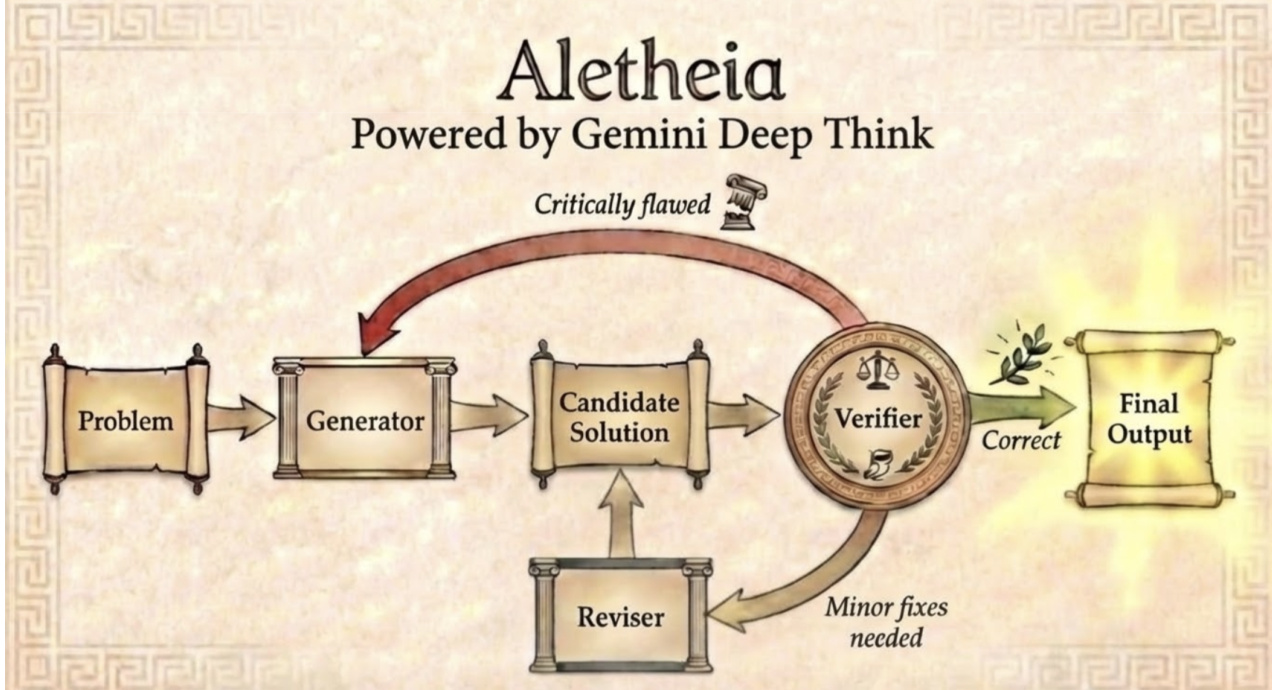
The core architecture of Aletheia consists of three tightly coupled subagents: a Generator, a Verifier, and a Reviser. The Generator is responsible for producing initial candidate solutions to a given mathematical problem. These candidates are then passed to the Verifier, which critically evaluates their correctness and logical soundness. If the Verifier identifies flaws, it routes the candidate back to the Reviser, which performs targeted refinements or minor fixes. This iterative loop continues until the Verifier approves a solution or a predefined attempt limit is reached. The entire process is designed to emulate the human mathematician’s cycle of conjecture, critique, and revision.
Refer to the framework diagram, which illustrates the flow of information and control between the subagents. The Generator initiates the process by receiving the problem statement and producing a candidate solution. The Verifier then assesses this solution, either approving it for final output or flagging it for revision. The Reviser, upon receiving feedback, modifies the candidate and resubmits it to the Generator for re-evaluation. This closed-loop design ensures that solutions are not only generated but also rigorously validated and refined, significantly enhancing the reliability of the output.
Experiment
- Gemini Deep Think achieved IMO gold by solving five of six 2025 problems, demonstrating strong performance under inference scaling, with accuracy improving significantly before plateauing.
- A more efficient model (Jan 2026) reduced compute needs by 100x while maintaining or improving performance, solving difficult IMO problems including 2024 P3 and P5 at high scales, though knowledge cutoff raises potential exposure concerns.
- On FutureMath (Ph.D.-level math), performance saturated at lower accuracy than IMO, with expert feedback highlighting persistent hallucinations and errors that limit research utility despite scaling.
- Tool use (especially internet search) substantially reduced citation hallucinations in Aletheia, though subtler misrepresentations of real papers persisted; Python integration offered minimal gains, suggesting baseline math proficiency is already high.
- In testing 700 Erdős problems, Aletheia generated 212 candidate solutions; 63 were technically correct, but only 13 addressed the intended problem meaningfully — 4 of these represented autonomous or partially autonomous novel solutions.
- Ablation studies showed Gemini Deep Think (IMO scale) solved 8 of 13 Erdős problems Aletheia solved, using twice the compute, and partially reproduced results from research papers, indicating Aletheia’s tool-augmented approach adds value beyond raw scaling.
- AI remains prone to misinterpreting ambiguous problems, favoring trivial solutions, and hallucinating or misquoting references — even with tools — revealing qualitative gaps in creativity, depth, and reliability compared to human researchers.
- Most AI-generated math results are brief and elementary; success often stems from technical manipulation or retrieval rather than conceptual innovation, and human oversight remains critical for novelty and rigor.
- When prompted to adapt solutions to IMO standards, the model successfully rewrote a proof using elementary techniques, achieving full rigor — showing adaptability under constraint, though initial attempts relied on unproven advanced theorems.
- On IMO 2024 variants, the model solved Problem 3 at 2^7 scale (with minor error) and Problem 5 at 2^8 scale, using novel, non-visual, state-based reasoning — suggesting first-principles derivation rather than memorization.
Results show that when evaluated on 200 candidate solutions for open Erdős problems, the majority were fundamentally flawed, while only a small fraction were both technically and meaningfully correct. The model frequently produced solutions that were mathematically valid under loose interpretations but failed to address the intended mathematical intent, highlighting persistent gaps in understanding problem context. Even with verification mechanisms, the system remains prone to misinterpretation and hallucination, limiting its reliability for autonomous research.
