Command Palette
Search for a command to run...
BagelVLA: 시각-언어-행동 병행 생성을 통한 장기 지속 조작 성능 향상
BagelVLA: 시각-언어-행동 병행 생성을 통한 장기 지속 조작 성능 향상
초록
실행 가능한 에이전트에게 작업에 대한 추론 능력, 물리적 결과 예측 능력, 정밀한 동작 생성 능력을 부여하는 것은 일반 목적의 조작을 위한 핵심 요소이다. 최근의 시각-언어-행동(Vision-Language-Action, VLA) 모델들은 사전 훈련된 기반 모델을 활용하고 있으나, 일반적으로 언어 기반 계획 또는 시각적 예측 중 하나에만 집중하는 경향이 있다. 이러한 방법들은 두 가지 능력을 동시에 통합하여 동작 생성을 안내하는 경우가 거의 없어, 복잡하고 장기적인 조작 과제에서 최적의 성능을 달성하지 못하고 있다. 이 격차를 메우기 위해 우리는 언어 기반 계획, 시각적 예측, 동작 생성을 하나의 프레임워크 내에 통합한 통합형 모델인 BagelVLA를 제안한다. 사전 훈련된 통합적 이해 및 생성 모델을 기반으로 초기화된 BagelVLA는 텍스트 기반 추론과 시각적 예측을 동작 실행 루프 내에서 직접 번갈아가며 수행하도록 훈련된다. 이러한 다양한 모달리티를 효율적으로 결합하기 위해 우리는 잔차 흐름 안내(Residual Flow Guidance, RFG)를 도입한다. RFG는 현재 관측값에서 초기화되며, 단일 단계의 노이즈 제거 기법을 활용해 예측 가능한 시각적 특징을 추출함으로써, 최소한의 지연 시간으로 동작 생성을 안내한다. 광범위한 실험을 통해 BagelVLA가 여러 시뮬레이션 및 실제 환경 벤치마크에서 기존의 기준 모델들을 크게 능가함을 입증하였으며, 다단계 추론이 필요한 과제에서尤为 뛰어난 성능을 보였다.
One-sentence Summary
Researchers from Tsinghua University and ByteDance Seed propose BagelVLA, a unified VLA model integrating linguistic planning and visual forecasting via Residual Flow Guidance to enable precise, low-latency action generation, significantly outperforming baselines in complex, multi-stage manipulation tasks.
Key Contributions
- BagelVLA introduces a unified framework that jointly performs linguistic planning, visual forecasting, and action generation within a single transformer architecture, addressing the fragmentation in prior VLA models that treat these components in isolation.
- The method employs Residual Flow Guidance (RFG), which conditions on the current observation and uses single-step denoising to predict visual dynamics efficiently, enabling low-latency foresight without full image synthesis while guiding precise action execution.
- Evaluated on both simulated and real-world benchmarks, BagelVLA significantly outperforms existing baselines, especially in multi-stage tasks, and demonstrates strong generalization to unseen instructions and object arrangements.
Introduction
The authors leverage recent advances in unified vision-language models to tackle long-horizon robotic manipulation, where agents must reason about instructions, predict visual outcomes, and execute precise actions—all in sequence. Prior VLA models typically handle either linguistic planning or visual forecasting in isolation, leading to brittle performance on complex, multi-step tasks. BagelVLA overcomes this by integrating all three capabilities within a single transformer architecture, interleaving text-based planning, visual prediction, and action generation in a unified loop. To keep inference efficient, they introduce Residual Flow Guidance (RFG), which uses the current observation as a structural prior and applies single-step denoising to predict visual changes—avoiding costly full-frame generation. Their approach significantly outperforms baselines in both simulation and real-world settings, especially on tasks requiring multi-stage reasoning and generalization to novel instructions.
Dataset

The authors use a multi-source, multi-stage dataset to train their model for embodied subtask planning and keyframe prediction. Here’s how the data is composed, processed, and used:
-
Dataset Composition and Sources:
- Robotic Data: Combines self-collected expert demonstrations and public datasets. Proprietary data is manually annotated for subtask boundaries (lt); public data without fine labels uses Seed-1.5-VL-thinking to generate lt and temporal boundaries, followed by quality filtering.
- General Data: Includes egocentric human videos and large-scale image-text VQA data. Seed-1.5-VL-thinking generates language annotations for human videos, but only final frame prediction is performed (no subtask annotation). VQA data preserves general language understanding.
-
Key Subset Details:
- General VQA (Language Co-training): 2.56M QA pairs — used to maintain base model linguistic skills.
- Human-hand Data (Visual Dynamics): 310k episodes — derived from egocentric human videos, annotated via Seed-1.5-VL-thinking.
- Open-source Robot Data (Planning & Dynamics): 382k episodes — processed with Seed-1.5-VL-thinking for subtask and frame annotations.
- Self-collected Real Robot Data (Planning & Dynamics): 4.5k episodes — manually segmented and annotated for high-quality training.
- Downstream Robot Tasks (Stage 2):
- Calvin: Uses ABC dataset.
- Robotwin: 50 tasks × 50 episodes = 2.5k episodes.
- Aloha Short-horizon: 3k episodes.
- Aloha Long-horizon: 1.5k episodes.
-
How the Data Is Used:
- Stage 1 (Pretraining): Finetunes Understanding and Generation Experts using a mixture of General VQA (2.56M), Human-hand (310k), Open-source Robot (382k), and Self-collected Robot (4.5k) data. General QA co-training preserves language proficiency.
- Stage 2 (Action Planning): Finetunes the full model on downstream robot datasets with action labels, training all three planning tasks simultaneously for robust interleaved planning.
-
Processing and Metadata:
- Seed-1.5-VL-thinking generates subtask annotations (lt) and temporal boundaries for unlabeled datasets (e.g., Bridge, EgoDex, AgiBot).
- Prompt templates (Fig. 12 and 13) extract task descriptions and subtask labels from videos or image sequences.
- No explicit cropping strategy is mentioned; focus is on temporal segmentation and annotation synthesis.
- All data is filtered for quality, especially in public robotic datasets, to ensure reliable training signals.
Method
The authors leverage an interleaved planning paradigm to address the limitations of conventional vision-language-action (VLA) models in long-horizon manipulation tasks. Rather than mapping observations and global instructions directly to actions, BagelVLA explicitly models the joint distribution pθ(at,vt+k,lt∣vt,L), decomposing the policy into three sequential reasoning steps: linguistic planning, visual forecasting, and action generation. This factorization enables the model to reason about the causal structure of the task by first identifying the immediate subtask lt, then predicting the visual outcome vt+k, and finally generating the grounded action at. The training objective maximizes the log-likelihood of this factorized distribution, optimizing three distinct losses: Ll for subtask prediction, Lv for keyframe forecasting, and La for action generation.
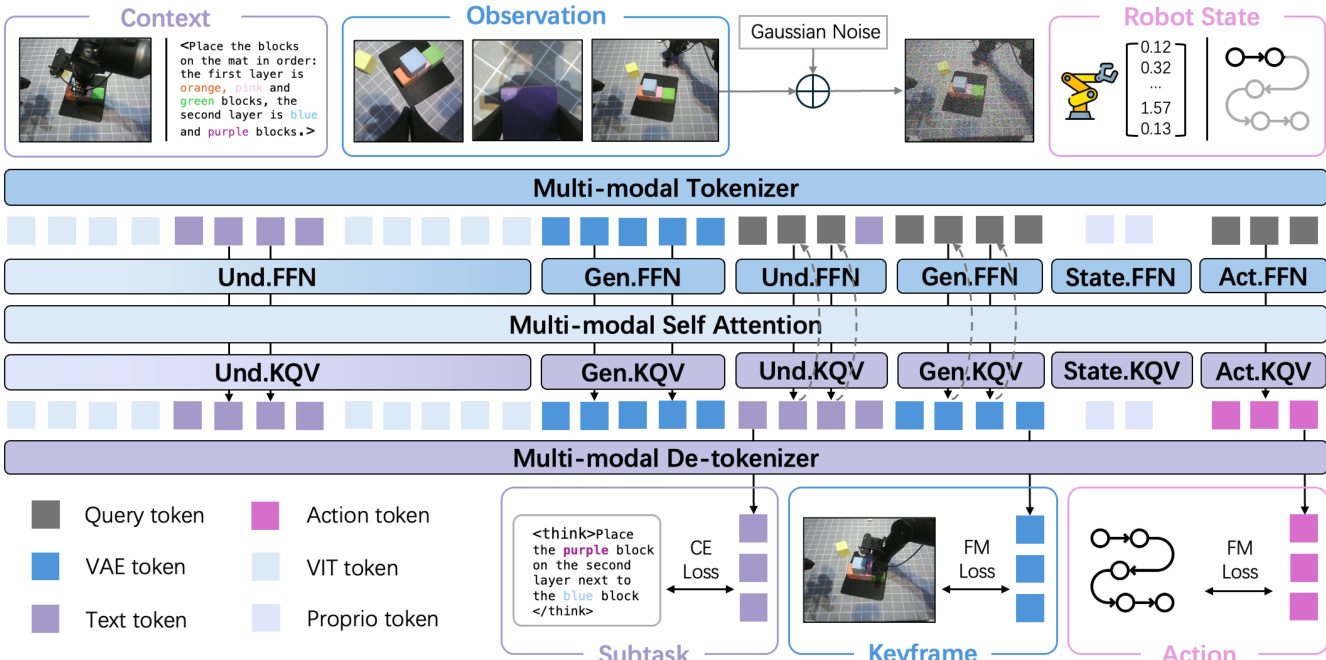
To implement this framework, the authors introduce BagelVLA, a unified Mixture-of-Transformers (MoT) architecture comprising three specialized experts: an understanding expert for linguistic planning, a generation expert for visual forecasting, and an action expert for control. As shown in the framework diagram, these experts operate on a shared interleaved sequence of tokens representing text, visual features, and proprioceptive states. The understanding and generation experts are initialized from the Bagel model and employ Qwen2.5-LLM-7B architecture, with distinct visual encoders (SigLIP2 for ViT features and FLUX VAE for latent image encoding) to process observations. The action expert, a smaller 2B-parameter transformer, is designed for low-latency inference and attends to both visual and textual context during action generation.
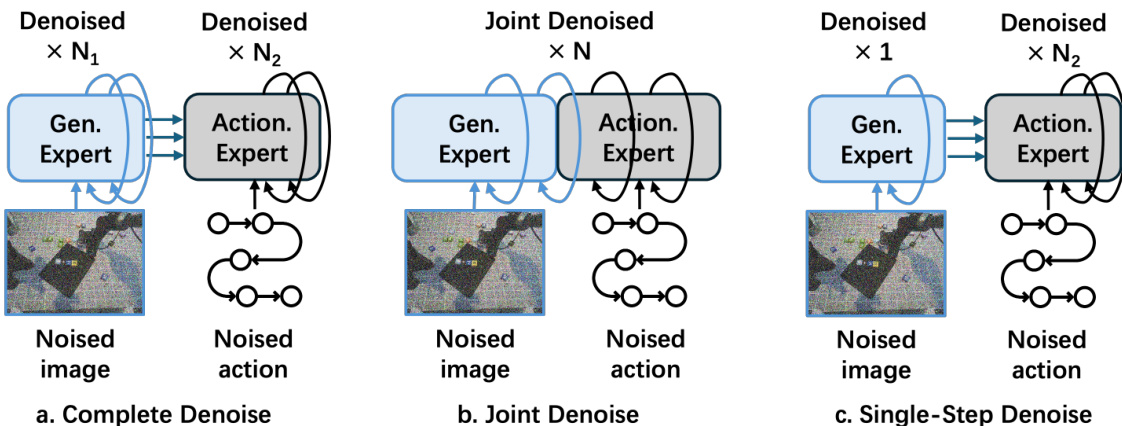
To coordinate the visual and action generation processes, the authors propose a dual flow-matching mechanism. As illustrated in the figure below, three conditioning schemes are explored: Complete Denoise, Joint Denoise, and Single-Step Denoise. In Complete Denoise, the keyframe is fully denoised before action generation, ensuring high fidelity but incurring high latency. Joint Denoise synchronizes both denoising processes, allowing the action expert to attend to intermediate noisy keyframes. Single-Step Denoise, the selected default, conditions action generation on the initial noise state of the keyframe, drastically reducing computational cost. A variant, Residual Flow Guidance (RFG), injects the current observation vt into the initial noise, enabling the model to focus on task-relevant dynamics rather than reconstructing static background.
Training proceeds in two stages. Stage 1 pretrains the understanding and generation experts using a mix of general VQA data and robot datasets to develop linguistic planning and visual dynamics capabilities. Stage 2 introduces action-labeled robot data to finetune the entire model, aligning all three planning tasks. During inference, the model generates subtasks, keyframes, and actions in an interleaved fashion, activating only one expert per denoising step. The Single-Step Denoise scheme, combined with asynchronous execution, enables real-time control at 72Hz on a single GPU by updating only proprioceptive inputs while reusing cached visual and textual context.

The model’s ability to perform long-horizon planning is demonstrated on tasks such as stacking blocks in a specified order and assembling arithmetic equations. In these scenarios, BagelVLA interleaves linguistic reasoning (e.g., computing “21+3=24”) with visual forecasting and action generation, enabling it to handle complex, multi-step instructions that require both semantic understanding and physical foresight. The framework’s design ensures that each action is grounded in a predicted future state and a decomposed subtask, enhancing robustness and instruction-following fidelity.
Experiment
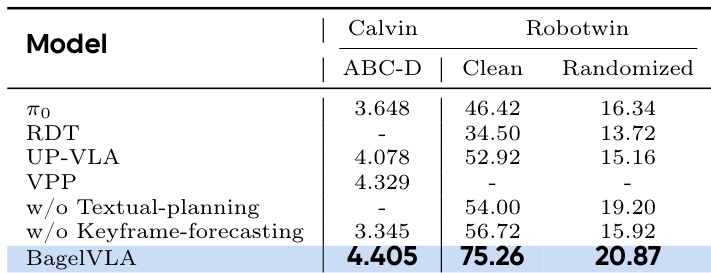
- BagelVLA demonstrates superior interleaved planning across simulation (Calvin, Robotwin) and real-world (Aloha-AgileX) environments, outperforming baselines including π₀, RDT, UP-VLA, and VPP.
- In simulation, BagelVLA excels in both in-domain and OOD settings, particularly when incorporating textual planning, achieving state-of-the-art success rates and robust generalization to visual variations.
- On real-world basic tasks, BagelVLA shows strong multi-task learning and OOD generalization, leveraging semantic features from pre-training to handle unseen objects and distractors.
- For long-horizon tasks, BagelVLA significantly outperforms baselines in planning accuracy (nearly 90%) and task success, validating its ability to reason, follow instructions, and execute subtask sequences.
- Ablations confirm that single-step denoising with RFG (Recurrent Flow Guidance) improves inference speed and generation quality over joint or complete denoising, while preserving background fidelity.
- Pre-training on language planning and visual dynamics enhances downstream performance, enabling implicit subtask planning even without explicit interleaved inference.
- Both visual forecasting and textual planning are critical components: removing either degrades performance, especially in complex, long-horizon scenarios.
- The model’s robustness is validated across diverse manipulation tasks, including pick-and-place, stacking, sweeping, pouring, and arithmetic-based sequencing, under randomized conditions and novel objects.
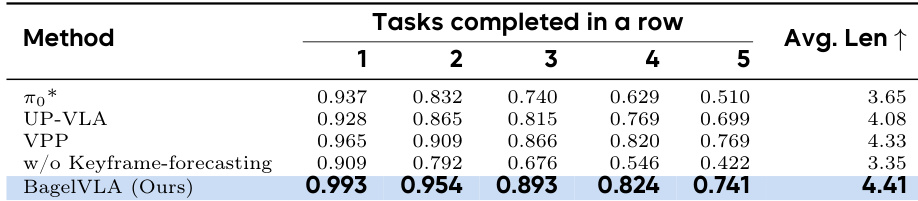
Results show that BagelVLA consistently outperforms baseline models across both clean and randomized Robotwin tasks, with its full configuration achieving the highest average success rate. The model’s advantage is particularly evident when incorporating both textual planning and keyframe forecasting, which significantly boost performance in out-of-distribution settings. Ablation experiments confirm that each component of the interleaved planning framework contributes meaningfully to robust action generation and generalization.
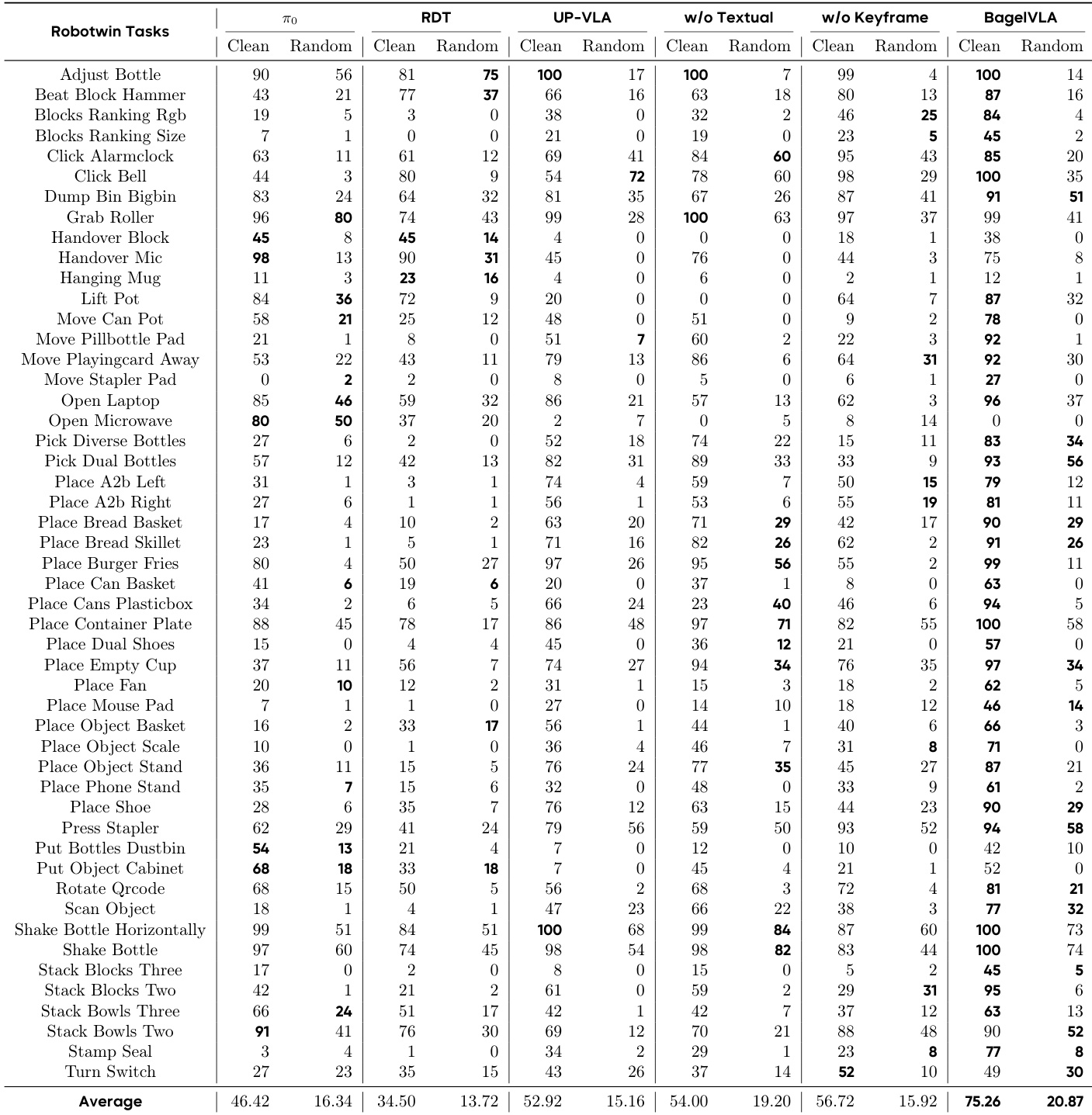
The authors use BagelVLA to evaluate interleaved planning across simulation and real-world robotic tasks, comparing it against baselines including π₀, UP-VLA, and VPP. Results show that BagelVLA consistently outperforms all baselines in both simulation environments and real-world long-horizon tasks, particularly when incorporating textual planning and visual forecasting. The model’s superior performance stems from its ability to integrate language-guided subtask decomposition with visual goal prediction, enabling robust generalization across diverse and unseen scenarios.
The authors evaluate different dual flow-matching schemes in the Calvin ABC-D environment and find that single-step denoising and RFG both achieve the lowest inference latency at 1.23 seconds per action chunk, while RFG delivers the highest task completion length of 3.600. This indicates that RFG not only maintains fast inference speed but also significantly improves task success over other conditioning methods, likely due to its use of initial frame context for more informed action generation.

BagelVLA demonstrates superior multi-task performance across diverse real-world manipulation tasks, consistently outperforming baseline models in both seen and unseen object settings. Its strength stems from preserved semantic features during fine-tuning, enabling robust generalization even under visual and object variations. The model achieves the highest average success rate, particularly excelling in tasks requiring fine motor control and semantic understanding.

BagelVLA outperforms all baseline models on both the Calvin ABC-D and Robotwin benchmarks, achieving the highest success rates in both clean and randomized settings. The model’s performance improves significantly when incorporating textual planning and keyframe forecasting, confirming the effectiveness of its interleaved planning framework. Results also indicate that visual prediction as an auxiliary task enhances generalization to out-of-distribution scenarios while maintaining high manipulation accuracy.