Command Palette
Search for a command to run...
SemanticMoments: 제3모멘트 특징을 통한 훈련 없이 구현하는 움직임 유사도
SemanticMoments: 제3모멘트 특징을 통한 훈련 없이 구현하는 움직임 유사도
Saar Huberman Kfir Goldberg Or Patashnik Sagie Benaim Ron Mokady
초록
의미 있는 동작을 기반으로 영상을 검색하는 것은 핵심적이지만 여전히 해결되지 않은 문제이다. 기존의 영상 표현 방법들은 정적 외관과 장면 맥락에 과도하게 의존하며, 동작 역학에 대한 고려가 부족하다. 이러한 편향은 훈련 데이터와 목적에 기인한 것이다. 반면, 광학 흐름과 같은 전통적인 동작 중심 입력은 고차원 동작을 이해하기 위해 필요한 의미적 기반을 갖추지 못하고 있다. 이러한 내재된 편향을 입증하기 위해, 우리는 조작 가능한 합성 데이터와 새로운 인간 주석이 달린 실세계 데이터셋을 결합한 SimMotion 벤치마크를 제안한다. 우리는 기존 모델이 이러한 벤치마크에서 낮은 성능을 보이며, 종종 동작과 외관을 분리하지 못함을 보여준다. 이 격차를 해결하기 위해, 사전 훈련된 의미적 모델의 특징에 대해 시간적 통계(특히 고차 모멘트)를 계산하는 간단하고 훈련이 필요 없는 방법인 SemanticMoments를 제안한다. 우리의 벤치마크 전반에서 SemanticMoments는 기존의 RGB, 광학 흐름, 텍스트 감독 기반 방법들을 일관되게 능가한다. 이는 의미적 특징 공간 내의 시간적 통계가 동작 중심의 영상 이해를 위한 확장 가능하고 인지적으로 타당한 기반을 제공함을 보여준다.
One-sentence Summary
Researchers from BRIA AI, Tel Aviv University, and Hebrew University propose SemanticMoments, a training-free method using higher-order temporal statistics over semantic features to disentangle motion from appearance, enabling accurate motion-centric video retrieval where prior models fail.
Key Contributions
- We identify a critical bias in existing video representations that prioritize static appearance over motion dynamics, revealing their failure to disentangle motion from visual context in retrieval tasks.
- We introduce the SimMotion benchmarks—combining synthetic and human-annotated real-world datasets—to rigorously evaluate motion-centric video similarity and expose the limitations of current methods.
- We propose SemanticMoments, a training-free method that computes higher-order temporal statistics over semantic features, achieving state-of-the-art performance on motion retrieval without requiring optical flow or labeled motion data.
Introduction
The authors tackle the challenge of retrieving videos based on semantic motion rather than static appearance or scene context — a capability critical for applications like motion-aware video editing, generative modeling, and dataset curation. Prior methods, whether supervised, self-supervised, or flow-based, inherit biases that prioritize visual consistency over temporal dynamics, often failing to disentangle motion from appearance even when motion is identical. To address this, they introduce SemanticMoments, a training-free approach that computes higher-order temporal moments (variance, skewness) over patch-level embeddings from pretrained semantic models like DINO. This yields compact, motion-sensitive descriptors that outperform existing methods across synthetic and real-world benchmarks, without requiring optical flow, labeled data, or additional training.
Dataset

-
The authors use two benchmarks — SimMotion-Synthetic and SimMotion-Real — to evaluate motion similarity beyond categorical labels, focusing on structural and dynamic properties through relative comparisons.
-
SimMotion-Synthetic contains 250 triplets (750 videos total), each with a reference, a motion-preserving positive, and a hard negative with matching appearance but different motion. Videos are 5 seconds long, sampled at 16 fps, 512x512 resolution. Triplets are grouped into five categories: Static Object, Dynamic Object, Dynamic Appearance, Scene Style, and View — each isolating a specific visual variation while preserving motion.
-
Videos are generated using GPT-4.1 to craft prompts, then synthesized via Gemini2.5-Flash for images and WAN 2.2 for temporally synchronized videos. Hard negatives are generated from the same base image with a different motion prompt. This ensures precise motion alignment while varying appearance, subject, or viewpoint.
-
SimMotion-Real contains 40 reference-positive-negative triplets curated from real-world videos. Positives are sourced from Pexels via text queries and ranked by human annotators for motion similarity, ignoring appearance. Negatives are drawn from the same source video but show different motions, plus random clips from Kinetics-400 to increase retrieval difficulty.
-
Both benchmarks are used to test whether models capture motion structure rather than visual cues. The authors extract patch-wise features per frame (e.g., using DINO), summarize them over time via first three moments (mean, variance, skewness), then spatially aggregate to form global motion-centric embeddings for evaluation.
Method
The authors leverage a parametric moment-based representation, termed M+, to encode temporal dynamics in video data by preserving structured statistical descriptors rather than collapsing temporal information into a single pooled vector. The framework begins with a patch-wise embedding stage, where each frame of a video is processed through a pretrained backbone (e.g., DINOv2, Video-MAE, or VideoPrism) to extract spatial patch features. These features are then used to compute temporal moments independently for each spatial patch across the video’s temporal axis.
Refer to the framework diagram: the process starts with a sequence of video frames fed into a patch-wise embedder, which outputs a spatiotemporal tensor of patch features. For each patch p, the first temporal moment μp(1) is computed as the mean feature vector across time, capturing average appearance. Higher-order moments μp(k) for k>1 are computed as central moments, encoding the magnitude of variation (k=2) and directional asymmetry (k=3) of temporal change. These patch-wise moments are then spatially aggregated via averaging to produce global moment descriptors M(k)∈Rd for each order k.
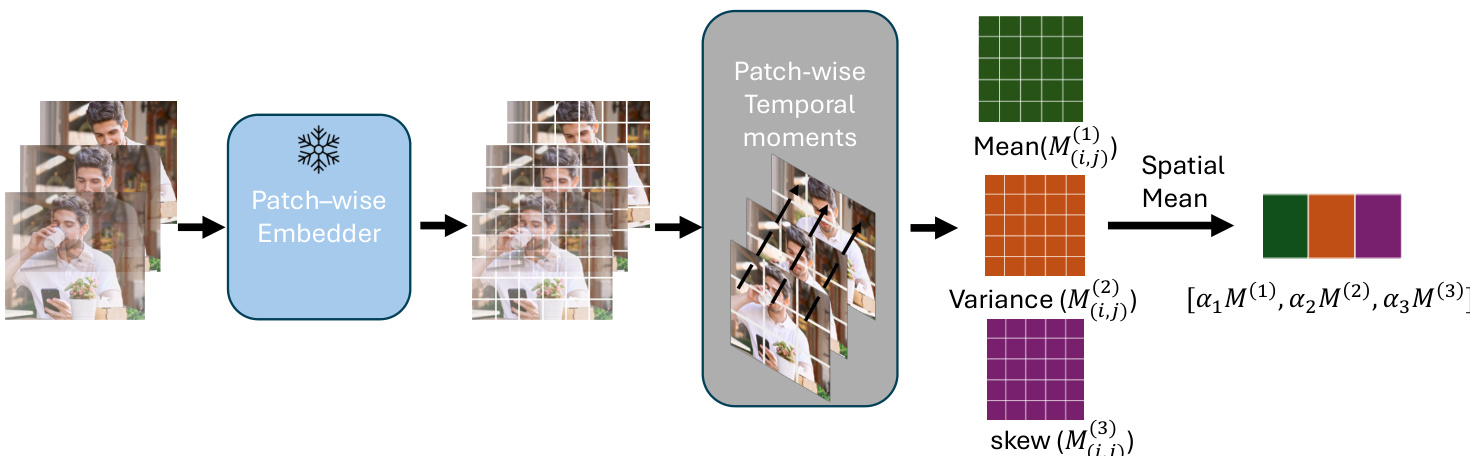
The final video-level representation ϕvideo is constructed by concatenating the first three moment descriptors—mean, variance, and skew—each scaled by a learnable or fixed weight αk. In practice, the authors fix α1=1, α2=8, and α3=4 to emphasize motion-related statistics. The resulting embedding ϕvideo∈R3d is computed without additional training, relying solely on pretrained backbones and moment aggregation, enabling efficient and scalable deployment on large video datasets.
Experiment
- Existing self-supervised and appearance-focused video embeddings fail to consistently capture fine-grained motion similarity, often conflating motion with style or background.
- A controlled synthetic benchmark reveals that motion-preserving variants are poorly clustered by prior methods, while the proposed SemanticMoments approach successfully isolates motion by summarizing temporal statistics over semantic features.
- On real-world motion retrieval tasks, SemanticMoments outperforms baselines—including flow-based, CLIP-based, and action-trained models—by maintaining robustness to appearance shifts, camera motion, and unsynchronized timing.
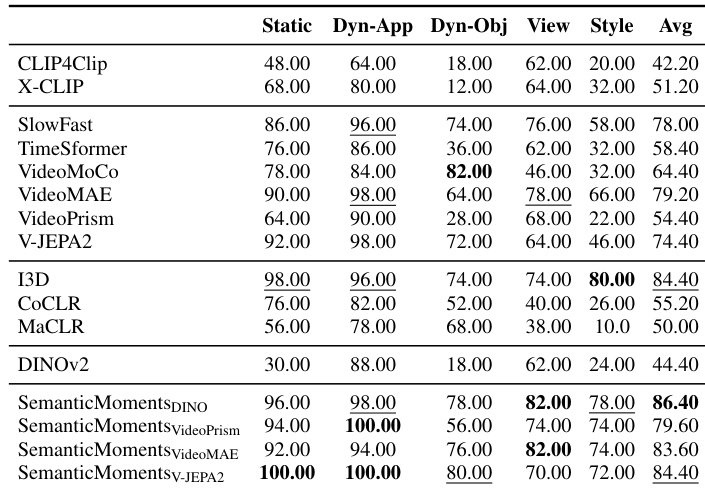
- Applied to gesture classification, SemanticMoments enhances separability in embedding space without additional training, improving kNN accuracy across multiple backbones.
- Ablation studies confirm that higher-order moments, patch-level granularity, and additive fusion yield optimal motion alignment, with performance peaking at 32 uniformly sampled frames.
- Limitations include challenges with subtle or absence-defined motions, dependency on upstream backbone quality, and inability to adapt to rare motion types without targeted training.
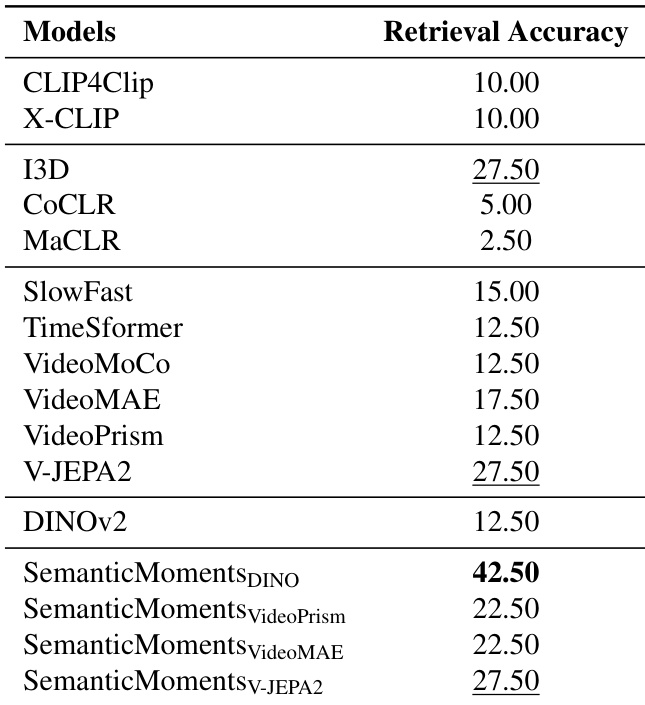
The authors evaluate motion-sensitive video representations across synthetic benchmarks that isolate appearance variations while preserving motion. Results show that existing methods—including CLIP-based, RGB-supervised, and optical-flow models—struggle to consistently capture motion similarity under style, object, or viewpoint changes, while their proposed SemanticMoments approach achieves superior or competitive performance by summarizing temporal dynamics through higher-order statistics over semantic features. This indicates that motion-aware embeddings can be effectively derived without explicit motion supervision or training, by leveraging temporal moments of semantic frame representations.
The authors evaluate how temporal sampling density affects motion retrieval performance, finding that accuracy improves as frame count increases up to 32 frames, beyond which performance plateaus or declines. This suggests that moderate temporal resolution captures sufficient motion dynamics without introducing redundancy or noise.

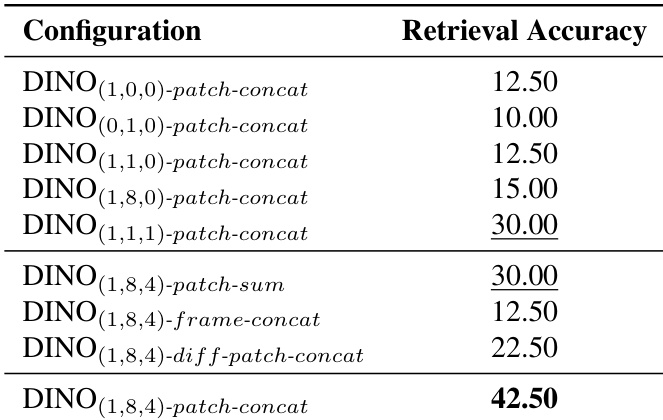
The authors evaluate different configurations of their moment-based representation on SimMotion-Real, finding that combining multiple temporal moments (mean, variance, skewness) at the patch level with concatenation yields the highest retrieval accuracy. Results show that higher-order moments and localized patch features significantly improve motion alignment over single-moment or frame-level approaches. The best-performing variant, DINO(1,8,4)-patch-concat, achieves 42.50% accuracy, demonstrating the value of richer temporal statistics and spatial granularity in capturing motion similarity.
The authors use SemanticMoments to enhance motion-sensitive video representations by applying temporal statistics to semantic features from pretrained encoders. Results show that this approach consistently outperforms baseline methods across multiple evaluation metrics, particularly when using V-JEPA2 as the backbone, indicating stronger gesture-level separability without additional training. The gains highlight the effectiveness of higher-order temporal moments in capturing motion structure beyond appearance or coarse semantics.
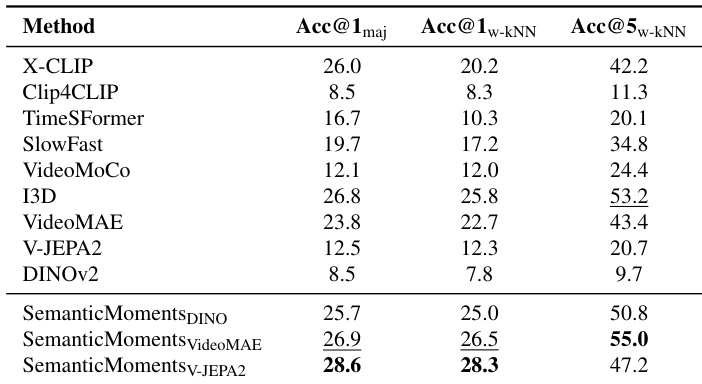
The authors evaluate motion similarity retrieval using a synthetic benchmark that isolates motion from appearance variations. Results show that existing methods, including CLIP-based, flow-based, and self-supervised models, struggle to consistently capture motion equivalence across style changes. In contrast, their SemanticMoments approach, which aggregates temporal statistics over semantic features, achieves significantly higher retrieval accuracy, demonstrating stronger robustness to appearance shifts while preserving motion structure.