Command Palette
Search for a command to run...
SKILLRL: 재귀적 기술 증강 강화 학습을 통한 Agent의 진화
SKILLRL: 재귀적 기술 증강 강화 학습을 통한 Agent의 진화
초록
Large Language Model (LLM) agent는 복잡한 작업에서 놀라운 성과를 보여주고 있으나, 대개 고립된 상태로 작동하여 과거의 경험으로부터 학습하지 못한다는 한계가 있습니다. 기존의 메모리 기반 방식은 주로 가공되지 않은 raw trajectory를 저장하는데, 이는 데이터의 중복이 심하고 노이즈가 많다는 단점이 있습니다. 이로 인해 agent는 일반화(generalization)에 필수적인 고차원적이고 재사용 가능한 행동 패턴을 추출하는 데 어려움을 겪습니다.본 논문에서는 자동화된 skill discovery와 재귀적 진화(recursive evolution)를 통해 raw experience와 policy 개선 사이의 간극을 메우는 프레임워크인 SKILLRL을 제안합니다. 본 연구의 접근 방식은 다음과 같은 핵심 요소를 도입합니다: 첫째, 경험 기반의 distillation 메커니즘을 통해 계층적 skill library인 SKILLBANK를 구축합니다. 둘째, 일반적인 휴리스틱과 작업 특화형(task-specific) 휴리스틱을 위한 적응형 검색(adaptive retrieval) 전략을 도입합니다. 마지막으로, reinforcement learning 과정에서 skill library가 agent의 policy와 함께 공동 진화(co-evolve)할 수 있도록 하는 재귀적 진화 메커니즘을 제공합니다.이러한 혁신적인 방식은 token 사용량을 크게 줄이는 동시에 추론 효율성(reasoning utility)을 향상시킵니다. ALF-World, WebShop 및 7개의 search-augmented task를 대상으로 진행한 실험 결과, SKILLRL은 기존의 강력한 baseline 모델들을 15.3% 이상 상회하는 state-of-the-art 성능을 달성하였으며, 작업의 복잡도가 증가함에 따라 더욱 견고한(robust) 성능을 유지함을 입증하였습니다.
One-sentence Summary
The proposed SKILLRL framework evolves LLM agents through recursive skill-augmented reinforcement learning by utilizing an experience-based distillation mechanism to build a hierarchical SKILLBANK and an adaptive retrieval strategy, which transforms redundant trajectories into reusable behavioral patterns to achieve state-of-the-art performance on ALF-World, WebShop, and seven search-augmented tasks.
Key Contributions
- The paper introduces SKILLRL, a framework that bridges the gap between raw experience and policy improvement through automatic skill discovery and recursive evolution.
- This work presents an experience-based distillation mechanism that builds a hierarchical skill library called SKILLBANK, which differentiates between general strategic guidance and task-specific heuristics to reduce token footprint and enhance reasoning utility.
- The method incorporates a recursive evolution mechanism that allows the skill library and the agent policy to co-evolve during reinforcement learning, achieving state-of-the-art performance with a 15.3% improvement over baselines on benchmarks such as ALF-World and WebShop.
Introduction
Large Language Model (LLM) agents are increasingly used for complex tasks like web navigation and deep research, but they often operate in isolation without the ability to learn from past experiences. Current memory-based methods typically store raw trajectories, which are often redundant, noisy, and difficult for models to use for high-level reasoning. The authors propose SKILLRL, a framework that bridges the gap between raw experience and policy improvement through automatic skill discovery and recursive evolution. They leverage an experience-based distillation mechanism to transform trajectories into a hierarchical skill library called SKILLBANK, which contains both general and task-specific skills. By incorporating a recursive evolution mechanism, the authors ensure that the skill library and the agent policy co-evolve during reinforcement learning, significantly improving reasoning utility and performance while reducing the token footprint.
Method
The authors propose SKILLRL, a framework designed to bridge the gap between raw interaction experience and policy improvement through automatic skill discovery and recursive evolution. The framework aims to transform verbose, redundant trajectories into concise, actionable knowledge that can be effectively utilized within the limited context windows of LLM-based agents.
As shown in the figure below:
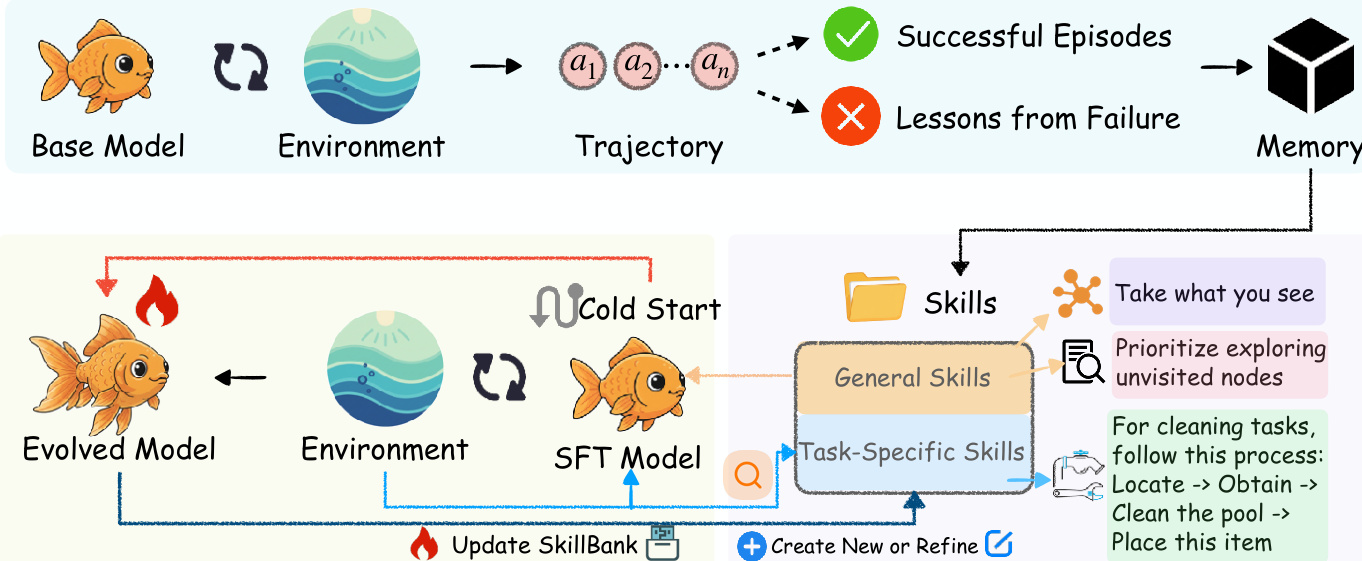
The SKILLRL framework consists of three core components: experience-based skill distillation, hierarchical skill library construction, and recursive skill evolution.
Experience-based Skill Distillation
To convert raw trajectories into usable knowledge, the authors employ a teacher model MT to distill experiences. Unlike traditional methods that only focus on successful episodes, the authors deliberately collect both successful trajectories T+={τi:r(τi)=1} and failed trajectories T−={τi:r(τi)=0}. Successful trajectories are processed to extract strategic patterns: s+=MT(τ+,d) This allows the teacher model to identify critical decision points and generalizable reasoning. For failed trajectories, the teacher model synthesizes concise failure lessons: s−=MT(τ−,d) This transformation identifies the point of failure and provides counterfactual guidance, turning noisy, lengthy failed episodes into actionable principles.
Hierarchical Skill Library (SKILLBANK)
The distilled knowledge is organized into a hierarchical structure called SKILLBANK. It is divided into two levels:
- General Skills Sg: These capture universal strategic principles, such as exploration strategies and state management, which are applicable across all tasks.
- Task-Specific Skills Sk: These encode specialized knowledge for specific task categories, including domain-specific action sequences and unique failure modes.
The complete library is defined as Sg∪⋃k=1KSk. During inference, general skills are always provided, while task-specific skills are retrieved via semantic similarity: Sret=TopK({s∈Sk:sim(ed,es)>δ},K) where ed and es are the embeddings of the task description and the skill, respectively.
Recursive Skill Evolution and RL Training
To ensure the agent can effectively use these skills, the authors implement a cold-start stage using Supervised Fine-Tuning (SFT). The teacher model generates skill-augmented reasoning traces DSFT, and the base model is fine-tuned to minimize the cross-entropy loss: θsft=argminθLCE(DSFT;θ)
Following initialization, the policy πθ is optimized using Group Relative Policy Optimization (GRPO). For each task, the agent retrieves skills and samples G trajectories. The policy is updated using a clipped objective that incorporates a KL penalty to maintain stability relative to the reference policy πref: J(θ)=Ed,{τ(i)}[G1∑i=1Gmin(ρiAi,clip(ρi,1−ϵ,1+ϵ)Ai)−βDKL(πθ∣∣πref)]
To prevent the skill library from becoming static, the authors introduce recursive evolution. If the success rate for a task category falls below a threshold, the framework collects failed validation trajectories Tval− and uses the teacher model to generate new skills: Snew=MT(Tval−,SKILLBANK) These new skills are then integrated into the library, allowing the skills and the policy to co-evolve.
Experiment
SKILLRL is evaluated across nine benchmarks, including ALFWorld, WebShop, and various search-augmented QA tasks, to compare its performance against closed-source models, prompt-based agents, and reinforcement learning methods. The experiments validate that abstracting experiences into a co-evolving skill library significantly outperforms methods relying on raw trajectory memory or static prompting. Overall, the results demonstrate that structured skill distillation enables smaller open-source models to surpass much larger closed-source counterparts while accelerating training convergence and improving context efficiency.
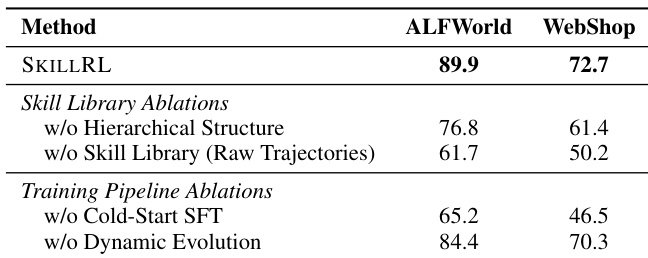
The authors conduct ablation studies to evaluate the impact of different components within the SKILLRL framework on ALFWorld and WebShop performance. The results demonstrate that the full SKILLRL configuration achieves the highest success rates across both benchmarks. Removing the hierarchical structure or replacing the skill library with raw trajectories leads to significant performance decreases. The cold-start SFT phase is essential for maintaining high success rates in both environments. Dynamic evolution contributes to improved performance compared to a static skill library.
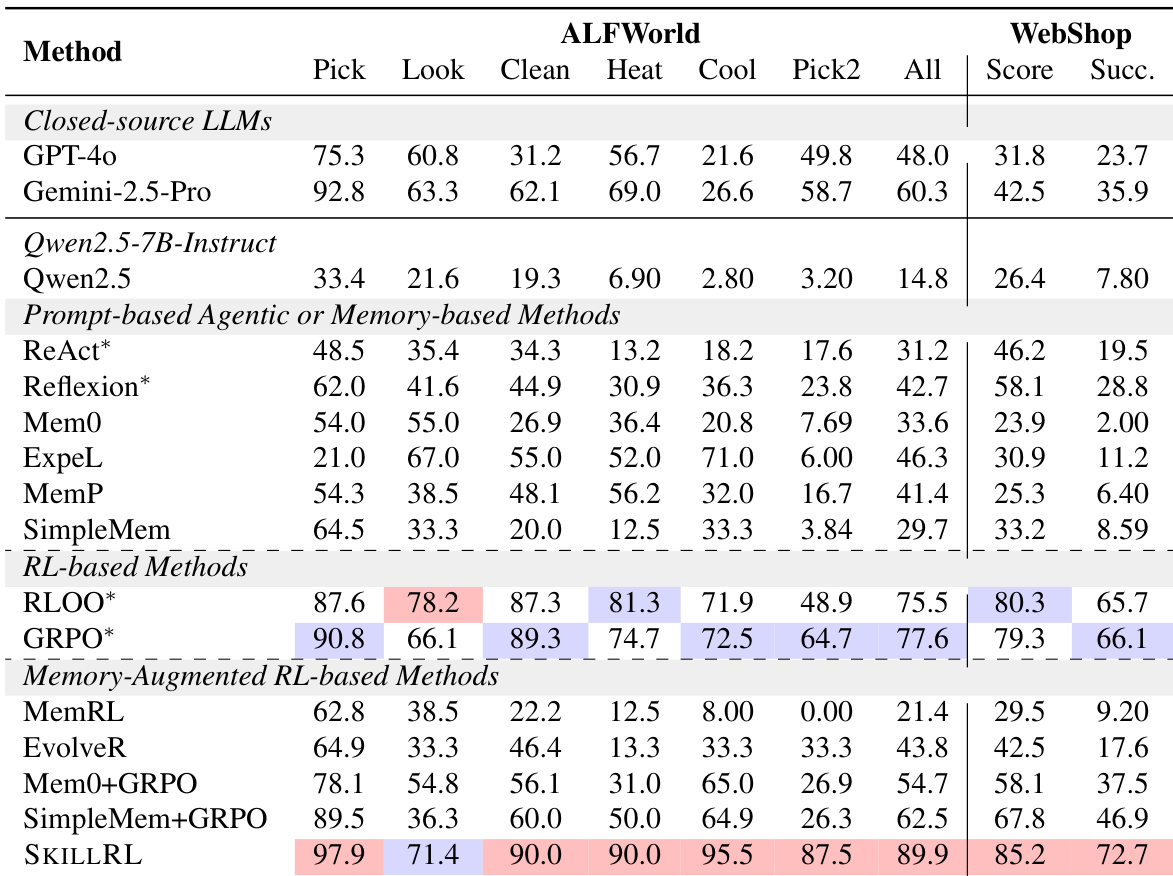
The authors compare SKILLRL against various baseline methods including closed-source LLMs, prompt-based agents, and reinforcement learning approaches on the ALFWorld and WebShop benchmarks. Results show that SKILLRL consistently achieves superior performance across most subtasks and overall metrics compared to all tested baselines. SKILLRL outperforms both closed-source models and standard reinforcement learning methods in overall success rates. The method demonstrates significant improvements in complex ALFWorld subtasks compared to memory-augmented RL baselines. SKILLRL achieves higher average scores and success rates on the WebShop benchmark than prompt-based and RL-based competitors.
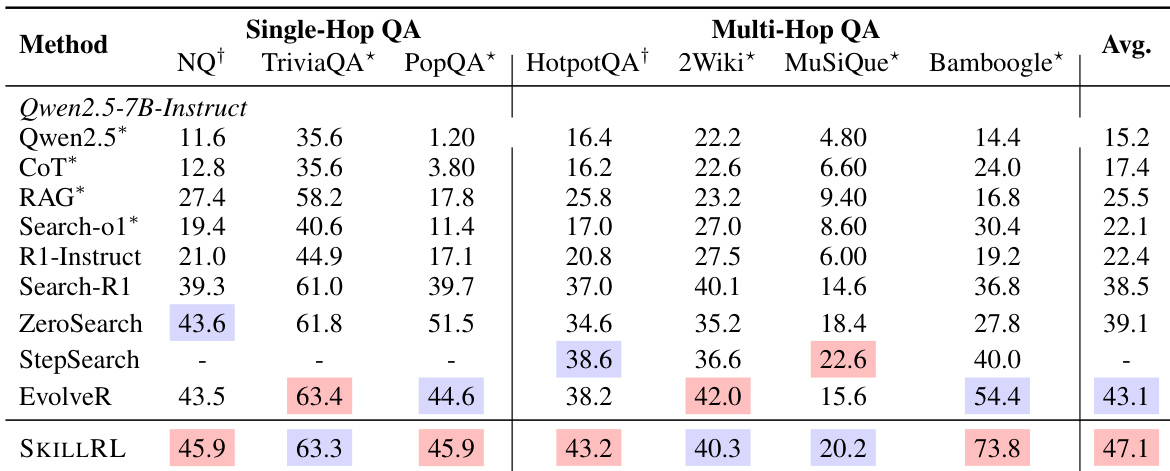
The authors evaluate SKILLRL on various search-augmented single-hop and multi-hop QA tasks to demonstrate its reasoning capabilities. Results show that the method achieves a higher average score compared to both specialized search-augmented baselines and memory-augmented reinforcement learning frameworks. SKILLRL achieves superior performance on multi-hop reasoning tasks such as Bamboogle and MuSiQue compared to existing baselines. The method demonstrates strong generalization by maintaining competitive results on out-of-domain datasets. SKILLRL outperforms state-of-the-art search-augmented models in overall average score across the evaluated QA benchmarks.
Through ablation studies, comparative benchmarks on ALFWorld and WebShop, and reasoning evaluations on QA tasks, the authors validate the effectiveness of the SKILLRL framework. The results demonstrate that the full configuration, including its hierarchical structure and dynamic skill library, consistently outperforms closed-source LLMs, prompt-based agents, and standard reinforcement learning methods. Furthermore, the framework exhibits strong reasoning capabilities and generalization across complex multi-hop tasks and out-of-domain datasets.