Command Palette
Search for a command to run...
기반 흐름 GRPO에서 단계별 및 장기적 샘플링 효과 모델링을 통한 희소 보상 완화
기반 흐름 GRPO에서 단계별 및 장기적 샘플링 효과 모델링을 통한 희소 보상 완화
초록
텍스트-이미지 생성을 위한 플로우 매칭 모델에 GRPO를 적용하는 것은 효과적임이 입증되었다. 그러나 기존의 접근 방식은 각 전단계의 디노이징 단계에 대해 결과 기반 보상을 동일하게 전파하되, 각 단계의 국소적 영향을 구분하지 못하는 문제가 있다. 더불어 현재의 그룹 기반 순위 매기기는 일치하는 시간 단계(timestep)에서의 경로를 비교하는 데 주로 초점을 맞추며, 경로 내부의 의존성은 무시한다. 즉, 특정 초기 디노이징 행동이 지연되고 암묵적인 상호작용을 통해 후속 상태에 영향을 미칠 수 있다는 점을 간과한다. 본 연구에서는 단계별 보상의 희소성을 완화하고, 디노이징 경로 내에서 장기적 영향을 명시적으로 모델링하는 GRPO 프레임워크인 TurningPoint-GRPO(TP-GRPO)를 제안한다. TP-GRPO는 두 가지 핵심 혁신을 도입한다: (i) 결과 기반 보상 대신 단계 수준의 증분 보상(incremental reward)을 도입하여, 각 디노이징 행동의 '순수한' 영향을 보다 정확히 분리할 수 있는 밀도 높고 단계 인식형 학습 신호를 제공하며, (ii) 보상의 국소적 추세를 반전시키는 '전환점(turning point)'을 식별하고, 이러한 단계에 대해 장기적 보상을 집계하여 지연된 영향을 포착한다. 전환점은 증분 보상의 부호 변화(sign change)만을 기반으로 탐지되므로, TP-GRPO는 효율적이며 하이퍼파라미터가 필요 없는 특징을 갖는다. 광범위한 실험을 통해 TP-GRPO가 보상 신호를 더욱 효과적이고 일관되게 활용함을 입증하였으며, 생성 품질이 지속적으로 향상됨을 확인하였다. 데모 코드는 다음 주소에서 확인 가능하다: https://github.com/YunzeTong/TurningPoint-GRPO.
One-sentence Summary
Researchers from institutions including Tsinghua and Alibaba propose TP-GRPO, a GRPO variant that replaces sparse outcome rewards with dense step-level signals and identifies turning points to capture delayed effects, improving text-to-image generation by better modeling denoising trajectory dynamics without hyperparameters.
Key Contributions
- TP-GRPO replaces sparse outcome-based rewards with step-level incremental rewards to isolate the pure effect of each denoising action, reducing reward sparsity and improving credit assignment during RL fine-tuning of Flow Matching models.
- It introduces turning points—steps identified by sign changes in incremental rewards—that flip local reward trends and are assigned aggregated long-term rewards to explicitly model delayed, within-trajectory dependencies critical for coherent image generation.
- Evaluated on standard text-to-image benchmarks, TP-GRPO consistently outperforms prior GRPO methods like Flow-GRPO and DanceGRPO by better exploiting reward signals, with no added hyperparameters and efficient implementation.
Introduction
The authors leverage flow-based generative models and reinforcement learning to address sparse, misaligned rewards in text-to-image generation. Prior methods like Flow-GRPO assign the final image reward uniformly across all denoising steps, ignoring step-specific contributions and within-trajectory dynamics — leading to reward sparsity and local-global misalignment. To fix this, they introduce TurningPoint-GRPO, which computes step-wise rewards via incremental reward differences and explicitly models long-term effects of critical “turning point” steps that reverse local reward trends, enabling more accurate credit assignment without extra hyperparameters.
Method
The authors leverage a modified GRPO framework, TurningPoint-GRPO (TP-GRPO), to address reward sparsity and misalignment in flow matching-based text-to-image generation. The core innovation lies in replacing outcome-based rewards with step-level incremental rewards and explicitly modeling long-term effects via turning points—steps that flip the local reward trend to align with the global trajectory trend. This design enables more precise credit assignment across the denoising trajectory.
The method begins by sampling diverse trajectories using an SDE-based sampler, which injects stochasticity into the reverse-time denoising process. For each trajectory, intermediate latents are cached, and ODE sampling is applied from each latent to completion to obtain corresponding clean images. This allows the reward model to evaluate the cumulative effect of all preceding SDE steps. The step-wise reward rt for the transition from xt to xt−1 is then computed as the difference in reward between the ODE-completed images: rt=R(xt−1ODE(t−1))−R(xtODE(t)). This incremental reward isolates the “pure” effect of each denoising action, providing a dense, step-aware signal that avoids the sparsity inherent in propagating a single terminal reward.
Turning points are identified based on sign changes in these incremental rewards. A timestep t qualifies as a turning point if the local reward trend flips to become consistent with the overall trajectory trend. Specifically, the authors define a turning point using the sign consistency between the local step gain and the cumulative gain from that step to the end. As shown in the figure below, turning points are visually characterized by a local reversal in reward direction that aligns with the global trajectory trend, distinguishing them from normal points that either do not flip or misalign with the global direction.
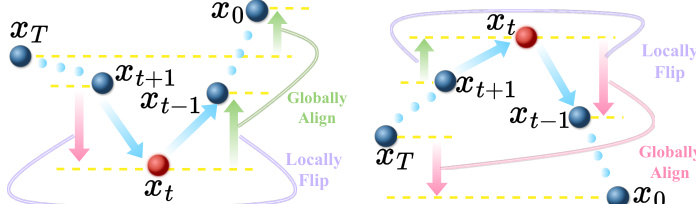
At identified turning points, the local step reward rt is replaced with an aggregated reward rtagg=R(x0)−R(xtODE(t)), which captures the cumulative effect from the turning point to the final image. This aggregated reward encodes the delayed, implicit impact of the denoising action on subsequent steps. The authors further refine this by introducing a stricter criterion—consistent turning points—that requires the aggregated reward to have a larger absolute value than the local reward, ensuring that only steps with significant long-term influence are selected.
To address the exclusion of the initial denoising step from turning point detection, the authors extend the framework via Remark 5.2. The first step is eligible for aggregated reward assignment if its local reward change aligns with the overall trajectory trend. This ensures that early, influential decisions are also modeled for their long-term impact.
The overall training process follows a group-wise ranking scheme. For each timestep, rewards (either rt or rtagg) are normalized across a group of trajectories to compute advantages. The policy is then optimized using a clipped objective that includes a KL regularization term to prevent excessive deviation from the reference policy. A balancing strategy is employed to maintain a roughly equal number of positive and negative aggregated rewards in each batch, preventing optimization bias.
Refer to the framework diagram for a visual summary of the method. The diagram illustrates how step-wise rewards are computed, turning points are identified, and aggregated rewards are assigned to capture long-term effects. It also highlights the inclusion of the initial step via Remark 5.2, ensuring comprehensive modeling of implicit interactions across the entire denoising trajectory.
Experiment
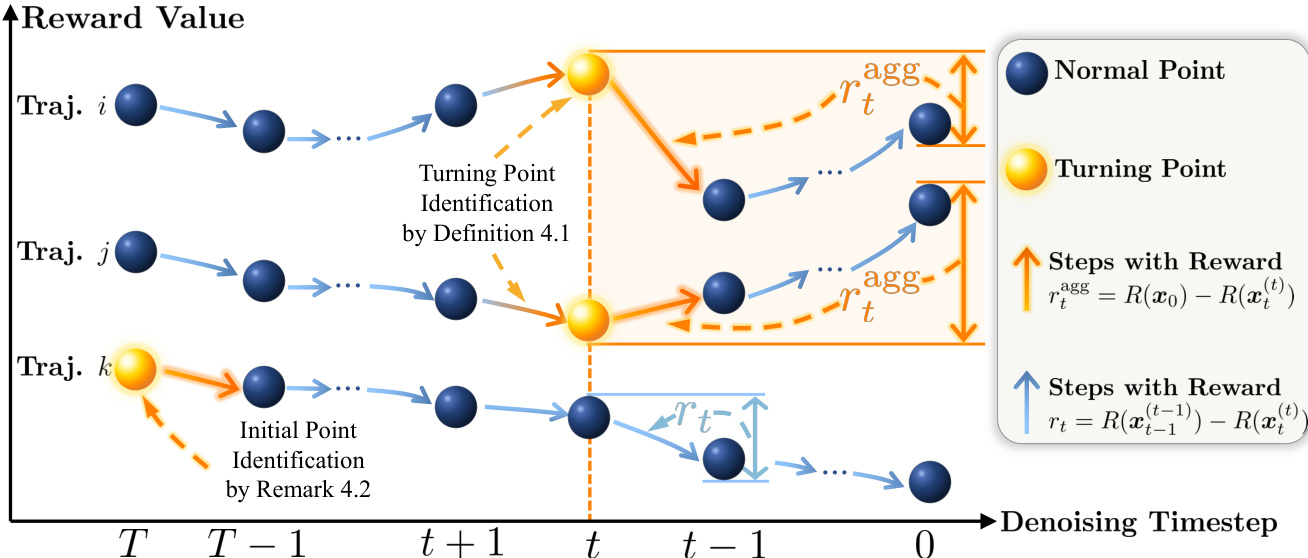
- TP-GRPO variants outperform Flow-GRPO across compositional image generation, visual text rendering, and human preference alignment, with improved accuracy, aesthetics, and content alignment without reward hacking.
- Training without KL penalty confirms TP-GRPO’s stronger exploratory capability and faster convergence, especially on non-rule-based rewards like PickScore.
- Reducing SDE sampling window size moderately (e.g., to 8 steps) improves efficiency and performance, but overly aggressive reduction harms turning-point capture.
- Noise scale α around 0.7 yields optimal stability; both lower and higher values degrade performance, though TP-GRPO remains robust across settings.
- Method generalizes to FLUX.1-dev base model, maintaining superior performance over Flow-GRPO under adjusted hyperparameters.
- Qualitative results show TP-GRPO better handles sparse rule-based rewards, avoids text omissions/overlaps, and produces more semantically coherent and aesthetically aligned outputs.
The authors use TP-GRPO to refine diffusion model training by incorporating step-level rewards and turning-point detection, which consistently improves performance across compositional image generation, visual text rendering, and human preference alignment tasks. Results show that both variants of TP-GRPO outperform Flow-GRPO in task-specific metrics while maintaining or enhancing image quality and preference scores. The method also demonstrates faster convergence and robustness across different base models and hyperparameter settings.