Command Palette
Search for a command to run...
오디세이아레인: 장기적, 능동적, 유도적 상호작용을 위한 대규모 언어모델 평가
오디세이아레인: 장기적, 능동적, 유도적 상호작용을 위한 대규모 언어모델 평가
초록
대규모 언어 모델(LLM)의 급속한 발전은 복잡한 환경을 탐색할 수 있는 자율 에이전트의 개발을 촉진해왔다. 그러나 기존의 평가 방법은 주로 추론적(paradigm) 접근을 취하는데, 이는 에이전트가 명시적으로 제공된 규칙과 정적 목표에 기반해 작업을 수행하며 제한된 계획 수평 내에서 작동하도록 설계되어 있다. 중요한 점은 이러한 접근이 경험을 통해 은닉된 전이 법칙을 자율적으로 탐색할 필요성—즉, 에이전트의 전망력(foresight)을 가능하게 하고 전략적 일관성을 유지하는 데 핵심적인 역할을 하는 인과적(인도적) 탐색 능력—을 간과하고 있다는 것이다. 이러한 격차를 메우기 위해 우리는 장기적 계획 수평, 능동적이고 인도적인 상호작용을 중심에 두는 'OdysseyArena'를 제안한다. 우리는 추상적인 전이 역학(dynamic)을 구체적인 상호작용 환경으로 전환하기 위해 네 가지 기본(primitive) 요소를 체계화하고 구현하였다. 이를 바탕으로 표준화된 벤치마킹을 위한 'OdysseyArena-Lite'를 구축하였으며, 에이전트의 인도적 효율성과 장기적 탐색 능력을 측정할 수 있는 120개의 작업을 제공한다. 더 나아가, 극한의 상호작용 수평(예: 200단계 이상)에서 에이전트의 안정성을 시험할 수 있도록 'OdysseyArena-Challenge'를 도입하였다. 15개 이상의 선도적 LLM에 대한 광범위한 실험 결과, 심지어 최첨단 모델들조차도 인도적 시나리오에서는 부족함을 보이며, 복잡한 환경에서 자율적 탐색을 추구하는 데 있어 핵심적인 성능 제약 요소를 확인할 수 있었다. 본 연구의 코드와 데이터는 https://github.com/xufangzhi/Odyssey-Arena 에서 공개되어 있다.
One-sentence Summary
Fangzhi Xu, Hang Yan, Qiushi Sun et al. propose ODYSSEYARENA, a novel evaluation framework emphasizing inductive, long-horizon agent interactions, contrasting prior deductive methods; it introduces ODYSSEYARENA-LITE and -CHALLENGE benchmarks, revealing critical LLM limitations in autonomous discovery across complex environments.
Key Contributions
- We introduce ODYSSEYARENA, a new evaluation framework that shifts agent assessment from deductive task execution to inductive discovery of latent environment dynamics over long interaction horizons, addressing a critical gap in current benchmarks.
- We formalize and implement four structural primitives—discrete rules, stochastic dynamics, periodic patterns, and relational dependencies—into concrete environments, and provide ODYSSEYARENA-LITE (120 tasks) and ODYSSEYARENA-CHALLENGE (>200-step tasks) for standardized and stress testing.
- Experiments across 15+ leading LLMs reveal significant deficiencies in inductive reasoning and long-horizon stability, even among frontier models, exposing a key bottleneck in autonomous agent development despite commercial models outperforming open-source ones.
Introduction
The authors leverage the growing role of LLMs in autonomous agents to address a critical gap in evaluation: most benchmarks test deductive reasoning under static rules and short horizons, failing to measure how agents discover hidden dynamics through active, long-term interaction. Prior work often bypasses exploration, limits task length to under 50 steps, and assumes pre-specified goals—ignoring the inductive reasoning needed for real-world deployment. Their main contribution is ODYSSEYARENA, a benchmark suite that formalizes four structural primitives of environment dynamics (discrete rules, stochastic systems, multi-objective patterns, relational graphs) and instantiates them in interactive environments. They introduce ODYSSEYARENA-LITE for standardized evaluation across 120 tasks and ODYSSEYARENA-CHALLENGE for stress-testing agents over 1,000+ steps, revealing that even top LLMs struggle with inductive discovery—highlighting a fundamental bottleneck in current agentic intelligence.
Dataset
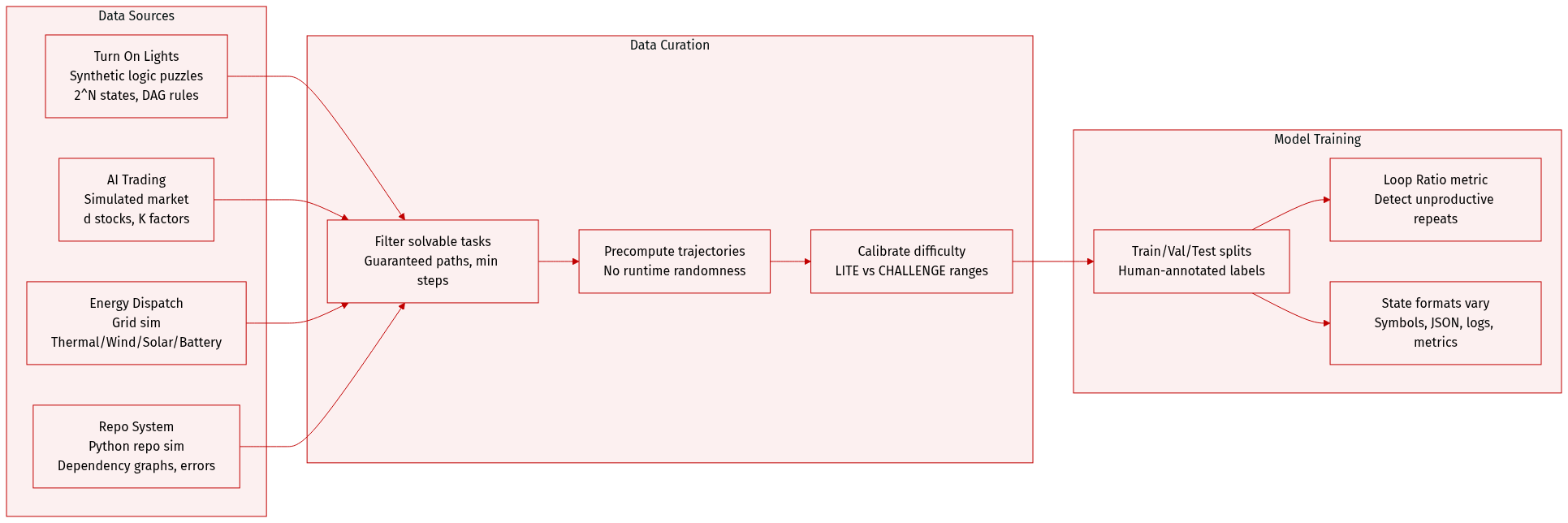
The authors use ODYSSEYARENA to build two benchmark suites—ODYSSEYARENA-LITE for efficient evaluation and ODYSSEYARENA-CHALLENGE for stress-testing long-horizon reasoning. Both are derived from deterministic task instances sampled from bounded parameter distributions, ensuring reproducibility and solvability.
Key dataset subsets and their details:
-
Turn On Lights:
- Size: Scalable via state space N (lights), generating 2^N possible states.
- Source: Synthetic logic puzzles with DAG-based rules using {∧, ∨, ¬} operators.
- Filtering: Only instances with guaranteed solution paths and minimum step thresholds are retained.
- Action: Single integer index per step.
- Metadata: Fixed trajectory, visual state symbols, system prompt with goal and rules.
-
AI Trading:
- Size: Controlled via stock count d and market factors K.
- Source: Simulated market with linear factor models and noise (ε).
- Filtering: All tasks are resolvable; diversity comes from sparsity of W matrix and SNR adjustments.
- Action: Sell then buy in one step, formatted as JSON.
- Metadata: Daily prices, holdings, cash, news hints, and predictive signals.
-
Energy Dispatch:
- Size: Modulated by daily dynamics and generation types (thermal, wind, solar, battery).
- Source: National grid simulation with fixed unit costs and capacity limits.
- Filtering: All tasks solvable; constraints include budget, demand, carbon, and stability.
- Action: Plan all four generation types per step; battery charge/discharge mutually exclusive.
- Metadata: Daily status, previous results, demand, next-day budget, and dynamic thresholds.
-
Repo System:
- Size: Configurable via dependency graph density and package versions.
- Source: Simulated Python repo with partial info, runtime failures, and non-monotonic side effects.
- Filtering: Solution-first generation ensures ground-truth version paths exist.
- Action: Single command string per step.
- Metadata: Execution result (success/error), structured history with command feedback.
Processing and usage:
- All environments use deterministic trajectories: dynamic factors (e.g., daily fluctuations, efficiency curves) are precomputed to eliminate runtime randomness.
- Task difficulty is calibrated via parameter ranges—LITE uses tractable settings, CHALLENGE pushes to empirical limits.
- Training splits and mixture ratios are not explicitly defined in the text, but evaluation uses human-annotated labels from 4 independent raters per example.
- Human annotation: Annotators are AI students compensated $15/hour; inter-rater reliability measured via Fleiss’ Kappa (discrete tasks) and ICC (continuous profit in AI Trading).
- Loop Ratio metric tracks unproductive action repetition in Turn On Lights and Repo System to evaluate inductive reasoning failure.
- State representations vary: symbolic visuals (Lights), structured financial data (Trading), daily metrics (Energy), and execution logs (Repo).
- No cropping is mentioned; all metadata is constructed to preserve full context for each environment’s unique constraints and feedback loops.
Method
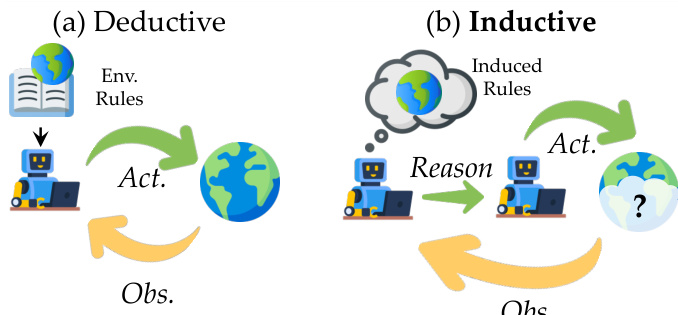
The authors leverage a structured benchmark framework, ODYSSEYARENA, designed to evaluate an agent’s capacity for inductive world-modeling across four distinct environment primitives. Each environment imposes unique latent structural constraints that require the agent to autonomously infer transition dynamics rather than operate under known rules. The overall architecture is modular, with each environment encapsulating its own state transition logic, observation space, and action space, while sharing a common interaction protocol with the agent.
Refer to the framework diagram illustrating the core distinction between deductive and inductive reasoning paradigms. In the deductive setting, the agent operates with explicit knowledge of environment rules, whereas in the inductive setting—central to ODYSSEYARENA—the agent must reason over observations to induce latent rules before acting. This inductive loop forms the foundation of all four environments, where the agent iteratively observes state changes, hypothesizes transition functions, and refines its policy through strategic intervention.
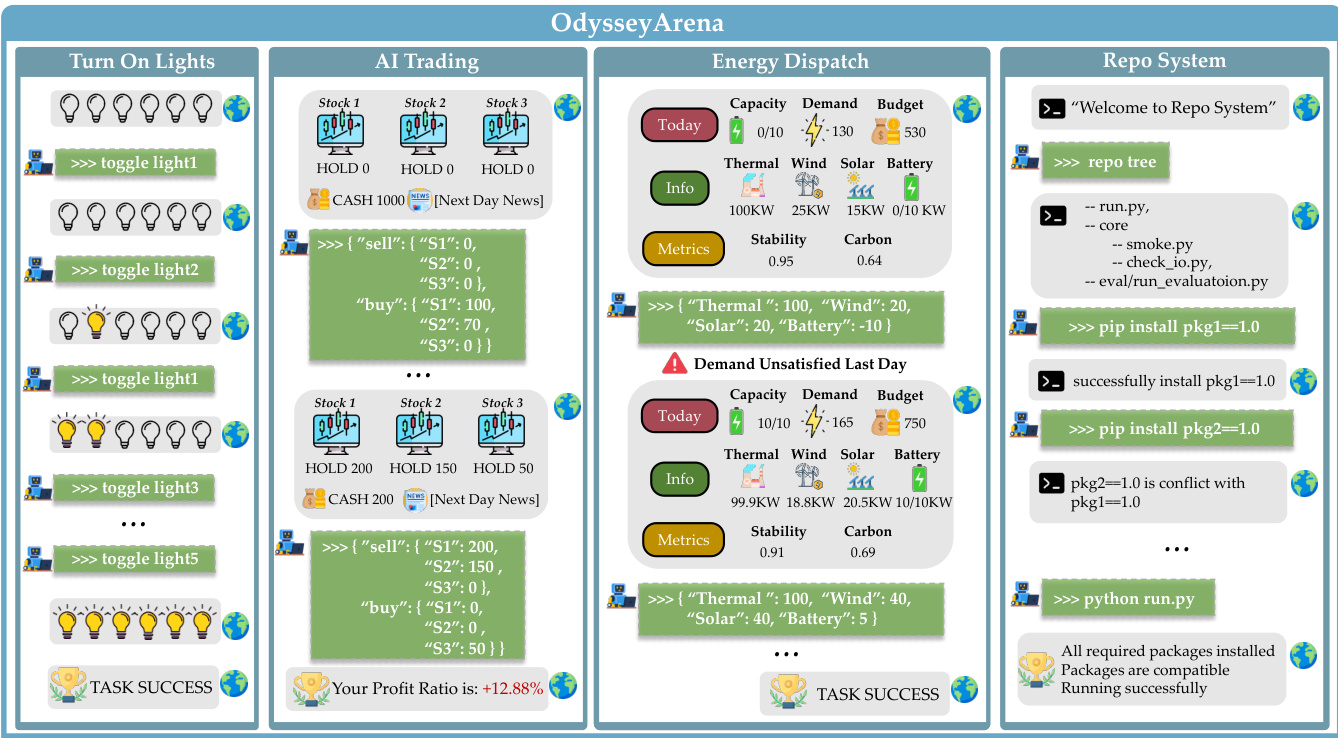
The first environment, Turn On Lights, instantiates discrete symbolic rules. The agent interacts with a network of N lights governed by latent Boolean logic. Each light Li has an activation condition ϕi defined over lights with lower indices, ensuring a strict partial order. The transition function toggles light i only if ϕi(st)=True, introducing non-monotonic dynamics. The agent observes the full state vector st∈{0,1}N after each action but must infer the hidden logical dependencies through systematic toggling. The environment enforces a random mapping of light IDs to obscure any numerical ordering, forcing inductive reasoning over causal chains.
The second environment, AI Trading, models continuous stochastic dynamics. Asset returns evolve as st+1=Wzt+ϵ, where W∈Rd×K is a latent factor loading matrix mapping unobserved market factors zt to asset returns, and ϵ is Gaussian noise. The agent observes historical prices and news-derived indicators as proxies for zt, and must issue combinatorial buy/sell actions across d assets. The transition logic updates the portfolio state and computes reward based on cumulative returns, adjusted for transaction costs. Success requires the agent to estimate W from noisy observations and execute long-horizon strategies.
The third environment, Energy Dispatch, embodies periodic temporal patterns. The agent allocates power across thermal, wind, solar, and battery resources to meet daily demand under budget constraints. The actual output Preal is modulated by a time-varying efficiency vector Et, where wind and solar efficiencies follow distinct hidden periodic functions Et≈Et+T with randomly sampled periods T∈[15,25]. The efficiency is generated hierarchically: a base pattern with stochastic spikes, cyclic offsets per full cycle, and micro-fluctuations, all clipped to realistic ranges. The agent observes demand Dt and budget Bt, and must infer the latent periodic structure from historical output gaps to plan over a 120-day horizon without triggering early termination.
The fourth environment, Repo System, encodes relational graph structures. The agent navigates a latent dependency graph G=(V,E), where nodes represent package versions and edges encode compatibility constraints. Actions are symbolic shell commands (e.g., pip install) that trigger a resolution process: the system automatically installs dependencies, upgrades/downgrades conflicting packages, or pins versions to maintain local consistency. This induces non-monotonic side effects, where the order of actions affects the final state. The agent observes terminal outputs and execution logs, which reveal only broken edges (e.g., ImportError), and must reason over the hidden graph topology to achieve global consistency.
As shown in the figure below, each environment presents a distinct interaction trajectory: Turn On Lights involves toggling lights to reach a target state; AI Trading requires portfolio reallocation based on market signals; Energy Dispatch demands resource allocation under temporal efficiency cycles; and Repo System necessitates dependency resolution through symbolic commands. All environments share a common evaluation protocol: success is binary and requires global task completion, not partial fixes.
The benchmark architecture, as illustrated in the system diagram, consists of two main components: environment configuration and agent interaction. The environment is initialized via a manual-crafted configuration that supports difficulty control, followed by a task generator that produces config files with auto-validation. The LLM agent interacts with the environment through an API-based interface, which manages the step-by-step loop: the agent receives observations, generates thought and action, and the environment updates state and returns new observations. The loop continues until the task is evaluated for success or failure, with working memory maintaining context across steps.
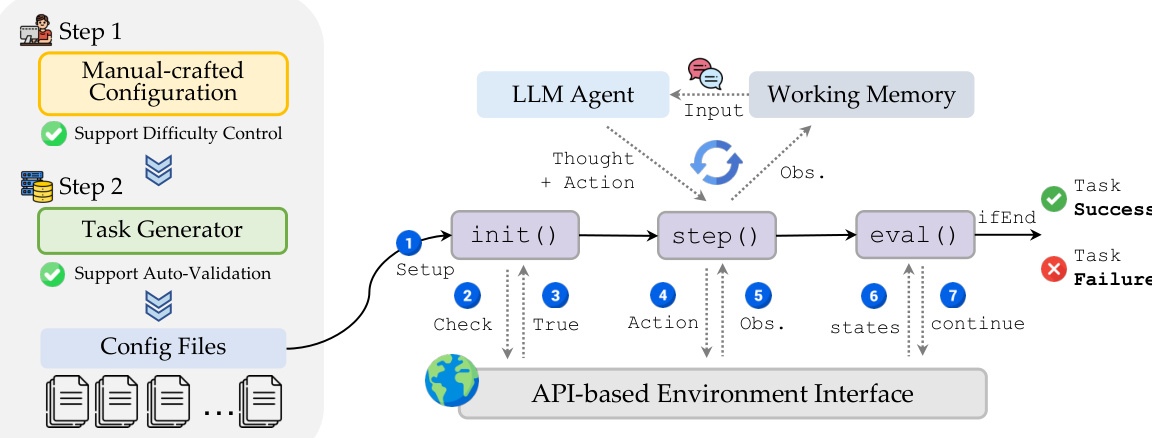
Experiment
- Evaluated 15+ LLMs on ODYSSEYARENA-LITE, revealing a consistent gap between human and model performance due to LLMs’ inability to autonomously induce latent environment rules.
- Proprietary models (e.g., Gemini 3 Pro Preview) lead in performance but still fail in complex tasks like Energy Dispatch, exposing a shared architectural limitation in modeling long-term periodic patterns.
- LLMs excel in deductive reasoning when rules are provided but severely underperform without them, confirming that inductive world-modeling—not task logic—is the core bottleneck.
- Performance plateaus with extended interaction steps, indicating that more trials do not overcome the absence of internal world models; weaker models sometimes underperform random baselines.
- Persistent “action loops” and failure to credit feedback to hidden constraints reveal inductive stagnation, especially in long-horizon scenarios.
- A rigid inductive ceiling exists: even top models fail 6+ high-complexity tasks unsolved by any LLM, highlighting scaling limits in world-structure discovery.
- ODYSSEYARENA-CHALLENGE (1,000+ steps) confirms long-horizon reasoning remains an unsolved challenge, exposing failure modes like credit assignment decay and planning compounding errors.
- Increased reasoning budget improves inductive performance slightly, but does not close the fundamental gap; token efficiency varies significantly across models and environments.
- Human agents outperform all LLMs across all environments, particularly in discovering hidden dependencies and adapting strategies over time.
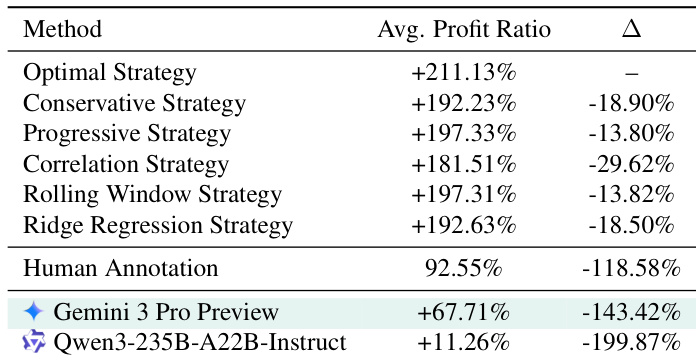
The authors evaluate LLMs on a financial trading task where success depends on inferring hidden market dynamics over 120 steps. Results show that even top models like Gemini 3 Pro Preview and Qwen3-235B-A22B-Instruct underperform human annotators and simple rule-based strategies, with performance gaps exceeding 100 percentage points in profit ratio. This highlights a persistent inductive reasoning deficit in current LLMs when synthesizing long-horizon, latent environmental rules from sparse feedback.
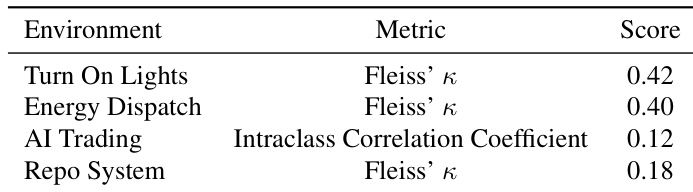
The authors use Fleiss’ κ and intraclass correlation to measure inter-model agreement across four environments, revealing low to moderate consensus among LLMs. Results show that agreement is highest in Turn On Lights and Energy Dispatch, but drops sharply in AI Trading and Repo System, indicating greater divergence in how models interpret complex, multi-constraint tasks. This suggests that task structure and hidden rule complexity significantly influence model behavior consistency.
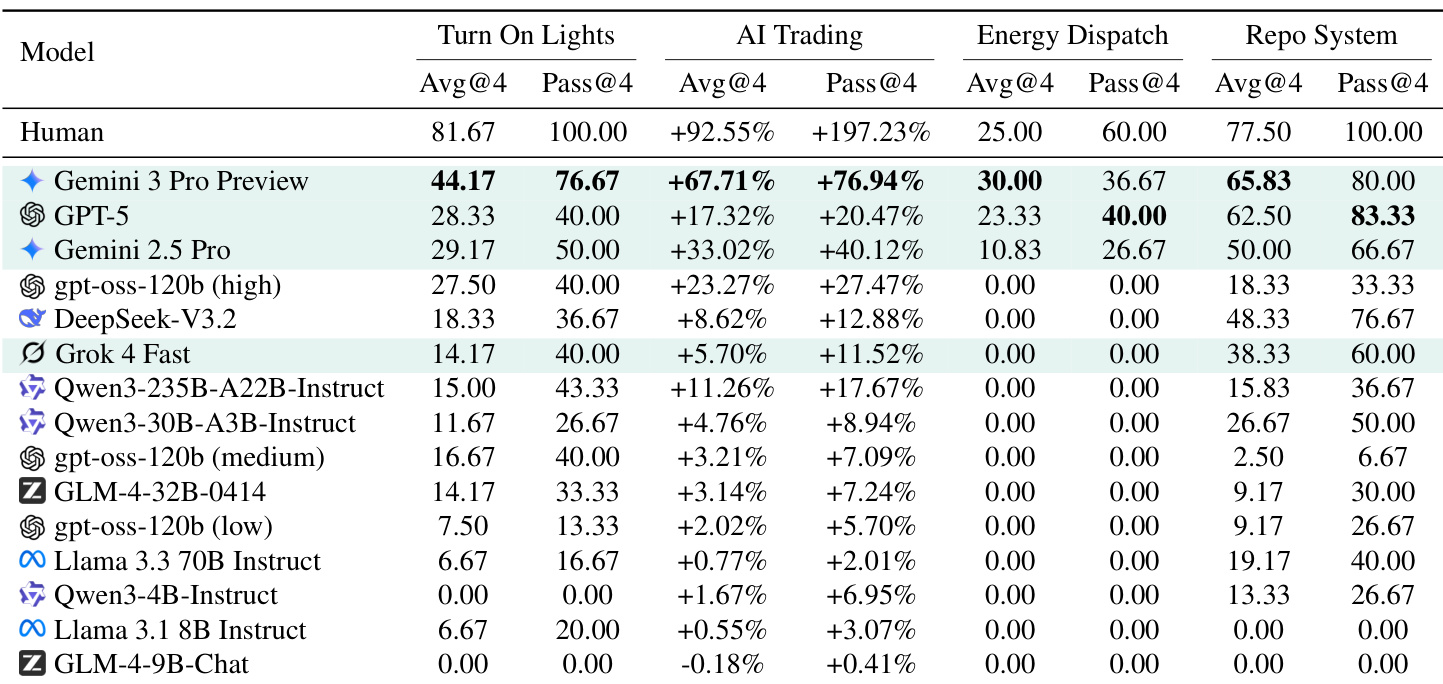
The authors evaluate multiple large language models on a multi-environment benchmark requiring inductive reasoning to discover hidden rules, finding that even top proprietary models significantly underperform humans and struggle to autonomously infer environment dynamics. Results show that while models excel when rules are provided, their inductive capacity remains limited, especially in long-horizon or complex tasks like Energy Dispatch, where no model achieves success. Performance plateaus with extended interaction, indicating that increased steps or scale alone cannot overcome the fundamental bottleneck in world-modeling from trial-and-error feedback.
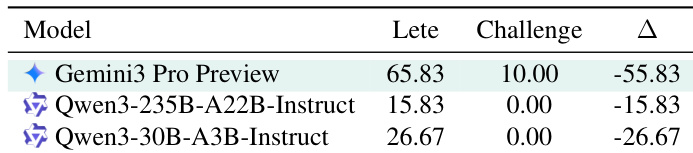
The authors evaluate multiple LLMs on a structured benchmark with varying task complexity, revealing that even top-performing models like Gemini 3 Pro Preview show a sharp performance drop when transitioning from standard to long-horizon challenge settings. Results indicate that current LLMs struggle with inductive reasoning over extended interaction sequences, regardless of scale or architecture, highlighting a fundamental limitation in autonomous world-modeling. This gap persists even for models that excel in deductive tasks when explicit rules are provided.
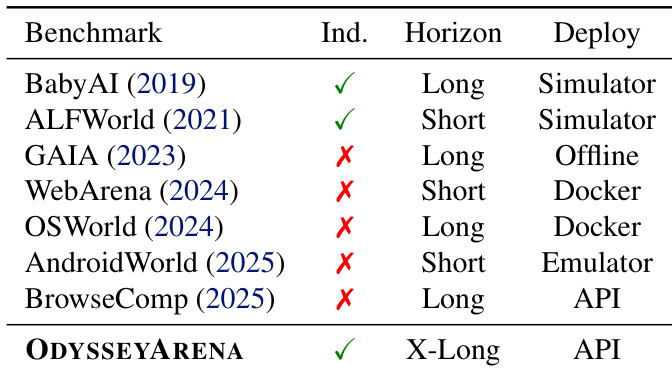
The authors introduce ODYSSEYARENA as a benchmark that uniquely combines inductive reasoning, extended interaction horizons, and API-based deployment, distinguishing it from prior benchmarks that lack one or more of these dimensions. Results show that even top-tier LLMs struggle with long-horizon inductive tasks, revealing a persistent gap between deductive reasoning and autonomous world-modeling. This highlights a fundamental limitation in current agents: they fail to synthesize latent environment rules from experience, regardless of scale or interaction budget.