Command Palette
Search for a command to run...
ASA: 도구 호출 도메인 적응을 위한 활성화 조정
ASA: 도구 호출 도메인 적응을 위한 활성화 조정
Youjin Wang Run Zhou Rong Fu Shuaishuai Cao Hongwei Zeng Jiaxuan Lu Sicheng Fan Jiaqiao Zhao Liangming Pan
초록
일반 목적의 LLM 에이전트의 실세계 도입을 위한 핵심 과제는 도구 사용 자체가 아니라, 빠르게 변화하는 도구 세트, API 및 프로토콜 환경에서의 효율적인 도메인 적응에 있다. 다양한 도메인에서 반복적으로 LoRA 또는 SFT를 적용할 경우, 학습 및 유지보수 비용이 지수적으로 증가하게 되며, 프롬프트 기반 또는 스키마 기반 접근법은 분포 변화나 복잡한 인터페이스 환경에서는 취약하다. 본 연구에서는 중간 활성화 값에서 라우팅 신호를 읽어내고, 초경량 라우터를 활용하여 정밀한 도메인 정렬을 위한 적응형 제어 강도를 생성하는 경량적이고 추론 시점에서 작동하며, 학습이 필요 없는 기법인 활성화 안내 어댑터(Activation Steering Adapter, ASA) 를 제안한다. 다양한 모델 규모와 도메인에서 ASA는 LoRA 수준의 적응 성능을 달성하면서도 훨씬 낮은 부하를 가지며, 다중 모델 간 강력한 전이 성능을 보여주어, 빈번한 인터페이스 변화 동역학을 겪는 복잡하고 확장 가능한 다중 도메인 도구 생태계에 있어 강건하고 효율적이며 실용적인 솔루션으로 적합하다.
One-sentence Summary
Wang, Zhou et al. propose Activation Steering Adapter (ASA), a training-free inference controller that steers LLMs toward reliable tool use via mid-layer intervention, closing the representation-behavior gap and boosting F1 from 0.18 to 0.50 on MTU-Bench with minimal overhead.
Key Contributions
- We identify a "Lazy Agent" failure mode where tool necessity is nearly perfectly decodable from mid-layer activations, yet the model fails to trigger tool mode due to a representation-behavior gap under strict parsing constraints.
- We propose Activation Steering Adapter (ASA), a training-free inference-time controller that uses a router-conditioned mixture of steering vectors and a probe-guided signed gate to amplify true intent and suppress spurious triggers with minimal overhead.
- On MTU-Bench with Qwen2.5-1.5B, ASA boosts strict tool-use F1 from 0.18 to 0.50 and cuts false positives from 0.15 to 0.05, using only 20KB of assets and no weight updates.
Introduction
The authors leverage the observation that large language models often encode tool-use intent in mid-layer activations but fail to trigger tool mode due to a representation-behavior gap—where latent intent doesn’t translate into discrete action under strict parsing. Prior approaches either rely on fragile prompt engineering or costly parameter-efficient fine-tuning, both of which scale poorly with evolving tool schemas and risk forgetting or brittleness. Their main contribution is ASA, a training-free inference-time controller that injects a single mid-layer intervention using a router-conditioned mixture of steering vectors and a probe-guided signed gate to amplify true intent while suppressing spurious triggers. This approach improves strict tool-use F1 by over 170% on MTU-Bench with Qwen2.5-1.5B, reduces false positives by 67%, and requires only 20KB of portable assets—enabling robust, scalable tool adaptation without weight updates.
Dataset

- The authors use a 1,600-sample multi-domain benchmark covering MATH, CODE, SEARCH, and TRANSLATION, built from public instruction-following and QA datasets including Alpaca and Natural Questions.
- Each sample is filtered into Tool-Necessary and Non-Tool pairs using domain-specific rules, with tool usage validated via explicit markers in the output.
- The evaluation set is randomly subsampled to 1,600 instances—an engineering choice that scales to larger corpora—and is used strictly for testing, not training.
- Tool call detection is binary: a call is counted only if the output contains .
- Metrics include Precision, Recall, F1, Accuracy, and FPR (Non-Tool trigger rate), plus Success Precision (P_succ), which requires JSON validity, schema consistency, and valid arguments.
- Hyperparameters L, α, and τ are tuned on validation data: L via probe sweep (best AUC), α via F1 optimization, and τ via grid search (0.50–0.70), then fixed for test.
- Routers and probes are trained only on training data; vector representations use only the CAL dataset.
Method
The authors leverage ASA, an inference-time intervention mechanism, to dynamically control whether a frozen large language model enters tool-invocation mode. The method operates without modifying model parameters, instead applying a single, signed perturbation to the hidden state at a selected intermediate layer—typically layer 18—during the pre-fill pass. This intervention is designed to be lightweight, reversible, and domain-aware, enabling precise steering of tool-use behavior while preserving the model’s original capabilities.
The core architecture of ASA comprises three lightweight components: a domain router, per-domain intent probes, and a set of steering vectors. At inference time, ASA first extracts the last-token hidden state hL(x) from the Pre-LN residual stream at layer L. This representation is then standardized using training-set statistics to yield h~L(x), which serves as input to the router. The router, a small linear classifier, maps the standardized representation to a predicted domain d^ by computing d^=argmaxdsoftmax(Wrh~L(x)+br)d. Concurrently, a domain-specific linear probe computes an intent probability p(x)=σ(wd^⊤hL(x)+bd^), estimating the likelihood that a tool invocation is appropriate for the given input.
Refer to the framework diagram, which illustrates how ASA integrates these components into a single-shot intervention pipeline. The method constructs a Mixture-of-Vectors (MoV) direction by combining a domain-specific steering vector v^d^ with a global intent vector v^global, scaled by a hyperparameter β: MoV(hL(x))=v^d^+βv^global. The global vector is derived from the difference between class-conditional means of tool-necessary and non-tool hidden states, while domain vectors are computed analogously within each domain. Both are unit-normalized to ensure consistent scaling.
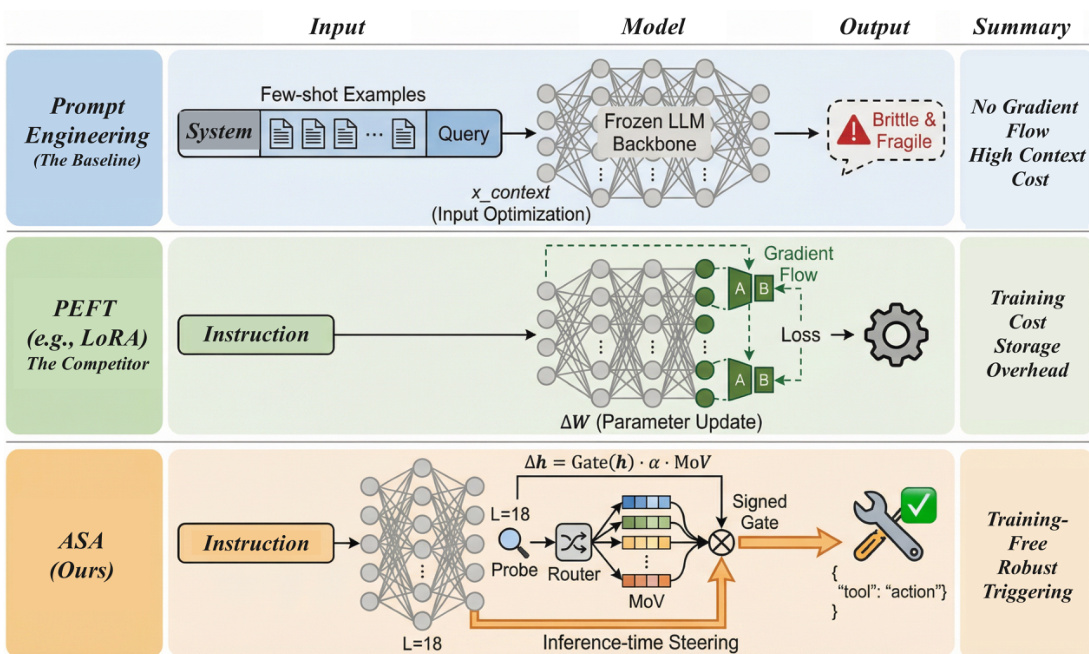
The intervention is gated by the probe’s confidence: a ternary signal Gate(hL(x)) is computed as +1 if p(x)>τ, −1 if p(x)<1−τ, and 0 otherwise, where τ∈(0.5,1) is a validation-selected threshold. The final perturbation is then applied as Δh=Gate(hL(x))⋅α⋅MoV(hL(x)), where α≥0 controls the intervention strength. This signed injection modifies the hidden state only once, before continuing the forward pass from layer L through the remaining layers and autoregressive decoding.
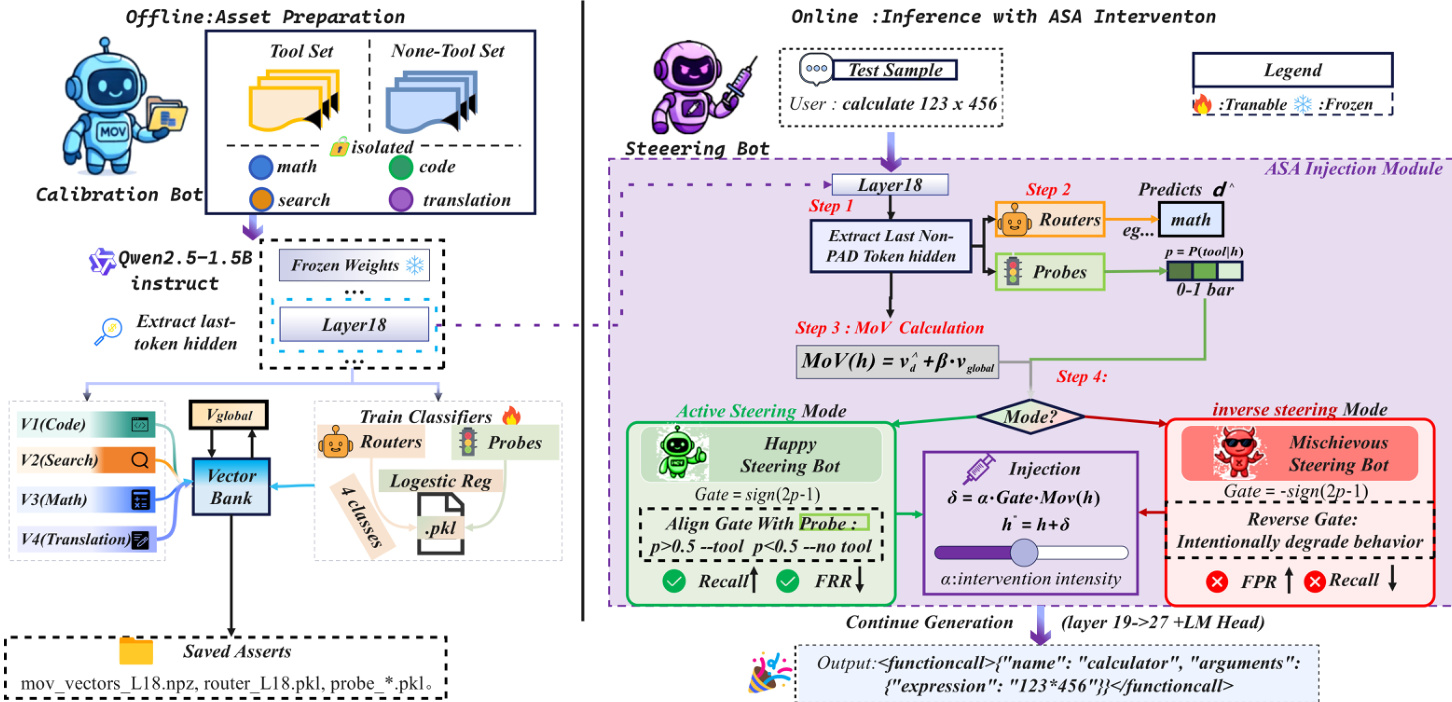
As shown in the figure below, the offline phase involves calibrating the steering vectors, routers, and probes using a disjoint dataset, with all assets saved for inference. During online inference, the ASA module extracts the layer-18 hidden state, routes the input, computes the MoV, evaluates the gate, and applies the perturbation if warranted. The system supports both “happy steering” (enhancing tool recall) and “inverse steering” (suppressing false positives) by flipping the gate sign, enabling fine-grained control over tool-use behavior without retraining.
Experiment
- ASA validates that tool intent is linearly decodable in mid-layer activations and can be causally manipulated via targeted direction vectors to influence early trigger logits.
- Domain-specific intent vectors reduce cross-domain interference, supporting modular routing for improved schema consistency and reduced false triggers.
- Probe-guided gating is essential for safety, suppressing spurious tool-mode activation on non-tool inputs while preserving recall on necessary cases.
- ASA achieves better recall-FPR trade-offs than prompt-only or PEFT baselines, particularly under strict parsing, without corrupting post-trigger output validity.
- The method is training-free, lightweight, and portable, requiring only small steering vectors and linear controllers, making it suitable for dynamic deployment environments.
- Optimal intervention depth varies with model scale, and ASA transfers only when the base model already possesses latent tool-calling capability.
- Ablations confirm that gains stem from structured, intent-aligned control—not random perturbations—and that combining global and domain-specific directions yields best performance.
- Strict evaluation protocols ensure gains reflect genuine behavioral control, not sampling variance or relaxed parsing, aligning closely with real-world deployment requirements.
The authors use a linear probe at Layer 18 to assess tool intent decodability across Qwen2.5 models of varying sizes, finding near-perfect AUC scores that indicate tool intent is linearly separable in mid-layer activations regardless of scale. Results show this decodability is statistically significant across all tested model sizes, supporting the feasibility of steering-based control for tool-calling behavior. However, high AUC alone does not guarantee correct tool execution, as behavior requires strict output formatting and schema compliance beyond mere intent detection.

The authors use prompt-only baselines to establish a performance floor under strict tool-triggering constraints, showing that even few-shot prompting increases recall at the cost of significantly higher false triggers. Removing system specifications entirely causes tool mode to collapse, confirming that input-level methods are brittle under protocol changes. These results highlight the need for structured, inference-time control mechanisms to reliably trigger tool use without degrading precision.

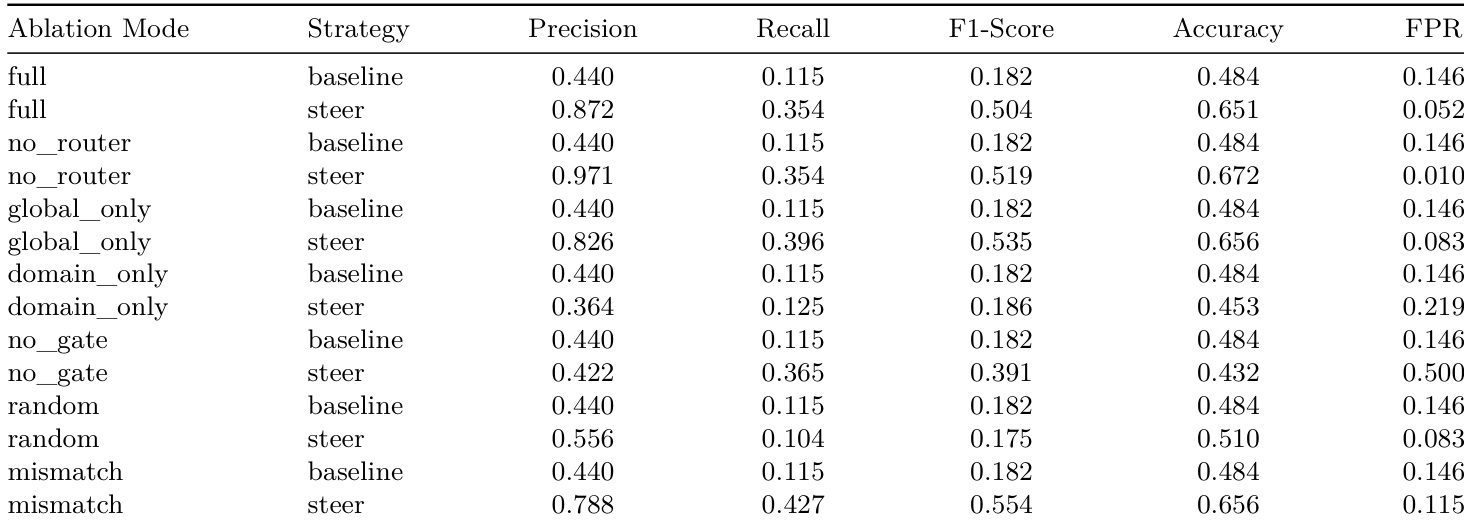
The authors use ablation experiments to isolate the contributions of each component in their steering framework, showing that the full system achieves the best balance of precision, recall, and FPR. Removing the probe-guided gate causes a sharp rise in false positives, confirming its role as a critical safety mechanism, while using only global or domain-specific directions alone leads to suboptimal trade-offs. Random or mismatched directions fail to improve performance, indicating that structured, intent-aligned interventions are necessary for effective control.
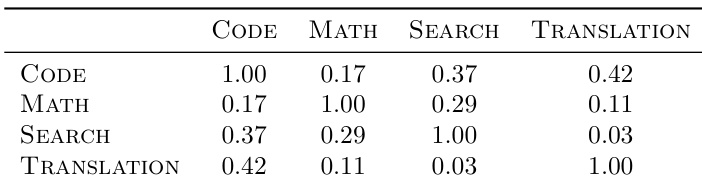
The authors use domain-specific intent vectors to steer tool-calling behavior and find that these vectors exhibit low cosine similarity across domains, indicating distinct geometric representations. This supports the design choice to route interventions per domain rather than relying on a single global direction, as cross-domain interference would otherwise degrade schema consistency. Results confirm that domain-aware steering reduces unintended activation in unrelated contexts while preserving task-specific tool invocation.
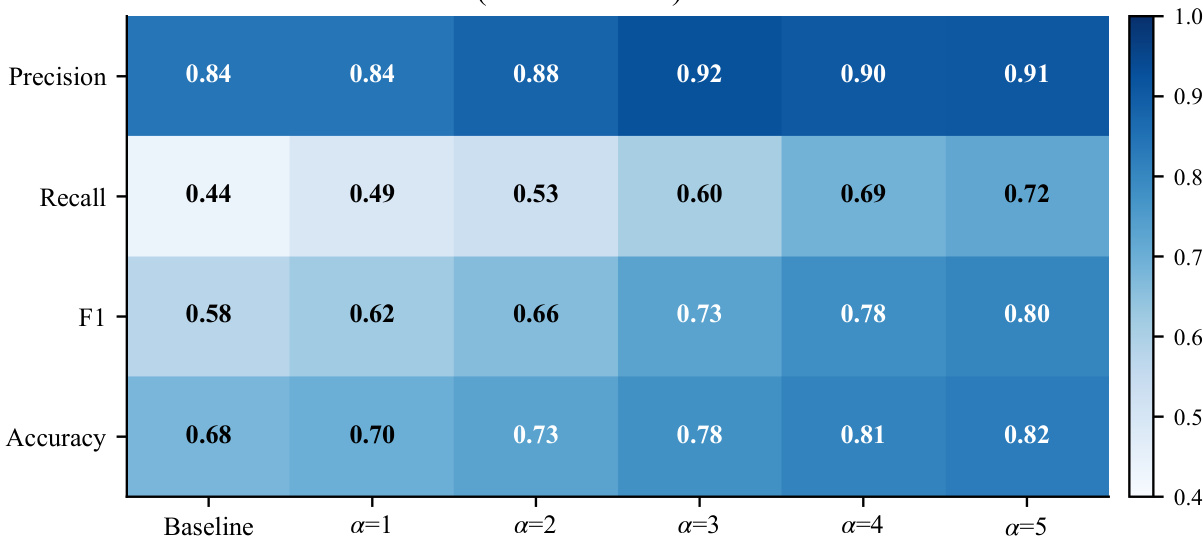
The authors use a steering parameter α to modulate tool-triggering behavior, observing that increasing α improves recall and F1 while maintaining or slightly improving precision, indicating selective amplification of tool intent rather than indiscriminate triggering. Results show that moderate α values strike the best balance, with higher values risking precision loss due to spurious triggers, validating the need for probe-guided gating to preserve control. The consistent gains across metrics confirm that activation steering effectively bridges the gap between latent intent and strict behavioral execution under deterministic parsing.