Command Palette
Search for a command to run...
13개의 파라미터에서 추론하는 법을 배우기
13개의 파라미터에서 추론하는 법을 배우기
John X. Morris Niloofar Mireshghallah Mark Ibrahim Saeed Mahloujifar
초록
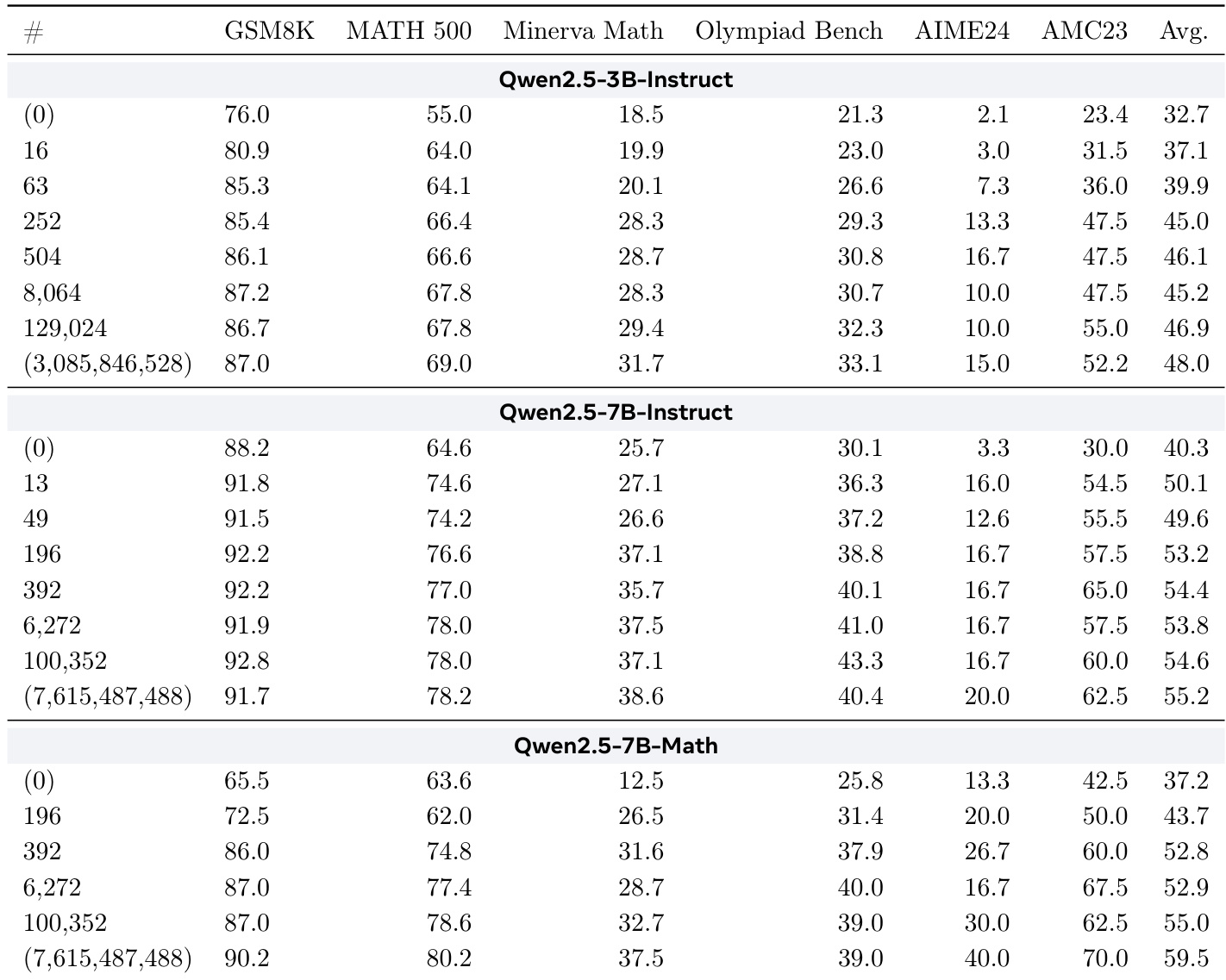
최근 연구에 따르면, 언어 모델은 강화 학습을 통해 추론 능력을 학습할 수 있음이 밝혀졌다. 일부 연구에서는 추론을 위한 낮은 랭크 파라미터화를 적용하기도 하나, 기존의 LoRA는 모델 차원 이하로는 확장되지 않는다. 우리는 추론을 학습하는 데 랭크=1의 LoRA조차 필수적인지에 대해 의문을 제기하며, 단 하나의 파라미터 규모까지 낮은 랭크 어댑터를 확장할 수 있는 TinyLoRA를 제안한다. 새로운 파라미터화 방식을 통해, Qwen2.5의 8B 파라미터 규모 모델을 bf16 형식으로 단 13개의 훈련 파라미터(총 26바이트)로 사용하여 GSM8K에서 91%의 정확도를 달성할 수 있었다. 이 경향은 일반적으로도 성립함을 확인했다. AIME, AMC, MATH500과 같은 더 어려운 추론 학습 벤치마크 세트에서, 훈련 파라미터 수를 줄이면서도 성능 향상의 약 90%를 회복할 수 있었다. 특히 주목할 점은, 이러한 뛰어난 성능을 달성하기 위해 강화 학습(RL)이 필수적이라는 점이다. 반면, SFT(Supervised Fine-Tuning)로 훈련된 모델은 동일한 성능에 도달하기 위해 더 큰 업데이트가 필요하다.
One-sentence Summary
Researchers from FAIR at Meta, Cornell, and CMU propose TinyLoRA, enabling reasoning in 8B-parameter Qwen2.5 with just 13 trained parameters via RL—achieving 91% GSM8K accuracy—by exploiting RL’s information-dense updates, unlike SFT, and scaling low-rank adaptation to near-zero parameter regimes.
Key Contributions
- TinyLoRA enables effective reasoning in large language models using as few as 13 trained parameters by scaling low-rank adapters below rank=1, achieving 91% accuracy on GSM8K with Qwen2.5-8B via reinforcement learning.
- The method demonstrates consistent efficiency across challenging benchmarks like AIME and MATH500, recovering 90% of performance gains while training 1000x fewer parameters than conventional approaches, but only when using RL—not supervised finetuning.
- Empirical results show that large models trained with RL require dramatically smaller parameter updates to reach high performance, revealing that reasoning capabilities can be unlocked with updates under 1KB, a scale previously considered insufficient.
Introduction
The authors leverage reinforcement learning to show that large language models can learn complex reasoning tasks with astonishingly few parameters—down to just 13 trainable parameters in some cases. Prior low-rank adaptation methods like LoRA typically operate at scales of 10K to 10M parameters and struggle to scale below model dimension, limiting their efficiency for extreme parameter constraints. TinyLoRA, their proposed method, enables effective adaptation at sub-kilobyte scales by exploiting the inherent low intrinsic dimensionality of overparameterized models under RL, outperforming supervised fine-tuning which requires 100–1000x more parameters to match performance. Their work demonstrates that RL, not SFT, unlocks this extreme efficiency—especially when applied to large backbones—challenging assumptions about how much parameter update is actually needed to teach reasoning.
Method
The authors leverage a parameter-efficient fine-tuning framework built upon low-rank adaptation techniques, introducing TinyLoRA as a method to drastically reduce the number of trainable parameters while preserving model performance. The core idea stems from the observation that even minimal-rank adaptations like LoRA-XS still require at least one parameter per module, which becomes prohibitive when scaling across many layers and attention/MLP components in large transformer architectures.
TinyLoRA redefines the low-rank update by replacing the trainable matrix R∈Rr×r in LoRA-XS with a low-dimensional trainable vector v∈Ru, projected through a fixed random tensor P∈Ru×r×r. The updated weight matrix becomes:
W′=W+UΣ(i=1∑uviPi)V⊤where U,Σ,V are derived from the truncated SVD of the original frozen weight matrix W. This formulation allows each module to be adapted with only u trainable parameters, independent of the model width d or rank r.
To further minimize parameter count, the authors implement weight tying across modules. In standard transformer architectures such as LLaMA-3, LoRA is typically applied to seven distinct modules per layer (query, key, value, output in attention; up, down, gate in MLP). Without sharing, even u=1 yields 560 parameters for an 80-layer model. By tying the vector v across all modules—either within a layer or across the entire model—the total trainable parameters scale as O(nmu/ntie), where ntie is the number of modules sharing a single v. With full weight tying (ntie=nm), the entire model can be fine-tuned with just u parameters—potentially as few as one.
Refer to the parameter usage comparison per layer, which illustrates how TinyLoRA reduces trainable parameters relative to LoRA and LoRA-XS under varying configurations of rank, projection dimension, and weight tying.
Experiment
- Reinforcement learning (RL) enables dramatically smaller model updates than supervised finetuning (SFT), achieving strong math reasoning performance with as few as 13 parameters.
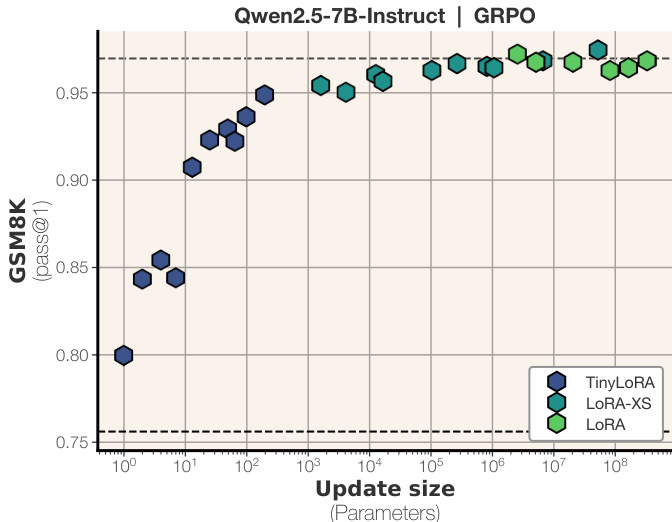
- TinyLoRA, an ultra-low-rank variant, scales smoothly down to a single trained parameter and recovers 95% of full finetuning performance on GSM8K with under 100 parameters.
- RL-based training (using GRPO) is uniquely effective in low-parameter regimes; SFT fails to match performance at comparable update sizes, indicating RL produces more information-dense updates.
- Performance improves with model scale: larger models like Qwen-2.5-7B achieve near-full performance with fewer absolute parameters, suggesting trillion-scale models may be trainable with minimal updates.
- Qwen models outperform LLaMA at small update sizes, possibly due to architectural or pretraining differences, requiring roughly 10x fewer parameters for equivalent gains.
- Parameter-sharing strategies matter: tiled sharing (by depth) outperforms structured sharing (by module type), and fp32 precision yields better results than bf16/float16 despite larger size.
- Ablations show diminishing returns with higher frozen rank; optimal TinyLoRA design favors maximizing per-module expressivity (higher u) before increasing parameter sharing (n_tie).
- Findings are currently limited to math reasoning tasks; generalization to other domains like science or creative writing remains unverified.
The authors use reinforcement learning with TinyLoRA to finetune Qwen models on math reasoning tasks, achieving near-full-finetuning performance with as few as 13 to 196 parameters. Results show that smaller parameter updates are far more effective under RL than supervised finetuning, especially for larger models, which can reach high accuracy with minimal parameter changes. Performance scales smoothly with update size, and Qwen models consistently outperform others at low parameter counts, suggesting pretraining differences may contribute to their efficiency.