Command Palette
Search for a command to run...
AOrchestra: 에이전트 오케스트레이션을 위한 서브에이전트 생성 자동화
AOrchestra: 에이전트 오케스트레이션을 위한 서브에이전트 생성 자동화
초록
언어 에이전트는 작업 자동화 분야에서 큰 잠재력을 보여주고 있다. 점점 더 복잡하고 장기적인 목표를 가진 작업에 대한 이러한 잠재력을 실현하기 위해, 다단계 작업 해결을 위한 '하위 에이전트를 도구로 활용하는' 패러다임이 부상하고 있다. 그러나 기존 설계들은 여전히 하위 에이전트에 대한 동적 추상화 관점을 결여하고 있어, 시스템의 적응성에 제약을 초래한다. 이 문제를 해결하기 위해, 우리는 어떤 에이전트든 '지시사항, 맥락, 도구, 모델'의 튜플로 모델링하는 통합적이고 프레임워크에 종속되지 않는 에이전트 추상화를 제안한다. 이 튜플은 능력의 구성적 조리법 역할을 하며, 각 작업에 대해 필요에 따라 전문화된 실행 엔진을 동적으로 생성할 수 있게 한다. 이러한 추상화를 기반으로, 중앙 오케스트레이터가 각 단계에서 튜플을 구체화하는 에이전트 시스템 AOrchestra를 도입한다. 오케스트레이터는 작업에 적합한 맥락을 선별하고, 도구와 모델을 선택하며, 실시간으로 자동 에이전트 생성을 통해 실행을 위임한다. 이러한 설계는 인간의 엔지니어링 노력 감소를 가능하게 하며, 다양한 에이전트를 태스크 실행자로 즉시 연동할 수 있는 플러그 앤 플레이 지원을 제공한다. 또한 성능과 비용 간의 조절 가능한 트레이드오프를 가능하게 하여, 시스템이 파레토 효율적 접근에 근접할 수 있도록 한다. 세 가지 도전적인 벤치마크(GAIA, SWE-Bench, Terminal-Bench)에서 AOrchestra는 Gemini-3-Flash와 결합했을 때 가장 강력한 기준 모델 대비 16.28%의 상대적 성능 향상을 달성했다. 코드는 다음 링크에서 확인할 수 있다: https://github.com/FoundationAgents/AOrchestra
One-sentence Summary
Researchers from multiple institutions propose AORCHESTRA, a framework-agnostic system using dynamic agent tuples (Instruction, Context, Tools, Model) to auto-generate specialized executors, reducing human effort and enabling Pareto-efficient performance-cost trade-offs, outperforming baselines by 16.28% on GAIA, SWE-Bench, and Terminal-Bench.
Key Contributions
- AORCHESTRA introduces a unified, framework-agnostic agent abstraction as a 4-tuple 〈Instruction, Context, Tools, Model〉, enabling dynamic on-demand creation of specialized sub-agents tailored to each subtask’s requirements.
- The system’s central orchestrator automatically concretizes this tuple at each step by curating context, selecting tools and models, and spawning executors—reducing human engineering and supporting plug-and-play integration of diverse agents.
- Evaluated on GAIA, SWE-Bench, and Terminal-Bench with Gemini-3-Flash, AORCHESTRA achieves a 16.28% relative improvement over the strongest baseline, demonstrating superior performance in complex, long-horizon tasks while enabling controllable cost-performance trade-offs.
Introduction
The authors leverage a dynamic, framework-agnostic agent abstraction—defined as a 4-tuple (Instruction, Context, Tools, Model)—to enable on-demand creation of specialized sub-agents for complex, long-horizon tasks. Prior systems either treated sub-agents as static roles (requiring heavy engineering and lacking adaptability) or as isolated context threads (ignoring capability specialization), limiting performance in open-ended environments. AORCHESTRA’s orchestrator automatically concretizes this tuple at each step, selecting tools, models, and context to spawn tailored executors, reducing human effort while enabling cost-performance trade-offs. Evaluated on GAIA, SWE-Bench, and Terminal-Bench, it delivers a 16.28% relative improvement over baselines when paired with Gemini-3-Flash, and supports learning-based optimization for even better efficiency.
Dataset

-
The authors use three benchmark datasets for evaluation: GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified. GAIA contains 165 tasks testing tool-augmented, multi-step reasoning; Terminal-Bench 2.0 includes 89 real-world command-line workflows (70 sampled for cost); SWE-Bench-Verified has 500 software engineering tasks (100 sampled), all verified via test execution and human screening.
-
Each task is structured with an instruction template including repository and instance ID fields. The agent system breaks down complex queries—like identifying 2015 Met exhibition zodiac figures—into delegated subtasks with detailed instructions, context, and model assignments.
-
The model uses a recursive delegation strategy: initial attempts identify the exhibition and accession numbers; later attempts refine object identification and hand visibility checks; final decisions synthesize findings into a single answer (e.g., “11” visible hands).
-
Third-party APIs (web search, sandboxed environments) are accessed only via a controlled tool interface. Responses are cached with metadata (URLs, timestamps, queries) to ensure reproducibility and consistent evaluation.
Method
The authors leverage a unified, orchestrator-centric architecture called AORCHESTRA to solve complex, long-horizon agentic tasks. The core innovation lies in treating sub-agents not as static roles or isolated threads, but as dynamically creatable executors parameterized by a four-tuple interface: (I,C,T,M), where I is the task instruction, C is the curated context, T is the tool set, and M is the underlying model. This abstraction decouples working memory (instruction and context) from capability (tools and model), enabling on-demand specialization for each subtask.
Refer to the framework diagram, which illustrates the orchestrator’s iterative process. The system begins with a user’s task, which the Orchestrator Agent decomposes into subtasks. At each step t, the Orchestrator samples an action at from its restricted action space AAORCHESTRA={Delegate(Φt),Finish(y)}. If the action is Delegate, the Orchestrator instantiates a Dynamic SubAgent with the specified four-tuple Φt=(It,Ct,Tt,Mt). This sub-agent executes the subtask using model Mt, restricted to tool set Tt, and conditioned only on (It,Ct). Upon completion, it returns a structured observation ot—typically including a result summary, artifacts, and error logs—which is integrated into the next system state st+1 via the state-transition function δ(st,at,ot). The process repeats until the Orchestrator selects Finish, outputting the final answer y.
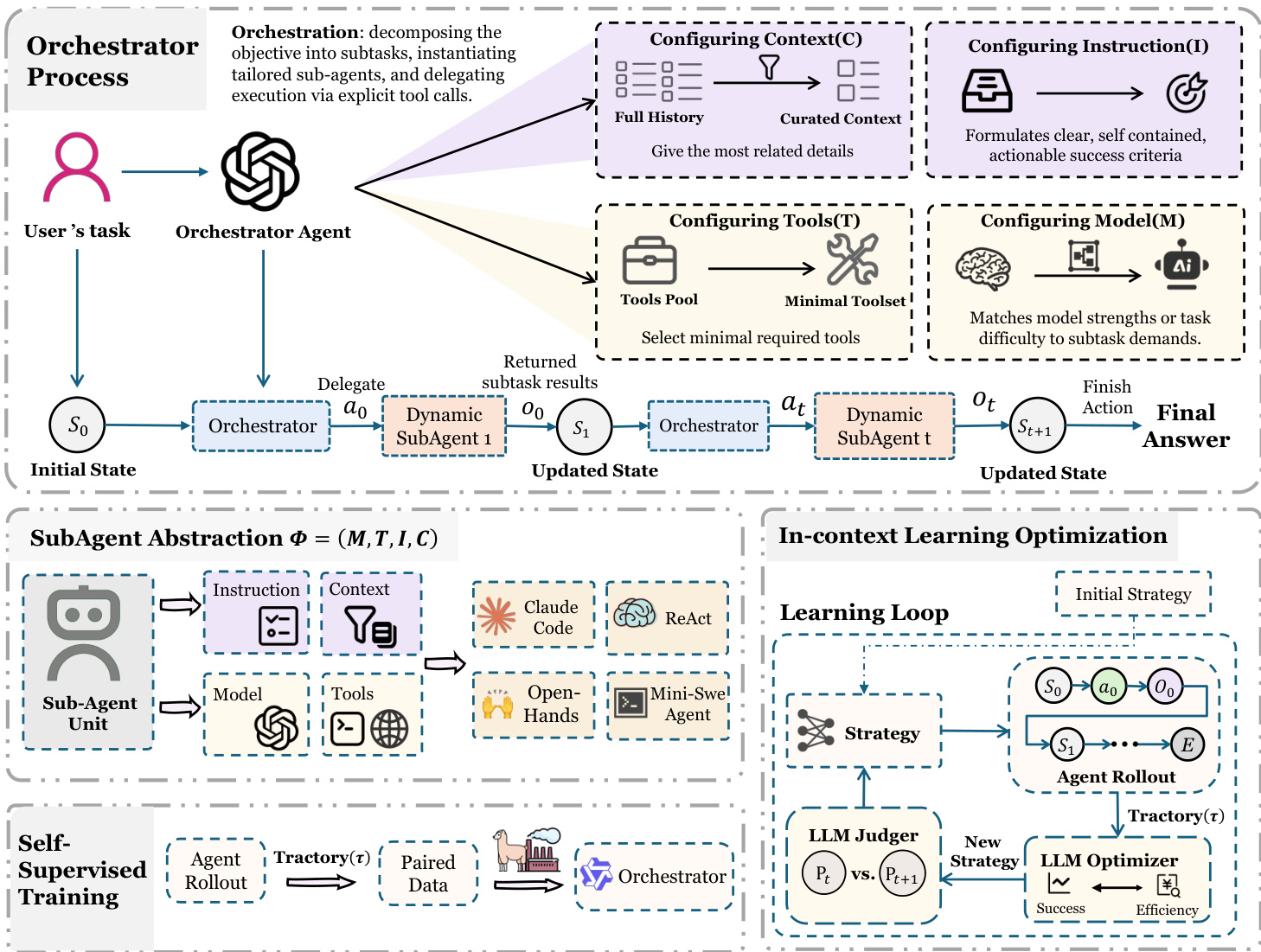
The Orchestrator’s design explicitly separates orchestration from execution: it never directly performs environment actions. Instead, it delegates all execution to dynamically instantiated sub-agents. This enables fine-grained control over context, tools, and model selection per subtask. For instance, the Orchestrator can curate context by filtering the full history to provide only the most relevant details, configure tools by selecting a minimal required subset from a pool, and match model capabilities to subtask demands—such as selecting a cheaper model for simple tasks or a more capable one for complex reasoning.
The framework also supports two complementary learning paradigms to improve the Orchestrator’s policy πθ(at∣st). First, supervised fine-tuning (SFT) distills expert trajectories to improve task orchestration—enhancing subtask decomposition and the synthesis of (It,Ct,Tt). Second, iterative in-context learning optimizes cost-aware orchestration without updating model weights. Here, the Orchestrator’s instruction Imain is treated as a learnable object. After rolling out trajectories τk, an optimizer analyzes performance and cost metrics to propose prompt edits ΔI, updating the instruction as Ik+1main=OPTIMIZE(Ikmain,τk,Perf(τk),Cost(τk)). This loop aims to discover Pareto-efficient trade-offs between performance and cost, such as selecting cheaper models for non-critical subtasks.
The sub-agent abstraction is implementation-agnostic, allowing diverse internal designs—from a simple ReAct loop to a mini-SWE agent—while maintaining a consistent interface for the Orchestrator. This flexibility, combined with explicit capability control and learnable orchestration, enables AORCHESTRA to achieve strong training-free performance and adapt to cost-performance trade-offs across benchmarks.
Experiment
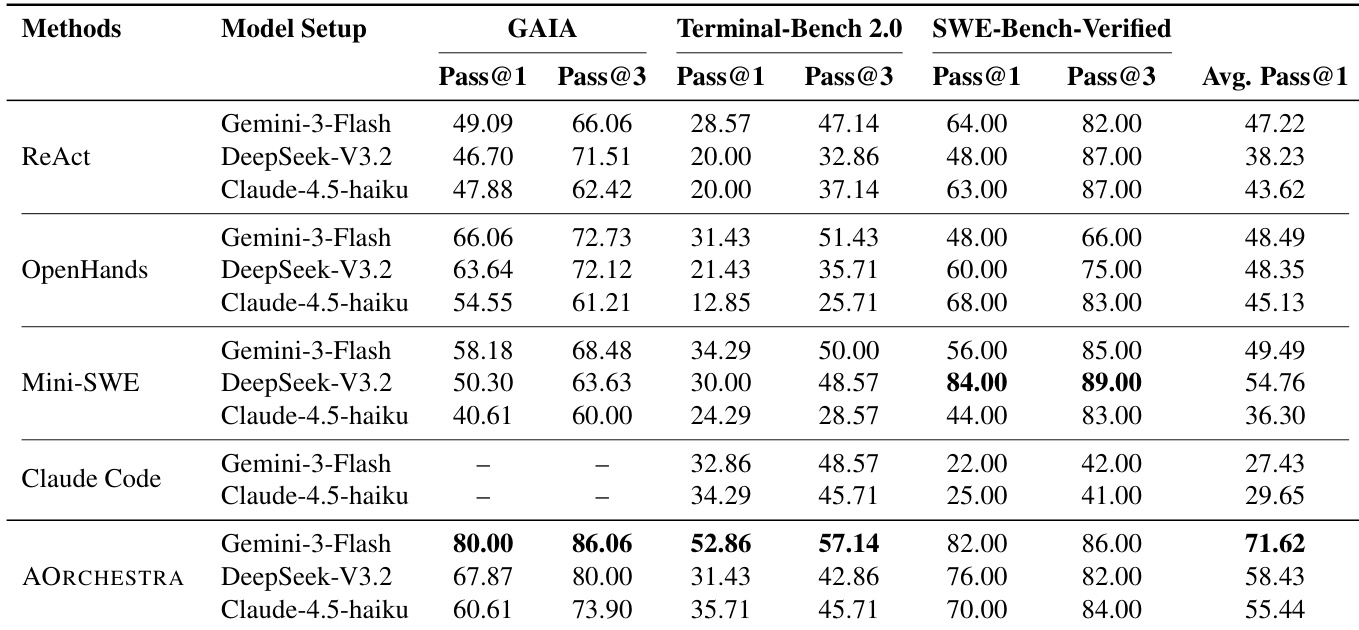
- AORCHESTRA consistently outperforms baseline systems across GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified, achieving significant gains in pass@1 and pass@3 metrics, particularly with Gemini-3-Flash as orchestrator.
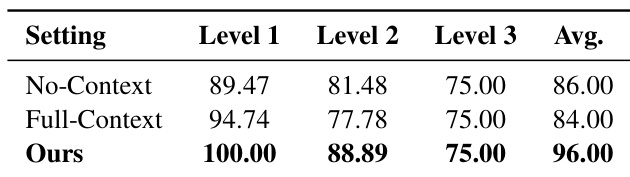
- Context sharing between orchestrator and sub-agents proves critical: curated, task-relevant context improves performance over no context or full context inheritance, reducing noise and preserving execution fidelity.
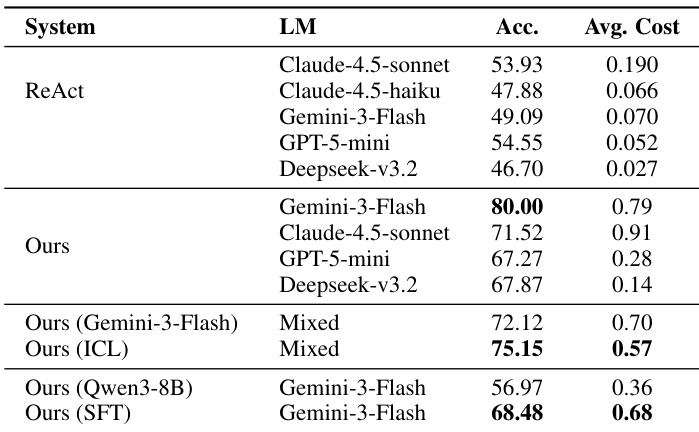
- Orchestration is a learnable skill: fine-tuning a smaller model (Qwen3-8B) for task delegation boosts performance, and in-context learning enables cost-aware model routing that improves both accuracy and efficiency.
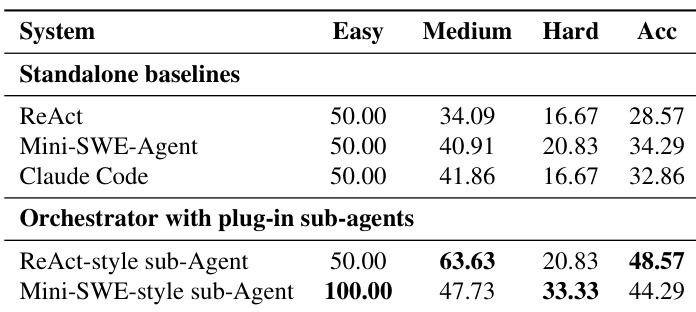
- Plug-and-play sub-agents demonstrate framework robustness: AORCHESTRA maintains strong performance when swapping sub-agent backends, confirming modular design and implementation independence.
- The system exhibits strong long-horizon reasoning and error recovery: it successfully resolves complex, multi-attempt tasks by iteratively refining hypotheses, propagating intermediate findings, and adapting based on sub-agent feedback.
The authors evaluate context-sharing strategies in their agent framework by comparing No-Context, Full-Context, and their proposed method. Results show that explicitly curating and passing relevant context to sub-agents significantly improves performance across all difficulty levels, achieving the highest average score. This design avoids the pitfalls of missing critical cues or introducing noise from irrelevant history.
The authors use a hierarchical agent framework where a main orchestrator delegates tasks to specialized sub-agents, achieving higher accuracy than baseline systems across multiple benchmarks. Results show that explicitly curating and passing context to sub-agents improves performance, and that fine-tuning or in-context learning of the orchestrator further enhances both accuracy and cost efficiency. The system also demonstrates robustness by maintaining strong performance even when using smaller models or different sub-agent backends.
The authors use an orchestrator framework that dynamically delegates tasks to specialized sub-agents, achieving higher overall accuracy than standalone baselines across difficulty levels. Results show that combining the orchestrator with different sub-agent styles improves performance, particularly on medium-difficulty tasks, while maintaining strong results on easy tasks. The framework demonstrates flexibility in sub-agent selection, with ReAct-style sub-agents yielding the best overall accuracy.
The authors use AORCHESTRA, a multi-agent orchestration framework, to outperform baseline systems across three diverse benchmarks: GAIA, Terminal-Bench 2.0, and SWE-Bench-Verified. Results show consistent gains in pass@1 and pass@3 metrics, with the largest improvements observed on Terminal-Bench 2.0 and GAIA, indicating strong generalization across task types and model backbones. The system’s design—enabling context-aware sub-agent delegation, learnable orchestration, and plug-and-play execution—contributes to its robust performance and cost-efficiency.