Command Palette
Search for a command to run...
Quant VideoGen: 2비트 KV 캐시 양자화를 통한 자동 회귀적 장시간 비디오 생성
Quant VideoGen: 2비트 KV 캐시 양자화를 통한 자동 회귀적 장시간 비디오 생성
초록
자기회귀형 비디오 확산 모델의 빠른 발전에도 불구하고, 도입 가능성과 생성 능력을 동시에 제한하는 새로운 시스템 알고리즘적 한계가 존재한다: KV 캐시 메모리이다. 자기회귀형 비디오 생성 모델에서 KV 캐시는 생성 이력에 따라 증가하며 GPU 메모리의 대부분을 차지하게 되어 종종 30GB를 초과하게 되어 일반적으로 사용 가능한 하드웨어에 배포하는 것을 불가능하게 만든다. 더욱 심각하게는 제한된 KV 캐시 예산으로 인해 실질적인 작업 메모리가 제약받게 되어, 정체성, 레이아웃 및 동작의 장기적 일관성이 직접적으로 저하된다. 이 문제를 해결하기 위해 우리는 자기회귀형 비디오 확산 모델을 위한 훈련 없이 사용 가능한 KV 캐시 양자화 프레임워크인 Quant VideoGen(QVG)을 제안한다. QVG는 시맨틱 인식 스무딩(Semantic Aware Smoothing)을 통해 비디오의 시공간적 중복성을 활용하여 낮은 크기의 양자화 친화적인 잔차(residual)를 생성한다. 또한, 거시적에서 미시적까지의 다단계적 접근 방식인 프로그레시브 잔차 양자화(Progressive Residual Quantization)를 도입하여 양자화 오차를 줄이면서도 품질과 메모리 사용 간의 부드러운 트레이드오프를 가능하게 한다. LongCat Video, HY WorldPlay, Self Forcing 벤치마크에서 QVG는 품질과 메모리 효율성 사이의 새로운 파레토 경계를 확립하였으며, 최대 7.0배의 KV 캐시 메모리 감소를 달성하면서 전체 지연 시간은 4% 미만의 추가 오버헤드로 유지하며, 생성 품질 측면에서 기존의 모든 벤치마크를 일관되게 능가하였다.
One-sentence Summary
Researchers from MIT, UC Berkeley, and Tsinghua propose Quant VideoGen (QVG), a training-free KV-cache quantization method that leverages spatiotemporal redundancy and progressive residual quantization to cut memory use by 7× while preserving video consistency and quality across long-horizon generation tasks.
Key Contributions
- Auto-regressive video diffusion models face a critical KV-cache memory bottleneck that limits deployment on consumer hardware and degrades long-horizon consistency in identity, layout, and motion due to forced memory budgeting.
- Quant VideoGen (QVG) introduces a training-free quantization framework leveraging Semantic-Aware Smoothing and Progressive Residual Quantization to exploit spatiotemporal redundancy, producing low-magnitude, quantization-friendly residuals with coarse-to-fine error reduction.
- Evaluated on LongCat-Video, HY-WorldPlay, and Self-Forcing, QVG reduces KV memory up to 7.0× with <4% latency overhead, enables HY-WorldPlay-8B to run on a single RTX 4090, and achieves higher PSNR than baselines under constrained memory.
Introduction
The authors leverage auto-regressive video diffusion models to enable long-horizon video generation, which is critical for applications like live streaming, interactive content, and world modeling. However, these models face a severe memory bottleneck: the KV-cache grows linearly with video length and quickly exceeds GPU capacity, forcing short context windows that degrade consistency in identity, motion, and layout. Prior KV-cache quantization methods from LLMs fail on video due to its heterogeneous activation statistics and lack of spatiotemporal awareness. Their main contribution, Quant VideoGen (QVG), is a training-free framework that exploits video’s spatiotemporal redundancy via Semantic-Aware Smoothing—grouping similar tokens and subtracting centroids to create low-magnitude residuals—and Progressive Residual Quantization, a multi-stage compression scheme that refines quantization error. QVG reduces KV-cache memory by up to 7x with under 4% latency overhead, enabling high-quality, minute-long generation on consumer GPUs and setting a new quality-memory Pareto frontier.
Method
The authors leverage a two-stage quantization framework—Semantic-Aware Smoothing followed by Progressive Residual Quantization—to address the challenges of quantizing video KV-cache, which exhibits both high dynamic range and spatiotemporal redundancy. The overall pipeline is designed to progressively reduce quantization error by exploiting semantic similarity and temporal structure inherent in video tokens.
The process begins with Semantic-Aware Smoothing, which operates on chunks of tokens (e.g., N=HWTc tokens per chunk) extracted from the KV-cache tensor X∈RN×d. The authors apply k-means clustering to partition tokens into C disjoint groups G={G1,…,GC} based on their hidden representations. Each group’s centroid Ci∈Rd is computed as the mean of its members. The residual for each group is then derived via centroid subtraction:
Ri=XGi−Ci,Ri∈R∣Gi∣×dThis step effectively reduces the dynamic range within each group, as large outlier values are captured in the centroids and subtracted out. The result is a residual tensor R with significantly lower maximum magnitude, which directly reduces quantization error since E[∥x−x^∥]∝SX, and SX is proportional to the maximum absolute value in the group.
Refer to the framework diagram, which illustrates how the original KV-cache (a) is transformed through semantic grouping and centroid subtraction (b) into a smoother residual distribution, enabling more accurate low-bit quantization.
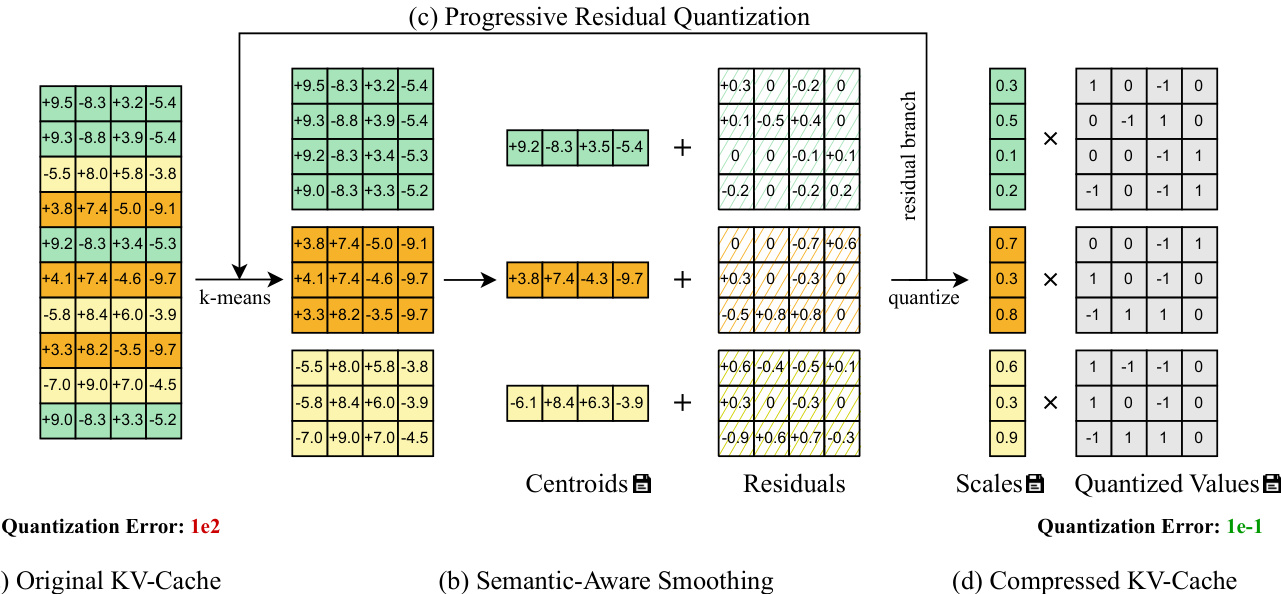
Building on this, Progressive Residual Quantization iteratively refines the residual tensor across T stages. Starting with R(0)=X, each stage applies Semantic-Aware Smoothing to the current residual to produce a new residual R(t), centroids C(t), and assignment vector π(t). After T stages, the final residual R(T) is quantized using symmetric per-group integer quantization:
XINT,SX=Q(R(T))The centroids and assignment vectors from all stages are stored in global memory, while intermediate residuals are discarded. During dequantization, the process is reversed: the quantized residual is dequantized and then iteratively reconstructed by adding back the assigned centroids from stage T down to stage 1, yielding the final reconstructed tensor X^(0).
This multi-stage approach allows the model to capture coarse semantic structure in early stages and fine-grained variations in later stages, leading to diminishing but cumulative reductions in quantization error. As shown in the figure, the quantization error drops from 1e2 in the original cache to 1e−1 in the final compressed representation, demonstrating the efficacy of the progressive refinement.
To support efficient deployment, the authors introduce algorithm-system co-design optimizations. They accelerate k-means by caching centroids from prior chunks, reducing clustering overhead by 3×. Additionally, they implement a fused dequantization kernel that reconstructs the full tensor by adding back centroids across all stages while keeping intermediate results in registers to minimize global memory access.
Experiment
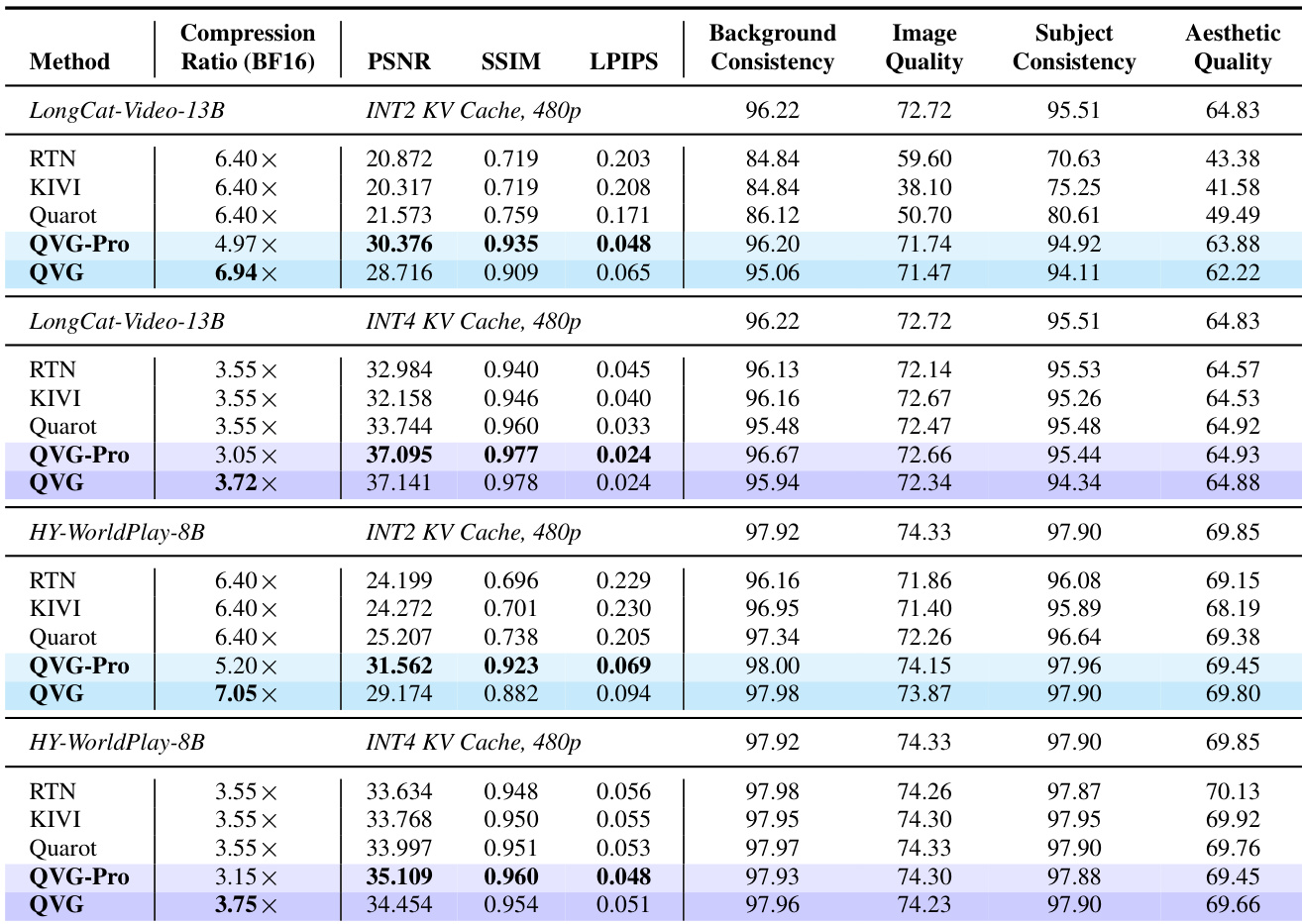
- QVG and QVG-Pro significantly reduce KV-cache memory usage (up to 7x compression) while preserving video fidelity and perceptual quality across LongCat-Video-13B, HY-WorldPlay-8B, and Self-Forcing-Wan models.
- Both variants maintain near-lossless performance on VBench metrics (Background, Subject, Image, and Aesthetic Quality), outperforming baselines like RTN, KIVI, and QuaRot, especially under INT2 quantization.
- QVG effectively mitigates long-horizon drift, sustaining stable image quality beyond 700 frames in Self-Forcing, whereas baselines degrade sharply after ~100 frames.
- End-to-end latency overhead is minimal (1.5%–4.3% across models), confirming QVG does not impede generation speed.
- Progressive Residual Quantization’s first stage delivers the largest MSE reduction; subsequent stages offer diminishing returns.
- Larger quantization block sizes (e.g., 64) improve compression but reduce quality, while smaller blocks (e.g., 16) preserve quality at the cost of lower compression.
The authors use QVG and QVG-Pro to compress the KV cache in video generation models, achieving high compression ratios while preserving perceptual quality across multiple metrics. Results show that QVG-Pro delivers the highest fidelity scores, while QVG offers the largest memory savings with only minor quality trade-offs, outperforming all baselines. Both methods maintain near-lossless performance over long video sequences, effectively mitigating drift without introducing significant latency.