Command Palette
Search for a command to run...
WAXAL: 대규모 다국어 아프리카 언어 음성 말뭉치
WAXAL: 대규모 다국어 아프리카 언어 음성 말뭉치
초록
음성 기술의 발전은 주로 고자원 언어에 편향되어 있어, 사하라 이남 아프리카 대부분의 언어를 사용하는 화자들에게 심각한 디지털 격차를 초래했습니다. 이러한 격차를 해소하기 위해 우리는 1 억 명 이상의 화자를 대표하는 24 개 언어를 위한 대규모 개방형 음성 데이터셋인 WAXAL 을 소개합니다. 이 데이터셋은 두 가지 주요 구성 요소로 이루어져 있습니다. 첫째, 다양한 화자로부터 수집된 약 1,250 시간 분량의 전사된 자연 음성으로 구성된 자동 음성 인식 (ASR) 데이터셋과, 둘째, 음소적으로 균형 잡힌 대본을 읽는 단일 화자의 고품질 녹음이 235 시간 이상 포함된 텍스트 - 음성 변환 (TTS) 데이터셋입니다. 본 논문에서는 네 개의 아프리카 학술 및 지역사회 기관과의 협력을 통해 수행된 데이터 수집, 주석 작성, 품질 관리 방법론을 상세히 기술합니다. 또한 데이터셋에 대한 상세한 통계적 개요를 제시하고, 잠재적 한계점 및 윤리적 고려사항에 대해 논의합니다. WAXAL 데이터셋은 연구 촉진을 포괄적 기술 개발을 가능하게 하며, 해당 언어들의 디지털 보존을 위한 핵심 자원으로 활용될 수 있도록 CC-BY-4.0 라이선스 하에 https://huggingface.co/datasets/google/WaxalNLP 에서 공개되었습니다.
One-sentence Summary
To address the significant digital divide for Sub-Saharan African languages, WAXAL provides a large-scale, openly accessible speech corpus of 24 languages representing over 100 million speakers, consisting of approximately 1,250 hours of transcribed natural speech for Automated Speech Recognition and over 235 hours of high-quality single-speaker recordings reading phonetically balanced scripts for Text-to-Speech, developed in partnership with four African academic and community organizations and released under a CC-BY-4.0 license to catalyze research, enable inclusive technology development, and support digital preservation.
Key Contributions
- We introduce WAXAL, a large-scale speech dataset for 24 Sub-Saharan African languages representing over 100 million speakers. The collection comprises an Automated Speech Recognition (ASR) dataset with approximately 1,250 hours of transcribed natural speech and a Text-to-Speech (TTS) dataset with over 235 hours of high-quality recordings.
- We detail a methodology for data collection, annotation, and quality control established through partnerships with four African academic and community organizations. This process supports the inclusion of diverse speakers and maintains quality control standards for the resulting speech resources.
- The datasets are released at https://huggingface.co/datasets/google/WaxalNLP under a permissive CC-BY-4.0 license to catalyze research and enable the development of inclusive technologies. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations.
Introduction
Automatic speech recognition systems often lack sufficient training data for African languages, which limits technological accessibility and inclusivity in these regions. Existing datasets frequently do not offer the scale or multilingual diversity required for robust model performance across the continent. The authors introduce WAXAL, a large-scale multilingual African language speech corpus designed to address this resource gap. They also emphasize that releasing any large-scale human data requires careful consideration of its limitations and ethical implications.
Dataset
-
Dataset Composition and Sources
- The authors present WAXAL, a large-scale speech dataset covering 24 Sub-Saharan African languages spoken by over 100 million people.
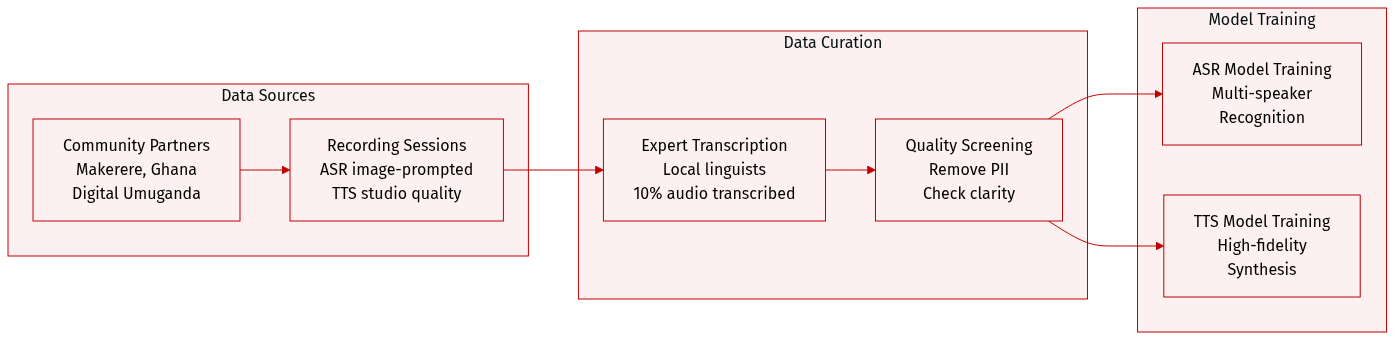
- Collection efforts were conducted in partnership with four African academic and community organizations, such as Makerere University and the University of Ghana.
- The entire collection is released under a CC-BY-4.0 license to encourage academic and commercial research.
-
Key Details for Each Subset
- ASR Subset: Includes approximately 1,250 hours of transcribed natural speech across 14 languages. Recordings were image-prompted to capture spontaneous speech with a minimum duration of 15 seconds.
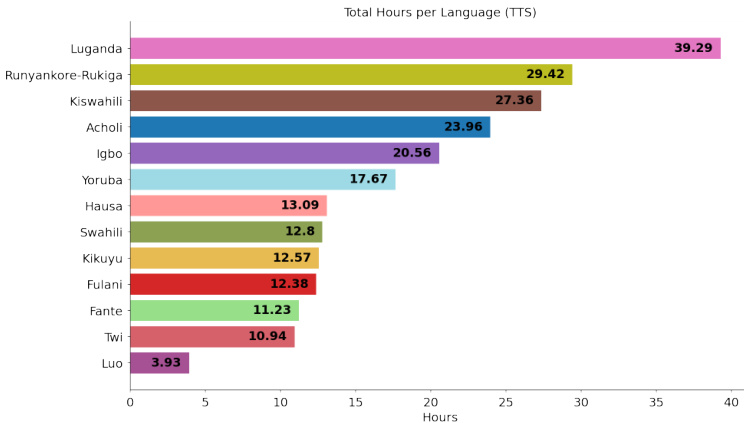
- TTS Subset: Comprises over 180 hours of studio-quality recordings from 72 voice actors across 10 languages. Speakers read phonetically balanced scripts in professional environments.
- File Statistics: The released ASR data occupies 1.7 TB, while the TTS data totals 99 GB.
-
Data Usage and Processing
- Intended Use: The ASR data is suitable for training and evaluating multi-speaker recognition models, whereas the TTS data is designed for high-fidelity voice synthesis.
- Annotation Strategy: Transcriptions were created by local linguistic experts using local scripts or English transliteration. Only 10% of the total collected audio was transcribed for the release.
- Metadata Construction: The dataset includes speaker demographics such as age, gender, and recording environment (e.g., indoor, outdoor).
- Quality Control: The authors removed personally identifiable information and screened audio for clarity, language accuracy, and appropriate content.