Command Palette
Search for a command to run...
비전-디프리서치 벤치마크: 다중모달 대규모 언어 모델을 위한 시각적 및 텍스트 검색의 재고
비전-디프리서치 벤치마크: 다중모달 대규모 언어 모델을 위한 시각적 및 텍스트 검색의 재고
초록
다중모달 대규모 언어 모델(Multimodal Large Language Models, MLLMs)은 이제 시각-질의응답(VQA) 기술을 크게 발전시켰으며, 검색 엔진을 활용한 복잡한 시각-텍스트 정보 탐색을 수행하는 '시각-심층연구(Vision-DeepResearch)' 시스템의 지원도 가능하게 되었다. 그러나 이러한 시각적 및 텍스트 기반 검색 능력을 평가하는 것은 여전히 어려운 과제이며, 기존의 평가 벤치마크는 두 가지 주요한 한계를 지닌다. 첫째, 기존 벤치마크는 시각 검색 중심이 아님: 시각 검색이 필요해야 하는 질문들에 대해서도 질문 텍스트 내의 교차 텍스트적 단서나 현재 MLLMs가 내장한 사전 세계 지식을 통해 답을 유추할 수 있는 경우가 많다. 둘째, 평가 시나리오가 지나치게 이상적임: 이미지 검색 측면에서는 전체 이미지와 거의 정확한 매칭을 통해 필요한 정보를 얻을 수 있는 반면, 텍스트 검색 측면은 지나치게 직관적이며 도전적 요소가 부족하다.이러한 문제를 해결하기 위해, 현실적인 실세계 조건에서 시각-심층연구 시스템의 행동을 평가할 수 있도록 설계된 '시각-심층연구 벤치마크(Vision-DeepResearch benchmark, VDR-Bench)'를 구축하였다. 이 벤치마크는 2,000개의 VQA 인스턴스를 포함하며, 모든 질문은 철저한 다단계 셀렉션 프로세스와 엄격한 전문가 검토를 거쳐 생성되었다. 또한 현재 MLLMs의 시각 검색 능력이 부족한 문제를 보완하기 위해, 간단한 다라운드 컷팅-검색(workflow) 전략을 제안한다. 이 전략은 현실적인 시각 검색 시나리오에서 모델 성능을 효과적으로 향상시킨다는 것이 입증되었다. 종합적으로, 본 연구 결과는 향후 다중모달 심층연구 시스템 설계에 실질적인 지침을 제공한다. 코드는 https://github.com/Osilly/Vision-DeepResearch 에 공개될 예정이다.
One-sentence Summary
The authors from Shenzhen Loop Area Institute and collaborating institutions propose Vision-DeepResearch, a benchmark rethinking visual-textual search for multimodal LLMs, introducing novel evaluation metrics that better capture real-world retrieval challenges beyond prior static datasets.
Key Contributions
- We identify critical limitations in existing multimodal search benchmarks, including reliance on text-only cues and idealized whole-image retrieval that fail to reflect real-world visual search challenges.
- We introduce VDR-Bench, a 2,000-instance benchmark built via a multi-stage curation pipeline requiring genuine visual search and multi-hop reasoning, with human verification to eliminate shortcut solutions.
- We propose a multi-round cropped-search workflow that improves visual retrieval accuracy by iteratively localizing entities, validated through experiments showing significant performance gains on realistic scenarios.
Introduction
The authors leverage advances in multimodal large language models to address the growing need for systems that can perform deep, real-world visual-textual research—combining image understanding, web search, and multi-hop reasoning. Existing benchmarks fall short because they allow models to bypass genuine visual search via text-based shortcuts or rely on idealized, near-perfect image matching, failing to reflect the noisy, iterative nature of real visual retrieval. To fix this, they introduce VDR-Bench, a 2,000-instance benchmark built through a human-verified pipeline that enforces visual-first reasoning and cross-modal evidence gathering. They also propose a multi-round cropped-search workflow that improves performance by iteratively refining visual queries, offering a practical path toward more robust multimodal agents.
Dataset

The authors use VDR-Bench, a benchmark of 2,000 multi-hop Visual Question Answering (VQA) instances across 10 diverse visual domains, to evaluate deep research and entity-level retrieval performance. Here’s how the dataset is built and used:
-
Sources & Composition:
- Images are sourced from multiple public datasets, pre-filtered for resolution and visual richness using Qwen3-VL-235B-A22B-Instruct to retain only those with multiple entities and realistic scenes.
- Each sample is built around a manually cropped salient region (e.g., object, logo, landmark) used as a visual query for web-scale image search.
- Final samples combine visual evidence, retrieved entities, and multi-hop reasoning chains grounded in external knowledge graphs.
-
Key Subset Details:
- Step 0: Multi-domain image pre-filtering removes low-res images; Qwen3-VL-235B-A22B-Instruct selects high-quality, entity-rich scenes.
- Step 1: Human annotators crop salient regions; each crop triggers a web visual search to retrieve candidate images.
- Step 2: Candidate entities (persons, brands, locations) are extracted from search result titles/captions. Qwen3-VL-235B-A22B-Instruct filters inconsistent matches, followed by human verification to ensure entities can’t be trivially found via full-image search.
- Step 3: Gemini-2.5-Pro generates seed VQA pairs tied to verified entities. Human reviewers ensure questions require visual grounding and have unique, unambiguous answers.
- Step 4: Knowledge-graph random walks expand questions into multi-hop reasoning tasks (e.g., “What city is the HQ of the company whose logo appears?”).
- Step 5: Automated solvability checks confirm answers can be derived from the recorded visual search + KG path; human annotators remove questions with text-only shortcuts or ambiguous reasoning.
-
Model Usage & Training Setup:
- VDR-Bench is used for evaluation only — no training split is mentioned.
- Questions are designed to force agents to retrieve and reason over visual entities, not rely on prior knowledge.
- The benchmark emphasizes both final answer accuracy and entity-level retrieval success.
-
Processing & Metadata:
- Each sample includes: the original image, cropped region, visual search results, verified entity names, knowledge-graph expansion path, and multi-hop question.
- Metadata tracks the full reasoning trajectory — including search queries, retrieved entities, and KG hops — to support evaluation.
- Two metrics are used:
- Answer Accuracy: Evaluated via Qwen3-VL-30B-A3B-Instruct as judge model using a standardized prompt.
- Entity Recall (ER): Measures whether the agent’s retrieved entity set matches the gold entity sequence semantically (not via string match), using an LLM-as-judge to accept valid reasoning paths and synonyms.
Experiment
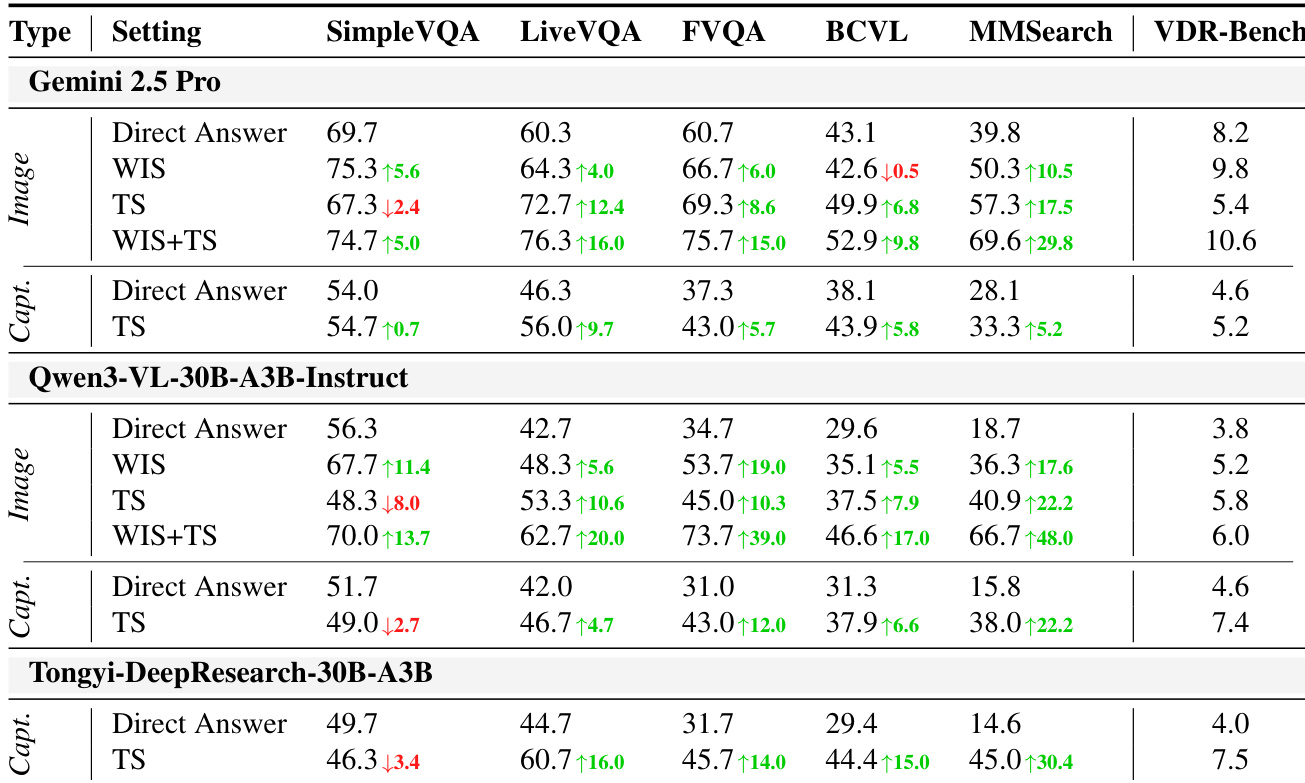
- Existing Vision-DeepResearch benchmarks often fail to enforce visual-search-centric reasoning, as many questions can be answered using text search or model priors alone, revealing significant textual cue leakage.
- Current evaluation settings are overly idealized, relying on near-exact image matches that bypass real-world challenges like iterative localization, entity refinement, and cross-modal verification.
- On the new VDR-Bench, models perform poorly without search tools, confirming the necessity of active visual and textual retrieval for accurate answers.
- Open-source models with weaker prior knowledge outperform closed-source counterparts when equipped with search tools, indicating that effective tool use matters more than pre-trained knowledge alone.
- Multi-turn visual forcing enhances performance by promoting iterative region cropping and cross-modal verification, highlighting the value of structured visual grounding in complex reasoning tasks.
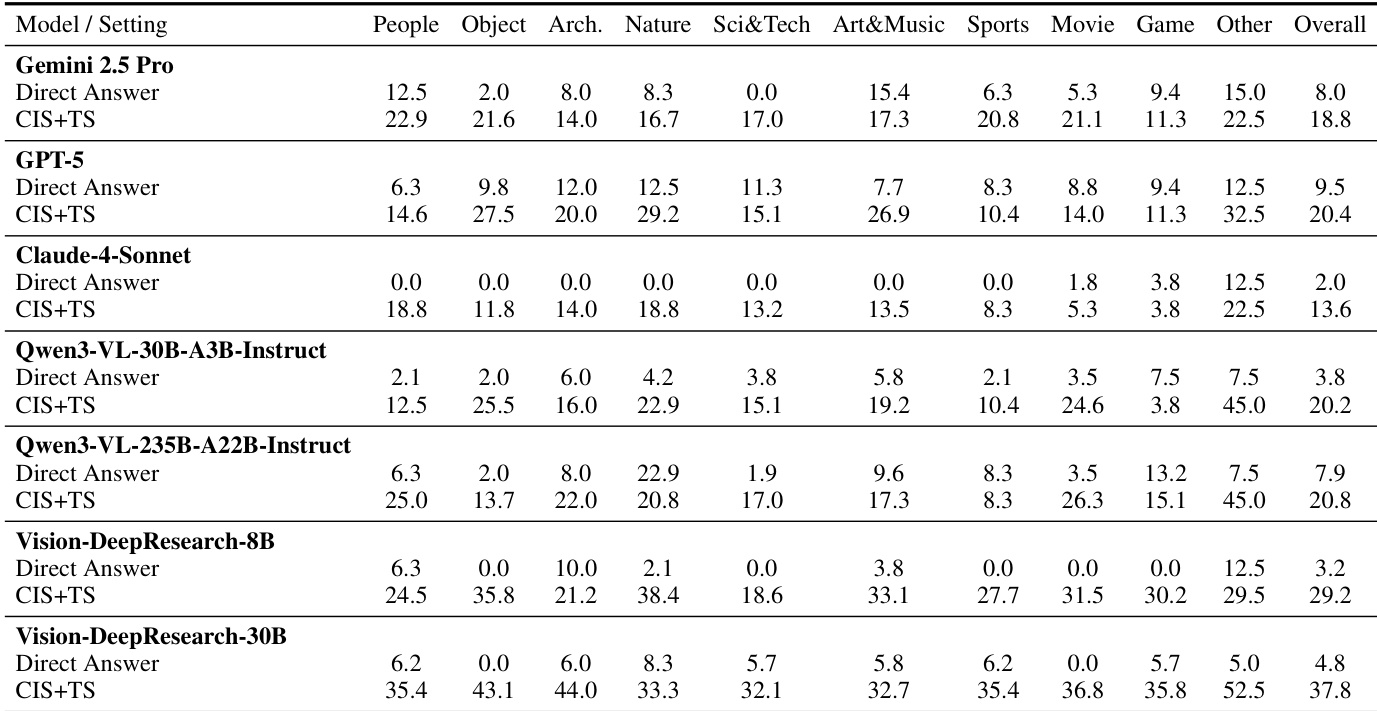
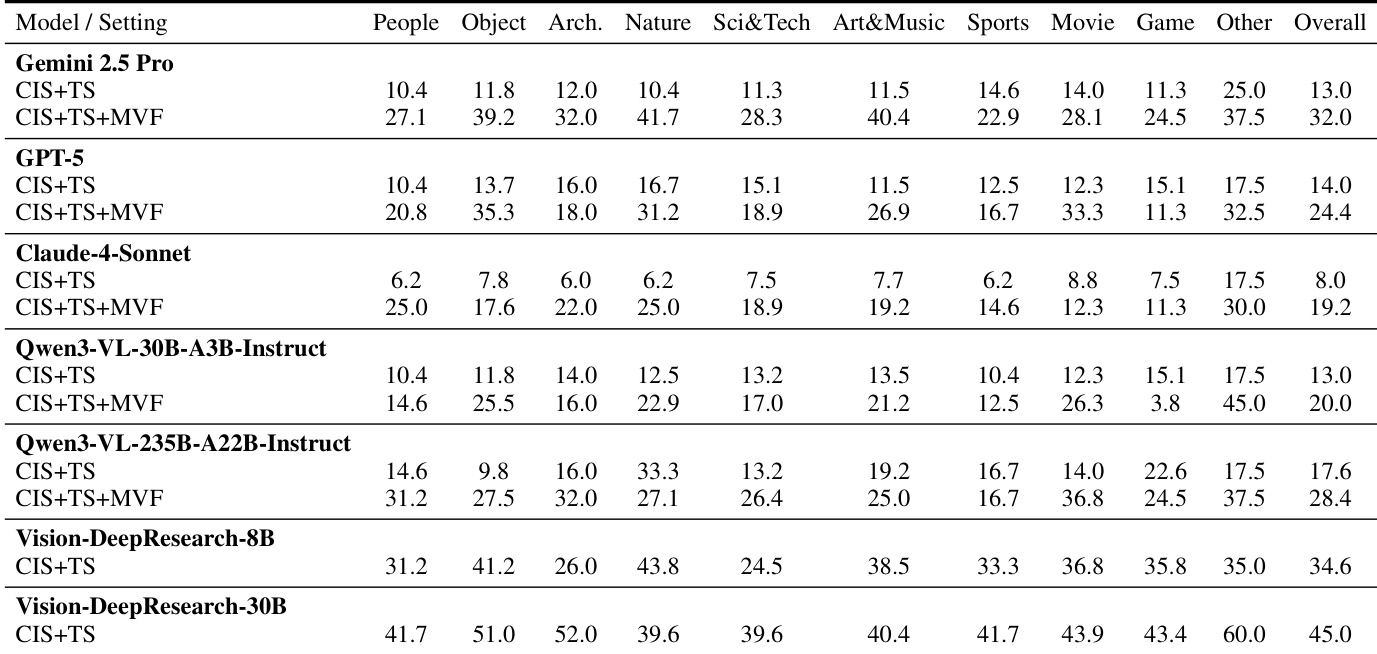
The authors evaluate multiple vision-language models under controlled search settings to isolate the contributions of visual and textual retrieval. Results show that enabling multi-turn visual forcing consistently improves performance across domains, indicating that iterative refinement and cross-modal verification are critical for effective visual deep research. Open-source models, particularly larger ones, demonstrate strong search-driven reasoning despite weaker prior knowledge, suggesting that tool usage strategy matters more than parametric memory alone.
The authors use controlled experiments to show that many existing vision-based benchmarks can be solved effectively without visual search, relying instead on text retrieval or model priors, which undermines their validity for evaluating true visual reasoning. Results show that performance often improves more with text search than with whole-image search, indicating widespread textual cue leakage and an overreliance on language-based knowledge. In contrast, the new VDR-Bench requires active search and demonstrates that model scale and search tool usage, not just prior knowledge, are critical for visual deep-research performance.
The authors evaluate multiple vision-language models under controlled search conditions to assess their reliance on visual versus textual evidence. Results show that performance improves significantly when models use both cropped-image and text search, with further gains from multi-turn visual forcing, indicating that effective visual reasoning requires iterative refinement and cross-modal verification. Notably, models with weaker prior knowledge often outperform stronger ones when search tools are enabled, suggesting that search strategy matters more than pre-trained knowledge for visual deep-research tasks.
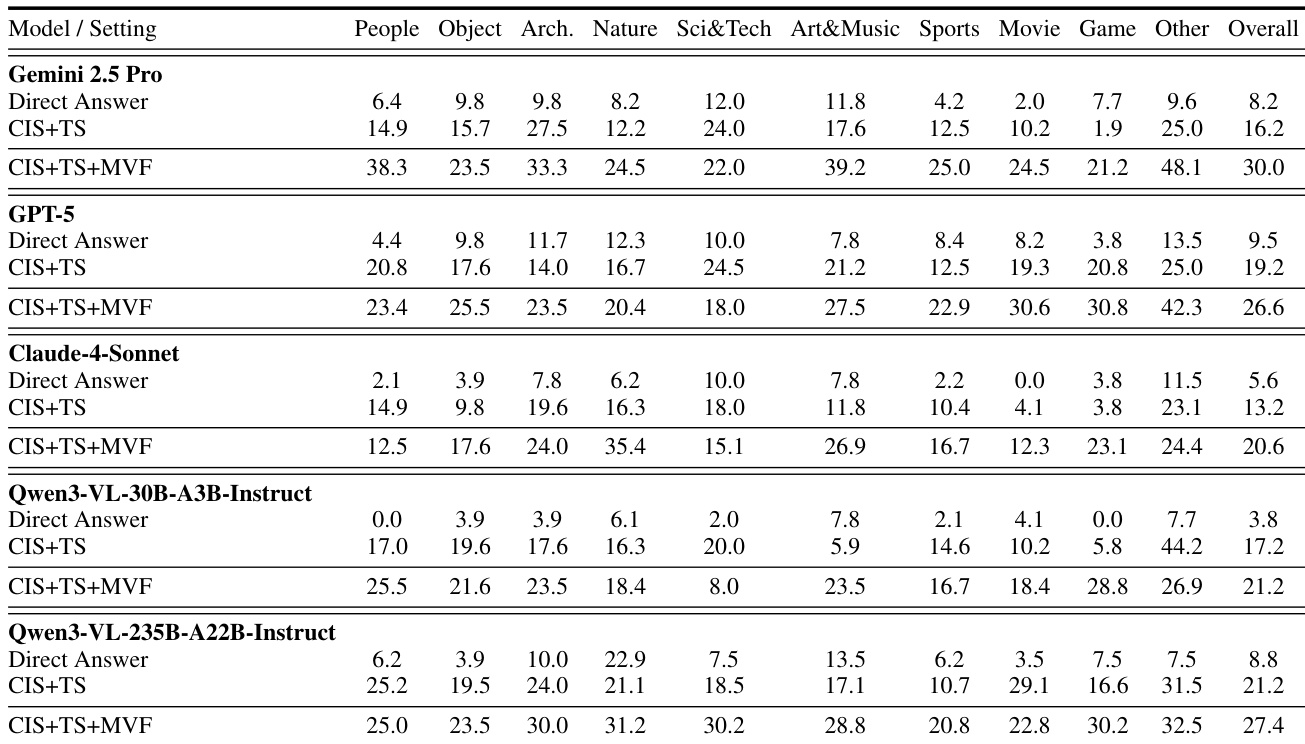
The authors evaluate multiple vision-language models on a new benchmark designed to enforce visual-search-centric reasoning, finding that performance improves significantly when models use both cropped-image and text search tools. Results show that models with weaker prior knowledge often outperform larger closed-source models in search-driven tasks, suggesting that effective tool use matters more than pre-trained knowledge alone. The highest scores are achieved by models that actively engage with visual evidence through iterative search, highlighting the importance of designing benchmarks that require genuine visual grounding rather than textual shortcuts.