Command Palette
Search for a command to run...
세계 모델에 대한 연구는 특정 작업에 세계 지식을 주입하는 것을 넘어서는 것이다.
세계 모델에 대한 연구는 특정 작업에 세계 지식을 주입하는 것을 넘어서는 것이다.
초록
세계 모델(World models)은 대규모 모델에 물리적 역학과 세계에 대한 지식을 통합함으로써 그 능력을 향상시키려는 목표를 지닌 인공지능 연구의 핵심적인 전선으로 부상하고 있다. 핵심적인 목적은 에이전트가 복잡한 환경을 이해하고 예측하며 상호작용할 수 있도록 하는 것이다. 그러나 현재의 연구 환경은 여전히 분산되어 있으며, 주로 시각 예측, 3차원 추정, 기호 기반(symbol grounding)과 같은 특정 작업에 세계 지식을 도입하는 데 집중하고 있을 뿐, 통합적인 정의나 프레임워크를 수립하지 못하고 있다. 이러한 작업 중심의 통합 방식은 성능 향상은 가져오지만, 종합적인 세계 이해를 위해 필수적인 체계적 일관성은 자주 부족하다. 본 논문에서는 이러한 분산된 접근 방식의 한계를 분석하고, 세계 모델을 위한 통합적인 설계 사양을 제안한다. 우리는 견고한 세계 모델이 능력의 느슨한 집합이 아니라, 상호작용, 인지, 기호적 추론, 공간적 표현을 통합적으로 포함하는 규범적 프레임워크여야 한다고 제안한다. 본 연구는 향후 연구가 더욱 일반화되고, 견고하며 원칙적인 세계 모델 개발로 나아갈 수 있도록 체계적인 시각을 제시하는 것을 목적으로 한다.
One-sentence Summary
The authors from multiple institutions propose a unified framework for world models, integrating interaction, perception, symbolic reasoning, and spatial representation to overcome fragmented task-specific approaches, aiming to guide AI toward more general and principled environmental understanding.
Key Contributions
- The paper identifies a critical fragmentation in current world model research, where methods focus on injecting world knowledge into isolated tasks like visual prediction or 3D estimation, leading to performance gains but lacking systematic coherence for holistic world understanding.
- It proposes a unified design specification for world models, defining them as normative frameworks that integrally combine interaction, perception, symbolic reasoning, and spatial representation to enable agents to actively understand and respond to complex environments.
- Through analysis of LLMs, video generation, and embodied AI systems, the work demonstrates the limitations of task-specific approaches and outlines essential components—Interaction, Reasoning, Memory, Environment, and Multimodal Generation—to guide future development toward general, robust world simulation.
Introduction
The authors leverage the growing interest in world models—systems designed to simulate physical dynamics and enable agents to interact intelligently with complex environments—to critique the current fragmented research landscape. Most existing approaches inject world knowledge into isolated tasks like video generation or 3D estimation, relying on task-specific data and fine-tuning, which yields short-term performance gains but fails to produce coherent, physics-aware understanding or long-term consistency. Their main contribution is a unified design specification for world models that integrates interaction, perception, reasoning, memory, and multimodal generation into a normative framework, aiming to guide future research toward general, robust, and principled models capable of active exploration and real-world adaptation.
Method
The authors leverage a unified world model framework designed to overcome the fragmentation of task-specific models by integrating perception, reasoning, memory, interaction, and generation into a cohesive, closed-loop architecture. This framework is structured around five core modules, each addressing a critical capability required for holistic world understanding and adaptive interaction.
The interaction module serves as the unified perceptual and operational interface between users, the environment, and the model. It accepts multimodal inputs—including text, images, video, audio, and 3D point clouds—and processes diverse operational signals such as natural language instructions, embodied commands, or low-level motion controls. As shown in the figure below, this module unifies the encoding and scheduling of heterogeneous data streams to produce structured input for downstream components.
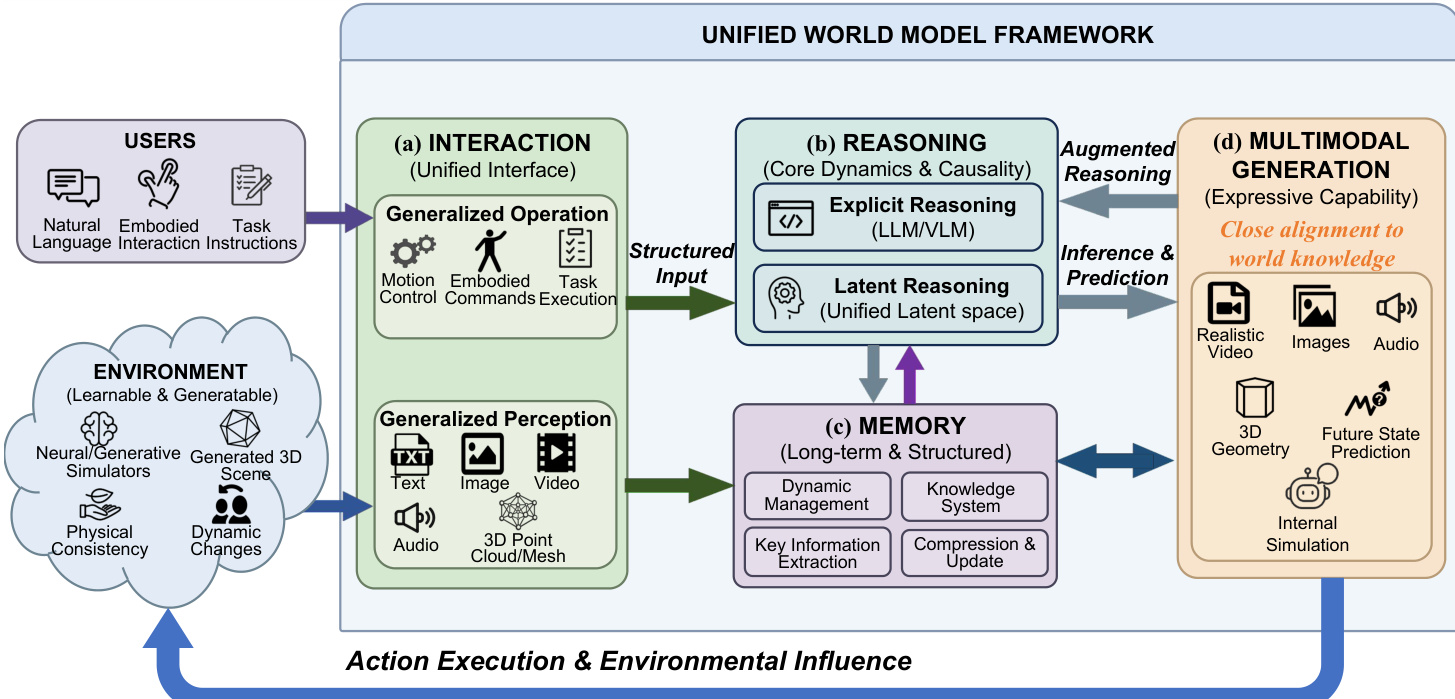
The reasoning module is responsible for inferring dynamics and causality from the structured inputs. It supports two complementary paradigms: explicit reasoning, which leverages LLMs/VLMs to generate textual reasoning chains for symbolic planning and physical law inference; and latent reasoning, which operates directly in a unified latent space to preserve sub-symbolic, continuous physical details. The module dynamically selects or combines these approaches based on task requirements, ensuring both interpretability and fidelity in complex scenarios.
Memory is implemented as a structured, dynamic knowledge system capable of managing multimodal, high-concurrency interaction streams. It extends beyond sequential storage by incorporating mechanisms for categorization, association, and fusion of experiential data. The memory module also performs key information extraction and compression to maintain efficiency, while continuously updating and purging redundant content to preserve relevance and timeliness.
The environment component is not merely a passive simulator but an active, learnable, and generative entity. It supports both physical and simulated interactions, with an emphasis on generative 3D scene synthesis and procedural content creation to bridge the sim-to-real gap. This enables training on near-infinite, physically consistent environments, enhancing the model’s generalization to open-world scenarios.
Finally, multimodal generation enables the model to synthesize realistic outputs—including video, images, audio, and 3D geometry—based on internal states and predictions. This capability is tightly coupled with reasoning and memory, forming a closed loop where generated content supports planning, self-augmentation, and verification of world understanding. For example, in navigation tasks, the model can generate a 3D scene from the agent’s perspective to simulate and validate its strategy before execution.
Together, these modules form a tightly integrated system that continuously perceives, reasons, remembers, acts, and generates, enabling robust, adaptive, and human-aligned interaction with complex, dynamic environments.