Command Palette
Search for a command to run...
다이나믹VLA: 동적 물체 조작을 위한 시각-언어-행동 모델
다이나믹VLA: 동적 물체 조작을 위한 시각-언어-행동 모델
Haozhe Xie Beichen Wen Jiarui Zheng Zhaoxi Chen Fangzhou Hong Haiwen Diao Ziwei Liu
초록
동적 물체 조작은 비전-언어-행동(Vision-Language-Action, VLA) 모델에게 여전히 해결되지 않은 과제로 남아 있다. 비록 정적 조작 상황에서는 뛰어난 일반화 능력을 보이지만, 빠른 인지, 시간적 예측 및 지속적인 제어가 요구되는 동적 환경에서는 여전히 어려움을 겪는다. 본 연구에서는 세 가지 핵심 설계를 통해 시간적 추론과 폐쇄 루프 적응을 통합한 동적 물체 조작을 위한 프레임워크인 DynamicVLA를 제안한다. 첫째, 공간 효율적이고 구조적으로 충실한 인코딩을 가능하게 하는 컨볼루션 기반 비전 인코더를 사용한 0.4B 규모의 컴팩트한 VLA 모델을 도입하여 빠른 다모달 추론을 실현한다. 둘째, 연속적 추론(Continuous Inference) 기법을 도입하여 추론과 실행을 겹쳐 수행함으로써 지연 시간을 낮추고 물체의 운동에 실시간으로 적응할 수 있도록 한다. 셋째, 감각-실행 간 격차를 해소하기 위해 시간적으로 정렬된 행동 실행을 강제하는 잠재 인식 기반 행동 스트리밍(Latent-aware Action Streaming)을 제안한다. 동적 조작 데이터의 기반 부족 문제를 해결하기 위해, 자동 데이터 수집 파이프라인을 활용해 2,800개의 장면과 206종의 물체를 기반으로 총 20만 개의 합성 에피소드를 효율적으로 수집한 동적 물체 조작(Dynamic Object Manipulation, DOM) 벤치마크를 새로 도입하였다. 이 벤치마크는 원격 조작 없이도 2,000개의 실제 환경 에피소드를 신속하게 수집할 수 있도록 지원한다. 광범위한 평가 결과를 통해 반응 속도, 인지 능력 및 일반화 성능에서 뚜렷한 향상을 입증하였으며, DynamicVLA는 다양한 로봇 구현체를 아우르는 일반적인 동적 물체 조작을 위한 통합 프레임워크로 자리매김하고 있다.
One-sentence Summary
Researchers from Nanyang Technological University’s S-Lab propose DynamicVLA, a compact 0.4B-parameter VLA model featuring Continuous Inference and Latent-aware Action Streaming to eliminate perception-execution gaps in dynamic manipulation, validated on their novel DOM benchmark with 200K synthetic and 2K real-world episodes across multiple robot embodiments.
Key Contributions
- DynamicVLA introduces a compact 0.4B-parameter VLA model with a convolutional vision encoder for fast, spatially efficient inference, enabling real-time closed-loop control in dynamic object manipulation where latency critically impacts success.
- It implements Continuous Inference and Latent-aware Action Streaming to eliminate perception-execution gaps and inter-chunk waiting, ensuring temporally aligned, continuous action execution despite object motion and inference delays.
- The paper establishes the DOM benchmark with 200K synthetic and 2K real-world episodes across 2.8K scenes and 206 objects, collected via automated pipelines, enabling rigorous evaluation of perception, interaction, and generalization in dynamic manipulation tasks.
Introduction
The authors leverage Vision-Language-Action (VLA) models to tackle dynamic object manipulation, a critical challenge where robots must react to moving objects with precise, real-time control—unlike static tasks where latency is tolerable. Prior VLAs and robotic systems struggle with perception-execution delays and lack data for dynamic scenarios, often relying on predictable motion or forgiving tasks like ball-paddling. DynamicVLA introduces a compact 0.4B-parameter model with a convolutional vision encoder for fast inference, plus two key modules: Continuous Inference to overlap prediction and action, and Latent-aware Action Streaming to discard stale commands and maintain temporal alignment. To enable evaluation and training, they build the DOM benchmark with 200K synthetic and 2K real-world episodes via an automated pipeline, supporting generalization across scenes, objects, and robot embodiments.
Dataset

-
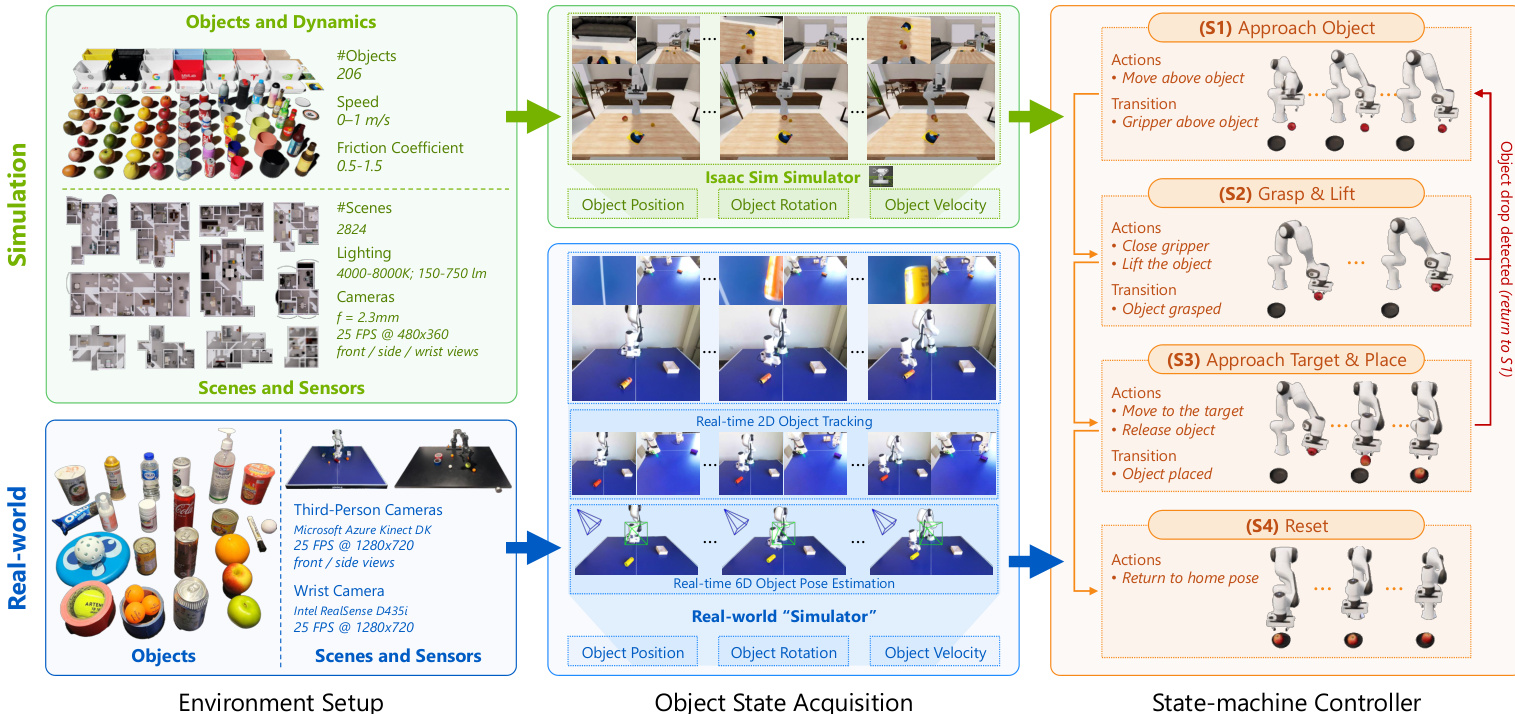
The authors use DOM, the first large-scale benchmark for dynamic object manipulation, to address the lack of standardized datasets for evaluating robotic policies on moving objects. It combines 200K synthetic episodes from simulation with 2K real-world episodes where human teleoperation is impractical due to fast object motion.
-
Real-world data comes from a custom “simulator” system using commodity RGB-D sensors (two Azure Kinect DK cameras and a wrist-mounted RealSense D435i) to estimate 6D object poses and velocities in real time. This setup enables teleoperation-free, high-frequency data collection (~10 seconds per episode) across Franka and PiPER robots for consistent multi-embodiment evaluation.
-
The real-world scenes include 25 household objects (containers, food, bottles, tools), with multiple objects per episode—some as targets, others as distractors. Object states are estimated using EfficientTAM for segmentation, followed by geometric triangulation for 3D centroids and motion fitting for velocity, producing low-latency, controller-compatible state streams.
-
The same four-stage controller from simulation runs unchanged in the real world, consuming the estimated 6D object states and target poses. This unified pipeline ensures consistent behavior across simulation and real environments, supporting scalable, reproducible evaluation along interaction, perception, and generalization dimensions.
Method
The authors leverage a compact 0.4B-parameter Vision-Language Action (VLA) model, referred to as DynamicVLA, designed for fast and efficient multimodal reasoning in dynamic object manipulation tasks. The overall framework integrates a vision-language backbone with a diffusion-based action expert, enabling continuous inference and temporally consistent action execution. The architecture is structured to minimize latency while maintaining robust perception and reasoning capabilities in environments where object states evolve continuously.
The vision-language backbone employs a convolutional vision encoder, FastViT, to process multi-frame visual inputs efficiently. This choice avoids the quadratic token growth associated with transformer-based vision encoders, allowing for scalable processing of temporal observation windows. The language backbone is derived from SmolLM2-360M, truncated to its first 16 transformer layers to reduce inference latency with minimal impact on multimodal reasoning. Visual observations, language instructions, and robot proprioceptive state are jointly encoded and processed by the language backbone. Specifically, RGB images in the temporal window are concatenated and encoded by FastViT, which outputs a reduced set of visual tokens. The robot's proprioceptive state, represented as a 32-dimensional vector, is linearly projected into the language embedding space and treated as a single state token. These visual, language, and state tokens are concatenated and processed together by the language backbone, producing key-value representations that are cached and reused across inference cycles.
The action generation is handled by a dedicated diffusion-based action expert, instantiated as a lightweight transformer copied from the language backbone and also truncated to 16 layers. This expert predicts an action chunk with a horizon of n=20 timesteps, which is sufficient under continuous inference while keeping latency low. Each action is a 32-dimensional vector representing end-effector pose and gripper state. The action expert uses a reduced hidden dimension of 720 to lower computation. During training, the expert is optimized to denoise a noisy action chunk Atτ conditioned on the multimodal features ft extracted from the visual observations, using a flow matching objective. The objective is defined as:
ℓτ(θ)=Ep(At∣ft),q(A∗τ∣At)[Eθ(Atτ,Ot)−u(Atτ∣At)]where q(Atτ∣At)=N(τAt,(1−τ)I) and Atτ=τAt+(1−τ)ϵ, with ϵ∼N(0,I). Under this objective, the action expert learns to match the denoising vector field u(Atτ∣At)=ϵ−At.
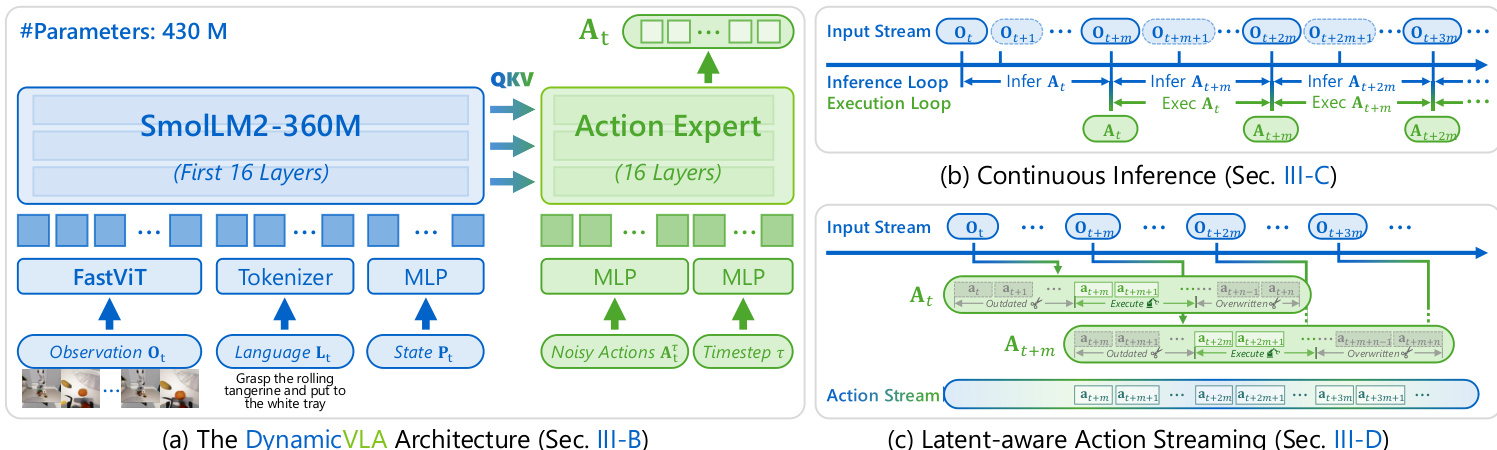
To address the challenge of inference latency in dynamic environments, the model employs a continuous inference strategy. In this paradigm, inference cycles are triggered as soon as the previous inference finishes, independent of whether the previously predicted action sequence has been exhausted. This pipelined approach allows the next action sequence to be inferred while the current one is being executed, eliminating inter-chunk waiting and enabling non-blocking action execution. The inference delay, denoted by m, represents the number of timesteps between the start and completion of an inference cycle. The model predicts an action sequence At={at,…,at+n} at time t, and the next inference cycle begins at t+m, predicting At+m.
However, this continuous inference introduces a temporal misalignment between predicted actions and the evolving environment, manifesting as a perception-execute gap and conflicts between overlapping action chunks. To resolve these issues, the authors implement a latent-aware action streaming (LAAS) strategy. Actions in the current action chunk At that correspond to timesteps earlier than t+m are discarded as outdated. For timesteps where the current and next action chunks overlap, actions from the newer sequence At+m are prioritized, overwriting those from At. This ensures that execution adapts promptly to the most recent environment state, particularly under dynamic object motion. The model is trained in three stages: a pre-training stage on 150M English image-text pairs, a mid-training stage on the synthetic Dynamic Object Manipulation (DOM) dataset, and a post-training stage on real-world robot demonstrations to adapt to new embodiments and sensing configurations.
Experiment
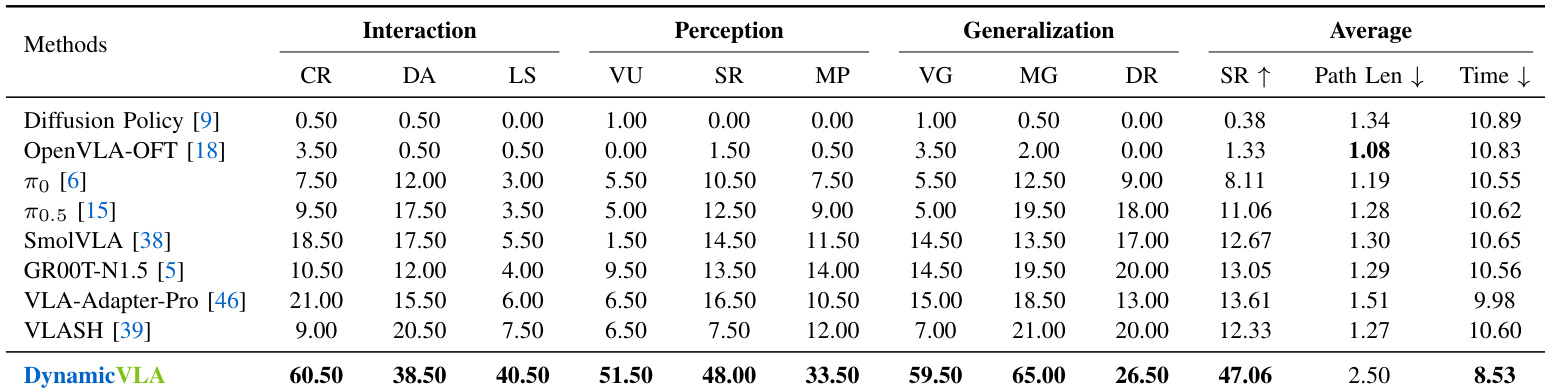
- DynamicVLA excels in dynamic object manipulation under real-time constraints, outperforming baselines across Interaction, Perception, and Generalization dimensions on the DOM benchmark (1,800 trials), achieving 60.5%/38.5%/40.5% success in Interaction tasks—surpassing best baselines by +188.1% to +440.0%.
- In real-world tests (Franka and PiPER arms), DynamicVLA achieves 51.9% success in Perception tasks vs. 11.7% for top baselines, demonstrating superior spatial-temporal reasoning under motion.
- Generalization tests show DynamicVLA robust to unseen objects and motion patterns, though environmental perturbations remain challenging; real-world appearance and motion shifts show consistent performance advantage.
- Ablations confirm 360M LLM backbone balances capacity and latency; FastViT encoder outperforms transformers via lower latency; Continuous Inference and Latent-aware Action Streaming are critical for temporal alignment, boosting success by up to 22.3%.
- Integrated into SmolVLA and π0.5, CI+LAAS improve performance generically, but gains are limited by model-specific inference latency.
- Truncated 16-layer LLM backbone offers optimal efficiency-robustness trade-off; sparse two-frame visual context (t-2, t) maximizes motion perception without added latency.
- Runs at 88Hz on RTX A6000 with 1.8GB GPU memory, trained over two weeks on 32 A100 GPUs.
The authors use ablation studies to evaluate the impact of key design choices in DynamicVLA, including model size, visual encoding, and execution mechanisms. Results show that combining Continuous Inference and Latent-aware Action Streaming with a 360M model achieves the highest success rate of 47.06%, while removing either component significantly reduces performance, indicating their complementary roles in maintaining stability and responsiveness during dynamic manipulation.
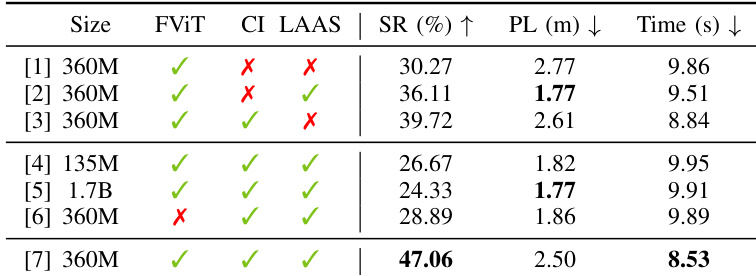
The authors use a temporal ablation study to evaluate the impact of visual context on dynamic manipulation performance, varying the observation window to include different combinations of past frames. Results show that using a sparse temporal window with frames at t−2 and t achieves the highest success rate and lowest task completion time, indicating that this configuration provides optimal motion cues without unnecessary redundancy.
The authors use a simulation benchmark to evaluate DynamicVLA against baseline models on dynamic object manipulation tasks, reporting success rate, path length, and task completion time. Results show that DynamicVLA achieves a success rate of 47.06%, outperforming π₀.₅ and SmolVLA in both success rate and task completion time, while also exhibiting a longer path length.

The authors evaluate the impact of LLM backbone depth on DynamicVLA's performance by retaining the first l transformer layers during inference. Results show that a 16-layer backbone achieves the highest success rate while maintaining efficient inference, indicating it strikes the optimal balance between model capacity and computational efficiency.
Results show that DynamicVLA significantly outperforms all baseline methods across the dynamic object manipulation benchmark, achieving the highest success rates in interaction, perception, and generalization categories. The authors use the table to demonstrate that DynamicVLA achieves 60.5% success in closed-loop reactivity, 38.5% in dynamic adaptation, and 40.5% in long-horizon sequencing, substantially surpassing the best baseline in each interaction subtask.