Command Palette
Search for a command to run...
비전-딥리서치: 다중모달 대규모 언어 모델에서 딥리서치 능력 유도하기
비전-딥리서치: 다중모달 대규모 언어 모델에서 딥리서치 능력 유도하기
초록
다중모달 대규모 언어 모델(Multimodal Large Language Models, MLLMs)은 다양한 비전 작업에서 놀라운 성과를 거두고 있다. 그러나 내부 세계 지식의 한계로 인해, 과거 연구들은 시각적 및 텍스트 검색 엔진을 활용하여 '추론 후 도구 호출(reasoning-then-tool-call)' 방식을 도입함으로써 MLLMs의 성능을 향상시키는 방안을 제안해왔다. 이는 광범위한 사실 정보를 요구하는 과제에서 상당한 성과를 거두었다. 그러나 이러한 접근 방식은 일반적으로 다중모달 검색을 단순한 설정에서 정의하며, 하나의 전체 수준 또는 엔티티 수준의 이미지 쿼리와 몇 개의 텍스트 쿼리만으로도 질문에 대한 핵심 증거를 효과적으로 검색할 수 있다고 가정한다. 이는 실세계에서 큰 시각적 노이즈가 존재하는 상황에서는 현실적이지 않다. 또한 이러한 기법들은 추론의 깊이와 검색의 폭이 제한적이어서, 다양한 시각적 및 텍스트적 소스로부터 증거를 통합해야 하는 복잡한 질문을 해결하기 어렵다.이러한 문제를 해결하기 위해, 우리는 새로운 다중모달 심층 탐구(paradigm)인 Vision-DeepResearch를 제안한다. 이 모델은 고도로 노이즈가 있는 실세계 검색 엔진에서도 강건하게 작동할 수 있도록, 다단계, 다엔티티, 다스케일의 시각적 및 텍스트적 검색을 수행한다. Vision-DeepResearch는 수십 개의 추론 단계와 수백 개의 엔진 상호작용을 지원하며, 콜드스타트 감독과 강화학습(RL) 훈련을 통해 MLLM 내부에 심층 탐구 능력을 내재화함으로써, 강력한 엔드투엔드 다중모달 심층 탐구 MLLM을 구현한다. 이 모델은 기존의 다중모달 심층 탐구 MLLM들뿐 아니라, GPT-5, Gemini-2.5-pro, Claude-4-Sonnet과 같은 강력한 폐쇄형 기초 모델 기반 워크플로우보다도 뛰어난 성능을 보이며, 실용성과 효율성 면에서 우수한 성과를 나타낸다. 코드는 https://github.com/Osilly/Vision-DeepResearch 에 공개될 예정이다.
One-sentence Summary
Researchers from CUHK MMLab, USTC, and collaborators propose Vision-DeepResearch, a new multimodal paradigm enabling multi-turn, multi-entity, multi-scale search via deep-reasoning MLLMs trained with SFT and RL, outperforming GPT-5 and Gemini-2.5-pro on noisy real-world image retrieval tasks with fewer parameters.
Key Contributions
- Vision-DeepResearch introduces a new multimodal deep-research paradigm that performs multi-turn, multi-entity, and multi-scale visual and textual searches to overcome the low hit-rate problem in noisy real-world search engines, where prior methods rely on simplistic full-image or single-entity queries.
- The framework internalizes deep-research capabilities into MLLMs via cold-start supervised fine-tuning and reinforcement learning, enabling dozens of reasoning steps and hundreds of engine interactions—significantly expanding reasoning depth and search breadth beyond existing approaches.
- Evaluated on six benchmarks, Vision-DeepResearch achieves state-of-the-art performance with smaller models (8B and 30B-A3B scales), outperforming both open-source multimodal deep-research MLLMs and workflows built on closed-source models like GPT-5, Gemini-2.5-pro, and Claude-4-Sonnet.
Introduction
The authors leverage multimodal large language models (MLLMs) to tackle complex, fact-intensive visual question answering by enabling deep-research capabilities that go beyond single-query, single-scale retrieval. Prior methods treat visual search as a one-off operation using full-image or entity-level queries, ignoring real-world noise and search engine variability—leading to low hit rates and shallow reasoning. They also limit training to short trajectories, preventing models from performing iterative, multi-step evidence gathering. The authors’ main contribution is Vision-DeepResearch, a new paradigm that synthesizes long-horizon, multi-turn trajectories involving multi-entity, multi-scale visual and textual search. Through cold-start supervision and RL training, they equip MLLMs to perform dozens of reasoning steps and hundreds of engine interactions, achieving state-of-the-art results on six benchmarks—even outperforming agent workflows built on closed-source models like GPT-5 and Gemini-2.5-Pro.
Dataset

-
The authors use a curated collection of real-world, high-quality images from multiple open-source datasets, filtering out those smaller than 224×224 pixels. They apply an MLLM to select visually complex, non-trivial images and discard any that can be answered without external evidence or that return exact matches via image search.
-
From the retained images, they generate “Fuzzy Multi-hop VQA” instances: first prompting an MLLM to propose entity-level bounding boxes, then cropping regions at multiple scales and verifying entity consistency via image search. Entity-level questions (e.g., “What is the name of the cat?”) are generated, then deliberately obfuscated via two techniques: (1) answer chaining to deepen reasoning, and (2) entity replacement via random walks over webpages to simulate multi-hop knowledge. These are interleaved to avoid templated or shortcut-prone patterns.
-
The final synthesis pipeline emulates human question design: extracting keywords, retrieving external evidence, generating multiple candidate questions, and selecting the best via a judge MLLM. This produces complex, realistic VQA problems paired with answers, used for both trajectory synthesis and RL training.
-
For supervised fine-tuning (SFT), the authors construct 30K high-quality multimodal deep-research trajectories: 16K from verified fact-centric VQA problems (augmented with trajectories), 8K text-only QA trajectories, and 6K fuzzy VQA trajectories. All are trained using autoregressive CE loss to teach multi-turn, multi-scale, cross-modal reasoning and planning.
-
For RL training, they use 15K verified VQA instances, sampling trajectories via interaction with a live search environment. Reward is computed via an LLM-as-Judge evaluating answer correctness and adherence to ReAct formatting, optimized using the rllm framework.
-
The training data is processed using Ms-Swift for SFT and rllm for RL, applied to Qwen3-VL-30B and Qwen3-VL-8B models. The pipeline emphasizes visual cropping, external search, and long-horizon reasoning behaviors, with evaluation on six benchmarks including VDR-Bench, FVQA, and BC-VL.
Method
The authors leverage a highly automated data pipeline to construct long-horizon multimodal deep-research trajectories, enabling their Vision-DeepResearch agent to perform complex vision-language reasoning in noisy web environments. The pipeline integrates visual search with text-based reasoning, bridged through image descriptions, and is structured into two primary phases: visual evidence gathering and text-based deep-research extension.
As shown in the figure below, the process begins with an input image and question. The model first generates reasoning steps and localizes relevant regions via multi-entity and multi-scale cropping, producing a set of bounding boxes Sb={Ib1,…,Ibn}. Each crop triggers a visual action At=Tool-Call(Sbt), submitted to a visual search tool pipeline. The pipeline returns observations Otv, which are accumulated into visual evidence Vtv={O1,…,Otv}. This sequence includes three sequential tools: visual search (to retrieve URLs), website visit (to fetch markdown content), and website summary (to extract relevant text while filtering noise).
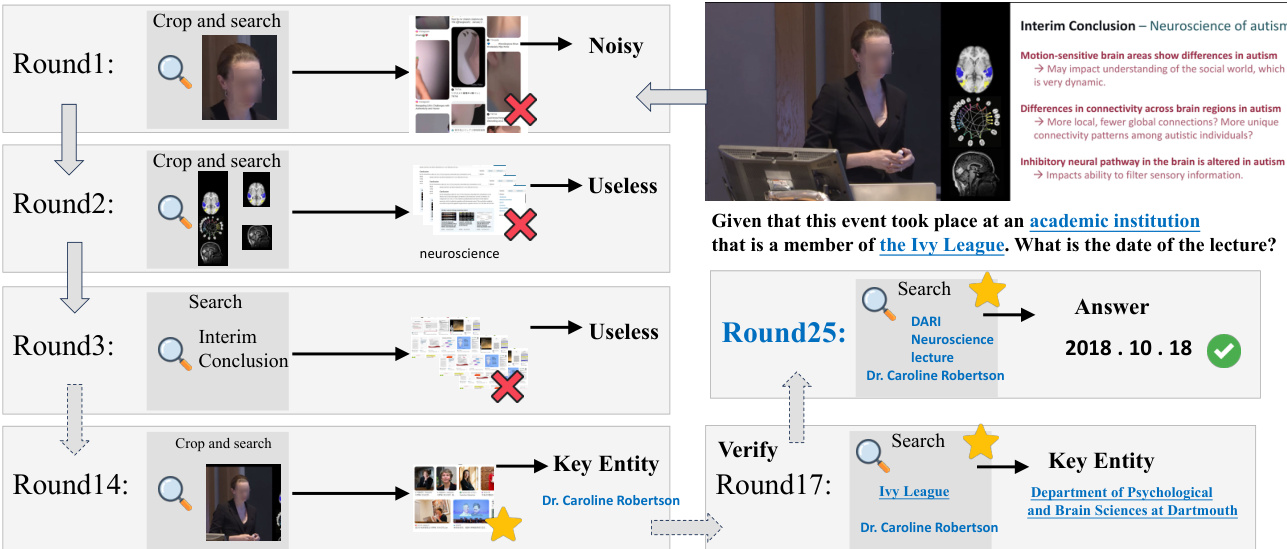
To control search depth, an external judge model evaluates whether the accumulated evidence Vtv is sufficient to support downstream reasoning, outputting a binary hit signal htv=Judge(I,q,Vtv,atrue)∈{0,1}. If htv=0, the pipeline continues; if htv=1, the visual phase terminates at step Tv. The resulting visual trajectory is denoted as Cvision={I,q,pv,R1,A1,O1,…,pv,RTv,ATv,OTv}.
The authors then bridge this visual trajectory to text by replacing the original image I with a detailed textual description D, while preserving the reasoning, actions, and observations. This bridged context is fed into a text-based deep-research foundation LLM, which extends the trajectory using tools such as web search, website visit & summary, and Python code execution. The textual trajectory is denoted as Ctext={D,q,R1,A1,O1,…,RTv,ATv,OTv,pt,RTv+1,ATv+1,OTv+1,…,RTv+Tt,ATv+Tt,aoutput}, where Tt is the number of text-based steps and aoutput is the final answer.
The full multimodal trajectory Cmultimodal merges both phases and undergoes rejection sampling: an LLM verifies whether aoutput matches the ground-truth atrue, retaining only consistent trajectories for training. The authors also incorporate text-only trajectories generated directly from the original question.
For training, the authors combine supervised fine-tuning (SFT) with reinforcement learning (RL). The RL phase employs a high-throughput asynchronous rollout architecture built on the rLLM framework, enabling concurrent tool calls and achieving over 10× higher throughput than synchronous methods. Training uses Group Relative Policy Optimization (GRPO) with a Leave-One-Out trick, applied to 15K high-quality VQA instances. The model interacts with a real online search environment, sampling long-horizon trajectories capped at 50 turns, 64K context tokens, and 4K response tokens per turn.
Reward is determined via an LLM-as-Judge paradigm: a reward of 1.0 is assigned if the final answer is correct, 0.0 otherwise. To ensure training stability, the authors implement several engineering safeguards: trajectory interruption for repetitive text or cascading tool-call failures, masking of anomalous trajectories from gradient updates, and training in BF16 precision to avoid numerical overflow from long contexts.
Refer to the framework diagram for an overview of the end-to-end Vision-DeepResearch paradigm, including the integration of factual VQA synthesis, multi-turn trajectory generation, and the long-horizon ReAct-style reasoning loop.
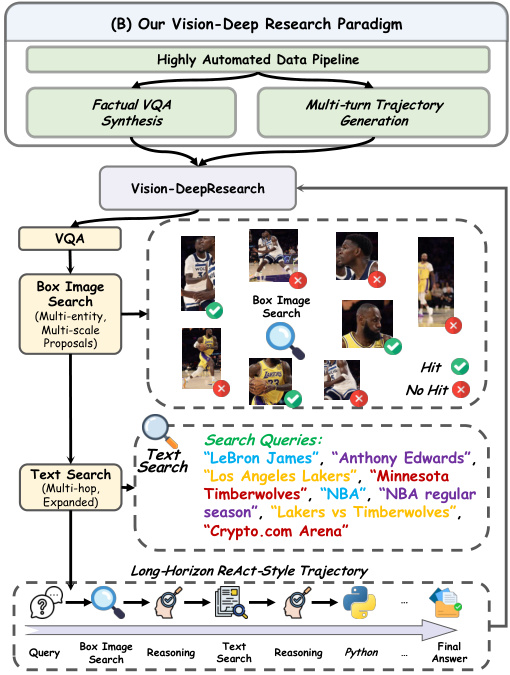
The final training data includes both multimodal trajectories and text-only deep-research trajectories, enabling the agent to generalize across modalities and perform robust, long-horizon reasoning in complex, real-world web environments.
Experiment
- Our approach outperforms existing open models and rivals strong proprietary systems on multimodal deep-research tasks, particularly when using agentic workflows that combine reasoning with tool use.
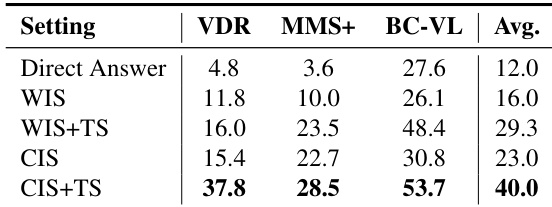
- Ablation studies confirm that multi-scale visual cropping and text search are jointly essential: cropping improves object-level grounding, while text search provides missing factual context, together enabling balanced performance across benchmarks.
- Data ablation shows that supervised fine-tuning with tool-augmented trajectories significantly improves performance, and reinforcement learning further refines long-horizon decision making, yielding the best overall results.
- RL training reduces trajectory length while increasing reward, indicating more efficient tool usage, with further gains expected from larger-scale RL optimization.
- Direct answering without tools performs poorly, while ReAct-style agentic reasoning consistently delivers substantial improvements, validating the necessity of iterative evidence gathering for complex multimodal tasks.
The authors use a multimodal agent framework combining multi-scale visual cropping and text search to significantly improve open-domain reasoning performance over baseline models. Results show that their approach outperforms both proprietary and open-source models under agentic workflows, with gains driven by better long-horizon tool-use behavior and evidence grounding. Ablation studies confirm that both visual localization and textual retrieval are jointly necessary, and reinforcement learning further refines decision-making beyond supervised fine-tuning.
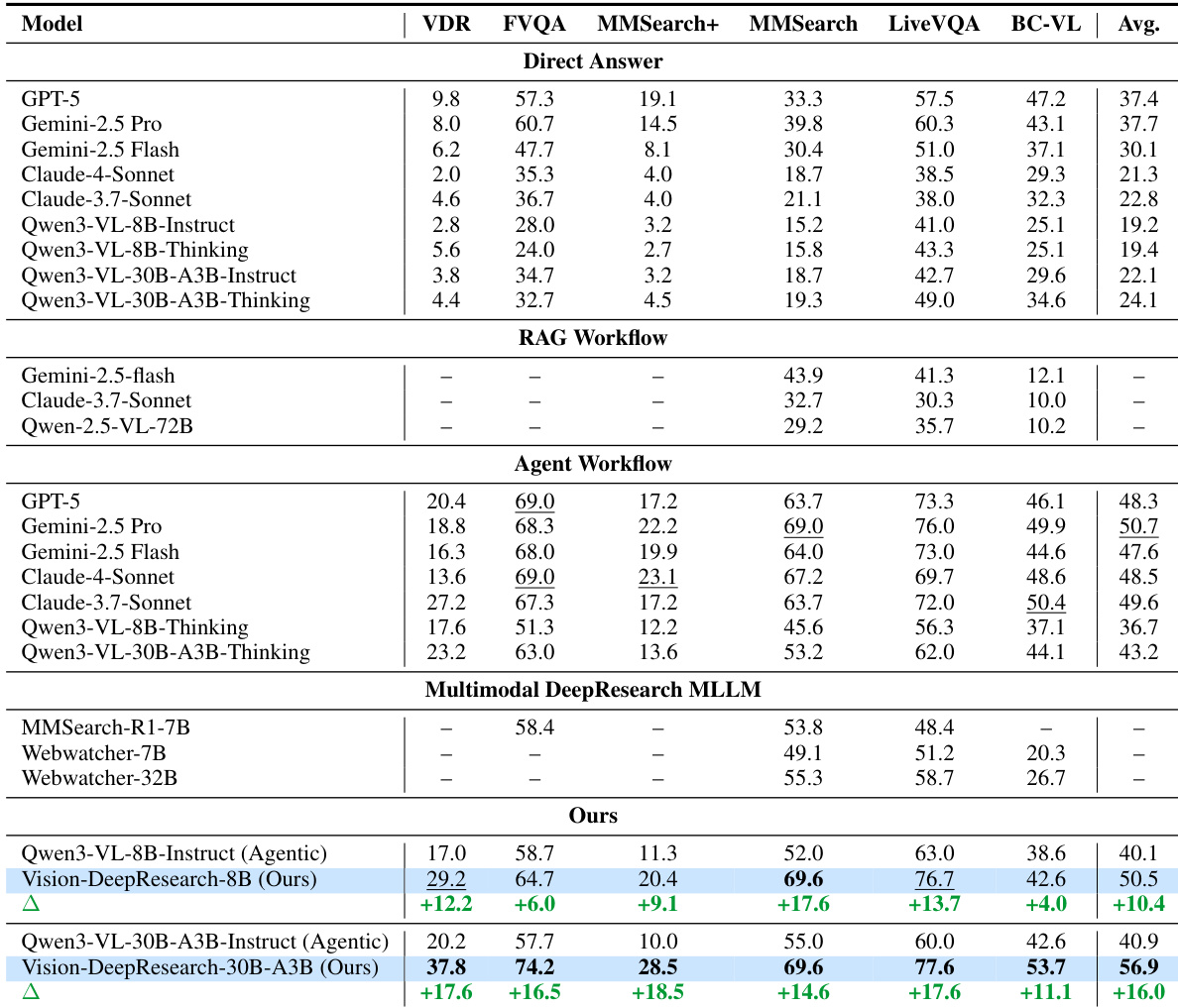
The authors evaluate different retrieval strategies in multimodal reasoning, finding that combining multi-scale visual cropping with text search (CIS+TS) yields the strongest and most balanced performance across benchmarks. Results show that relying solely on direct answers or whole-image search leads to poor outcomes, while integrating localized visual anchors with textual evidence significantly improves accuracy. This indicates that effective multimodal reasoning requires both precise visual grounding and complementary factual retrieval.
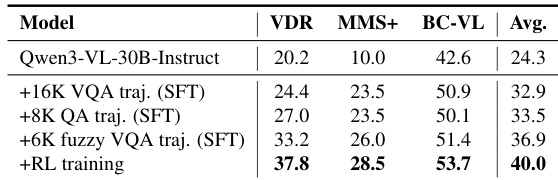
The authors use a combination of supervised fine-tuning with tool-augmented trajectories and reinforcement learning to significantly improve multimodal reasoning performance. Results show that adding verified and fuzzy multi-hop trajectories boosts accuracy, while RL further refines long-horizon decision-making, leading to the best overall scores across benchmarks. The final model outperforms the base version by a substantial margin, demonstrating the value of iterative tool use and reward-driven optimization.