Command Palette
Search for a command to run...
MMFineReason: 오픈 데이터 중심적 방법을 통한 다중모달 추론 격차 해소
MMFineReason: 오픈 데이터 중심적 방법을 통한 다중모달 추론 격차 해소
Honglin Lin Zheng Liu Yun Zhu Chonghan Qin Juekai Lin Xiaoran Shang Conghui He Wentao Zhang Lijun Wu
초록
최근 비전-언어 모델(Vision Language Models, VLMs)의 발전은 시각적 추론 분야에서 중요한 진전을 이끌었다. 그러나 오픈소스 VLM들은 여전히 사내 개발 시스템에 뒤처져 있으며, 주로 고품질 추론 데이터의 부족 때문이라고 볼 수 있다. 기존 데이터셋은 STEM 다이어그램이나 시각적 퍼즐과 같은 도전적인 분야에 대한 커버리지가 제한적이며, 강력한 추론 능력을 유도하기 위해 필수적인 일관성 있고 장문형의 사고 과정(Chain-of-Thought, CoT) 주석도 부족한 실정이다. 이러한 격차를 메우기 위해 우리는 Qwen3-VL-235B-A22B-Thinking 모델로부터 고도로 정제된 추론 주석을 도출한 대규모 다중모달 추론 데이터셋 MMFineReason을 소개한다. 이 데이터셋은 총 180만 개의 샘플과 51억 개의 해결 토큰을 포함하며, 체계적인 세 단계 파이프라인을 통해 구축되었다: (1) 대규모 데이터 수집 및 표준화, (2) CoT 추론 과정 생성, (3) 추론 품질과 난이도 인식 기반의 종합적 선택. 최종적으로 생성된 데이터셋은 STEM 문제, 시각적 퍼즐, 게임, 복잡한 다이어그램 등 다양한 영역을 아우르며, 각 샘플은 시각적 정보에 기반한 추론 흐름을 명확히 주석화하였다. 우리는 MMFineReason 데이터셋을 기반으로 Qwen3-VL-Instruct 모델을 파인튜닝하여 MMFineReason-2B/4B/8B 버전을 개발하였다. 해당 모델들은 각 크기 범주에서 새로운 최고 성능(SOTA)을 달성하였다. 특히 MMFineReason-4B는 Qwen3-VL-8B-Thinking을 초월하였으며, MMFineReason-8B는 Qwen3-VL-30B-A3B-Thinking을 능가하면서 Qwen3-VL-32B-Thinking에 근접하는 성능을 보여, 놀라운 파라미터 효율성을 입증하였다. 특히 중요한 점은, 난이도 인식 기반 필터링 전략을 통해 ‘적은 것이 더 크다(less is more)’라는 현상을 발견했다는 점이다. 전체 데이터셋의 단지 7%에 해당하는 123,000개 샘플의 서브셋만으로도 전체 데이터셋과 유사한 성능을 달성할 수 있었으며, 이는 데이터의 질과 구성의 중요성을 강조한다. 또한, 추론 중심의 데이터 구성이 일반적 능력 향상에 상호보완적인 효과를 발휘함을 밝혀냈다.
One-sentence Summary
Researchers from Shanghai AI Lab, Peking University, and Shanghai Jiao Tong University introduce MMFineReason, a 1.8M-sample multimodal reasoning dataset distilled from Qwen3-VL-235B, enabling their fine-tuned MMFinereason-2B/4B/8B models to surpass larger proprietary systems via efficient, difficulty-filtered training and synergistic data composition.
Key Contributions
- We introduce MMFineReason, a 1.8M-sample multimodal reasoning dataset with 5.1B tokens, built via a three-stage pipeline that collects, distills Chain-of-Thought rationales from Qwen3-VL-235B-A22B-Thinking, and filters for quality and difficulty to address scarcity in STEM and puzzle domains.
- Fine-tuning Qwen3-VL-Instruct on MMFineReason yields MMFineReason-2B/4B/8B models that set new SOTA for their size class, with MMFineReason-4B surpassing Qwen3-VL-8B-Thinking and MMFineReason-8B outperforming Qwen3-VL-30B-A3B-Thinking while approaching Qwen3-VL-32B-Thinking.
- We reveal a “less is more” effect: a difficulty-filtered 7% subset (123K samples) matches full-dataset performance, and show reasoning-focused data composition improves both specialized and general capabilities, validated through ablation studies on training strategies and data mixtures.
Introduction
The authors leverage a data-centric approach to address the gap between open-source and proprietary Vision Language Models (VLMs) in multimodal reasoning. While prior efforts have expanded multimodal data quantity, they still lack high-quality, consistent Chain-of-Thought annotations—especially for STEM diagrams, visual puzzles, and complex diagrams—due to data scarcity and annotation cost. Existing datasets also suffer from fragmented annotation styles and insufficient reasoning depth, limiting reproducible research. The authors’ main contribution is MMFineReason, a 1.8M-sample dataset with 5.1B tokens of distilled, visually grounded reasoning traces generated via a three-stage pipeline: aggregation, CoT distillation from Qwen3-VL-235B, and difficulty-aware filtering. Fine-tuning Qwen3-VL-Instruct on this data yields MMFineReason-2B/4B/8B models that outperform much larger proprietary baselines—showing that just 7% of the data can match full-dataset performance, revealing a “less is more” efficiency. Their work also uncovers that reasoning-focused data improves general capabilities and provides practical training recipes for future multimodal model development.
Dataset

The authors use MMFineReason, a large-scale, open-source multimodal reasoning dataset built entirely with locally deployed models and no closed-source APIs. Here’s how it’s composed, processed, and used:
-
Dataset Composition & Sources:
The dataset aggregates and refines over 2.3M samples from 30+ open-source multimodal datasets, including FineVision, BMMR, Euclid30K, Zebra-CoT-Physics, GameQA-140K, and MMR1. It covers four domains: Mathematics (79.4%), Science (13.8%), Puzzle/Game (4.6%), and General/OCR (2.2%). The final training set, MMFineReason-1.8M, retains 1.77M high-quality samples after filtering. -
Key Subset Details:
- Mathematics: Dominated by MMR1 (1.27M), supplemented by WaltonColdStart, ViRL39K, Euclid30K, and others for geometric and symbolic diversity.
- Science: Anchored by VisualWebInstruct (157K) and BMMR (54.6K), with smaller additions like TQA and ScienceQA.
- Puzzle/Game: Led by GameQA-140K (71.7K), plus Raven, VisualSphinx, and PuzzleQA for abstract reasoning.
- General/OCR: Only 38.7K samples from LLaVA-CoT, used as regularization to preserve visual perception without diluting reasoning focus.
All datasets undergo strict filtering: multi-image, overly simple, or highly specialized (e.g., medical) data are excluded.
-
Processing & Metadata:
- Images are cleaned: corrupted or unreadable images are discarded; oversized images (>2048px) are resized while preserving aspect ratio; all are converted to RGB.
- Text is standardized: non-English questions are translated to English; noise (links, indices, formatting) is removed; shallow prompts are rewritten to demand step-by-step reasoning.
- Metadata includes: source.id, original-question/answer, standardized image/question/answer, augmented annotations (Qwen3-VL-235B-generated captions and reasoning traces), and metrics (pass rate, consistency flags).
- All samples receive 100% dense image captions (avg. 609 tokens), far exceeding prior datasets.
-
Annotation & Filtering:
- Qwen3-VL-235B-A22B-Thinking generates CoT explanations using a 4-phase framework and outputs them in a strict template: reasoning in
...blocks, final answer in<answer>...</answer>tags. - Filtering stages:
- Template/length validation (discard <100 words or malformed structure).
- N-gram deduplication (remove CoTs with 50-gram repeats ≥3 times).
- Correctness verification (compare extracted answer with ground truth; discard mismatches).
- Difficulty filtering: Qwen3-VL-4B-Thinking attempts each question 4 times; samples with 0% pass rate (123K) are kept for hard SFT; those with <100% pass rate (586K) are used for ablation studies.
- Qwen3-VL-235B-A22B-Thinking generates CoT explanations using a 4-phase framework and outputs them in a strict template: reasoning in
-
Model Training Use:
- The 1.8M dataset is split: 40K sampled for RL training, remainder for SFT.
- Mixtures prioritize challenging samples via pass-rate filtering to accelerate convergence.
- CoT lengths are significantly longer than baselines (avg. 2,910 tokens vs. HoneyBee’s 1,063), with Puzzle/Game tasks averaging 4,810 tokens, reflecting intensive reasoning demands.
- Visual content is 75.3% STEM/diagrammatic (geometric, logic, plots), ensuring symbolic reasoning focus while retaining diverse natural images for generalization.
This pipeline enables reproducible, high-quality training for open-source VLMs to close the gap with proprietary systems.
Method
The authors leverage a multi-stage framework designed to process and solve mathematical problems by integrating data construction, annotation, selection, and model training into a cohesive pipeline. The overall architecture begins with data construction, where raw data undergoes standardization and cleaning to prepare it for downstream tasks. This stage is followed by data annotation, in which a model performs thinking distillation and captioning to generate structured textual descriptions from the input. As shown in the figure below, the annotated data is then subjected to data selection, where template validation and redundancy checks filter the data into high-quality, difficulty-balanced subsets.
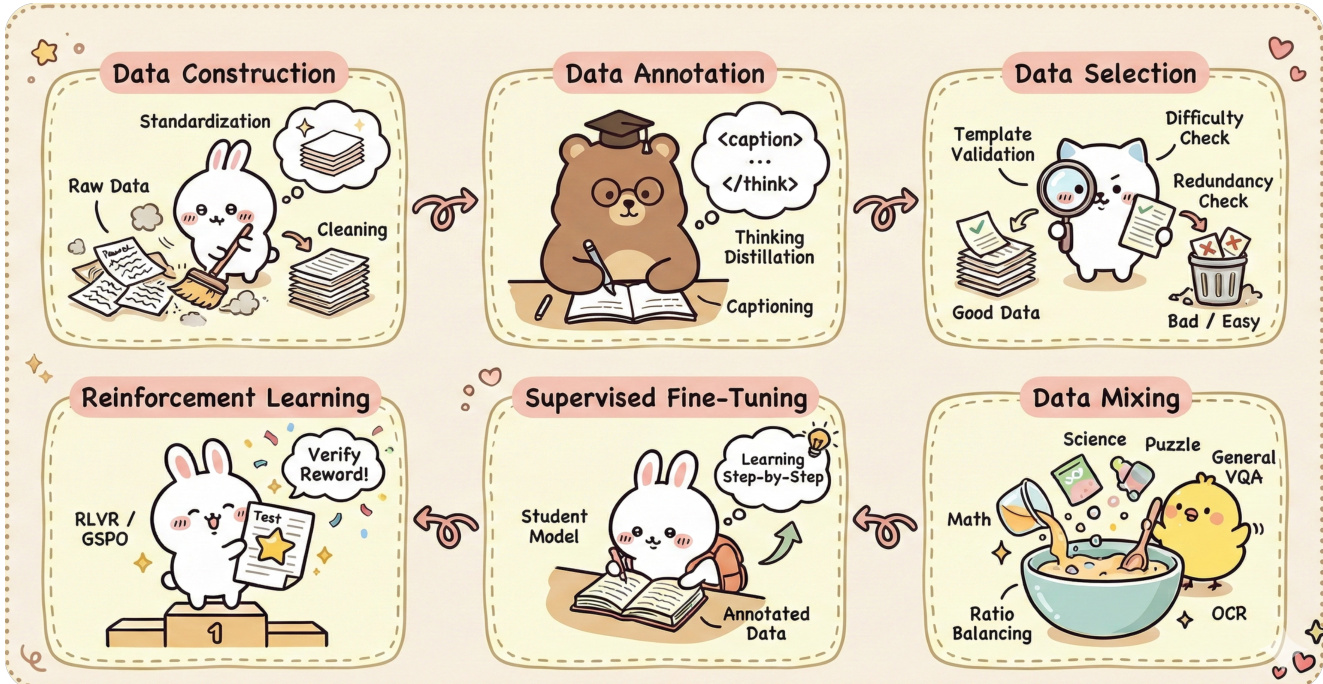
The selected data is used to train a student model through supervised fine-tuning, where the model learns step-by-step reasoning from annotated data. This process is enhanced by reinforcement learning, which employs a reward mechanism to optimize the model’s performance on test tasks, using methods such as RLVR or GSPO. Concurrently, data mixing combines diverse problem types—such as math, science, puzzles, and general VQA—into a unified training set, with ratio balancing and OCR integration to ensure diversity and coverage across domains.
The framework further incorporates a structured answer extraction process, guided by a set of prioritized rules that extract the final answer from a solution. These rules emphasize preserving LaTeX formatting, avoiding simplification, and handling multiple solutions or word-based answers appropriately. The extracted answer is then verified by comparing the generated response against a reference solution, focusing on semantic equivalence and factual correctness. The evaluation process assesses whether the generated answer conveys the same conclusion as the reference, with outputs formatted to include a concise analysis and a judgment of equivalence or difference.
Experiment
- Data-centric strategies enable strong scaling: MMFineReason models trained on 5.1B tokens surpass Qwen3-VL-30B-A3B-Thinking and approach GPT-5-mini-high performance.
- Difficulty-aware filtering yields 93% of full-dataset performance using only 7% of data (MMFineReason-123K), confirming high data efficiency.
- Reasoning-focused data mixing improves both general and reasoning tasks simultaneously, even with minimal general data.
- Ultra-high resolution (2048²) offers limited gains for reasoning tasks but remains beneficial for general vision benchmarks like RealWorldQA.
- Caption augmentation provides marginal or no benefit once reasoning chains are mature, as CoT already encodes sufficient visual context.
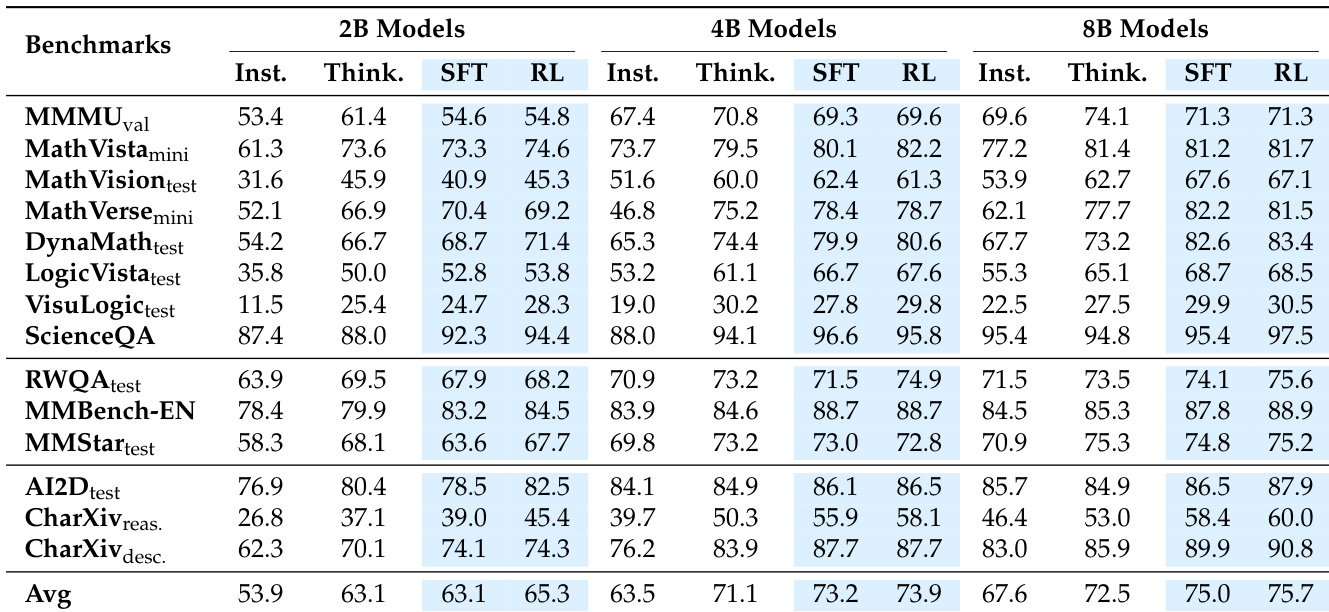
- MFR-8B achieves 83.4% on DynaMath, outperforming Qwen3-VL-32B-Thinking (82.0%) and Qwen3-VL-30B-A3B-Thinking (76.7%); on MathVerse, it reaches 81.5%, nearing Qwen3-VL-32B-Thinking (82.6%).
- MFR-8B outperforms HoneyBee-8B and OMR-7B by >30 points on MathVision (67.1% vs. 37.4%/36.6%), demonstrating superior reasoning chain quality.
- SFT drives major reasoning gains (e.g., +13.66% on MathVision for 8B), while RL enhances generalization on chart and real-world tasks (e.g., +4.04% on AI2D for 2B).
- MMFineReason-1.8M achieves 75.7 on benchmarks, outperforming HoneyBee-2.5M (65.1) and MMR1-1.6M (67.4), despite smaller data volume.
- MMFineReason-123K achieves 73.3, matching or exceeding full-scale baselines using only ~5% of their data volume.
- MFR-4B surpasses Qwen3-VL-8B-Thinking (73.9 vs. 72.5), proving data quality compensates for 2x smaller model size.
- MFR-8B sets new SOTA for its class (75.7), exceeding Qwen3-VL-30B-A3B-Thinking (74.5) and Gemini-2.5-Flash (75.0).
- ViRL39K achieves 98.9% of MMR1’s performance using only 2.4% of its data, confirming diminishing returns beyond curated data thresholds.
- WeMath2.0-SFT (814 samples) achieves 70.98%, rivaling datasets 1000x larger, validating high-density instruction as a capability trigger.
- Puzzle/game datasets (e.g., GameQA-140K, Raven) underperform due to mismatched reasoning styles; geometry-only data (Geo3K, Geo170K) shows limited generalization.
- Broad disciplinary coverage (e.g., BMMR) outperforms narrow domains (GameQA-140K), highlighting diversity as a stronger driver than task depth.
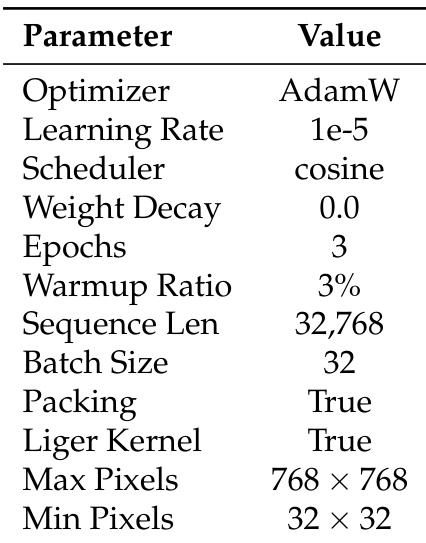
The authors use AdamW with a cosine scheduler and a learning rate of 1e-5 for supervised fine-tuning, training for 3 epochs with a sequence packing length of 32,768 and enabling the Liger Kernel. The model processes images resized to a maximum of 768 × 768 pixels during training, with a minimum resolution of 32 × 32 pixels.
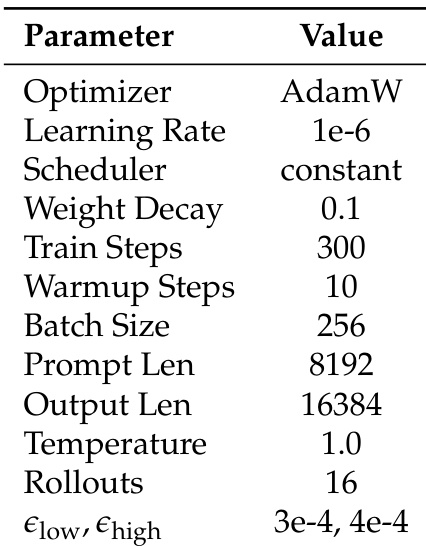
The authors use a constant learning rate scheduler and AdamW optimizer for the reinforcement learning stage, with 300 training steps and 16 rollouts per prompt. The model is trained with a temperature of 1.0 and a prompt length of 8192 tokens, using KL-divergence penalties set to 3e-4 and 4e-4.
The authors use a multi-stage training approach with supervised fine-tuning (SFT) and reinforcement learning (RL) to evaluate the performance of MMFineReason models across various benchmarks. Results show that SFT drives major gains in reasoning tasks, while RL enhances generalization on general understanding and chart reasoning benchmarks, with the 8B model achieving state-of-the-art results on its size class and outperforming larger open-source and closed-source models.
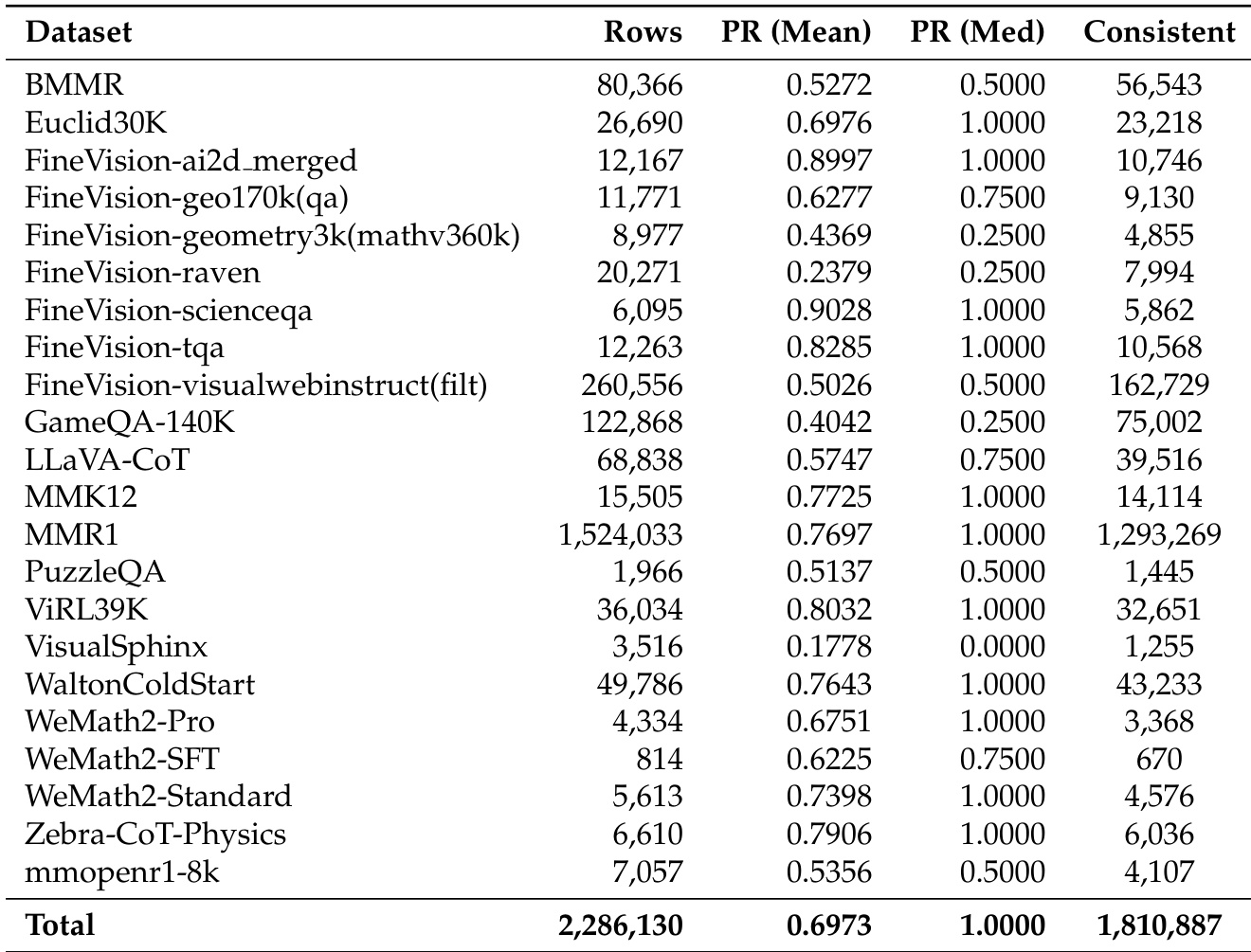
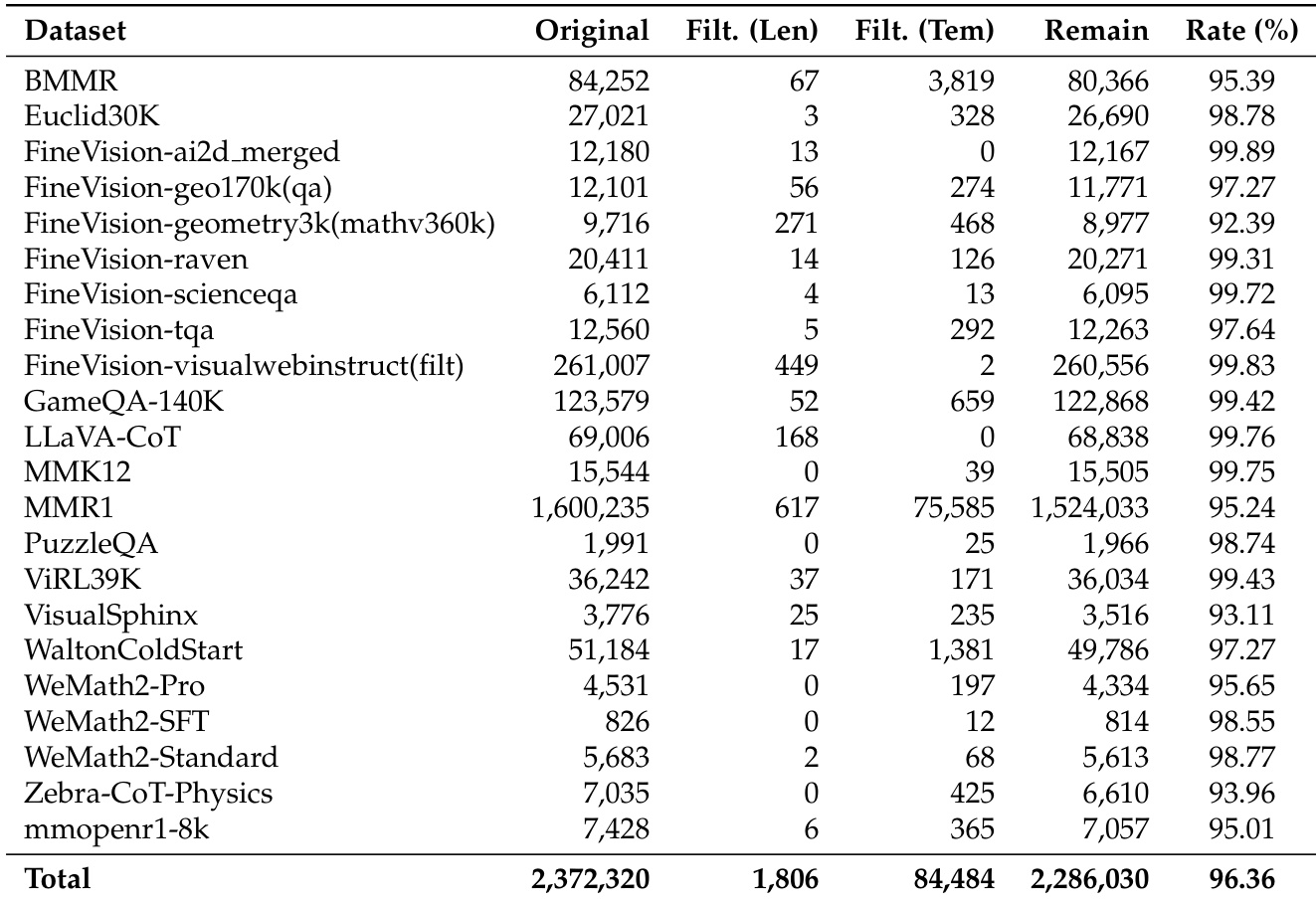
The authors use the table to quantify the impact of their filtering process on dataset size and quality, showing that filtering reduces the total number of samples from 2,372,320 to 1,806 while maintaining a high retention rate of 96.36%. The results indicate that the filtering strategy effectively removes low-quality or redundant data, particularly in datasets like MMR1 and FineVision-visualwebinstruct, which see significant reductions in sample count, while preserving high-quality reasoning data.
The authors use the table to compare the performance of various datasets on reasoning tasks, with metrics including mean pass rate (PR), median pass rate, and consistency. Results show that datasets like FineVision-ai2d_merged and FineVision-scienceqa achieve high mean pass rates, while others such as FineVision-geometry3k and FineVision-raven have significantly lower performance, indicating substantial variation in difficulty across datasets.