Command Palette
Search for a command to run...
DreamActor-M2: 시공간적 컨텍스트 내 학습을 통한 보편적인 캐릭터 이미지 애니메이션
DreamActor-M2: 시공간적 컨텍스트 내 학습을 통한 보편적인 캐릭터 이미지 애니메이션
Mingshuang Luo Shuang Liang Zhengkun Rong Yuxuan Luo Tianshu Hu Ruibing Hou Hong Chang Yong Li Yuan Zhang Mingyuan Gao
초록
캐릭터 이미지 애니메이션은 운동 정보를 운동 입력 시퀀스에서 정적 참조 이미지로 전이함으로써 고해상도 비디오를 합성하는 것을 목표로 한다. 최근의 기술 발전에도 불구하고, 기존 방법은 두 가지 근본적인 과제에 직면해 있다. 첫째, 정체성 보존과 운동 일관성 사이의 균형을 해치는 비최적의 운동 주입 전략으로 인해 ‘시소 효과’가 나타나며, 둘째, 골격과 같은 명시적 자세 사전 지식에 과도하게 의존함으로써 복잡한 운동 동역학을 충분히 포착하지 못하고, 인간형이 아닌 다양한 캐릭터에 대한 일반화 능력을 제한한다. 이러한 문제를 해결하기 위해, 우리는 움직임 조건화를 문맥 내 학습 문제로 재정의하는 보편적인 애니메이션 프레임워크인 DreamActor-M2를 제안한다. 본 연구는 이중 단계적 접근 방식을 따르며, 첫 번째 단계에서는 기초 모델의 생성 전제 지식을 활용해 참조 이미지의 시각적 특징과 운동 정보를 통합된 잠재 공간에 융합함으로써 입력 모달 간의 격차를 해소하고, 공간적 정체성과 시간적 동역학을 동시에 추론할 수 있도록 한다. 두 번째 단계에서는 자기 부트스트래핑 기반의 데이터 합성 파이프라인을 도입하여 가상의 다중 정체성 학습 쌍을 생성함으로써, 자세에 의존적인 제어에서 직접적인 RGB 기반의 엔드투엔드 애니메이션으로의 원활한 전환을 가능하게 한다. 이 전략은 다양한 캐릭터와 운동 시나리오에 걸쳐 뛰어난 일반화 성능을 크게 향상시킨다. 종합적인 평가를 가능하게 하기 위해, 다양한 캐릭터 유형과 운동 시나리오를 포괄하는 유연한 벤치마크인 AW Bench를 추가로 제안한다. 광범위한 실험 결과는 DreamActor-M2가 최신 기술 수준을 초월하며, 뛰어난 시각적 사실성과 강력한 교차 도메인 일반화 능력을 제공함을 입증한다. 프로젝트 페이지: https://grisoon.github.io/DreamActor-M2/
One-sentence Summary
Researchers from ByteDance, CAS, and Southeast University propose DreamActor-M2, a universal character animation framework that replaces pose priors with in-context learning and self-bootstrapped data to overcome identity-motion trade-offs, enabling high-fidelity, RGB-driven animation across diverse characters and motions.
Key Contributions
- DreamActor-M2 introduces a spatiotemporal in-context motion conditioning strategy that fuses appearance and motion into a unified latent space, enabling foundational video models to jointly preserve identity and motion without the “see-saw” trade-off.
- The framework employs a self-bootstrapped data synthesis pipeline to generate pseudo cross-identity training pairs, transitioning from pose-dependent control to end-to-end RGB-driven animation and significantly enhancing generalization across non-humanoid characters and complex motions.
- To support robust evaluation, the authors introduce AWBench, a new benchmark covering diverse character types and motion scenarios, where DreamActor-M2 demonstrates state-of-the-art visual fidelity and cross-domain generalization.
Introduction
The authors leverage foundational video diffusion models to tackle character image animation, where motion from a driving video is transferred to a static reference image—critical for digital entertainment but limited by trade-offs between identity preservation and motion fidelity. Prior methods either distort identity via pose-based injection or lose motion detail through attention-based compression, while relying on explicit pose priors that fail on non-humanoid characters. DreamActor-M2 reframes motion conditioning as an in-context learning problem, spatiotemporally fusing motion and appearance into a unified input to preserve both identity and dynamics. It introduces a self-bootstrapped pipeline that transitions from pose-guided to end-to-end RGB-driven animation, eliminating pose estimators and enabling robust generalization across diverse characters and motions. The authors also release AWBench, a new benchmark to rigorously evaluate cross-domain performance.
Dataset

- The authors use AWBench, a custom benchmark they created to evaluate DreamActor-M2’s ability to animate any subject—human or non-human—from driving videos and reference images.
- AWBench contains 100 driving videos and 200 reference images, selected to cover broad motion and identity diversity.
- Driving videos include human motions (face, upper body, full body; child, adult, elderly; dancing, daily activities; tracked and static camera) and non-human motions (animals like cats and monkeys, animated characters like Tom and Jerry).
- Reference images mirror this diversity, featuring humans, animals, and cartoon characters, with multi-subject cases (many-to-many, one-to-many) included to test complex scenarios not covered by prior datasets.
- The dataset was curated through manual collection and filtering to ensure quality and scope, and visual examples are provided in Figure 3.
- AWBench is used purely for evaluation; no training or mixture ratios are applied, and no cropping or metadata construction is described in this section.
Method
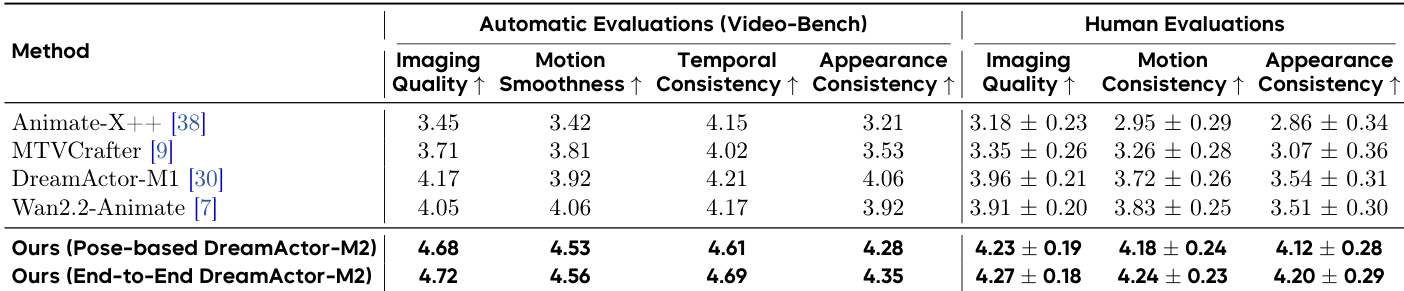
The authors leverage a unified framework called DreamActor-M2, designed to generate character animations conditioned on a reference image and driving motion signals—whether in the form of pose sequences or raw video clips. The architecture is modular and evolves from a pose-based variant to a fully end-to-end pipeline, both built atop a Latent Diffusion Model (LDM) backbone that employs the MMDiT architecture for multi-modal video generation. The core innovation lies in a spatiotemporal in-context motion injection strategy that avoids identity leakage while preserving fine-grained motion fidelity.
At the foundation, the model encodes input images into latent space via a 3D VAE, where Gaussian noise is progressively injected and denoised under conditional guidance. The denoising network, parameterized as ϵθ, is trained to minimize the reconstruction loss:
L=Ezt,c,ϵ,t(∣∣ϵ−ϵθ(zt,c,t)∣∣22)where c represents the conditional input derived from the in-context motion injection mechanism.
The spatiotemporal in-context injection strategy constructs a composite input sequence C∈RT×H×2W×3 by spatially concatenating the reference image with the first motion frame, and padding subsequent frames with zero images on the reference side. This preserves spatial correspondence without requiring lossy compression or explicit pose alignment. The motion and reference regions are distinguished via binary masks Mm and Mr, concatenated spatially to form M. The composite video C, along with its latent projection Z, noise latent Znoise, and mask M, are channel-concatenated to form the comprehensive input to the diffusion transformer.
Refer to the framework diagram for a visual breakdown of the pipeline, which illustrates the flow from driving video and reference image through spatiotemporal concatenation, conditional masking, and diffusion-based generation. The diagram also highlights the integration of text guidance and the dual training paradigms—pose-based and end-to-end.
In the pose-based variant, 2D skeletons serve as motion signals. To mitigate identity leakage from structural cues in pose data, the authors apply two augmentation strategies: random bone length scaling and bounding-box-based normalization. These preserve motion dynamics while decoupling body shape from motion semantics. To recover fine-grained motion details potentially lost during augmentation, a text guidance module is introduced. A multimodal LLM parses the driving video and reference image to generate motion and appearance descriptions, which are fused into a target-oriented prompt. This prompt is injected as a high-level semantic prior alongside the in-context visual inputs.
For efficient adaptation, the authors employ LoRA fine-tuning, freezing the backbone parameters and inserting low-rank adapters only into feed-forward layers. The text branch remains frozen to preserve semantic alignment, enabling plug-and-play customization with minimal computational overhead.
The end-to-end variant eliminates reliance on explicit pose estimation by training directly on raw RGB frames. This is enabled through a self-bootstrapped data synthesis pipeline: the pre-trained pose-based model generates pseudo-paired data by transferring motion from a source video to a new identity. The resulting video Vo forms a pseudo-pair (Vsrc,Vo) with the source video. A dual-stage filtering process—automated scoring via Video-Bench followed by manual verification—ensures only high-quality, semantically consistent pairs are retained.
The end-to-end model is then trained to reconstruct Vsrc from (Vo,Iref), where Iref=Vsrc[0]. The training dataset is defined as:
D={(Vo,Iref,Vsrc)}The model is warm-started from the pose-based variant, inheriting robust motion priors and accelerating convergence. This end-to-end paradigm enables motion transfer directly from raw RGB sequences, forming a unified and versatile framework for character animation.
Experiment
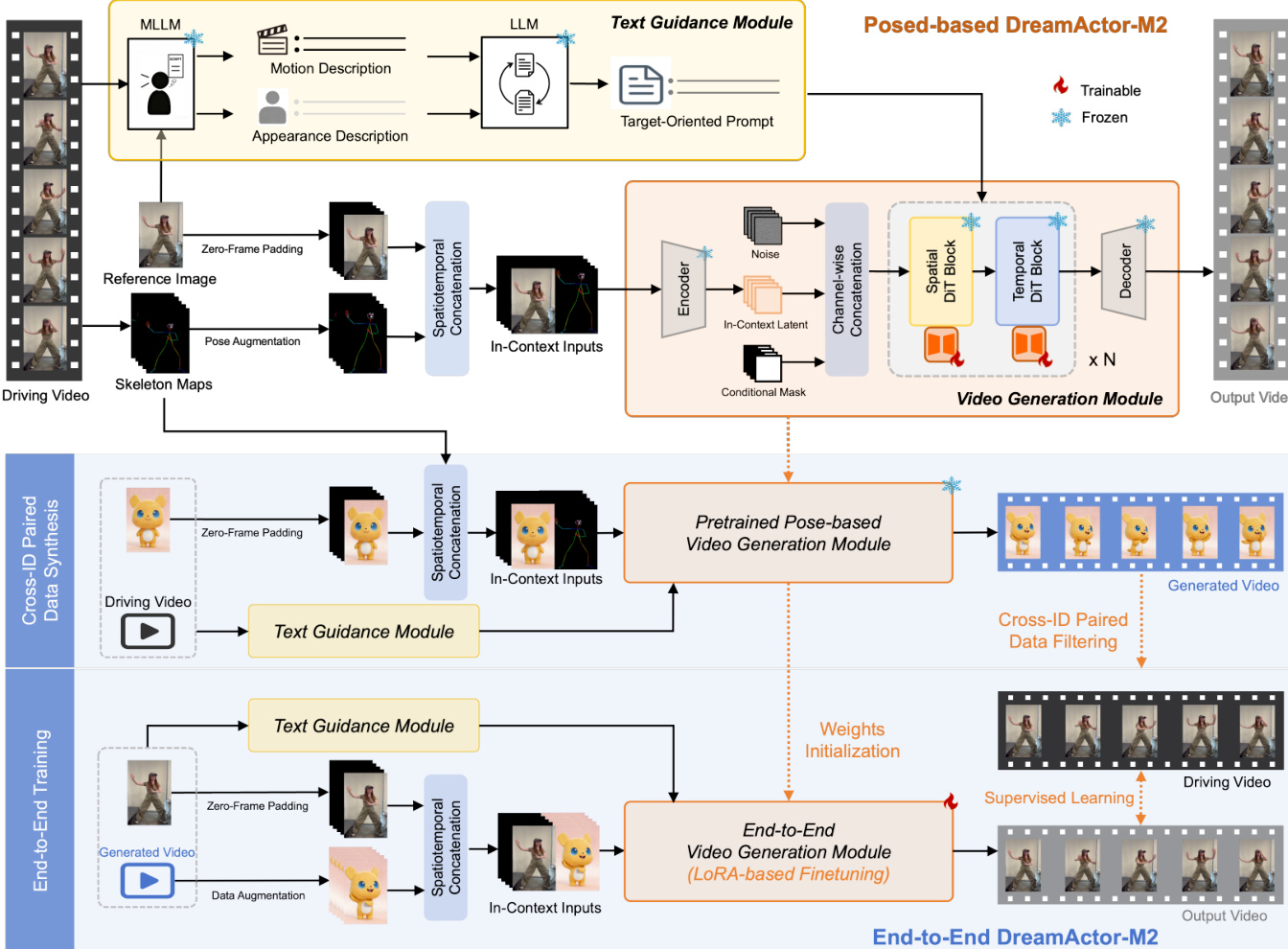
- DreamActor-M2 excels in cross-identity animation, validated through superior performance on automated and human evaluations across imaging quality, motion smoothness, temporal consistency, and appearance consistency.
- It outperforms state-of-the-art methods and industry products like Kling and Wan2.2 in subjective and objective benchmarks, demonstrating robustness in diverse scenarios including human-to-cartoon, multi-person, and non-human transfers.
- Qualitative results confirm strong identity preservation, fine-grained motion alignment, and semantic motion understanding, even in challenging cases like gesture replication and one-to-many driving.
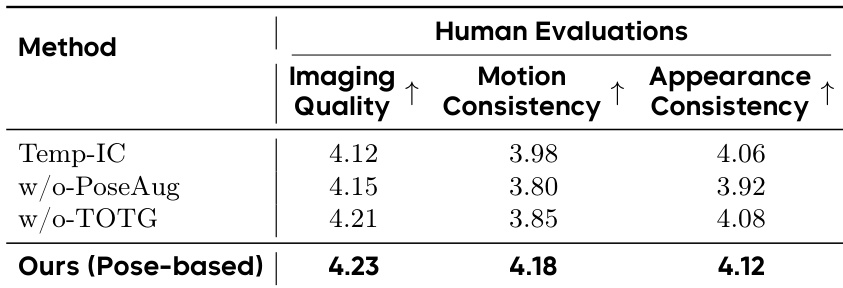
- Ablation studies confirm the necessity of spatiotemporal injection, pose augmentation, and LLM-driven text guidance for structural fidelity, motion accuracy, and identity retention.
- The model generalizes well to non-human subjects, varied shot types, and complex multi-person dynamics, though it currently struggles with intricate interactions like trajectory-crossing motions due to limited training data.
- Ethical safeguards are emphasized, including restricted model access and reliance on public data, to mitigate misuse risks associated with human image animation.
The authors evaluate ablated versions of their model against the full pose-based DreamActor-M2, showing that removing pose augmentation or target-oriented text guidance leads to lower scores across imaging quality, motion consistency, and appearance consistency. Results indicate that both pose augmentation and LLM-driven text guidance contribute meaningfully to the model’s ability to preserve structural detail and motion fidelity. The full pose-based variant achieves the highest human evaluation scores, confirming the effectiveness of the integrated design.
The authors use Video-Bench and human evaluations to assess DreamActor-M2 across diverse animation tasks, showing consistent superiority over prior methods in both automated and subjective metrics. Results show the end-to-end variant achieves the highest scores in imaging quality, motion smoothness, temporal consistency, and appearance preservation, validating its robustness in cross-identity and cross-domain scenarios. The model’s performance aligns closely with human judgment, confirming its ability to generate visually coherent and motion-consistent animations across varied character types and driving inputs.