Command Palette
Search for a command to run...
잠재적 체인-오프-Thought를 계획으로 활용하기: 추론과 언어화 분리하기
잠재적 체인-오프-Thought를 계획으로 활용하기: 추론과 언어화 분리하기
Jiecong Wang Hao Peng Chunyang Liu
초록
Chain-of-Thought(CoT)은 대규모 언어 모델(LLM)이 복잡한 문제를 해결할 수 있도록 지원하지만, 이는 이산 토큰 공간 내에서 구현될 때 계산 비용 증가 및 추론 경로 붕괴라는 한계에 직면한다. 최근의 잠재 추론(latent reasoning) 접근법들은 지속적인 숨겨진 상태 공간 내에서 추론을 수행함으로써 효율성을 개선하려는 시도를 하고 있다. 그러나 이러한 방법들은 일반적으로 명시적인 추론 단계에서 잠재 상태로의 투명하지 않은 엔드투엔드 매핑으로 작동하며, 추론 과정에서 미리 정의된 수의 잠재 단계를 필요로 하는 경우가 많다. 본 연구에서는 추론을 언어화로부터 본질적으로 분리함으로써 잠재 추론을 계획(planning)의 관점에서 재정의하는 PLaT(Planning with Latent Thoughts) 프레임워크를 제안한다. 우리는 추론을 잠재 계획 상태의 결정론적 경로로 모델링하고, 필요 시 별도의 디코더를 통해 이러한 사고를 텍스트로 구체화한다. 이 분리 구조는 고정된 하이퍼파라미터에 의존하지 않고, 추론을 종료할 시점을 모델이 동적으로 결정할 수 있도록 한다. 수학적 벤치마크에서의 실험 결과는 명확한 트레이드오프를 보여준다. PLaT는 기존의 베이스라인 대비 그리디 정확도에서는 낮은 성능을 보였지만, 추론 다양성 측면에서 우수한 확장성을 입증하였다. 이는 PLaT가 견고하고 보다 넓은 해결 공간을 학습하고 있음을 시사하며, 추론 시점 검색(inference-time search)을 위한 투명하고 확장 가능한 기반을 제공함을 의미한다.
One-sentence Summary
Jiecong Wang and Hao Peng from Beihang University, with Chunyang Liu from Didi Chuxing, propose PLaT, a latent planning framework that decouples reasoning from verbalization to enable dynamic, scalable inference, outperforming baselines in reasoning diversity while maintaining transparency for complex problem solving.
Key Contributions
- PLaT redefines latent reasoning as a planning process in continuous space, decoupling internal thought trajectories from verbal output to avoid discrete token collapse and enable dynamic termination without fixed step counts.
- The framework introduces a Planner-Decoder architecture where latent states evolve deterministically and are only verbalized on demand, offering interpretable intermediate reasoning and flexible inference control.
- On mathematical benchmarks, PLaT trades lower greedy accuracy for significantly better Pass@k scaling and reasoning diversity, indicating a broader, more robust solution space suitable for search-based inference.
Introduction
The authors leverage latent space reasoning to address the inefficiency and path collapse of traditional Chain-of-Thought (CoT) methods, which force models to commit to discrete tokens early, pruning alternative solutions and incurring high computational cost. Prior latent approaches improve efficiency but treat reasoning as a black box and fix the number of reasoning steps, limiting adaptability. The authors’ main contribution is PLaT, a Planner-Decoder framework that decouples continuous latent planning from verbalization, enabling dynamic termination and interpretable intermediate states. Empirically, PLaT trades off greedy accuracy for superior reasoning diversity, scaling better under search-based inference and learning broader solution manifolds.
Dataset

- The authors use GSM8k-Aug for training, an augmented version of GSM8k where reasoning chains are reformatted as GPT-4-generated equations, structured as Question → Step1 → Step2 → ⋯ Answer to support latent step segmentation.
- For evaluation, they test on three out-of-distribution benchmarks: GSM-HARD, SVAMP, and MultiArith, to assess generalization and robustness.
- The model backbone is GPT-2 (small), chosen to ensure fair comparison with recent latent reasoning baselines using the same architecture.
- Training initializes from a CoT-SFT checkpoint, fine-tunes for 25 epochs with learning rate 5e-4, and uses latent dimension ds = 2048.
- The Planner shares backbone parameters but adds two transformer layers for enhanced planning capacity; the Decoder shares the same backbone.
- No cropping or metadata construction is mentioned; processing focuses on equation-style chain formatting and latent state training.
- The model is evaluated using Greedy Accuracy (exploitation) and Pass@k (k=32,64,128) to measure exploration and reasoning diversity in the latent space.
Method
The authors leverage a novel framework called PLaT (Planning with Latent Trajectories) to model reasoning as a latent autoregressive process, decoupling the generation of intermediate reasoning steps from their verbalization. This architecture introduces continuous latent variables to represent each reasoning step, enabling a more flexible and stable exploration of reasoning paths compared to discrete token-based autoregressive models.
The core of PLaT consists of two primary modules: the Planner and the Decoder, which interact via linear projectors that bridge the latent space and the LLM backbone dimension. The Planner operates in a continuous latent manifold, evolving a sequence of latent states for each reasoning step without committing to specific tokens prematurely. It begins by encoding the input question into an initial latent state using a dedicated encoder projector. Subsequent states are generated autoregressively: the latent history is projected into the model’s hidden dimension, concatenated with a delimiter token, and fed into the backbone LLM to predict the next hidden state, which is then mapped back to the latent space. Crucially, the Planner produces deterministic latent vectors, ensuring stability during training and inference.
As shown in the figure below, the Decoder synthesizes textual output from the Planner’s latent trajectory. It employs an Exponential Moving Average (EMA) mechanism to stabilize the latent states across steps, maintaining independent aggregators for each latent slot. These aggregators accumulate information from corresponding slots in previous steps, forming a final aggregated state for each reasoning step. The Decoder then projects this state into the token space and generates the corresponding text segment, conditioning strictly on the current aggregated state to enforce semantic completeness.
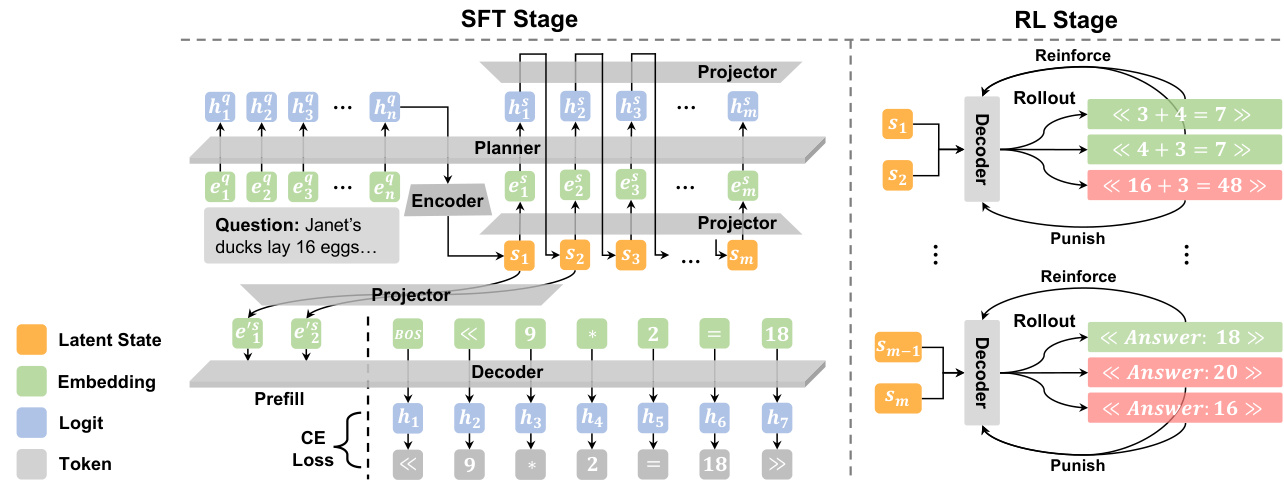
Training proceeds in two phases. During Supervised Fine-Tuning (SFT), the entire pipeline is optimized end-to-end using a reconstruction loss that minimizes the cross-entropy between ground-truth reasoning steps and the Decoder’s predictions. To encourage robustness and prevent overfitting to point-wise mappings, Gaussian noise is injected into the accumulated latent states during training. This phase treats all reasoning steps uniformly within the latent space, eliminating the need for mode-switching or fixed step counts.
For policy refinement, the authors employ Reinforcement Learning (RL) while freezing the Planner parameters to preserve the learned latent manifold. Exploration is induced solely in the Decoder via temperature sampling, allowing multiple verbalization paths to be generated from the same deterministic latent state. A Group Relative Policy Optimization (GRPO) objective is used to maximize the likelihood of correct and valid outputs, with advantages computed relative to rewards within each group of sampled trajectories. This decoupled approach ensures that the reasoning topology remains stable while optimizing the verbalization policy.
Inference is made efficient through a strategy called Lazy Decoding. Since the Planner operates in the latent space, the model can generate the full reasoning trajectory without producing intermediate text. To determine whether to continue reasoning or output the final answer, the model performs a semantic probe by decoding only the first token of each step. If this token is not the answer delimiter, the model discards it and proceeds; if it is, the model fully decodes the final answer from the current latent state. This significantly reduces computational cost while preserving interpretability.
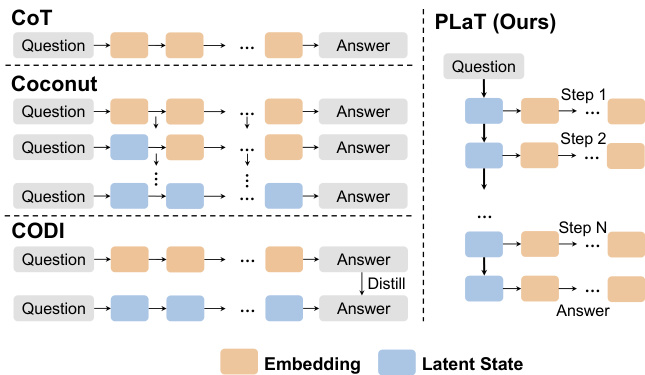
Refer to the framework diagram for a high-level comparison of PLaT with prior methods such as CoT, Coconut, and CODI. PLaT’s architecture explicitly separates latent planning from textual decoding, enabling both efficient inference and stable policy refinement through decoupled optimization.
Experiment
- PLaT demonstrates superior diversity in reasoning paths (Pass@128), outperforming Coconut and CODI across multiple datasets, indicating its latent space enables efficient sampling of varied solutions while baselines saturate.
- Increasing latent states (N_L=2) improves diversity and in-domain accuracy but may hurt out-of-domain performance, suggesting a trade-off between capacity and generalization.
- Reinforcement learning boosts greedy accuracy on in-domain tasks but reduces diversity and harms OOD performance, revealing overfitting to domain-specific rewards and highlighting the need for multi-task reward design.
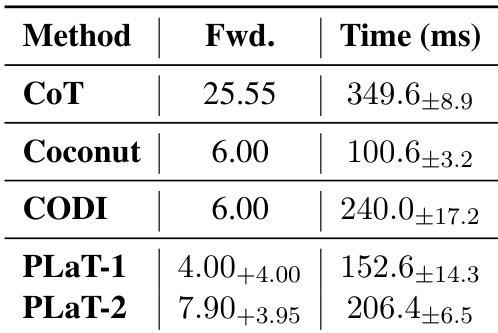
- PLaT offers significant inference speedups over explicit CoT (56% faster) while maintaining interpretability, striking a balance between efficiency, transparency, and high-diversity reasoning.
- Latent states in PLaT are interpretable and support active exploration, maintaining higher branching factors and preserving valid reasoning paths longer than CoT, making it well-suited for search-based inference methods.
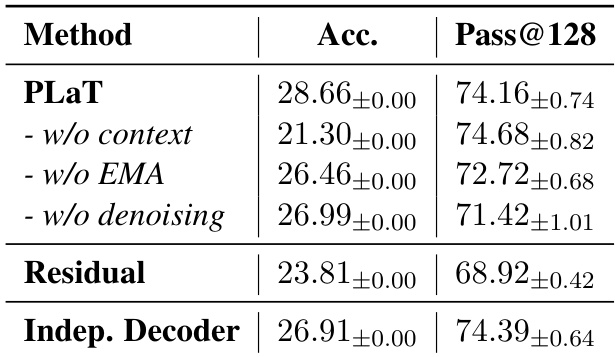
- Ablation studies confirm the importance of context injection, EMA aggregation, and denoising for stable performance; parameter sharing improves regularization, while removing context increases diversity at the cost of precision.
- Hyperparameter analysis shows N_L=2, α_EMA=0.5, and d_s=2048 yield optimal performance; longer latent chains or higher dimensions degrade results due to optimization challenges.
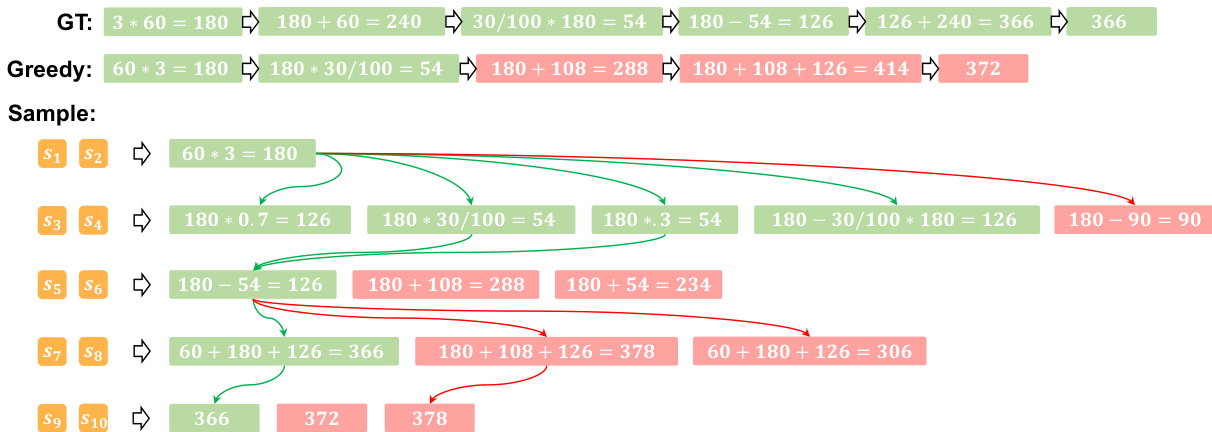
- Case studies confirm PLaT encodes multiple reasoning strategies in latent states, allowing correct paths to coexist even when greedy decoding fails, supporting its role as a diverse reasoning generator.
The authors use ablation studies to evaluate key architectural components of PLaT, finding that removing context injection causes the largest drop in greedy accuracy, while omitting EMA or denoising degrades both accuracy and diversity. Results show that the Residual variant performs worst overall, and an Independent Decoder achieves competitive diversity but lower precision, suggesting parameter sharing helps regularize the latent space.
The authors use GPT-4o-mini to automatically evaluate reasoning step validity and validate its reliability through human annotation, achieving 95.0% accuracy and near-perfect agreement (Cohen’s Kappa = 0.8721). Results show the automated evaluator is slightly lenient but consistent, never rejecting valid steps, which supports fair comparative analysis between methods.
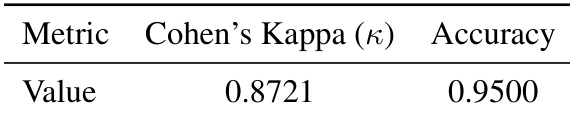
The authors use PLaT to compress reasoning into latent states, achieving a 56% reduction in inference latency compared to explicit CoT while maintaining higher diversity in sampled solutions. Although PLaT incurs moderate overhead over Coconut and CODI due to decoder checks, it offers interpretable intermediate states and supports efficient exploration of reasoning paths. Results show that PLaT strikes a favorable balance between speed, diversity, and transparency, making it suitable for search-based inference methods.