Command Palette
Search for a command to run...
DeepPlanning: 검증 가능한 제약 조건을 갖춘 장기 계획 태스크에 대한 벤치마킹
DeepPlanning: 검증 가능한 제약 조건을 갖춘 장기 계획 태스크에 대한 벤치마킹
Yinger Zhang Shutong Jiang Renhao Li Jianhong Tu Yang Su Lianghao Deng Xudong Guo Chenxu Lv Junyang Lin
초록
에이전트 평가가 장기적 시점의 과제로 이동하고 있는 가운데, 대부분의 벤치마크는 여전히 국소적이고 단계별 추론에 초점을 맞추고 있으며, 진정한 계획 능력을 요구하는 전반적인 제약 최적화(예: 시간 및 재정 예산)를 충분히 반영하지 못하고 있다. 한편, 기존의 대규모 언어 모델(LLM) 계획 벤치마크는 현실 세계에서 흔히 나타나는 능동적인 정보 수집 및 세부적인 국소적 제약 조건을 충분히 반영하지 못하고 있다. 이를 해결하기 위해 우리는 실용적인 장기적 시점 에이전트 계획을 위한 도전적인 벤치마크인 DeepPlanning을 제안한다. DeepPlanning은 사전 정보 획득, 국소적 제약 조건을 고려한 추론, 전반적인 제약 조건 하에서의 최적화를 요구하는 다일간 여행 계획 및 다제품 쇼핑과 같은 과제를 포함한다. DeepPlanning에 대한 평가 결과, 최첨단 에이전트형 LLM조차도 이러한 문제에 어려움을 겪는 것으로 나타나, 더 나은 효과성-효율성 균형을 달성하기 위해 신뢰할 수 있는 명시적 추론 패턴과 병렬 도구 사용의 중요성을 시사한다. 오류 분석을 통해 장기적 계획 과제에서 에이전트형 LLM의 성능 향상을 위한 전망 있는 방향성도 도출되었다. 본 연구는 코드와 데이터를 오픈소스로 공개하여 향후 연구를 지원한다.
One-sentence Summary
The Qwen Team at Alibaba Group introduces DEEPPLANNING, a benchmark for evaluating LLMs on real-world long-horizon planning tasks requiring proactive information gathering and global constraint optimization, revealing current models’ limitations and highlighting the need for explicit reasoning and parallel tool use.
Key Contributions
- We introduce DEEPPLANNING, a new benchmark featuring multi-day travel and multi-product shopping tasks that require proactive information gathering, local constraint handling, and global optimization under time and budget limits, addressing gaps in existing LLM agent evaluations.
- Evaluations on frontier agentic LLMs reveal consistent struggles with long-horizon planning, demonstrating that explicit reasoning patterns and parallel tool use are critical for improving effectiveness-efficiency trade-offs in complex, constrained scenarios.
- Through error analysis, we identify key failure modes—such as missed tool calls, undetected implicit constraints, and lack of global consistency checking—and outline actionable directions to enhance agentic LLMs for extended planning tasks.
Introduction
The authors leverage real-world multi-day travel and multi-product shopping scenarios to evaluate LLM agents’ long-horizon planning abilities, where global constraints like time budgets and cumulative costs must be optimized across interdependent steps. Prior benchmarks often focus on local, step-level reasoning or oversimplified global constraints, failing to capture the need for proactive information gathering and fine-grained constraint handling typical in practical settings. Their main contribution is DEEPPLANNING, a new benchmark that enforces verifiable, multi-level constraints and exposes critical gaps in current agents — particularly their inability to reliably backtrack, maintain global consistency, or use tools in parallel — while highlighting explicit reasoning and tool orchestration as key to improving effectiveness and efficiency.
Dataset
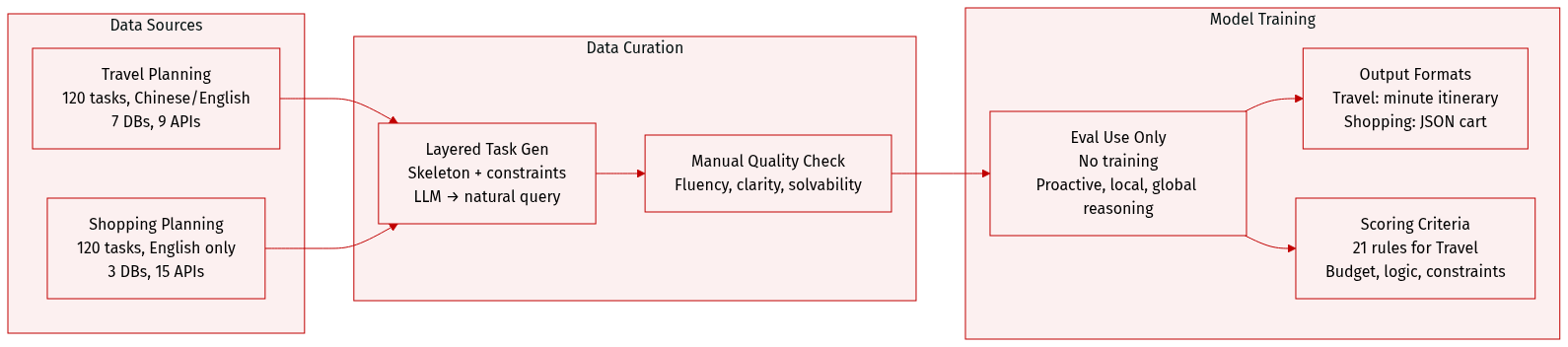
The authors use DeepPlanning, a benchmark composed of two complex, real-world planning domains: Travel Planning and Shopping Planning. Each task runs in an isolated sandbox backed by domain-specific databases and accessed via custom Python toolkits, ensuring reproducibility.
-
Dataset Composition and Sources:
- Travel Planning: 120 tasks (available in Chinese and English), sourced from real-world data via public APIs (Fliggy, Amap, Web Search) covering transportation, hotels, attractions, and dining in Chinese tourist cities.
- Shopping Planning: 120 English-only tasks, built from synthesized product data including price, stock, ratings, and promotions, designed for controlled complexity.
-
Key Subset Details:
- Travel Planning: Uses 7 sub-databases and 9 APIs (e.g., query_hotel_info). Tasks require multi-day itineraries with minute-level scheduling, itemized costs, and budget summaries. Constraints involve time, location, and budget coupling.
- Shopping Planning: Uses 3 sub-databases and 15 APIs (e.g., search_products). Tasks require assembling a JSON shopping cart that satisfies user preferences, sizing, shipping, coupons, and budget. Challenges involve combinatorial optimization across the cart.
-
Data Construction Pipeline:
- Database & Toolbox Design: Domain-specific databases and hierarchical APIs are built to encourage multi-step agent interaction.
- Layered Task Generation: Tasks are reverse-engineered from solutions:
- Base skeletons (e.g., travel route or product theme) are generated.
- Personalized constraints (e.g., “book flight after 7 AM”) and environmental constraints (e.g., closed attractions or coupon stacking) are injected.
- Database entries are adjusted to ensure exactly one optimal solution exists.
- LLMs convert constraints into natural language queries.
- Manual Quality Control: Human experts validate fluency, clarity, and solvability of each task.
-
Processing and Use in Model:
- Tasks are evaluated based on three core agent capabilities: proactive information acquisition, local constrained reasoning, and global constrained optimization.
- Output formats are strictly structured: Travel Planning returns minute-level itineraries with cost breakdowns; Shopping Planning returns JSON carts with item details and coupon usage.
- Evaluation uses 21 scoring criteria for commonsense reasoning in Travel Planning, covering logical consistency, constraint satisfaction, and budget accuracy.
- No cropping is applied; all tasks are full-scope, end-to-end planning challenges. Metadata is embedded in tool schemas and database fields (Tables 3–6), which define API parameters and data structure.
The authors do not train on this dataset; it serves as an evaluation benchmark for agent planning performance under real-world constraints.
Method
The authors leverage a layered task generation framework to decompose complex user queries into structured planning workflows for both travel and shopping domains. The architecture is organized into three sequential stages: Base Skeleton Generation, Personalized Constraint Injection, and Environment Constraint Injection. Each stage progressively refines the plan by integrating user preferences, domain-specific rules, and real-time environmental data.
In the travel planning module, the system begins by parsing the user’s high-level request—such as destination, dates, and budget—and generates an initial itinerary skeleton. This is followed by injecting personalized constraints, such as hotel star ratings or dining preferences, which are mapped to specific tool calls like query_hotel_info or recommend_around_restaurants. The final stage incorporates environmental constraints, such as flight availability or attraction opening hours, retrieved from external databases. The agent trajectory shown in the diagram illustrates how tool invocations are chained to populate the plan, ensuring all entities—flights, hotels, attractions—are sourced exclusively from tool outputs without fabrication.

For shopping planning, the framework similarly initiates with a base skeleton derived from product categories and budget. Personalized constraints—such as brand, size, or rating thresholds—are then injected, triggering targeted product searches via tools like search_products. The environment constraint phase integrates user profile data, such as available coupons, and evaluates combinations against pricing logic. The system enforces strict coupon application rules: cross-store coupons apply to the entire cart total, while same-brand coupons are scoped to individual brand subtotals. Stacking is permitted only if each coupon’s threshold is met post-discount, and the final selection is the combination yielding the absolute minimum price within budget.
The evaluation module in both domains assesses plan quality against predefined metrics. In travel, it checks for commonsense compliance, cost accuracy, and itinerary structure; in shopping, it validates product match accuracy against ground truth. The system mandates that all final decisions be based on the cart’s state, verified via getCart_info, ensuring that coupon usage and item selection are consistent with the final transactional context. All outputs are strictly derived from tool results, with no creative interpretation or data fabrication permitted.
Experiment
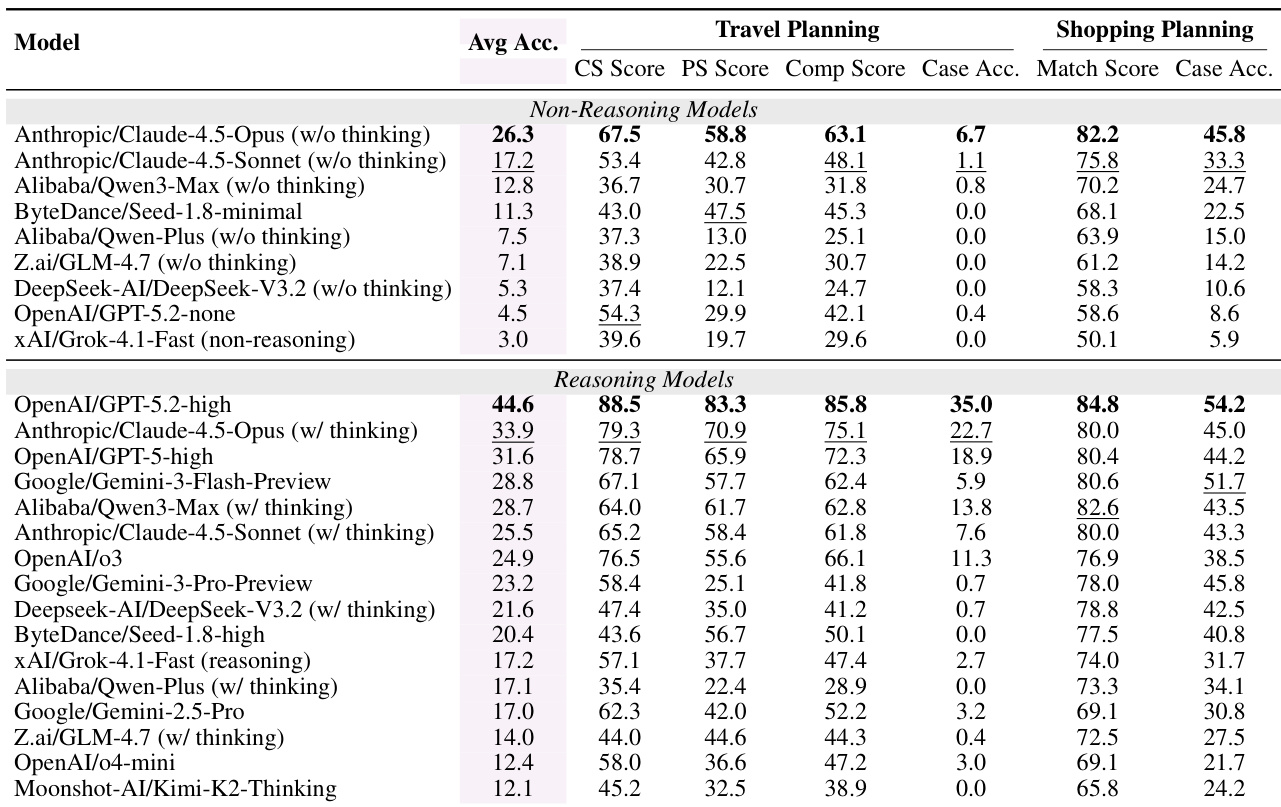
- DeepPlanning evaluates LLM agents on complex, real-world planning tasks in travel and shopping domains using code-based, rule-driven metrics to ensure objectivity.
- Agents show fragility in end-to-end execution: high constraint-level scores often mask critical global failures, leading to low case-level accuracy even in top models.
- Internal reasoning significantly improves performance and efficiency, reducing redundant tool use and enabling better cost-performance trade-offs.
- Performance declines with task complexity—longer itineraries or multi-constraint shopping tasks expose agents’ difficulty with global optimization and constraint propagation.
- Error analysis reveals three dominant failure modes: insufficient or misused information retrieval, local constraint violations, and systemic breakdowns in integrating interdependent decisions.
- Tool usage correlates with performance: more calls improve outcomes, but reasoning models achieve higher scores with fewer interactions, indicating smarter planning.
- Domain specialization is evident—some models excel in one domain (e.g., Gemini in shopping) but underperform in another, highlighting task-specific strengths.
- Current benchmarks are limited to travel and shopping; synthesized queries may not reflect real user behavior, and multi-turn interactions remain unexplored.
The authors use a code-based evaluation framework to assess LLM agents on complex travel and shopping planning tasks, revealing that even top models struggle with end-to-end coherence despite high component-level scores. Results show that models with internal reasoning capabilities consistently outperform non-reasoning counterparts, particularly in maintaining global plan integrity under multi-constraint conditions. Performance gains from reasoning come with trade-offs in interaction cost, as more deliberate planning reduces redundant tool use but may increase turn count or require more structured execution.