Command Palette
Search for a command to run...
LLM이 당신의 혼란을 정리해줄 수 있을까? LLM을 활용한 응용 준비 완료 데이터 준비에 대한 종합적 조사
LLM이 당신의 혼란을 정리해줄 수 있을까? LLM을 활용한 응용 준비 완료 데이터 준비에 대한 종합적 조사
초록
데이터 준비는 원시 데이터셋의 노이즈를 제거하고, 데이터셋 간 상관관계를 탐색하며, 유용한 통찰을 추출하는 것을 목표로 하며, 데이터 중심 응용 분야 전반에 있어 필수적인 과정이다. 이 과정은 (i) 분석, 시각화, 의사결정 등 응용 준비형 데이터에 대한 수요 증가, (ii) 점점 강력해지는 대규모 언어 모델(LLM) 기술의 발전, 그리고 (iii) 유연한 에이전트 구축을 가능하게 하는 인프라의 등장(예: Databricks Unity Catalog 활용)에 힘입어, LLM 기반 기법이 데이터 준비 분야에서 급속히 변혁적이고 잠재적으로 주도적인 패러다임으로 부상하고 있다. 본 논문은 최근 수백 건의 학술 연구를 체계적으로 조사하여, 다양한 후속 작업을 위한 데이터 준비에 LLM 기술을 활용하는 이 변화하는 생태계에 대한 포괄적인 종합적 리뷰를 제시한다. 먼저, 규칙 기반의 모델 특화 파이프라인에서부터 프롬프트 기반, 맥락 인식형, 에이전트 기반의 준비 워크플로우로의 근본적인 패러다임 전환을 설명한다. 다음으로, 작업 중심의 분류 체계를 제안하여 이 분야를 세 가지 주요 작업으로 체계화한다: 데이터 정제(예: 표준화, 오류 처리, 누락치 보정), 데이터 통합(예: 엔티티 매칭, 스키마 매칭), 데이터 풍부화(예: 데이터 주석화, 프로파일링). 각 작업에 대해 대표적인 기법들을 조사하고, 각각의 강점(예: 일반화 능력 향상, 의미적 이해 능력 향상)과 한계(예: LLM 확장 시 막대한 비용, 고도화된 에이전트에서도 지속되는 환각 현상, 고도화된 방법과 약한 평가 체계 간의 불일치)를 강조한다. 또한, 일반적으로 사용되는 데이터셋과 평가 지표(실증적 분석 부분)를 분석한다. 마지막으로, 아직 해결되지 않은 연구 과제들을 논의하고, 확장 가능한 LLM-데이터 시스템, 신뢰할 수 있는 에이전트 워크플로우를 위한 체계적인 설계, 그리고 강건한 평가 프로토콜을 강조하는 전망적인 로드맵을 제시한다.
One-sentence Summary
Wei Zhou et al. survey LLM-enhanced data preparation, proposing a task-centric taxonomy for cleaning, integration, and enrichment that shifts from rule-based to agentic, context-aware workflows, highlighting innovations like retrieval-augmented generation and hybrid LLM-ML systems while addressing scalability, hallucination, and evaluation gaps across enterprise analytics and ML pipelines.
Key Contributions
- LLMs enable a paradigm shift from manual, rule-based data preparation to instruction-driven, agentic workflows that reduce human effort by allowing natural language prompts and automated pipeline orchestration for tasks like cleaning and integration.
- The paper introduces a task-centric taxonomy covering data cleaning, integration, and enrichment, highlighting how LLMs improve semantic reasoning—resolving ambiguities like synonyms or domain terms—where traditional methods fail due to syntactic or statistical limitations.
- Through analysis of recent literature and empirical benchmarks, the survey identifies key challenges including LLM hallucinations, scalability costs, and weak evaluation protocols, while calling for scalable systems, reliable agent designs, and robust evaluation frameworks.
Introduction
The authors leverage large language models to address the growing need for application-ready data in analytics, decision-making, and real-time systems. Traditional data preparation methods suffer from heavy reliance on manual rules, limited semantic understanding, poor generalization across domains, and high labeling costs — all of which hinder scalability and adaptability. In response, the authors present a comprehensive survey that organizes LLM-enhanced techniques around three core tasks: cleaning, integration, and enrichment. They introduce a task-centric taxonomy, highlight how LLMs enable prompt-driven and agentic workflows, and identify key limitations including hallucinations, high inference costs, and weak evaluation protocols — while outlining a roadmap toward scalable, reliable, and cross-modal data preparation systems.
Dataset

The authors use a structured dataset taxonomy to evaluate LLM-enhanced data preparation methods, grouping benchmarks by processing granularity: record-level, schema-level, and object-level.
-
Record-Level Datasets: Focus on individual tuples, cells, or tuple pairs. Used for cleaning, error detection, imputation, and entity matching. Examples include:
- Tuple-level: Adult Income, Hospital, Beers, Flights, Enron Emails
- Column-level: Paycheck Protection Program, Chicago Food Inspection
- Cell-level: Buy, Restaurant, Walmart
- Tuple-pair: abt-buy, Amazon–Google, Walmart–Amazon, DBLP–Scholar, DBLP–ACM, WDC Products
-
Schema-Level Datasets: Align columns or attributes across heterogeneous schemas. Used for schema matching in domains like healthcare and biomedicine. Examples:
- OMOP, Synthea, MIMIC (clinical)
- GDC-SM, ChEMBL-SM (scientific/biomedical)
-
Object-Level Datasets: Treat entire tables or documents as units. Used for profiling and annotation requiring global context. Examples:
- Table-level: Public BI, Adventure Works, ChEMBL-DP, Chicago Open Data, NQ-Tables, FetaQA
- Document-level: AG-News, DBpedia, CoNLL-2003, WNUT-17
The authors do not train models on these datasets directly but use them to benchmark LLM-enhanced methods across cleaning, integration, and enrichment tasks. No specific cropping or metadata construction is described beyond the datasets’ inherent structure and evaluation metrics. Processing involves applying LLMs to standardize formats, detect and repair errors, impute missing values, match entities and schemas, annotate semantics, and profile metadata — all aimed at improving downstream analytical and ML tasks.
Method
The authors present a comprehensive framework for leveraging large language models (LLMs) in data preparation, structured around three core domains: data cleaning, data integration, and data enrichment. The overall architecture, as illustrated in the framework diagram, positions these domains as foundational processes that transform heterogeneous and raw data into structured, trustworthy, and enriched forms suitable for downstream applications such as visual analytics, enterprise business intelligence, model training, fraud monitoring, and data marketplaces. The framework highlights that data cleaning addresses issues like inconsistent standards, errors, and incompleteness, while data integration resolves semantic ambiguities and schema conflicts, and data enrichment enhances datasets with metadata and annotations. These processes are interconnected, with outputs from one domain often serving as inputs to another, forming a cohesive pipeline for data preparation.
The data cleaning module, as shown in the framework diagram, encompasses three primary tasks: data standardization, error processing, and imputation. For data standardization, the authors describe a prompt-based end-to-end approach where structured prompts guide the LLM to transform heterogeneous data into a unified format. This includes instruction-guided prompting, which uses manually crafted instructions and in-context examples, and reasoning-enhanced batch processing, which employs step-wise reasoning and batch-wise prompting to improve robustness and efficiency. An alternative paradigm is tool-assisted agent-based standardization, where LLM agents coordinate and execute standardization pipelines by generating and executing API calls or code, as depicted in the example of CleanAgent. For data error processing, the framework outlines a two-stage process of detection and correction. This is achieved through prompt-based end-to-end processing, which uses structured prompts to guide the LLM through iterative workflows, and task-adaptive fine-tuning, where LLMs are fine-tuned on synthetic or context-enriched datasets to learn specific error patterns. A hybrid approach integrates LLMs with machine learning models, using the LLM to generate pseudo-labels for training a lightweight ML classifier or to derive interpretable decision structures that guide ML-based error detection.
The data integration module focuses on entity and schema matching. For entity matching, the framework describes a prompt-based end-to-end approach that uses structured prompts to guide LLMs in determining if two records refer to the same real-world entity. This includes guidance-driven in-context matching, which uses expert-defined rules and multi-step pipelines, and batch-clustering matching, which processes multiple entity pairs simultaneously to enhance efficiency. Task-adaptive-tuned matching involves fine-tuning LLMs using reasoning traces distilled from larger models or by improving training data quality. A multi-model collaborative approach coordinates multiple models, such as a lightweight ranker and a stronger LLM, to achieve scalable and consistent matching. For schema matching, the framework presents a prompt-based end-to-end method that uses structured prompts to identify correspondences between column names across different schemas. This is enhanced by retrieval-enriched contextual matching, which augments LLM inputs with context from external retrieval components like knowledge graphs, and model-optimized adaptive matching, which uses modality-aware fine-tuning and specialized architectural components like table encoders. An agent-guided orchestration approach uses LLM agents to manage and coordinate the entire schema matching pipeline, either through role-based task partitioning or tool-planning mechanisms.
The data enrichment module addresses data annotation and profiling. For data annotation, the framework describes a prompt-based end-to-end approach that uses structured prompts to guide LLMs in assigning semantic or structural labels to data instances. This includes instruction-guided annotation and reasoning-enhanced iterative annotation, which uses step-by-step reasoning and self-assessment. A retrieval-assisted contextual annotation approach enriches prompts by retrieving relevant context from semantically similar examples or external knowledge graphs. Fine-tuned augmented annotation improves performance in specialized domains by fine-tuning LLMs on task-specific datasets. A hybrid LLM-ML annotation approach combines LLMs with machine learning models, using the LLM to generate candidate annotations that are then distilled and filtered by a smaller model. Tool-assisted agent-based annotation uses LLM agents augmented with specialized tools to handle complex annotation tasks. For data profiling, the framework outlines a prompt-based end-to-end approach that uses carefully designed prompts to guide LLMs in generating dataset descriptions, schema summaries, and hierarchical organization. This includes instruction and constraint-based profiling and example and reasoning-enhanced profiling, which combines few-shot examples with Chain-of-Thought reasoning. A retrieval-assisted contextual profiling approach combines multiple retrieval techniques with LLM reasoning to improve profiling accuracy, especially when metadata is sparse.
Experiment
- Evaluated data preparation methods across four dimensions: correctness, robustness, ranking quality, and semantic consistency.
- Correctness metrics include Accuracy, Precision, F1-score (for reliability), and Recall, Matching Rate (for coverage), validated on tasks like entity matching and error detection.
- Robustness assessed via ROC and AUC, measuring consistent performance across varying data distributions in error processing tasks.
- Ranking quality measured by P@k and MRR for retrieval utility, and Recall@GT, 1−α, Hit Rate for enrichment completeness in annotation and matching tasks.
- Semantic preservation evaluated using ROUGE (lexical overlap) and Cosine Similarity (embedding alignment), ensuring output consistency with reference content in standardization and profiling tasks.
The authors use a comprehensive evaluation framework to assess data preparation methods across multiple dimensions, including correctness, robustness, ranking quality, and semantic consistency, with metrics such as precision, recall, and F1-score for correctness, ROC and AUC for robustness, P@k and MRR for ranking quality, and ROUGE and cosine similarity for semantic preservation. Results show that while many methods achieve high performance in specific areas like correctness or ranking quality, there is no single approach that consistently outperforms others across all dimensions, highlighting the trade-offs between different evaluation criteria.
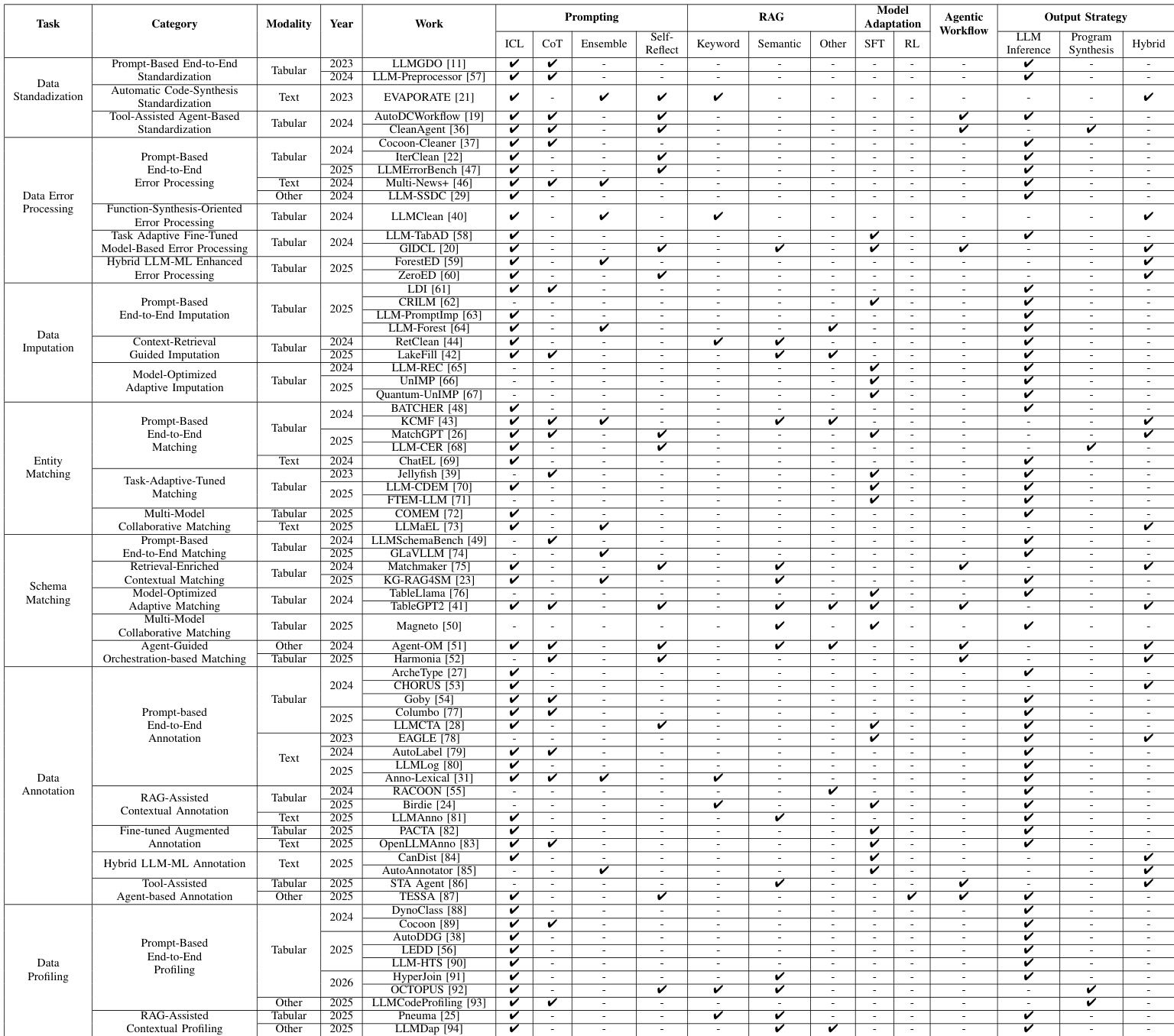
The authors use a diverse set of datasets across data cleaning, integration, and enrichment tasks to evaluate preparation methods, with metrics selected based on correctness, robustness, ranking quality, and semantic consistency. Results show that evaluation metrics vary significantly by task and data type, with precision, recall, and F1-score being most common, while specialized metrics like ROC-AUC, MRR, and ROUGE-1 are used for specific scenarios such as error detection and text-based enrichment.