Command Palette
Search for a command to run...
월드 크래프트: 텍스트를 통한 시각화 가능한 세계를 생성하는 에이전트 기반 프레임워크
월드 크래프트: 텍스트를 통한 시각화 가능한 세계를 생성하는 에이전트 기반 프레임워크
초록
대규모 언어 모델(Large Language Models, LLMs)은 AI 타운과 같은 생성형 에이전트 시뮬레이션을 촉진하여 '동적 세계(dynamic world)'를 구축함으로써 엔터테인먼트 및 연구 분야에서 막대한 가치를 지닌다. 그러나 프로그래밍 능력이 없는 비전문가들에게는 직접 시각화 가능한 환경을 커스터마이징하는 것이 쉽지 않다. 본 논문에서는 사용자의 텍스트 기반 설명을 통해 실행 가능하고 시각화 가능한 AI 타운을 생성할 수 있는 에이전트 기반 세계 창조 프레임워크인 World Craft를 소개한다. 이 프레임워크는 두 가지 주요 모듈인 World Scaffold와 World Guild로 구성된다. World Scaffold는 상호작용 가능한 게임 장면을 개발하기 위한 구조적이고 간결한 표준화 체계로, LLM이 실행 가능한 AI 타운 유사 환경을 효과적으로 커스터마이징할 수 있도록 지원하는 효율적인 기반 구조를 제공한다. World Guild는 사용자의 모호한 설명에서 의도를 점진적으로 분석하고, World Scaffold에 필요한 구조적 콘텐츠(예: 환경 배치 및 자산 등)를 합성하는 다중 에이전트 프레임워크이다. 또한, 공간 지식을 강화하고 배치 생성의 안정성 및 통제력을 향상시키기 위해 역설계(reverse engineering)를 통해 고품질의 오류 수정 데이터셋을 구축하였으며, 다양한 차원의 평가 지표를 제시하여 추가 분석을 가능하게 했다. 광범위한 실험을 통해 본 프레임워크가 기존 상용 코드 에이전트(Cursor, Antigravity) 및 LLM(Qwen3, Gemini-3-Pro)보다 장면 구축 및 내러티브 의도 전달 측면에서 크게 우수함을 입증하였으며, 환경 생성의 민주화를 위한 확장 가능한 솔루션을 제공한다.
One-sentence Summary
Researchers from Shanda AI Research, Shanghai Innovation Institute, Nankai University, and Fudan University propose World Craft, a novel framework enabling non-experts to generate executable, visual AI towns from text via structured scaffolding and intent-driven multi-agent synthesis, outperforming leading LLMs and code agents in controllability and narrative fidelity.
Key Contributions
- World Craft introduces a two-module framework (World Scaffold and World Guild) that enables non-experts to generate executable, visualizable AI Town environments directly from natural language, bypassing the need for programming skills and fragmented game engine toolchains.
- World Guild employs multi-agent reasoning to bridge the semantic gap between vague user descriptions and precise spatial layouts, while World Scaffold provides a standardized interface for LLMs to construct interactive scenes, supported by a curated asset library to ensure physical and visual consistency.
- The framework leverages a reverse-engineered error-correction dataset to enhance LLM spatial reasoning and is evaluated using multi-dimensional metrics, demonstrating superior performance over commercial code agents and leading LLMs in both scene construction and narrative intent fidelity.
Introduction
The authors leverage large language models to democratize the creation of interactive, visualizable AI Towns—simulated environments valuable for entertainment and social research—by letting non-programmers describe scenes in plain text. Prior tools rely on fragmented game engines and preset maps, demanding coding skills that exclude casual users, while general LLMs struggle with spatial reasoning, often producing physically impossible layouts. Their main contribution is World Craft, a two-part framework: World Scaffold standardizes scene construction for LLMs, and World Guild uses multi-agent reasoning to translate vague text into precise layouts, enhanced by a novel “reverse synthesis” dataset that teaches spatial correction. Together, they enable scalable, accurate environment generation from natural language, outperforming commercial code agents and leading LLMs in layout fidelity and intent alignment.
Dataset

The authors use a custom-built dataset designed to teach LLMs spatial reasoning and layout correction under physical constraints. Here’s how it’s structured and used:
-
Dataset sources span four domains: real-world, literature, film/TV, and TRPG games. Each domain contributes 125 seed scenarios, split 4:1 into training and held-out test sets to prevent leakage.
-
The training set is expanded via style augmentation: 560 style prompts (e.g., “Cyberpunk”, “Primitive”) are randomly injected into each scenario, generating 2,000 diverse training samples to improve cross-domain spatial logic.
-
Golden layouts (G_gold) are constructed using a multi-stage pipeline: procedural room generation, LLM-assigned functional attributes, and collision-free placement guided by a 12-zone grid. A Teacher Model and human experts refine long-tail cases to ensure physical and logical correctness.
-
From G_gold, the authors generate two core datasets:
- Dataset A: Maps from semantic descriptions (Z) to G_gold, plus error-correction trajectories (G_error → G_gold via correction instructions C). This trains iterative repair.
- Dataset B: Simulates user instructions (I) rewritten from Z at three densities (short, medium, long), teaching the model to map natural language to layout specs.
-
Data annotation includes controlled degradation via a “Chaos Monkey” agent that introduces 2–15 errors per layout using four perturbation levels (weighted 1:2:3:4), creating paired error-correction examples.
-
Final dataset size: ~14k samples after filtering out ~5k invalid cases and manually correcting ~1.2k long-tail samples.
-
Metadata is structured as a quadruple (M, A, L, P): scene metadata, asset definitions, spatial layout, and physics/interaction properties. Layouts are grid-based, with assets placed via coordinates and layer commands (floor, wall, object, NPC).
-
All assets are sourced from open-source platforms and anonymized. Human evaluators participated under informed consent, with all interaction data de-identified.
-
The dataset is used for two-stage fine-tuning: first to generate layouts from descriptions, then to correct errors via trajectory learning. The 12-zone grid and Physical Placer ensure spatial coherence during generation.
Method
The authors leverage a collaborative multi-agent framework, termed World Guild, to address the challenge of mapping natural language instructions to structured game scene layouts. This framework decomposes the generation process into a sequence of logically distinct stages, each handled by a specialized agent, thereby mitigating the significant semantic gap between abstract textual descriptions and precise geometric and physical specifications. The overall architecture, as illustrated in the framework diagram, orchestrates four core agents: the Semantic Enricher, the Layout Manager, the Quality Assurance Critic, and the Asset Artist, to transform a user instruction into a playable game scene.
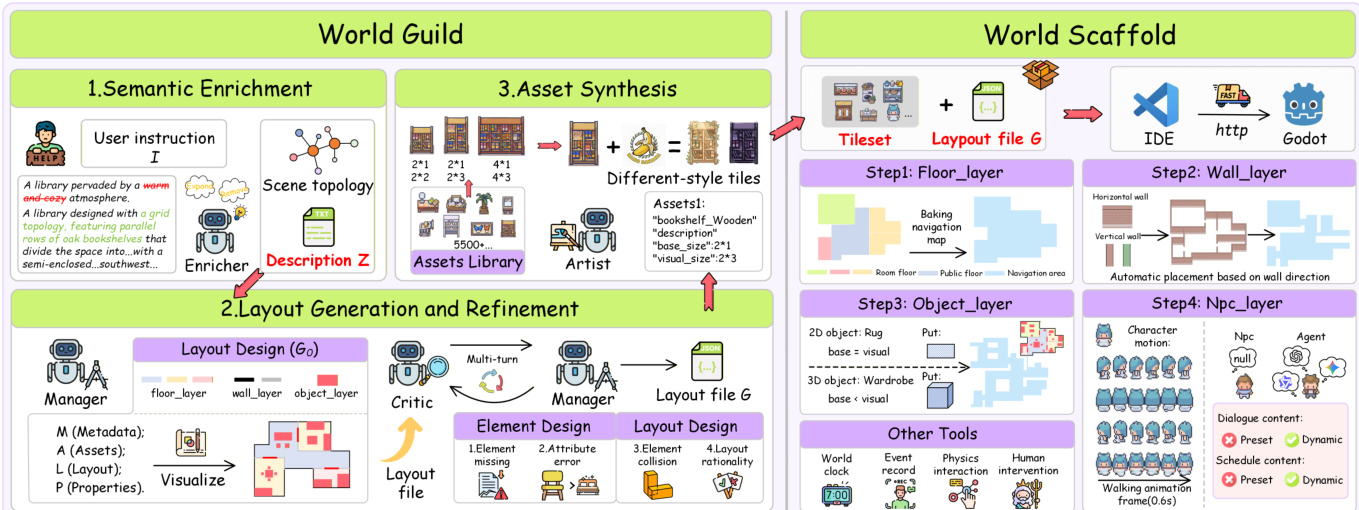
The process begins with the Semantic Enricher, which receives the user instruction I and generates an intermediate, semantically rich layout description Z. This description, referred to as scene topology, captures the high-level spatial logic and functional distribution of the scene without specifying exact coordinates. It defines the connectivity between core components and their rough distribution, effectively creating a spatial sketch that resolves the ambiguity inherent in natural language inputs. This step is crucial for normalizing diverse and often sparse user prompts into a coherent, logical structure that can guide the subsequent spatial planning.
The Layout Manager then takes this abstract description Z and performs the grounding process, converting it into a concrete initial layout file G0. This agent is responsible for the cross-modal transformation from text to executable data, determining the scene metadata M, instantiating the asset library A, and defining the precise grid coordinates and orientation for each component in the layout layer L. The Manager's function is to parse the topological logic and relative positional constraints from the natural language and map them into quantitative, precise geometric parameters, thereby generating a complete layout file with a hierarchical structure and asset attributes.
To ensure the generated layout adheres to physical and logical constraints, an iterative feedback loop is established with the Quality Assurance Critic. In each iteration t, the Critic performs rule-based physical checks, such as collision and connectivity detection, and model-based semantic evaluations on the current layout Gt. It generates specific correction instructions Ct if defects are found. The Manager then executes targeted spatial editing operations based on these instructions to produce a corrected layout Gt+1. This process continues until all checks are passed or a maximum number of rounds is reached, ensuring the rationality and logical self-consistency of the final output.
Finally, the Asset Synthesis agent, or Artist, is responsible for transforming the asset definition set A within the layout design G into visual assets. To address style fragmentation, it employs a retrieval-augmented texture synthesis strategy. For each component, it retrieves a reference image vref from a pre-built asset library Dlib, using it as a style anchor to guide a generative model in producing tile resources that possess a unified visual style. The World Scaffold then automatically assembles these generated visual resources with the layout layer L and property set P, constructing a complete, playable game scene with navigation meshes and interaction logic.
Experiment
- Validated stepwise reasoning framework (Enricher + Manager + Critic) improves layout metrics (RCS, OPS, OVD) over direct generation, confirming task decoupling efficacy.
- Decoupled training outperforms end-to-end fine-tuning; (8+32)B model combo surpasses (8+8)B, showing spatial planning requires higher capacity.
- Correction data training enables iterative refinement, yielding steady metric growth across rounds (T=0 to 4), unlike standard-trained models.
- On 300-sample test set (100 seeds × 3 lengths), method maintains stable performance across instruction lengths, outperforming general LLMs in robustness.
- Achieved strong correlation between automated metrics and human preference (mean |r| > 0.90, κ = 0.60), validating metric reliability.
- Outperformed code agents (Cursor, Antigravity) in both speed (one-shot vs. 60-min debugging) and quality (highest HWR/VWR), enabling high-fidelity simulation environments.
- Ablation showed asset library critical for visual harmony (VH ↑, VGG loss ↓); removal degrades VSA-V but not VSA-C, confirming style consistency aids VLM judgment.
- Visual examples (Scenes 1–3) demonstrate superior layout complexity, object density, and semantic fidelity versus baselines and code agents.
Results show that the proposed method achieves superior performance across multiple metrics compared to baseline models. It consistently outperforms the Open and Base models in layout design, object placement, and visual-semantic consistency, particularly on longer instructions, while maintaining stable performance across varying input lengths. The method also demonstrates robustness in handling complex spatial reasoning tasks, with significant improvements in metrics such as Collision-Free Rate, Room Connectivity Score, and Object Volume Density.

The authors use a two-stage framework to evaluate scene generation models, comparing their method against Qwen3-235B and Gemini-3-Pro across layout rationality, element richness, and visual consistency. Results show that their approach achieves the highest scores in layout rationality and visual consistency, with strong reliability across metrics, while also demonstrating superior performance in element richness compared to the open and closed baselines.

The authors use a multi-turn correction process to evaluate the impact of error-correction data on model refinement, showing that models trained on correction data achieve significant improvements in spatial layout metrics such as Collision-Free Rate, Room Connectivity Score, and Object Placement Score across all four correction rounds. In contrast, models trained only on standard data show minimal gains, indicating that correction data is essential for effective iterative refinement.

The authors use an ablation study to evaluate the impact of the asset library on visual generation quality. Results show that including the asset library significantly reduces VGG Loss and improves Visual Harmony, while also enhancing VSA-V scores, indicating that the asset library effectively resolves style discrepancies and ensures visual consistency across generated scenes.
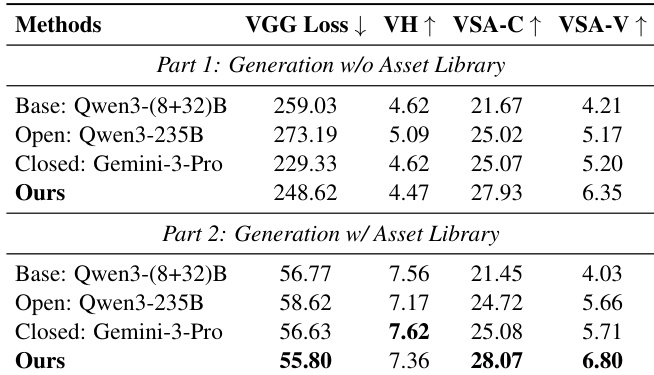
The authors use a two-stage training strategy to improve scene generation, with the inclusion of a critic module and correction data significantly enhancing performance across layout and element design metrics. Results show that the proposed method, trained on correction data, achieves the highest scores in all evaluated dimensions, demonstrating the effectiveness of iterative refinement and the importance of domain-specific training.
